






一、线性表的定义
1.1什么是线性表
线性表是具有相同特性的数据元素的一个有限序列。
特征:所有数据元素类型相同。
线性表是有限个数据元素构成的。
线性表中数据元素与位置相关,即每个数据元素有唯一的序号。
线性表的逻辑结构示意图:

1.2线性表的抽象数据类型
ADT List
{
数据对象:
D={ai | 0<=i<=n-1,n>=0 }
数据关系:
r={<ai,ai+1> | ai,ai+1∈D,i=0,…,n-2}
基本运算:
CreateList( a):由整数数组a中的全部元素建立线性表的相应存储结构。
Add(e):将元素e添加到线性表末尾。
getsize():求线性表的长度。
GetElem(int i):求线性表中序号为i的元素。
SetElem(int i,E e):设置线性表中序号i的元素值为e。
GetNo(E e):求线性表中第一个值为e的元素的序号。
Insert(int i,E e):在线性表中插入数据元素e作为第i个元素。
Delete(int i):在线性表中删除第i个数据元素。
display():输出线性表的所有元素。
}二、线性表的顺序存储结构
2.1、顺序表
长度为n的线性表存放在顺序表中

*这里指定data容量为capacity,随着线性表的插入和删除操作,size是变化的,当size达到capacity时,若再插入元素会出现溢出,为此将容量扩大为size的两倍,当删除元素时,size小到一定程度便缩小容量,从而实现顺序表的可扩展性。
*data数组存放线性表元素data数组的容量(存放最多的元素个数)为capacity。 线性表中实际数据元素个数size
设计顺序表为SqList,主要包含存放元素的data列表和表示实际元素个数的size属性
class SqList: #顺序表类
def __init__(self): #构造方法
self.initcapacity=5 #初始容量设置为5
self.capacity=self.initcapacity #容量设置为初始容量
self.data=[None]*self.capacity #设置顺序表的空间
self.size=0 #长度设置为02.2、线性表基本运算算法在顺序表中的实现
在动态分配顺序表的空间时,初始容量设置为initcapacity,当添加或者插入元素可能需要扩大容量,在删除元素时可能需要减少容量。
def resize(self,newcapacity): #改变顺序表的容量为newcapacity
assert newcapacity>=0 #检测参数正确性的断言
olddata=self.data
self.data=[None]*newcapacity
self.capacity=newcapacity
for i in range(self.size):
self.data[i]=olddata[i]该算法先让olddata指向data,为data重新分配一个容量为newcapacity的空间,再将olddata中的元素复制到data中,复制中所有元素的序号和长度size不变,原data空间会被系统自动释放
1、整体建立顺序表
def CreateList(self.a): #由数组a中的元素整体建立顺序表
for i in range(0,len(a)):
if self.size==self.capacity: #出现上溢出时
self.resize(2*self.size) #扩大容量
self.data[self.size]=a[i] #添加元素a[i]
self.size+=1 #添加一个元素后长度增1算法 的时间复杂度为O(n),n表示顺序表中的元素个数
2、顺序表的基本运算方法
(1)将元素e添加到顺序表的末尾:Add (e)
def Add(self, e): #在线性表的末尾添加一个元素e
if self.size==self.capacity: #顺序表空间满时倍增容量
self.resize(2*self.size)
self.data[self.size]=e #添加元素e
self.size+=1 #长度增1
在上述算法中调用一次resize()方法的时间复杂度为O(n),但n次Add操作只需要扩大一次空间所以平均时间复杂度为O(1)
