







一、栈
1、栈的定义
1.1、栈(stack)是一种只能在同一端进行插入或删除操作的线性表。 表中允许进行插入、删除操作的一端称为栈顶(top),表的另一端称为栈底(bottom)。 栈的插入操作通常称为进栈或入栈(push),栈的删除操作通常称为退栈或出栈(pop)。

1.2、主要特点
① 后进先出,即后进栈的元素先出栈。
② 每次进栈的元素都作为新栈顶元素,每次出栈的元素只能是当前栈顶元素。
③ 栈也称为后进先出表或者先进后出表。
1.3、基本结构:
ADT Stack
{
数据对象:
D={ai | 0≤i≤n-1,n≥0,元素ai为E类型}
数据关系:
R={r}
r={<ai,ai+1> | ai,ai+1∈D, i=0,…,n-2}
基本运算:
empty():判断栈是否为空,若空栈返回真;否则返回假。
push(e):进栈操作,将元素e插入到栈中作为栈顶元素。
pop():出栈操作,返回栈顶元素。
gettop():取栈顶操作,返回当前的栈顶元素。
}
2、栈的顺序存储结构及其基本运算算法实现
栈可以分为顺序栈和链栈。
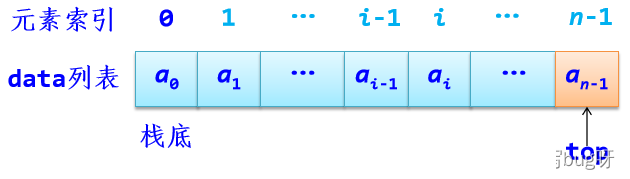
2.1、顺序栈:在采用顺序存储结构存储时,用列表data来存放栈中元素
顺序栈示意图:
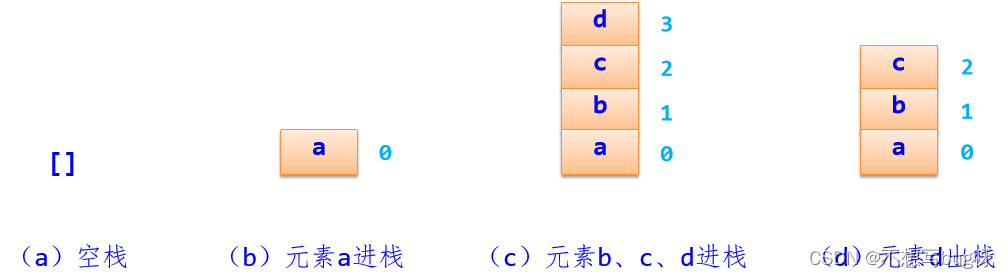
栈的动态示意图:
顺序炸的四要素:
① 栈空条件:len(data)==0或者not data。
② 栈满条件:由于data列表可以动态扩展,所以不必考虑栈满。
③ 元素e进栈操作:将e添加到栈顶处。
④ 出栈操作:删除栈顶元素并返回该元素。
2.2、顺序栈类SqStack
class SqStack:
def __init__(self): #构造方法
self.data=[] #存放栈中元素,初始为空
#栈的基本运算算法
2.3、顺序栈的基本运算算法:
#判断栈是否位空empty()
def empty(self): #判断栈是否为空
if len(self.data)==0:
return True
return False
#进栈push(e)
def push(self,e): #元素e进栈
self.data.append(e)
#出栈pop()
def pop(self): #元素出栈
assert not self.empty() #检测栈为空
return self.data.pop()
#取栈顶元素gettop()
def gettop(self): #取栈顶元素
assert not self.empty() #检测栈为空
return self.data[-1]
*注意:
栈中元素是从栈底向栈顶方向生长的,如果以data数组的中间位置作为栈底,那么栈顶方向的另外一端空间就不能使用,造成空间浪费,所以不能以data数组的中间位置作为栈底。
3、顺序栈的应用算法设计实例
(回文数)
用str存放表达式,其中含n个字符。若str的前半部分的反向序列与str的后半部分相同,则是回文,否则不是回文。判断过程如下:
① 用i从头开始遍历str,将前半部分字符依次进栈。
② 若n为奇数,i增1跳过中间的字符。
③ i继续遍历其他后半部分字符,每访问一个字符,则出栈一个字符, 两者进行比较,如图所示,若不相等返回False。
④ 当str遍历完毕返回True。
from SqStack import SqStack #引用顺序栈
def isPalindrome(str): #判断是否为回文的算法
st=SqStack() #建立一个顺序栈
n=len(str)
i=0
while i<n//2: #将str前半字符进栈
st.push(str[i])
i+=1 #继续遍历str
if n%2==1: #n为奇数时
i+=1 #跳过中间的字符
while i<n: #遍历str的后半字符
if st.pop()!=str[i]:
return False #若str[i]不等于出栈字符返回False
i+=1
return True #是回文返回True
(最小栈)
设计最小栈。定义栈的数据结构,添加一个Getmin()方法用于返回栈中的最小元素。要求方法Getmin()、push以及pop的时间复杂度都是O(1)。
例如:
push(5); #栈元素:(5) 最小元素:5
push(6); #栈元素:(6,5) 最小元素:5
