






一、什么是数据结构
1.1数据结构定义:
所涉及的数据元素的集合以及数据元素之间的关系,由数据元素之间的关系构成结构
1.2数据的逻辑结构:
由数据元素之间的逻辑关系构成,是数据结构在用户面前呈现的形式
1.3数据的存储结构:
指数据元素及其关系在计算机存储器中的存储方式
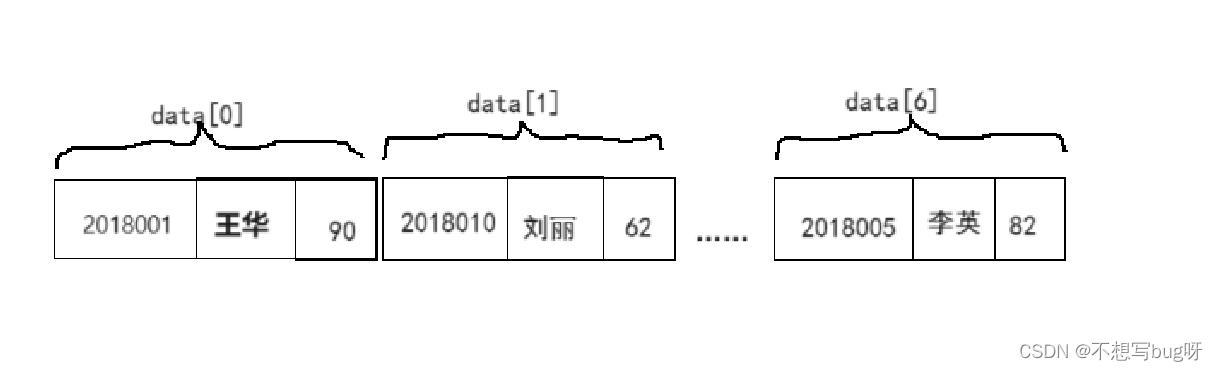
*设计高等数学成绩表的存储结构
(1)用python语言中的列表来存储高等数学成绩表
class Studl: #高等数学成绩顺序表的元素类型
def__int__(self,nol,namel,scorel): #构造函数
self.no=nol
self.name=namel
self.score=scoorel
def__repr__(self): #输出高等数学成绩元素的格式
return str(self.no)+"\t\t"+self.name+"\t\t"+str(self.score)
定义一个data列表(所有元素类型均为Stud1)存放高等数学成绩表,初始时为空,创建过程对应的成员函数Create():
def Create(self): #创建高等数学成绩顺序表
self.data.append (Studl (2018001,"王华",90) )
self.data.append (Studl (2018010,"刘丽",62) )
self.data.append (Studl (2018006,"陈明",54) )
self.data.append (Studl (2018009,"张强",95) )
self.data.append (Studl (2018007,"许兵",76) )
self.data.append (Studl (2018012,"李萍",88) )
self.data.append (Studl (2018005,"李英",82) )这种存储结构称为顺序存储结构(把逻辑上相邻的元素存储在物理位置上相邻的存储单元里)
*优点:节省存储空间
*缺点:初始空间大小难以确定,插入和删除操作需要移动较多的元素
(2)用python语言中的单链表来存储高等数学成绩表
class Stud2: #高等数学成绩单链表的节点类型
def__int__(self,nol,namel,scorel): #构造函数
self.no=nol
self.name=namel
self.score=scorel
self.next=None
def__repr__(self): #输出高等数学成绩节点的格式
return str(self.no)+"\t\t"+self.name+"\t\t"+str(self.score)单链表通过节点head来标识,初始时head为空
def Create(self):
self.head=Stud2(2018001,"王华",90)
p2=Stud2(2018010,"刘丽",62)
p3=Stud2(2018006,"陈明",54)
p4=Stud2(2018009,"张强",95)
p5=Stud2(2018007,"许兵",76)
p6=Stud2(2018012,"李萍",88)
p7=Stud2(2018005,"李英",82)
self.head.next=p2
p2.next=p3
p3.next=p4
p4.next=p5
p5.next=p6
p6.next=p7
p7.next=None这种存储结构特性是把数据元素存放在任意的存储单元中,这种存储单元可以是连续的,也可以是不连续的,通过指针域来反映数据元素的逻辑关系,称为链式存储结构
*优点:便于进行插入和删除,实现这些操作仅需修改相应结点的指针属性,不必移动节点;
*缺点:存储空间的利用率较低
1.4数据的运算
(1)在顺序存储结构中实现查找
def Findi(self,i): #查找序号为i的学生分数
assert i>=0 and i<len(self.data)
return self.data[i].score; #i正确时返回分数(2)在链式存储结构中查找
def Findi(self,i): #查找序号为i的学生分数
j=0
p=self.head #p指向首结点
while j<i and p!=None:
j+=1
p=p.next
assert i>=0 and p!=None
return p.score #i正确时返回分数
1.5数据结构和数据类型
*数据结构是指计算机处理数据元素的组织形式和相互关系
*数据类型是某种程序设计语言中已经实现的数据结构
*python中提供的数据类型包括布尔类型(bool)、数值类型(int和float)、字符串类型(str)和一些组合数据类型

二、算法及其描述
2.1、什么是算法
*算法是对特定问题的求解步骤的一种描述
*算法具有以下五个重要特性:

2.2、算法的描述
算法描述是指相对程序设计出的算法用一种方式进行详细的描述
算法描述的一般格式:
def 算法对应的函数或者方法名(形参列表):
#临时局部变量的定义
#实现输入参数到输出参数的操作
...