(2)求顺序表的长度:getsize():
def getsize(self): #求线性表长度
return self.size
(3)求顺序表中序号为i的元素的值:GetElem(i):
def __getitem__(self,i): #求序号为i的元素
assert 0<=i<self.size #检测参数i正确性的断言
return self.data[i] #返回data[i]
(4)设置顺序表中序号为i的元素值:SetElem(i,e):
def __setitem__(self, i, x): #设置序号为i的元素
assert 0<=i<self.size #检测参数i正确性的断言
self.data[i]=x
(5)求顺序表中第一个值为e的元素的序号:GetNo(e):
def GetNo(self,e): #查找第一个为e的元素的序号
i=0
while i<self.size and self.data[i]!=e:
i+=1 #查找元素e
if(i>=self.size): #未找到时返回-1
return -1
else:
return i #找到时返回序号
#该算法的时间复杂度为O(n)(6)在线性表中插入e作为第i个元素Insert(i,e)
def Insert(self,i,e):
assert 0<=i<=self.size
if self.size==self.capacity: #满时倍增容量
self.resize(2*self.size)
for j in range(self.size,i,-1): #将data[i]及后面的元素后移一个位置
self.data[j]=self.data[j-1]
self.data[i]=e #插入元素e
self.size+=1有效插入位置i的取值是0~n,共有n+1个位置可以插入元素:
当i=0时,移动次数为n,达到最大值。 当i=n时,移动次数为0,达到最小值。 其他情况,需要移动data[i..n-1]的元素,移动次数为(n-1)-i+1=n-i。
所需移动元素的平均次数为:
*扩容运算resize()在n次插入中仅仅调用一次,其平摊时间为O(1),上述算法时间分析可以忽略它
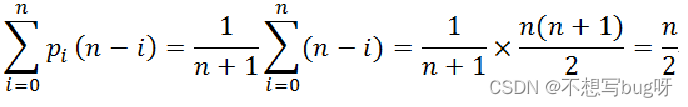
(7)在线性表中删除第i个数据元素Delete(i)
def Delete(self, i): #在线性表中删除序号i的元素
assert 0<=i<=self.size-1 #检测参数i正确性的断言
for j in range(i,self.size-1):
self.data[j]=self.data[j+1] #将data[i]之后的元素前移一个位置
self.size-=1 #长度减1
if self.capacity>self.initcapacity and self.size<=self.capacity/4:
self.resize(self.capacity//2) #满足缩容条件则容量减半
有效删除位置i的取值是0~n-1,共有n个位置可以删除元素:
当i=0时,移动次数为n-1,达到最大值。 当i=n-1时,移动次数为0,达到最小值。 其他情况,需要移动data[i+1..n-1]的元素,移动次数为(n-1)-(i+1)+1=n-i-1。
所需移动元素的平均次数为:
(8)输出线性表所有元素display()
def display(self): #输出线性表
for i in range(0,self.size):
print(self.data[i],end=' ')
print()
2.3 顺序表的应用算法设计示例
1、基于顺序表基本操作的算法设计
对于含有n个整数元素的顺序表L,设计一个算法将其中所有元素逆置。例如L=(1,2,3,4,5),逆置后L=(5,4,3,2,1)。并给出算法的时间复杂度和空间复杂度。
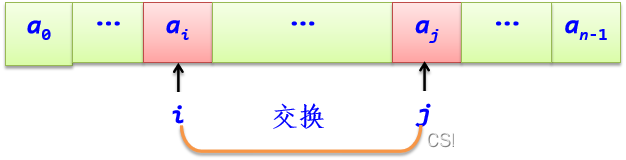
def Reverse(L): #求解算法
i=0
j=L.getsize()-1
while i<j :
L[i],L[j]=L[j],L[i] #序号为i和j的两个元素交换
i+=1
j-=1
#时间复杂度为O(n),空间复杂度为O(1)2、基于整体建立顺序表的算法设计
