







MaxCompute基本概念
MaxCompute的核心概念主要包括:项目、表、分区、生命周期、资源、函数、任务、任务实例(实例)、ACID语义等。MaxComopute常用术语表参见:MaxCompute术语表。
项目(Project)
项目(Project)是MaxCompute的基本组织单元,它类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。项目中包含多个对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等。
一个用户可以同时拥有多个项目的权限。通过安全授权,可以在一个项目中访问另一个项目中的对象,详情请参见基于Package的跨项目空间资源访问。
可以通过use project命令进入一个项目,例如使用如下命令进入一个名为my_project的项目,可以直接操作该项目下的对象,例如表、资源、函数和实例等。
--进入一个名为my_project的项目空间。
use my_project;表(Table)
表是MaxCompute的数据存储单元。它在逻辑上是由行和列组成的二维结构,每行代表一条记录,每列表示相同数据类型的一个字段,一条记录可以包含一个或多个列,表的结构由各个列的名称和类型构成。MaxCompute中不同类型计算任务的操作对象(输入、输出)都是表。可以创建表、删除表以及导入数据到表或从表中导出数据。
MaxCompute的表格有两种类型:内部表和外部表(MaxCompute2.0版本开始支持外部表)。
- 对于内部表,所有的数据都被存储在MaxCompute中,表中列的数据类型可以是MaxCompute支持的任意一种数据类型。
- 对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS或OTS中 。MaxCompute仅会记录表格的Meta信息,您可以通过MaxCompute的外部表机制处理OSS或OTS上的非结构化数据,例如视频、音频、基因、气象、地理信息等。
分区(Partitions)
分区表是指拥有分区空间的表,即在创建表时指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,一个分区对应一个文件夹,文件夹下是对应分区所有的数据文件。
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。MaxCompute将分区列的每个值作为一个分区(目录),可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。使用数据时,如果指定需要访问的分区名称,则只会读取相应的分区。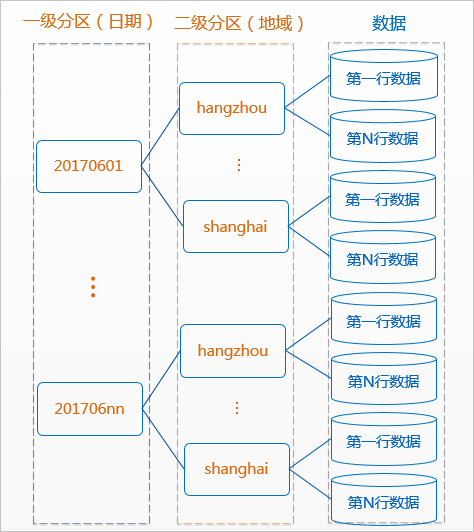
分区使用示例:
--创建一个二级分区表,以日期为一级分区,地域为二级分区
CREATE TABLE src (
key string,
value bigint
)
PARTITIONED BY (pt string, region string);
--正确使用方式。MaxCompute在生成查询计划时只会将'20170601'分区下region为'hangzhou'二级分区的数据纳入输入中。
select * from src where pt='20170601'and region='hangzhou'; MaxCompute2.0数据类型版本支持的分区字段为TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
生命周期(Lifecycle)
MaxCompute表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被MaxCompute自动回收。这个指定的时间就是生命周期。
- 生命周期单位为天,取值为正整数。
- 对于非分区表,如果表数据在生命周期内没有被修改,经过指定天数后此表将会被MaxCompute自动回收(类似DROP TABLE操作)。生命周期从最后一次表数据被修改的时间(LastDataModifiedTime)起开始计算。
- 对于分区表,每个分区可以分别被回收。在生命周期内未被修改数据的分区,经过指定的天数后此分区将会被回收,否则会被保留。每个分区的生命周期是从最后一次分区数据被修改的时间(LastDataModifiedTime)起开始计算。不同于非分区表,分区表的最后一个分区被回收后,该表不会被删除。
- 生命周期主要提供定期回收表或分区的功能,每天根据服务的繁忙程度,不定时回收。不能确保表或分区的生命周期到期后,立刻被回收。
- 只能在表级别设置生命周期,不能在分区级设置生命周期。为分区表指定的生命周期,适用于该表所有的分区。创建表时即可指定生命周期。
- 如果没有为表指定生命周期,则表(分区)不会根据生命周期规则被MaxCompute自动回收。
资源(Resource)
资源(Resource)是MaxCompute的特有概念,MaxCompute的UDF和MapReduce功能需要依赖资源来完成,如下所示:
- SQL UDF:编写UDF后,需要将编译好的Jar包以资源的形式上传到MaxCompute。运行此UDF时,MaxCompute会自动下载这个Jar包,获取代码来运行UDF。上传Jar包的过程就是在MaxCompute上创建资源的过程,这个Jar包是MaxCompute资源的一种。