eg:求和问题:当n(输入参数)>=1时,s(操作结果)=1+2+3+...+n。由于python中的int是不可变类型,所以采用列表s作为输出参数,既s[0]表示操作结果
def Sum1(n,s):
if(n<1):
return False
s.append(n*(n+1)//2)
return True调用上述的算法:
n=-5
s=[]
if Sum1(n,s):
print("1到%d的和=%d" %(n,s[0]))
else:
print("参数n错误")三、python简介
3.1python的标准数据类型
1、数值类型:int ,float,bool,complex
*python内置的type()函数可以用来查询变量所指的对象类型
a,b,c,d = 20,5.5,True,4+3j
printf(type(a),type(b),type(c),type(d))*数值类型是不可变的数据类型
2、字符串类型
(1)字符串运算符
eg:a="Hello",b="Python"
+:字符串连接,a+b:"HelloPython"
*:重复输出字符串,a*2:"HelloHello"
[ ]:通过索引获取字符串中的字符,a[1]=e
[ : ]:截取字符串中的一部分,a[1:4]="ell"
in:成员运算符,包含返回True
not in:不包含返回True
(2)字符串输出格式化
(3)字符串内建函数
len(string):返回字符串长度
3、列表类型
(1)创建列表
city=[[1,"beijing"],[2,"shenzhen"],[3,"nanjing"],[4,"wuhan"]](2)访问列表中的值
print("city[0]: ",city[0]) #输出:city[0]:[1,'beijing']
print("city[-1]: ",city[-1]) #输出: city[-1]:[4,'wuhan'](3)列表脚本操作
list1=[1,2,3]
list2=[4,5,6]
list=list1+list2 #连接操作
print(list) #输出:[1,2,3,4,5,6]
list=list*3 #重复操作
print(list) #输出:[1,2,3,1,2,3]
for x in [1,2,3]:print(x,end=" ") #迭代操作,输出 1 2 3(4)列表的截取
print("city[1:3]: ",city[1:3]) #输出: city[1:3]: [[2,'shenzhen'],[3,'nanjing']](5)更新列表 append()函数添加列表项,remove()函数删除列表项
list[] #空列表
list.append(1) #使用append()添加元素
list.append(3)
print(list) #输出:[1,3]
print(id(list)) #输出:3814904
list[0]+=1 #修改第一个元素的值
print(list) #输出:[2,3]
print(id(list)) #输出:3814904
list+=[5] #添加一个元素
print(list) #输出:[2,3,5]
print(id(list)) #输出:3814904
ist.remove(3) #删除元素
print(list) #输出:[2,5]
print(id(list)) #输出:3814904
列表(list)中的元素的修改不会导致内存的改变,所以说列表是一种可变的数据类型
(6)列表的函数
len(list):返回列表中的元素个数
max(list):返回列表中元素的最大值
min(list):返回列表中元素的最小值
list(seq): 将可迭代对象seq转换为列表
(7)range()函数和enumerate()函数
range(start,stop,[,step])
#它产生[start,stop)范围内步长为step的整数对象,start默认为0,step默认为1enumerate(sequence,[start=0])
#sequence表示一个序列,start表示下标的起始位置
#例如:
a=[1,2,3]
for index,item in enumerate(a,5): #指出下标的起始位置为5
print(index,item)
#输出结果:
5 1
6 2
7 3(8)列表推导式
*列表推导式提供了从序列创建列表的简单途径,每个列表推导式都在for之后跟一个表达式,有零到多个for或者if子句,返回结果是一个根据表达式从其后的for和if上下文环境中生成出来的列表,如果希望表达式能推导出来一个元组,就必须使用括号,例如:
a=[2,4,6]
b=[3*x for x in a] #将列表a中的每个数值乘3得到新列表b
print(b) #输出:[6,12,18]
c=[3*x for x in a if x>3] #用if子句作为过滤器
print(c) #输出[12,18]
d=[[x,x* *2] for x in a]
print(d) #输出:[[2,4],[4,16],[6,36]]
v1=[2,4,6]
v2=[4,3,-9]
v3=[x*y for x in v1 for y in v2]