对于含有n个整数元素的顺序表L,设计一个算法用于删除其中所有值为x的元素。
例如L=(1,2,1,5,1),若x=1,删除后L=(2,5)。并给出算法的时间复杂度和空间复杂度。
*解法一:对于整数顺序表L,删除其中所有x元素后得到的结果顺序表可以与原L共享,所以求解问题转化为新建结果顺序表。
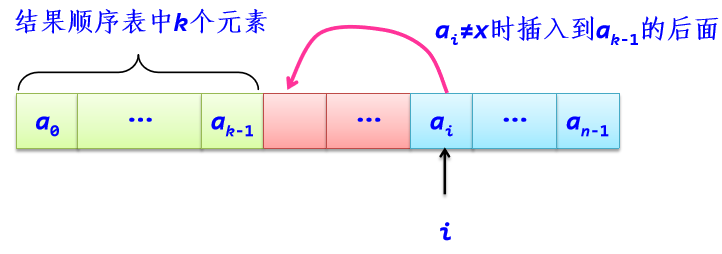
def Deletex1(L, x): #求解算法1
k=0
for i in range(L.getsize()):
if L[i]!=x: #将不为x的元素插入到data中
L[k]=L[i]
k+=1
L.size=k #重置长度为k
*解法二:前移法,对于整数顺序表L,从头开始扫描L,用k累计当前为止值为x的元素个数(初始值为0),处理当前序号为i的元素ai:
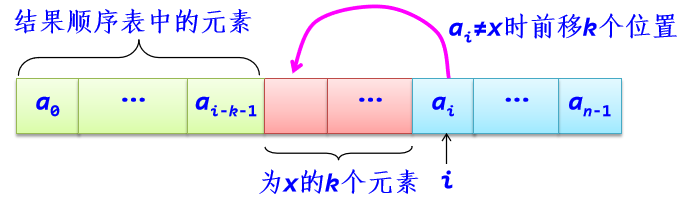
(1)若ai是不为x的元素,此时前面有k个为x的元素,将ai前移k个位置,继续处理下一个元素。
(2)若是为x的元素,置k++,继续处理下一个元素。 最后将L的长度减少k。
def Deletex2(L, x): #求解算法2
k=0;
for i in range(L.getsize()):
if L[i]!=x: #将不为x的元素前移k个位置
L[i-k]=L[i]
else: #累计删除的元素个数k
k+=1
L.size-=k #重置长度减少k
3、有序顺序表的算法设计
有序表是指按元素值或者某属性值递增或者递减排列的线性表,有序表是线性表的一个子集。 有序顺序表是有序表的顺序存储结构。 对于有序表可以利用其元素的有序性提高相关算法的效率,二路归并就是有序表的一种经典算法。
eg:有两个按元素值递增有序的整数顺序表A和B,设计一个算法将顺序表A和B的全部元素合并到一个递增有序顺序表C中。并给出算法的时间复杂度和空间复杂度。
*二路归并法
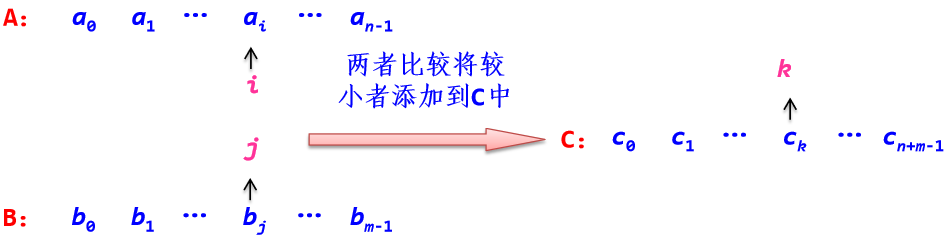
i遍历A,j遍历B,均从0开始 while i,j都没有超界
ai与bj比较:较小元素添加到C中,后移相应指针 将没有遍历完的元素添加到C中
def Merge2(A, B): #求解算法
C=SqList() #新建顺序表C
i=j=0 #i用于遍历A,j用于遍历B
while i<A.getsize() and j<B.getsize(): #两个表均没有遍历完毕
if A[i]<B[j]:
C.Add(A[i]) #将较小的A[i]添加到C中
i+=1
else:
C.Add(B[j]) #将较小的B[j]添加到C中
j+=1
while i<A.getsize(): #若A没有遍历完毕
C.Add(A[i])
i+=1
while j<B.getsize(): #若B没有遍历完毕
C.Add(B[j])
j+=1
return C #返回C
算法中尽管有多个while循环语句,但恰好对顺序表A、B中每个元素均访问一次,所以时间复杂度为O(n+m) 。 算法中需要在临时顺序表C中添加n+m个元素,所以算法的空间复杂度也是O(n+m)。
三、线性表的链式存储结构
3.1、链表
1、单链表:如果每个结点只设置一个指向其后继结点的指针成员,这样的链表称为线性单向链接表,简称单链表。
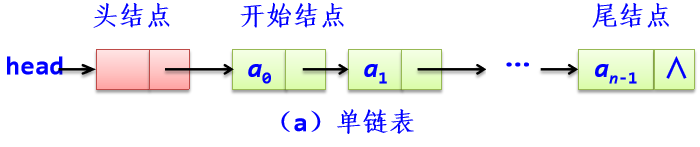
每个结点为LinkNode类对象,包括存储元素的数据列表data和存储后继结点的指针属性next。
class LinkNode: #单链表结点类
def __init__(self,data=None): #构造方法
self.data=data #data属性
self.next=None #next属性
设计单链表类,,其中head属性为单链表的头结点,构建方法用于创建这个头结点,并且置head结点的next为空
class LinkList: #单链表类
def __init__(self): #构造方法
self.head=LinkNode() #头结点head
self.head.next=None
(1)插入和删除结点操作
插入结点操作:将结点s插入到单链表中p结点的后面。