- MapReduce:编写MapReduce程序后,将编译好的Jar包作为一种资源上传到MaxCompute。运行MapReduce作业时,MapReduce框架会自动下载这个Jar资源获取代码。同样可以将文本文件以及MaxCompute中的表作为不同类型的资源上传到MaxCompute,在UDF及MapReduce的运行过程中读取、使用这些资源。
MaxCompute支持上传的单个资源大小上限为500MB,资源包括以下几种类型:
- File类型。
- Table类型:MaxCompute中的表。MapReduce引用的table类型资源中,table字段类型目前只支持BIGINT、DOUBLE、STRING、DATETIME、BOOLEAN,其他类型暂未支持。
- Jar类型:编译好的Java Jar包。
- Archive类型:通过资源名称中的后缀识别压缩类型,支持的压缩文件类型包括.zip/.tgz/.tar.gz/.tar/jar。
函数(Function)
MaxCompute您提供了SQL计算功能,可以在MaxCompute SQL中使用系统的内建函数完成一定的计算和计数功能。但当内建函数无法满足要求时,可以使用MaxCompute提供的Java编程接口开发自定义函数(User Defined Function,以下简称UDF)。
自定义函数(UDF)可以进一步分为标量值函数(UDF),自定义聚合函数(UDAF)和自定义表值函数(UDTF)三种类型。
使用步骤:在开发完成UDF代码后,需要将代码编译成Jar包,并将此Jar包以Jar资源的形式上传到MaxCompute,最后在MaxCompute中注册此UDF。具体可见:MaxCompute数据开发快速入门。
任务(Task)
任务(Task)是MaxCompute的基本计算单元,SQL及MapReduce功能都是通过任务完成的。
对于提交的大多数任务,特别是计算型任务,例如SQL DML语句,MapReduce,MaxCompute会对其进行解析,得到任务的执行计划。执行计划由具有依赖关系的多个执行阶段(Stage)构成。
目前,执行计划逻辑上可以被看做一个有向图,图中的点是执行阶段,各个执行阶段的依赖关系是图的边。MaxCompute会依照图(执行计划)中的依赖关系执行各个阶段。在同一个执行阶段内,会有多个进程,也称之为Worker,共同完成该执行阶段的计算工作。同一个执行阶段的不同Worker只是处理的数据不同,执行逻辑完全相同。计算型任务在执行时,会被实例化,您可以对这个实例(Instance)进行操作,例如获取实例状态(Status Instance)、终止实例运行(Kill Instance)等。
部分MaxCompute任务并不是计算型的任务,例如SQL中的DDL语句,这些任务本质上仅需要读取、修改MaxCompute中的元数据信息。因此,这些任务无法被解析出执行计划。
任务实例
在MaxCompute中,部分Task在执行时会被实例化,以MaxCompute实例(下文简称为实例或Instance)的形式存在。实例会经历运行(Running)和结束(Terminated)两个阶段。
运行阶段的实例状态为Running(运行中),而结束阶段则会有Success(成功)、Failed(失败)和Canceled(被取消)三种状态。可以根据运行任务时MaxCompute给出的实例ID进行查询、改变任务的状态等操作,示例如下。
--查看某实例的状态。
status instance_id;
--停止某实例,将其状态设置为Canceled。
kill instance_id;
--查看某实例的运行日志。
wait instance_id; MaxCompute数据类型
数据类型版本
MaxCompute 2.0推出之后,MaxCompute中包含的数据类型版本存在三个:
- MaxCompute 1.0数据类型
- MaxCompute 2.0数据类型
- MaxCompute兼容Hive数据类型
MaxCompute设置数据类型版本属性的参数共有3个:
- odps.sql.type.system.odps2:MaxCompute 2.0数据类型版本的开关,属性值为True和False。
- odps.sql.decimal.odps2:MaxCompute 2.0的Decimal数据类型的开关,属性值为True和False。
- odps.sql.hive.compatible:MaxCompute Hive兼容模式(即部分数据类型和SQL行为兼容Hive)数据类型版本的开关,属性值为True和False。
在新增项目时MaxCompute可以对3个版本的数据类型进行选择,各个版本默认设置如下:
1. MaxCompute 1.0数据类型版本
setproject odps.sql.type.system.odps2=false;--关闭MaxCompute 2.0数据类型。
setproject odps.sql.decimal.odps2=false;--关闭Decimal 2.0数据类型。
setproject odps.sql.hive.compatible=false;--关闭Hive兼容模式。适用于早期使用的MaxCompute项目,且该项目依赖的产品组件不支持2.0数据类型版本。
2. MaxCompute 2.0数据类型版本
setproject odps.sql.type.system.odps2=true;--打开MaxCompute 2.0数据类型。
setproject odps.sql.decimal.odps2=true;--打开Decimal 2.0数据类型。