print(v3) #输出:[8,6,-18,16,12,-36,24,18,-54](9) 列表元素的排序
*使用序列类型函数sorted(list),返回一个对象,可以用作表达式,原来的list不变,生成一个新的排序好的list对象
*使用链表的内建函数list.sort(),不会返回对象,改变原有的list ,格式如下:
list.sort(func=None,key=None,reverse=False)
#其中的key用来指进行比较的元素,,reverse指出排序规则,reverse=True为降序,reverse=False为升序
list=[2,5,8,9,3]
list.sort() #升序排序
print(list) #输出:[2,3,5,8,9]
list.sort(reverse=True) #降序排序
print(list) #输出:[9,8,5,3,2]4、元组类型
元组使用圆括号,只需要在括号中添加元素,使用逗号隔开
5、字典类型
字典是另一种可变的数据类型,字典中的每个元素是键值(每个键值元素由key:value 构成,其中key为键,value是对应的值),元素之间用逗号隔开,整个字典包括在{ }中
(1)创建字典
dict1={}
print(dict1) #输出:{}
dict2={1:"beijing",2:"shenzhen",3:"nanjing",4:"wuhan"}
print(dict2) #输出:{1:'beijing',2:'shenzhen',3:'nanjing',4:'wuhan'}(2)访问字典里的值
print("dict2[2]: %s" %(dict2[2])) #输出:shenzhen(3)修改字典
*在一个字典中不允许键重复,若同一个键被赋值两次,后者会覆盖前者
dict2={1:"beijing",2:"shenzhen",3:"nanjing",4:"wuhan"}
dict2[3]="chengdu" #更新
print(dict2) #输出:{1:'beijing',2:'shenzhen',3:'chengdu',4:'wuhan'}(4)删除字典元素
*可以使用del()函数删除指定键的元素
(5)字典的内置函数
*len(dict):返回字典中元素的个数
*str(dict):输出字典,以可打印的字符串表示
(6)字典内置方法
dict={1:"王华",2:"李明",3:"张斌"}
print(dict)
print("序号2的姓名是:%s" %(dict.get(2))) #输出:序号2的姓名是:李明
tuple=dict.items() #以列表返回可遍历的(键,值)元组数组
print(tuple) #输出:dict_items([(1,'王华'),(2,'李明'),(3,'张斌')])
for i,j in tuple: #输出3行
print(i,":\t",j)
list1=list(dict.keys())
print(list1) #输出:[1,2,3]
list2=list(dict.values())
print(list2) #输出:['王华','李明','张斌']
dict.popitem() #随机返回并删除字典中的最后一对键和值
print(dict) #输出:[1:'王华',2:'李明'](7)字典遍历
*在字典中遍历的时候,关键字和对应的值可以使用items()方法同时解读出来
d={'mary':90,'john':80,'smith':54}
for name,v in d.items():
print(name,v)
#输出结果如下
mary 90
john 80
smith 546、集合类型
*集合是一个无序的不重复元素序列,基本功能包括关系测试和消除重复元素
(1)创建集合
#parame={value01,value02,...}
#set(value)
a={'a','b','c','d','a'}
b=set("cabdb")
print(a) #去重,输出{'c','d','a','b'}
print(len(a)) #输出:4
print(b) #去重,输出{'c','d','a','b'}
print(len(b)) #输出:4(2)判断元素是否在集合中
x in s
(3)集合内置方法
a={1,2,5,3,9}
b=set([2,8,3,7,6])
print(a)
print(b)
a.add(4)
print(a) #输出:{1,2,3,4,5,9}
c=a.difference(b)
print(c) #输出:{1,4,5,9}
print(a.isdisjoint(b)) #输出 False #(判断两个集合是否包含相同的元素)
print(a.issubest({1,3,4})) #输出:False #判断指定集合是否为该方法参数集合的子集3.2列表的复制
1、直接复制
2、列表的深复制
列表的深复制通过调用copy模块的deepcopy()实现的,b=copy,deepcopy(a),则无论a有多少层,得到的新列表b都是和原来无关的。
import copy #导入copy模块
a=[1,[1,2,3],4]