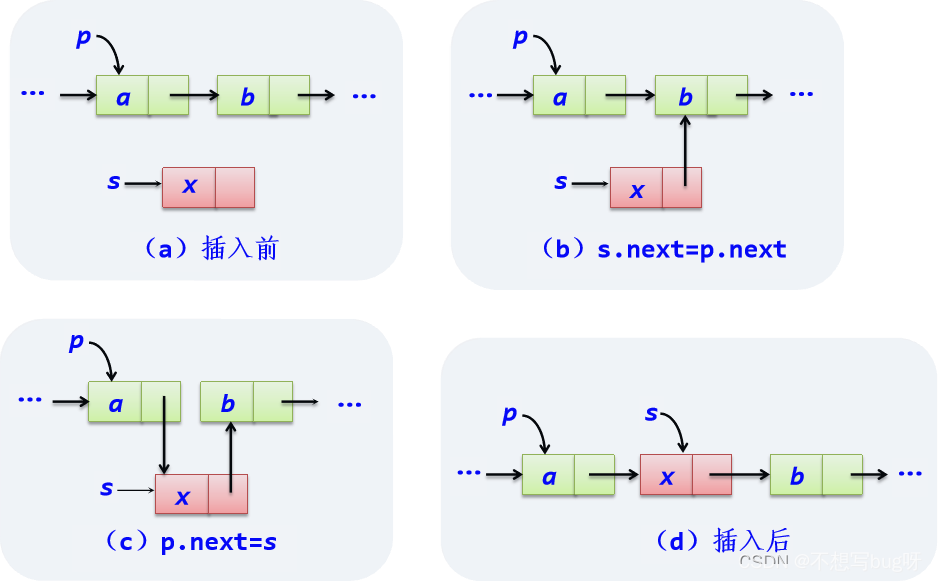
用python语句描述如下:
s.next=p.next
p.next=s删除结点操作:删除单链表中p结点的后继结点。
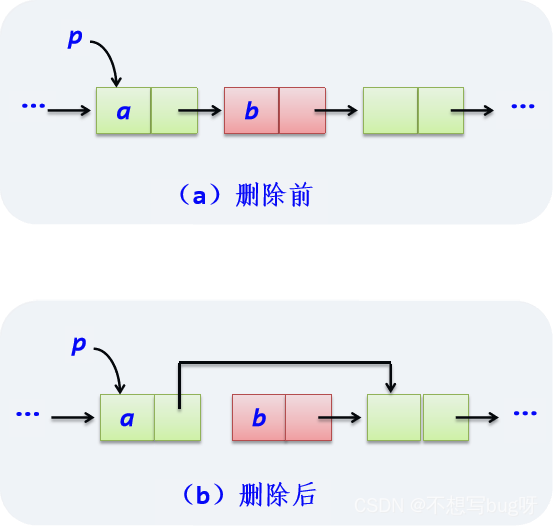
p.next=p.next.next(2)整体建立单链表
通过一个含有n个元素的a数组来建立单链表。 建立单链表的常用方法有两种:头插法和尾插法。
*头插法:
从一个空表开始,依次读取数组a中的元素。 生成新结点s,将读取的数据存放到新结点的数据成员中。 将新结点s插入到当前链表的表头上。
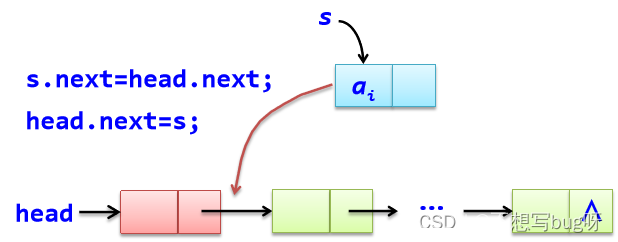
def CreateListF(self, a): #头插法:由数组a整体建立单链表
for i in range(0,len(a)): #循环建立数据结点s
s=LinkNode(a[i]) #新建存放a[i]元素的结点s
s.next=self.head.next #将s结点插入到开始结点之前,头结点之后
self.head.next=s
a=[1,2,3,4],调用CreateListF(a) 头插法建立的单链表中数据结点的次序与a数组中的次序正好相反

*尾插法:
从一个空表开始,依次读取数组a中的元素。 生成新结点s,将读取的数据存放到新结点的数据成员中。 将新结点s插入到当前链表的表尾上。
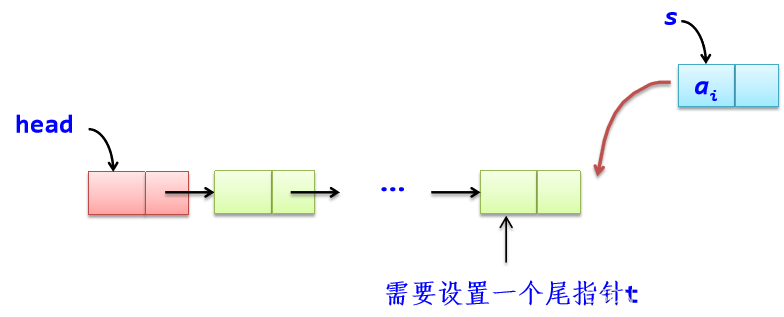
def CreateListR(self, a): #尾插法:由数组a整体建立单链表
t=self.head #t始终指向尾结点,开始时指向头结点
for i in range(0,len(a)): #循环建立数据结点s
s=LinkNode(a[i]) #新建存放a[i]元素的结点s
t.next=s #将s结点插入t结点之后
t=s
t.next=None #将尾结点的next成员置为空
a=[1,2,3,4],调用CreateListR(a) 尾插法建立的单链表中数据结点的次序与a数组中的次序正好相同

(3)线性表基本运算在单链表中的实现
*查找序号为i(0≤i≤n-1,n为单链表中数据结点个数)的结点
def geti(self, i): #返回序号为i的结点
p=self.head
j=-1
while (j<i and p is not None):
j+=1
p=p.next
return p
* 将元素e添加的线性表末尾Add(e)
def Add(self, e): #在线性表的末尾添加一个元素e
s=LinkNode(e) #新建结点s
p=self.head
while p.next is not None: #查找尾结点p
p=p.next
p.next=s; #在尾结点之后插入结点s
* 求线性表的长度getsize()
def getsize(self): #返回长度
p=self.head
cnt=0
while p.next is not None: #找到尾结点为止
cnt+=1
p=p.next
return cnt
若像顺序表中一样,在单链表中设置一个长度size,插入时size+=1,删除时size-=1。那么求长度的时间复杂度为O(1)了。
*求线性表中序号为i的元素GetElem(i)
def __getitem__(self,i): #求序号为i的元素
assert i>=0 #检测参数i正确性的断言
p=self.geti(i)
assert p is not None #p不为空的检测
return p.data
*设置线性表中序号为i的元素SetElem(i,e)
def __setitem__(self, i, e): #设置序号为i的元素
assert i>=0 #检测参数i正确性的断言
p=self.geti(i)
assert p is not None #p不为空的检测
p.data=e
*求线性表中第一个值为e的元素的逻辑序号GetNo(e)
def GetNo(self,e): #查找第一个为e的元素的序号
j=0
p=self.head.next
while p is not None and p.data!=e:
j+=1 #查找元素e
p=p.next
if p is None:
return -1 #未找到时返回-1
else:
return j #找到后返回其序号
*在线性表中插入e作为第i个元素Insert(i,e)
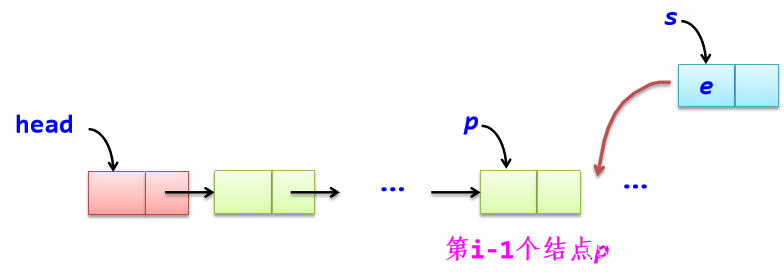
def Insert(self, i, e): #在线性表中序号i位置插入元素e
assert i>=0 #检测参数i正确性的断言
s=LinkNode(e) #建立新结点s
p=self.geti(i-1) #找到序号为i-1的结点p
assert p is not None #p不为空的检测
s.next=p.next #在p结点后面插入s结点
p.next=s
*在线性表中删除第i个数据元素Delete(i)
def Delete(self,i): #在线性表中删除序号i位置的元素
assert i>=0 #检测参数i正确性的断言
p=self.geti(i-1) #找到序号为i-1的结点p
assert p!=None and p.next!=None #p和p.next不为空的检测
p.next=p.next.next #删除p结点的后继结点
*输出线性表所有元素display()
def display(self): #输出线性表
p=self.head.next
while p is not None:
print(p.data,end=' ')
p=p.next
print()
(2)双链表
每个结点为DLinkNode类对象,包括存储元素的列表data、存储前驱结点指针属性prior和后继结点的指针属性next。

class DLinkNode: #双链表结点类
def __init__(self,data=None): #构造方法
self.data=data #data属性
self.next=None #next属性
self.prior=None #prior属性
双链表类DLinkList
class DLinkList: #双链表类
def __init__(self): #构造方法
self.dhead=DLinkNode() #头结点dhead
self.dhead.next=None
self.dhead.prior=None
*插入结点操作:
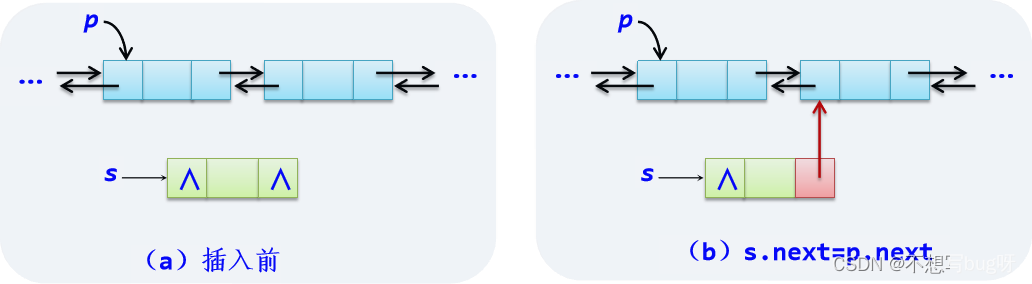
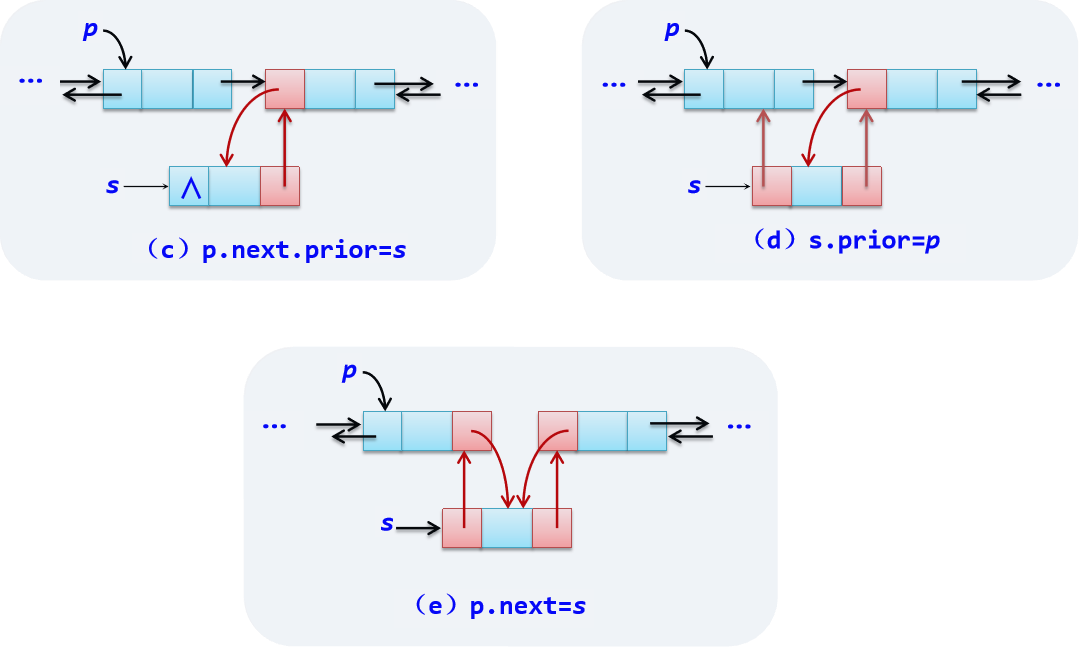
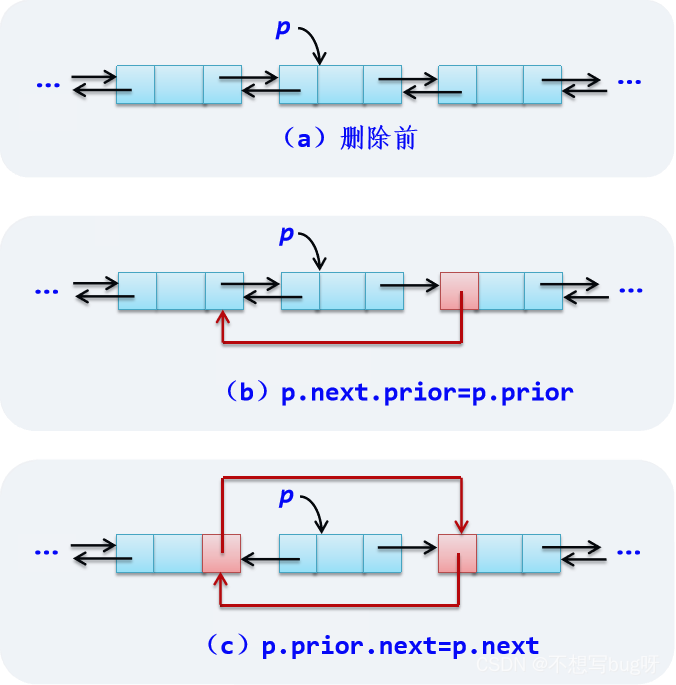
*删除结点操作:
*整体建立双链表
通过一个含有n个元素的a数组来建立双链表。 建立双链表的常用方法有两种:头插法和尾插法。
头插法:
def CreateListF(self, a): #头插法:由数组a整体建立双链表
for i in range(0,len(a)): #循环建立数据结点s
s=DLinkNode(a[i]) #新建存放a[i]元素的结点s,将其插入到表头
s.next=self.dhead.next #修改s结点的next成员
if self.dhead.next!=None: #修改头结点的非空后继结点的prior
self.dhead.next.prior=s
self.dhead.next=s #修改头结点的next
s.prior=self.dhead #修改s结点的prior
尾插法:
def CreateListR(self, a): #尾插法:由数组a整体建立双链表
t=self.dhead #t始终指向尾结点,开始时指向头结点
for i in range(0,len(a)): #循环建立数据结点s
s=DLinkNode(a[i]) #新建存放a[i]元素的结点s
t.next=s #将s结点插入t结点之后
s.prior=t
t=s
t.next=None #将尾结点的next成员置为None
*线性表基本运算在双链表中的实现
许多运算算法(如求长度、取元素值和查找元素等)与单链表中相应算法是相同的. 涉及结点插入和删除操作的算法需要改为按双链表的方式进行结点插入和删除。
在双链表dhead中序号为i的位置上插入值为e的结点的算法
