







 Spark可以通过SBT和Maven两种方式进行编译,再通过make-distribution.sh脚本生成部署包。SBT编译需要安装git工具,而Maven安装则需要maven工具,两种方式均需要在联网下进行,通过比较发现SBT编译速度较慢(原因有可能是1、时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 2、maven下载大文件是多线程进行,而SBT是单进程)
Spark可以通过SBT和Maven两种方式进行编译,再通过make-distribution.sh脚本生成部署包。SBT编译需要安装git工具,而Maven安装则需要maven工具,两种方式均需要在联网下进行,通过比较发现SBT编译速度较慢(原因有可能是1、时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 2、maven下载大文件是多线程进行,而SBT是单进程)
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送–Spark入门实战系列》获取
1 编译Spark
Spark可以通过SBT和Maven两种方式进行编译,再通过make-distribution.sh脚本生成部署包。SBT编译需要安装git工具,而Maven安装则需要maven工具,两种方式均需要在联网下进行,通过比较发现SBT编译速度较慢(原因有可能是1、时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 2、maven下载大文件是多线程进行,而SBT是单进程),Maven编译成功前后花了3、4个小时。
1.1 编译Spark(SBT)
1.1.1 安装git并编译安装
1.从如下地址下载git安装包
http://www.onlinedown.net/softdown/169333_2.htm
https://www.kernel.org/pub/software/scm/git/
如果linux是CentOS操作系统可以通过:yum install git直接进行安装
由于从https获取内容,需要安装curl-devel,可以从如下地址获取
http://rpmfind.net/linux/rpm2html/search.php?query=curl-devel
如果linux是CentOS操作系统可以通过:yum install curl-devel直接进行安装
2.上传git并解压缩
把git-1.7.6.tar.gz安装包上传到/home/hadoop/upload目录中,解压缩然后放到/app目录下
$cd /home/hadoop/upload/
$tar -xzf git-1.7.6.tar.gz
$mv git-1.7.6 /app
$ll /app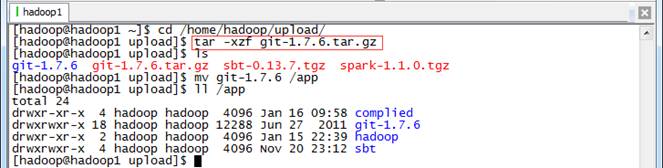
3.编译安装git
以root用户进行在git所在路径编译安装git
#yum install curl-devel
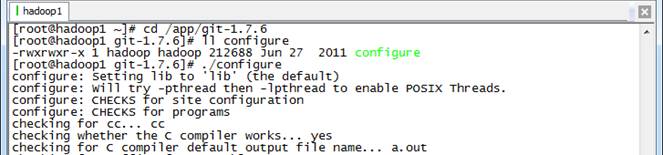
#cd /app/git-1.7.6
#./configure
#make
#make install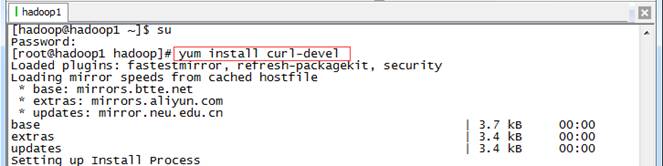


4.把git加入到PATH路径中
打开/etc/profile把git所在路径加入到PATH参数中
export GIT_HOME=/app/git-1.7.6
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$GIT_HOME/bin
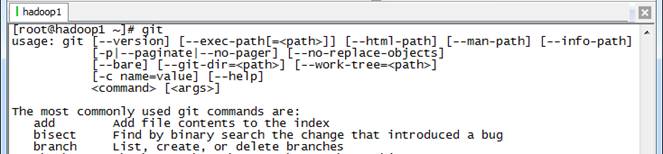
重新登录或者使用source /etc/profile使参数生效,然后使用git命令查看配置是否正确
1.1.2 下载Spark源代码并上传
1.可以从如下地址下载到spark源代码:
http://spark.apache.org/downloads.html
http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0.tgz
git clone https://github.com/apache/spark.git
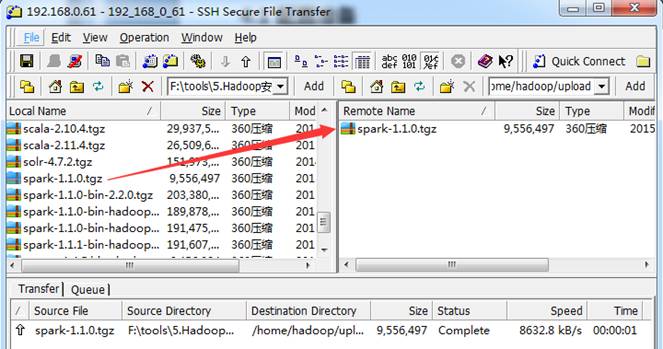
把下载好的spark-1.1.0.tgz源代码包使用1.1.3.1介绍的工具上传到/home/hadoop/upload 目录下
2.在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf spark-1.1.0.tgz
3.把spark-1.1.0改名并移动到/app/complied目录下
$mv spark-1.1.0 /app/complied/spark-1.1.0-sbt
$ls /app/complied
1.1.3 编译代码
编译spark源代码的时候,需要从网上下载依赖包,所以整个编译过程机器必须保证在联网状态。编译执行如下脚本:
$cd /app/complied/spark-1.1.0-sbt
$sbt/sbt assembly -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive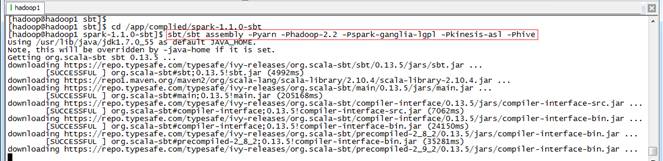

整个编译过程编译了约十几个任务,重新编译N次,需要几个甚至十几个小时才能编译完成(主要看下载依赖包的速度)。
1.2 编译Spark(Maven)
1.2.1 安装Maven并配置参数
在编译前最好安装3.0以上版本的Maven,在/etc/profile配置文件中加入如下设置:
export MAVEN_HOME=/app/apache-maven-3.0.5
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$GIT_HOME/bin
1.2.2 下载Spark源代码并上传
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