b=copy.deepcopy(a)
print(a)
print(b)
b[0]=3
b[1][0]=3
print(a) #输出:[1,[1,2,3],4]
print(b) #输出:[3,[3,2,3],4]3、列表的浅复制
a=[1,[1,2,3],4]
b=a.copy()
print(a)
print(b)
b[0]=3
b[1][0]=3
print(a) #输出:[1,[3,2,3],4]
print(b) #输出:[3,[3,2,3],4]
对于a的一层是实现了深复制,但对于嵌套的列表仍然是是浅复制,内层的列表保存的是地址,在复制过去的时候是把地址复制过去了,因此打印的时候 a中的元素也会跟着改变
3.3输入、输出和文件操作
1、 输入
变量名=input("提示信息")
2、输出
print(objects,sep='',end='\n',file=sys.studout)3、文件操作
实现文件操作,必须先用open()函数打开一个文件,
open(name[,mode])3.4python程序设计
1、定义类
类是面向对象的基础,在python中使用class关键字来定义类,类主要由属性和方法组成
class 类名(基类列表):
属性
方法2、定义属性
属性分为类属性和实例属性,类属性在整个实例化的对象中是公用的,一般类属性通过类对象引用,而实例属性是对于每个实例都独有的数据;类属性的引用方式是“类名称.类属性名称”,其他属性的引用方式是“self.属性名称”
属性又分为公有属性和私有属性,私有属性名称以(__)开头
Class A:
x=2 #类属性x
__y=0 #私有类属性y
def__init__(self,p): #构造方法
self.z=p #实例属性z
self.__w=0 #私有实例属性w
def add(self):
self.__y+=10
self.__w+=20
def disp(self):
print(A.x,self.__y,self.z,self.__w)
#主程序
A.x+=1 #修改类属性
a=A(10)
a.add()
a.disp() #输出:3 10 10 20
b=A("Bye")
b.disp() #输出:3 0 Bye 0
3、定义方法
在类的内部使用def关键字来定义一个方法,类方法必须包含参数self ,且为第一个参数,self代表的是类的实例(当前对象的地址),而self.class指向类
方法也分为公有方法和私有方法,私有方法名称以两个下划线(__)开头,私有方法不能在类的外部调用
python中一些专有方法:
__init__():称为构造方法,在类实例化时会自动调用。该方法可以有参数,由于在实例化时给对象属性赋值。
__del__:构析函数,释放对象时使用
__repr__:输出时实现转换
__setitem__:按照索引赋值
__getitem__:按照索引获取值__len__:获得长度
__cmp__:比较运算
__call__:函数调用
__add__,__sub__,__mul__,__truediv__,__mod__,__pow__:加减乘除,求余,乘方
4、定义对象
(1)类对象:定义的类本身就是一个以该类名称为名称的对象,称为类对象,所以类对象与类名称相同。可以使用“类对象.类属性”的方式引用类属性,不能通过类对象引用其他属性和调用类的其他方法。
Class B: #定义类B,B本身是一个类对象
n=1 #定义类属性
def__init__(self,p): #构造方法
self.m=p #定义实例属性
def disp(self):
print(self.m)
#主程序
print(B,n) #正确,输出1
print(B,m) #错误,提示类对象B没有m属性
B.disp() #错误,提示调用disp需要一个实例对象(2)实例对象
实例对象是类对象实例化的产物。
定义实例对象一般格式:实例对象名称=类名称([参数列表])。
通过实例对象可以引用类的所有非私有属性和调用非私有方法,对于实例对象而言,类属性是不存在的。
5、方法的类传递
(1)参数不可变数据类型
#求和程序
Class A:
def Sum(self,n,s):
s=n*(n+1)//2
#主程序
a=A()
s=0
a.Sum(5,s)
print(s) #输出0
在调用a.Sum()方法时实参是数值类型,为不可变数据类型,因此执行后不会回传给实参,所以输出结果为0
(2)参数可变数据类型
Class A:
def Sum(self,n,s):
s.append(n*(n+1)//2)
#主程序
a=A()
s=[]
a.Sum(5,s)
print(s[0]) #输出15
参数为可变类型时,形参的地址不变(仅仅改变该实例的元素不会导致地址改变),结果会回传给实参对象
若形参的地址发生改变,结果不会回传给实参对象
class A:
def Sum(self,n,s):
s=[n*(n+1)//2]
#主程序
a=A()
s=[]
a.Sum(5,s)
print(s[0]) #错误:提示超出列表s索引
6、继承
(1)单继承
class 子类名称(父类名称):
语句1
...