def Insert(self, i, e): #在线性表中序号i位置插入元素e
assert i>=0 #检测参数i正确性的断言
s=DLinkNode(e) #建立新结点s
p=self.geti(i-1) #找到序号为i-1的结点p
assert p is not None #p不为空的检测
s.next=p.next #修改s结点的next属性
if p.next!=None: #修改p结点的非空后继结点的prior属性
p.next.prior=s
p.next=s #修改p结点的next属性
s.prior=p #修改s结点的prior属性
在双链表dhead中删除序号为i的结点的算法
def Delete(self,i): #在线性表中删除序号i位置的元素
assert i>=0 #检测参数i正确性的断言
p=self.geti(i) #找到序号为i的结点p
assert p is not None #p不为空的检测
p.prior.next=p.next #修改p结点的前驱结点的next
if p.next!=None: #修改p结点非空后继结点的prior
p.next.prior=p.prior
3.2循环链表
1、循环单链表
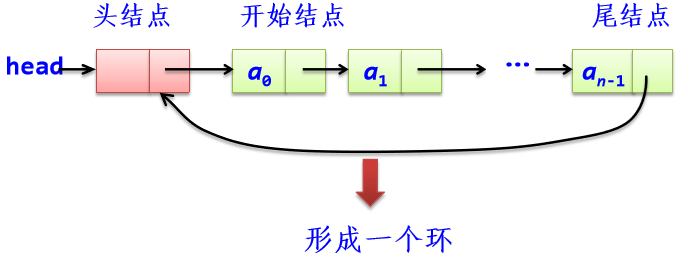
循环单链表类CLinkList:
class CLinkList: #循环单链表类
def __init__(self): #构造方法
self.head=LinkNode() #头结点head
self.head.next=self.head #构成循环单链表
循环单链表的插入和删除结点操作与非循环单链表的相同,所以两者的许多基本运算算法是相似的,主要区别如下:
初始只有头结点head,在循环单链表的构造方法中需要通过head.next=head语句置为空表。 循环单链表中涉及查找操作时需要修改表尾判断的条件,例如,用p遍历时,尾结点满足的条件是p.next==head而不是p.next==None。
例如:编写一个程序求解约瑟夫(Joseph)问题。有n个小孩围成一圈,给他们从1开始依次编号,从编号为1的小孩开始报数,数到第m个小孩出列,然后从出列的下一个小孩重新开始报数,数到第m个小孩又出列,…,如此反复直到所有的小孩全部出列为止,求整个出列序列。 如当n=6,m=5时的出列序列是5,4,6,2,3,1。
(1)设计存储结构
本题采用不带头结点的循环单链表存放小孩圈,其结点类如下:
class Child: #结点类型
def __init__(self,no1): #构造方法
self.no=no1 #编号no属性
self.next=None #next属性
(2)设计基本运算算法
设计一个求解约瑟夫问题的Joseph类,其中包含:
n、m整型成员和首结点指针first成员。 构造方法用于建立有n个结点的不带头结点的循环单链表first。 Jsequence方法用于产生约瑟夫序列的字符串。
class Joseph: #求解约瑟夫问题类
def __init__(self, n1, m1): #构造方法
self.n=n1
self.m=m1
self.first=Child(1); #循环单链表首结点
t=self.first
for i in range(2,self.n+1):
p=Child(i) #建立一个编号为i的新结点p
t.next=p #将p结点链到末尾
t=p
t.next=self.first #构成一个首结点为first的循环单链表
def Jsequence(self): #求约瑟夫序列
for i in range(1,self.n+1): #共出列n个小孩
p=self.first #每次都从first开始
j=1
while j<self.m-1: #从first结点开始报数,报到第m-1个结点
j+=1 #报数递增
p=p.next #移到下一个结点
q=p.next #q指向第m个结点
print(q.no,end=' ') #该结点的小孩出列
p.next=q.next #删除q结点
self.first=p.next #从下一个结点重新开始
print()
(3)设计主程序
n=6
m=3
L=Joseph(n,m)