push(3); #栈元素:(3,6,5) 最小元素:3
push(7); #栈元素:(7,3,6,5) 最小元素:3
pop(); #栈元素:(3,6,5) 最小元素:3
pop(); #栈元素:(6,5) 最小元素:5
设计满足题目要求的顺序栈类为STACK:
含data和mindata两个列表,data列表表示data栈(主栈),mindata列表表示mindata栈,后者作为存放当前最小元素的辅助栈。 当元素a0,a1,…,ai(i≥1)进栈到data栈后,min栈的栈顶元素bj为a0,a1,…,ai中的最小元素(含后进栈的重复最小元素)
STACK类的主要运算算法设计如下:
Getmin()方法用于返回栈中的最小元素,其操作是取mindata栈的栈顶元素。 进栈方法push(x)的操作是,当data栈空或者进栈元素x小于等于当前栈中最小元素(即x≤Getmin())时,则将x进mindata栈。最后将x进data栈。 出栈方法pop()的操作是,当data栈不空时,从data栈出栈元素x,若mindata栈的栈顶元素等于x,则同时从mindata栈出栈x。最后返回x。 取栈顶方法gettop()的操作是,当data栈不空时,返回data栈的栈顶元素。

class STACK: #含Getmin()的栈类
def __init__(self): #构造方法
self.data=[] #存放主栈中元素,初始为空
self.__mindata=[] #存放min栈中元素,初始为空
#min栈基本运算算法
def __minempty(self): #判断min栈是否空
return len(self.__mindata)==0
def __minpush(self,e): #元素进min栈
self.__mindata.append(e)
def __minpop(self): #元素出min栈
assert not self.__minempty() #检测min栈为空的异常
return self.__mindata.pop()
def __mingettop(self): #取min栈栈顶元素
assert not self.__minempty() #检测min栈为空的异常
return self.__mindata[-1];
#主栈基本运算算法
def empty(self): #判断主栈是否空
return len(self.data)==0
def push(self,x): #元素进主栈
if self.empty() or x<=self.Getmin():
self.__mindata.append(x) #栈空或者x<=min栈顶元素时进min栈
self.data.append(x); #将x进主栈
def pop(self): #元素出主栈
assert not self.empty() #检测主栈为空的异常
x=self.data.pop() #从主栈出栈x
if x==self.__mingettop(): #若栈顶元素为最小元素
self.__minpop() #min栈出栈一次
return x
def gettop(self): #取主栈栈顶元素
assert not self.empty() #检测主栈为空的异常
return self.data[-1]
def Getmin(self): #获取栈中最小元素
assert not self.empty() #检测主栈为空的异常
return self.__mindata[-1]; #返回min栈的栈顶元素即主栈中最小元素
4、栈的链式存储结构及其基本运算算法的实现
4.1、链栈
链栈示意图:

链栈的四要素:
栈空的条件:head.next==None。
由于只有在内存溢出才会出现栈满,通常不考虑这种情况。
元素e进栈操作:将包含该元素的结点s插入作为首结点。
出栈操作:返回首结点值并且删除该结点。
链栈类LinkStack
class LinkStack: #链栈类
def __init__(self): #构造方法
self.head=LinkNode() #头结点head
self.head.next=None
链栈的基本运算算法:
#判断栈是否为空empty()
def empty(self): #判断栈是否为空
if self.head.next==None:
return True
return False
#进栈push(e)
def push(self,e): #元素e进栈