setproject odps.sql.hive.compatible=false;--关闭Hive兼容模式。适用于在2020年04月之前无存量数据的MaxCompute项目,且该项目依赖的产品组件支持2.0数据类型版本。
查看和修改数据类型
--查看项目数据类型版本。
setproject;
--开启/关闭MaxCompute2.0数据类型版本。
setproject odps.sql.type.system.odps2=true/false;
--开启/关闭decimal2.0数据类型。
setproject odps.sql.decimal.odps2=true/false;
--开启/关闭hive兼容模式数据类型版本。
setproject odps.sql.hive.compatible=true/false;MaxCompute 1.0数据类型
| 类型 | 常量示例 | 描述 |
|---|---|---|
| BIGINT | 100000000000L、-1L | 64位有符号整型。 取值范围:-2 63 +1~2 63 -1。 |
| DOUBLE | 3.1415926 1E+7 | 64位二进制浮点型。 |
| DECIMAL | 3.5BD、99999999999.9999999BD | 10进制精确数字类型。 整型部分取值范围:-10 36 +1~10 36 -1, 小数部分精确到10 -18 。固定54位数字,其中整数部分36位,小数位为18位。 |
| STRING | “abc”、’bcd’、”alibaba”、‘inc’ | 字符串类型,目前长度限制为8MB。 |
| DATETIME | DATETIME ‘2017-11-11 00:00:00’ | 日期时间类型。 取值范围:0000年1月1日~9999年12月31日,精确到毫秒。 |
| BOOLEAN | True、False | BOOLEAN类型。 取值范围:True、False。 |
对于上述数据类型说明如下:
- 上述的各种数据类型均可为NULL。
- 整型常量的语义默认为BIGINT类型。如果常量过长,超过了BIGINT的值域(例如1,000,000,000,000,000,000,000,000)则会被作为DOUBLE类型处理。例如
SELECT 1 + a;中的整型常量1会被作为BIGINT类型处理。 - 参数涉及2.0数据类型的内置函数,在1.0数据类型版本下无法正常使用。
- 分区表的分区列的数据类型只支持STRING类型。
MaxCompute 2.0数据类型
| 类型 | 常量示例 | 描述 |
|---|---|---|
| TINYINT | 1Y、-127Y | 8位有符号整型。 取值范围:-128~127。 |
| SMALLINT | 32767S、-100S | 16位有符号整型。 取值范围:-32768~32767。 |
| INT | 1000、-15645787 | 32位有符号整型。 取值范围:-2 31 ~2 31 -1。 |
| BIGINT | 100000000000L、-1L | 64位有符号整型。 取值范围:-2 63 +1~2 63 -1。 |
| BINARY | 无 | 二进制数据类型,目前长度限制为8MB。 |
| FLOAT | 无 | 32位二进制浮点型。 |
| DOUBLE | 3.1415926 1E+7 | 64位二进制浮点型。 |
| DECIMAL(precision, scale) | 3.5BD、99999999999.9999999BD | 10进制精确数字类型。
如果不指定以上两个参数,则默认为 |
| VARCHAR(n) | 无 | 变长字符类型,n为长度。 取值范围:1~65535。 |
| CHAR(n) | 无 | 固定长度字符类型,n为长度。最大取值255。长度不足则会填充空格,但空格不参与比较。 |
| STRING | “abc”、’bcd’、”alibaba”、‘inc’ | 字符串类型,目前长度限制为8MB。 |
| DATE | DATE'2017-11-11' | 日期类型,格式为yyyy-mm-dd。 取值范围:0000-01-01~9999-12-31。 |
| DATETIME | DATETIME ‘2017-11-11 00:00:00’ | 日期时间类型。 取值范围:0000-01-01 00:00:00.000~9999-12-31 23.59:59.999,精确到毫秒。 |
| TIMESTAMP | TIMESTAMP ‘2017-11-11 00:00:00.123456789’ | 与时区无关的时间戳类型。 取值范围:0000-01-01 00:00:00.000000000~9999-12-3123.59:59.999999999,精确到纳秒。 说明 对于部分时区相关的函数,例如 |
| BOOLEAN | True、False | BOOLEAN类型。 取值范围:True、False。 |
支持的复杂数据类型:
| 类型 | 定义方法 | 构造方法 |
|---|---|---|
| ARRAY |
|
|
| MAP |
|
|
| STRUCT |
|
|
以上数据类型的具体说明,以及MaxCompute各类数据类型的区别,详见:MaxCompute 2.0数据类型。
Hive兼容数据类型
Hive兼容数据类型版本支持的基础数据类型与2.0数据类型定义基本一致,只有Decimal数据类型在两个版本下有些差异。具体见:Hive兼容数据类型版本。















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