print("n=%d,m=%d的约瑟夫序列:" %(n,m))
L.Jsequence()
(4)执行结果

2、循环双链表
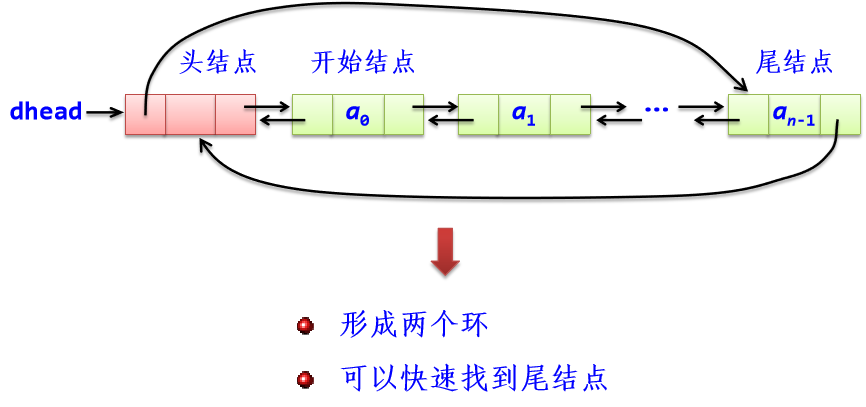
class CDLinkList: #循环双链表类
def __init__(self): #构造方法
self.dhead=DLinkNode() #头结点dhead
self.dhead.next=self.dhead
self.dhead.prior=self.dhead
循环双链表的插入和删除结点操作与非循环双链表的相同,所以两者的许多基本运算算法是相似的,主要区别如下:
初始只有头结点dhead,在循环双链表的构造方法中需要通过dhead.prior=dhead和dhead.next=dhead两个语句置为空表。 循环双链表中涉及查找操作时需要修改表尾判断的条件,例如,用p遍历时,尾结点满足的条件是p.next==dhead而不是p.next==None。
例如: 有一个带头结点的循环双链表L,其结点data成员值为整数,设计一个算法,判断其所有元素是否对称。如果从前向后读和从后向前读得到的数据序列相同,表示是对称的;否则不是对称的。
(1)结点个数为奇数:
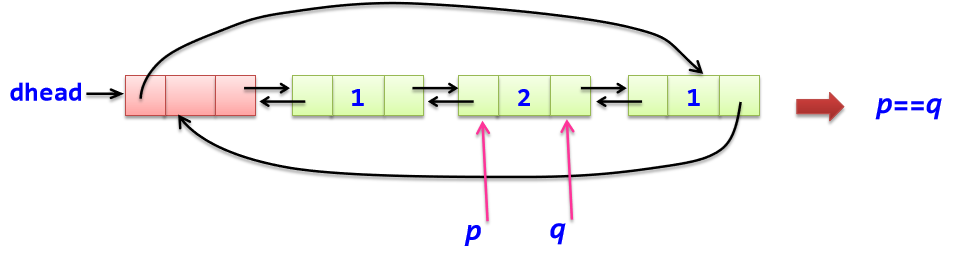
(2)结点个数为偶数
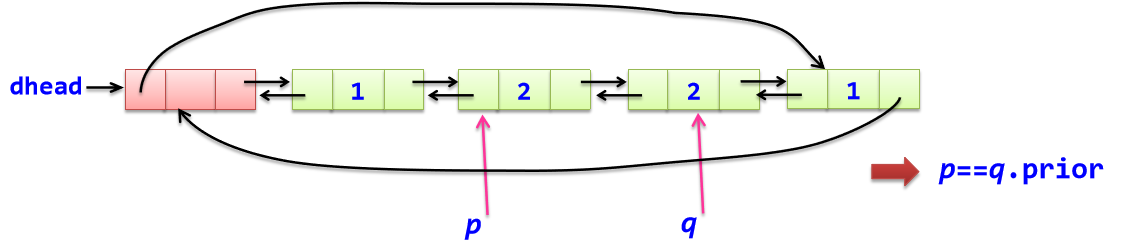
def Symm(L): #求解算法
flag=True; #flag表示L是否对称,初始时为真
p=L.dhead.next; #p指向首结点
q=L.dhead.prior; #q指向尾结点
while flag:
if p.data!=q.data: #对应结点值不相同,置flag为假
flag=False
else:
if p==q or p==q.prior: break
q=q.prior #q前移一个结点
p=p.next #p后移一个结点
return flag
四、线性表的应用 ——两个多项式相加
两个多项式的数据分别存放在abc1.in和abc2.in文本文件中,要求相加的结果多项式的数据存放在abc.out文本文件中。

abc.out文件

ADT PolyClass #多项式抽象数据类型
{
数据对象:
PolyElem={(ci,ei) | 1≤i≤n,ci∈float,ei∈int};
数据关系:
r={<xi,yi> | xi,yi∈PolyElem,i=1,…,n-1}
基本运算:
Add(e):将多项式项e添加到末尾。
CreateList(fname):从fname文件中读取数据建立多项式。
getsize():返回多项式的项数
getitem(i):返回序号为i的多项式项。
getdata():返回多项式。
Sort():对多项式按指数递减排序。
PolyAdd(B):返回当前多项式与多项式B的相加结果。
} #ADT PolyClass
1、设计顺序存储结构
每个多项式项用一个列表[ci,ei](其中ci为系数,ei为指数)存储,一个多项式顺序表用元素为列表[ci,ei]的列表data存储。 例如,多项式p(x)=2x3+3.2x5-6x+10的data列表为[[2.0, 3], [3.2, 5], [-6.0, 1], [10.0, 0]]。
多项式顺序表类PolyList
class PolyList: #多项式顺序表类
def __init__(self): #构造方法
self.data=[] #存放多项式项的列表
#修改基本运算算法
2、设计PolyList的基本运算算法
(1)PolyList的构造方法
def __init__(self): #构造方法
self.data=[] #存放多项式项的列表
(2)将多项式项e添加到末尾Add(e)
def Add(self,e): #添加一个多项式项e
self.data.append(e)
(3)创建多项式顺序表CreateList(fname)
def CreateList(self,fname): #从fname文件中读取多项式数据并添加到data
fin=open(fname,"r")
n=int(fin.readline().strip())
for i in range(n):