p=LinkNode(e)
p.next=self.head.next
self.head.next=p
#出栈pop()
def pop(self): #元素出栈
assert self.head.next!=None #检测空栈的异常
p=self.head.next;
self.head.next=p.next
return p.data
#取栈顶元素gettop()
def gettop(self): #取栈顶元素
assert self.head.next!=None #检测空栈的异常
return self.head.next.data
*注意:带头结点的单链表最适合做链栈
5、链栈的应用算法设计示例
1、设计一个算法利用栈的基本运算将一个整数链栈中所有元素逆置。例如链栈st中元素从栈底到栈顶为(1,2,3,4),逆置后为(4,3,2,1)。
这里要求利用栈的基本运算来设计算法,所以不能直接采用单链表逆置方法。先出栈st中所有元素并保存在一个数组a中,再将数组a中所有元素依次进栈。
程序设计如下:
from LinkStack import LinkStack #引用链栈SqStack
def Reverse(st): #逆置栈st
a=[]
while not st.empty(): #将出栈的元素放到列表a中
a.append(st.pop())
for j in range(len(a)): #将列表a的所有元素进栈
st.push(a[j])
return st
2、有一个含1~n的n个整数的序列a,通过一个栈可以产生多种出栈序列,设计一个算法采用链栈判断序列b(为1~n的某个排列)是否得为一个合适的出栈序列
建立一个整型链栈st,用i、j分别遍历a、b序列(初始值均为0),在a序列没有遍历完时循环:
① 将a[i]进栈,i++。
② 栈不空并且栈顶元素与b[j]相同时循环:出栈元素e,j++。
在上述过程结束后,如果栈空返回True表示b序列是a序列的出栈序列,否则返回False表示b序列不是a序列的出栈序列。
from Linktack import LinkStack #引用链栈LinkStack
def isSerial(a,b,n): #判断b是否为a的出栈序列算法
st=LinkStack() #建立一个链栈
i,j=0,0
while i<n: #遍历a序列
st.push(a[i])
i+=1 #i后移
while not st.empty() and st.gettop()==b[j]:
st.pop() #出栈
j+=1 #j后移
return st.empty() #栈空返回True否则返回False
二、队列
2.1、队列的定义
队列(queue)是一种只能在不同端进行插入或删除操作的线性表。
进行插入的一端称做队尾(rear),进行删除的一端称做队头或队首(front)。
队列的插入操作通常称为进队或入队(push),队列的删除操作通常称为出队或离队(pop)。
2.2、队列的主要特点:
先进先出,即先进队的元素先出队。
每次进队的元素作为新队尾元素,每次出队的元素只能是队头的元素。
队列也称为先进先出表。
2.3、队列的顺序存储结构及其基本运算算法实现
采用顺序存储结构的队列成为顺序队
1、非循环队列
(1)、四要素:
队空条件:front==rear。
队满(上溢出)条件:rear==MaxSize-1(因为每个元素进队都让rear增1,当rear到达最大下标时不能再增加。
元素e进队操作:rear增1,将元素e放在该位置(进队的元素总是在尾部插入的)。
出队操作:front增1,取出该位置的元素(出队的元素总是在队头出来的)。
(2)、非循环队列类SqQueue
MaxSize=100 #假设容量为100
class SqQueue: #非循环队列类
def __init__(self): #构造方法
self.data=[None]*MaxSize #存放队列中元素
self.front=-1 #队头指针
self.rear=-1 #队尾指针
(3)、非循环队列的基本运算算法
#判断队列是否为空empty()
def empty(self): #判断队列是否为空
return self.front==self.rear
#进队push(e)
def push(self,e): #元素e进队
assert not self.rear==MaxSize-1 #检测队满
self.rear+=1