p=fin.readline().strip().split()
self.data.append([float(p[0]),int(p[1])])
fin.close()
(4)返回多项式的项数getsize()
def getsize(self): #求多项式的项数
return len(self.data)
(5)返回序号为i的多项式项
def __getitem__(self,i): #求序号为i的元素
return self.data[i]
(6)返回多项式的data列表getdata()
def getdata(self): #返回多项式列表
return self.data
(7)对多项式按指数递减排序Sort()
def Sort(self): #对data按指数递减排序
self.data=sorted(self.data,key=itemgetter(1),reverse=True)
(8)返回当前多项式与多项式B的相加结果PolyAdd(B)

用i、j分别遍历A和B的元素,先建立一个空多项式顺序表C,在i、j都没有遍历完时循环,取i指向的A中元素p,取j指向的B中元素q: ① 若p元素的指数(p[1])较大,将p元素添加到C中,i增加1。 ② 若q元素的指数(q[1])较大,将q元素添加到C中,j增加1。 ③ 此时p、q元素的指数相同(p[1]=q[1]),求出它们的系数和k(k=p[0]+q[0]),如果k≠0,由k和p[1]新建一个元素并添加到C中,否则不新建结点,并将i、j均增加1。 上述循环过程结束后,若有一个多项式顺序表没有遍历完,说明余下的多项式项都是指数较小的多项式项,将它们均添加到C中,最后返回C。
def PolyAdd(self,B): #当前多项式和多项式B的相加运算
C=PolyList() #新建结果多项式顺序表
m=len(self.data) #多项式A的项数
n=B.getsize() #多项式B的项数
i,j=0,0
while i<m and j<n:
p,q=self.data[i],B[j]
if p[1]>q[1]: #将较大指数的p项添加到C中
C.Add(p)
i+=1
elif q[1]>p[1]: #将较大指数的q项添加到C中
C.Add(q)
j+=1
else: #两指数相同,即p[1]=q[1]
k=p[0]+q[0] #系数相加为k
if (k!=0): #k不为0时添加相应项到C中
C.Add([k,p[1]])
i+=1
j+=1
while i<m: #将A余下的项添加到C中
p=self.data[i]
C.Add(p)
i+=1
while j<n: #将B余下的项添加到C中
q=B[j]
C.Add(q)
j+=1
return C
3、设计主程序
fout=open("abc.out","w+")
p=PolyList() #创建第1个多项式顺序表p
p.CreateList("abc1.in")
print("第1个多项式:",end=' ',file=fout) #输出结果写入到abc.out文件中
print(p.getdata(),file=fout)
p.Sort() #第1个多项式顺序表按指数递减排序
print("排序后结果: ",end=' ',file=fout)
print(p.getdata(),file=fout)
q=PolyList() #创建第2个多项式顺序表q
q.CreateList("abc2.in")
print("第2个多项式:",end=' ',file=fout)
print(q.getdata(),file=fout)
q.Sort() #第2个多项式顺序表按指数递减排序
print("排序后结果: ",end=' ',file=fout)
print(q.getdata(),file=fout)
r=p.PolyAdd(q) #r=p+q
print("相加多项式: ",end=' ',file=fout)
print(r.getdata(),file=fout)
fout.close()















 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