self.data[self.rear]=e
#出队pop()
def pop(self): #出队元素
assert not self.empty() #检测队空
self.front+=1
return self.data[self.front]
#取队头元素gethead()
def gethead(self): #取队头元素
assert not self.empty() #检测队空
return self.data[self.front+1]
2、循环队列
把data数组的前端和后端连接起来,形成一个循环数组,即把存储队列元素的表从逻辑上看成一个环,称为循环队列(也称为环形队列)
(1)、四要素:
队空条件:rear==front。
队满条件:(rear+1)%MaxSize==front(相当于试探进队一次,若rear达到front,则认为队满了)。
元素e进队:rear=(rear+1)%MaxSize,将元素e放置在该位置。
元素出队:front=(front+1)%MaxSize,取出该位置的元素。
(2)、循环队列类SqQueue
MaxSize=100 #全局变量,假设容量为100
class CSqQueue: #循环队列类
def __init__(self): #构造方法
self.data=[None]*MaxSize #存放队列中元素
self.front=0 #队头指针
self.rear=0 #队尾指针(3)、循环队列的基本运算算法
#判断队列是否为空empty()
def empty(self): #判断队列是否为空
return self.front==self.rear
#进队push(e)
def push(self,e): #元素e进队
assert (self.rear+1)%MaxSize!=self.front #检测队满
self.rear=(self.rear+1)%MaxSize
self.data[self.rear]=e
#出队pop()
def pop(self): #出队元素
assert not self.empty() #检测队空
self.front=(self.front+1)%MaxSize
return self.data[self.front]
#取队头元素gethead()
def gethead(self): #取队头元素
assert not self.empty() #检测队空
head=(self.front+1)%MaxSize #求队头元素的位置
return self.data[head]
2.4、 队列的链式存储结构及其基本运算算法实现
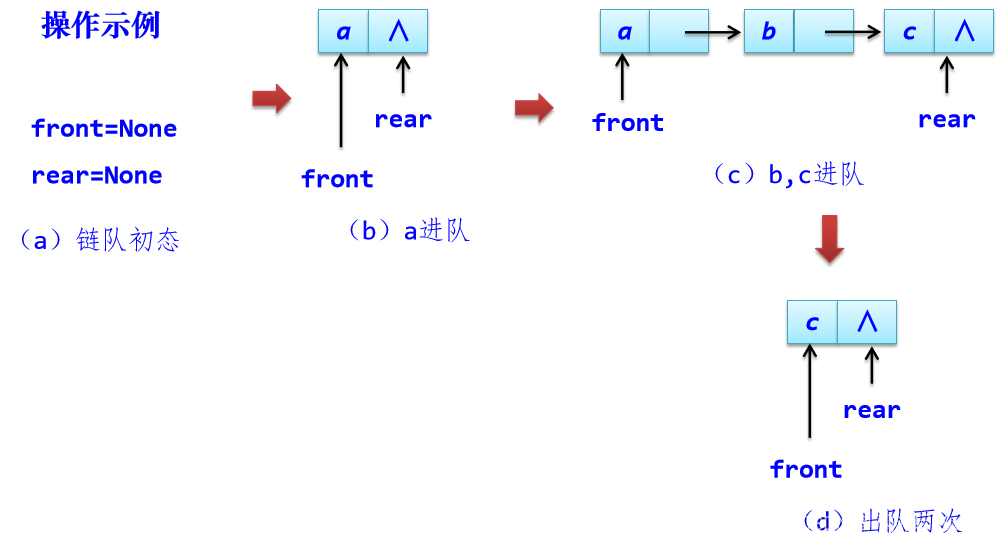
(1)、 链队的四要素:
队空条件:fronr=rear==None,不妨仅以front==None作为队空条件。
由于只有内存溢出时才出现队满,通常不考虑这样的情况。
元素e进队操作:在单链表尾部插入存放e的s结点,并让队尾指针指向它。
出队操作:取出队首结点的data值并将其从链队中删除。
(2)、链队中每个结点的类型LinkNode
class LinkNode: #链队结点类
def __init__(self,data=None): #构造方法
self.data=data #data属性
self.next=None #next属性
(3)、链队类LinkQueue
class LinkQueue: #链队类
def __init__(self): #构造方法
self.front=None #队头指针
self.rear=None #队尾指针
(4)、链队的基本运算算法
#判断队列是否为空empty()
def empty(self): #判断队是否为空
return self.front==None
#进队push(e)
def push(self,e): #元素e进队
s=LinkNode(e) #新建结点s
if self.empty(): #原链队为空
self.front=self.rear=s
else: #原链队不空
self.rear.next=s #将s结点链接到rear结点后面
self.rear=s
#出队pop()
def pop(self): #出队操作
assert not self.empty() #检测空链队
if self.front==self.rear: #原链队只有一个结点
e=self.front.data #取首结点值
self.front=self.rear=None #置为空队
else: #原链队有多个结点
e=self.front.data #取首结点值
self.front=self.front.next #front指向下一个结点
return e
#取队头元素gethead()
def gethead(self): #取队头元素
assert not self.empty() #检测空链队
e=self.front.data #取首结点值
return e
2.5、 Python中的双端队列deque
双端队列是在队列基础上扩展而来的,其示意图如下图所示。
双端队列与队列一样,元素的逻辑关系也是线性关系,但队列只能在一端进队,另外一端出队,而双端队列可以在两端进行进队和出队操作,具有队列和栈的特性,因此使用更加灵活。

1、创建双端队列:
qu=deque() #创建一个空的双端队列qu
qu=deque(maxlen=N) #创建一个固定长度为N的双端队列qu
qu=deque(L) #创建的双端队列qu中包含列表L中的元素
2、 双端队列的方法:
deque.clear():清除双端队列中的所有元素。
deque.append(x):在双端队列的右端添加元素x。时间复杂度为O(1)。
deque.appendleft(x):在双端队列的左端添加元素x。时间复杂度为O(1)。
deque.pop():在双端队列的右端出队一个元素。时间复杂度为O(1)。
deque.popleft():在双端队列的左端出队一个元素。时间复杂度为O(1)。
deque.remove(x):在双端队列中删除首个和x匹配的元素(从左端开始匹配的),如果没有找到抛出异常。时间复杂度为O(n)。
deque.count(x):计算双端队列中元素为x的个数。时间复杂度为O(n)。
deque.extend(L):在双端队列的右端添加列表L的元素。例如,qu为空,L=[1,2,3],执行后qu从左向右为[1,2,3]。
deque.extendleft(L):在双端队列的左端添加列表L的元素。例如,qu为空,L=[1,2,3],执行后qu从左向右为[3,2,1]。
deque.reverse():把双端队列里的所有元素的逆置。
deque.rotate(n):双端队列的移位操作,如果n是正数,则队列所有元素向右移动n个位置,如果是负数,则队列所有元素向左移动n个位置。
3、用双端队列实现栈
以左端作为栈底(左端保持不动),右端作为栈顶(右端动态变化,st[-1]为栈顶元素),栈操作在右端进行,则用append()作为进栈方法,pop()作为出栈方法。
以右端作为栈底(右端保持不动),左端作为栈顶(左端动态变化,st[0]为栈顶元素),栈操作在左端进行,则用appendleft()作为进栈方法,popleft()作为出栈方法。
from collections import deque #引用deque
st=deque()
st.append(1)
st.append(2)
st.append(3)
while len(st)>0:
print(st.pop(),end=' ') #输出:3 2 1
print()
4用双端队列实现普通队列
以左端作为队头(出队端,),右端作为队尾(进队端),则用popleft()作为出队方法,append()作为进队方法。在队列非空时qu[0]为队头元素,qu[-1]为队尾元素。
以右端作为队头(出队端),左端作为队尾(进队端),则用pop()作为出队方法,appendleft()作为进队方法。在队列非空时qu[-1]为队头元素,qu[0]为队尾元素。
from collections import deque
qu=deque()
qu.append(1)
qu.append(2)
qu.append(3)
while len(qu)>0:
print(qu.popleft(),end=' ') #输出:1 2 3
print()
2.6、优先队列
优先队列就是指定队列中元素的优先级,按优先级越大越优先出队,而普通队列中按进队的先后顺序出队,可以看成进队越早越优先。
优先队列按照根的大小分为大根堆和小根堆,大根堆的元素越大越优先出队(即元素越大优先级也越大),小根堆的元素越小越优先出队(即元素越小优先级也越大)。

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