语句n
class People: #定义父类
def __init__(self,n,a,w): #构造方法
self.name=n
self.age=a
self.__weight=w
def dispp(self):
print("我是%s: 体重是%d公斤," %(self.name,self.__weight),end='')
class Student(People): #定义子类
def __init__(self,n,a,w,g): #子类的构造方法
People.__init__(self,n,a,w) #调用父类的构造方法
self.grade=g
def disps(self):
super().dispp() #调用父类的方法
print("年龄是%d岁,我在读%d年级" %(self.age,self.grade))
#主程序
s=Student('John',10,50,3)
s.disps() #输出我是John: 体重是50公斤,年龄是10岁,我在读3年级(2)多继承
class 子类名称(父类名称1,…,父类名称m):
语句1
…
语句n
class A:
def disp(self):
print("A")
class B(A):
def disp(self):
print("进入B")
super().disp() #调用类C的disp()
print("退出B")
class C(A):
def disp(self):
print("进入C")
super().disp() #调用类A的disp()
print("退出C")
class D(B,C):
def disp(self):
print("进入D")
super().disp() #调用类B的disp()
print("退出D")
#主程序
print(D.__mro__)
d=D()
d.disp()
#输出结果:
进入D
进入B
进入C
A
退出C
退出B
退出D
7、异常处理:
最基本的异常处理语句
try:
#被检测的语句
except 异常类:
#处理异常的语句
在执行以下程序时检测到异常
try:
x=4/0
except ZeroDivisionError:
print("除0错误")def openfile(name):
try:
f=open(name,'r')
except:
raise Exception('') #raise用于异常抛出
print(name+"文件成功打开")
f.close()
def main():
name="aaa"
try:
openfile(name)
except:
print(name+"文件不存在")
#主程序
main()
8、迭代器和生成器
(1)迭代器:迭代器有两个基本的函数即iter()和next()。
iter()函数用来建立可迭代对象的迭代器对象。
next()函数返回迭代器的下一个元素,如果结束迭代,则抛出StopIteration异常。
a=[1,2,3,4,5] #定义可迭代对象a
it=iter(a) #建立列表a的迭代器对象it
while True: #循环
try:
x=next(it) #获得下一个元素值
print(x)
except StopIteration:
break #迭代结束退出循环
(2)生成器:在Python中使用了一个或者多个yield的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到yield时函数会暂停并保存当前所有的运行信息,返回yield的值, 并在下一次执行next()方法时从当前位置继续运行。
def revstr(str): #生成器
n=len(str)
for i in range(n-1,-1,-1):
yield str[i]
#主程序
it=revstr("hello") #产生迭代器it
while True: #输出:olleh
x=next(it,'#')
if x=='#':break
print(x,end='')
3.5、python的作用域和垃圾回收
1、变量的作用域:
若在函数内部定义全局变量,则可以使用global关键字来声明变量为全局变量:
def func():
global a #指定a为全局变量
print(a) #输出全局变量a即输出1
#主程序
a=1 #定义全局变量a
func()
print(a) #输出全局变量a即输出1
若在当前作用域中引入新的变量,则同时屏蔽外层作用域中的同名变量
a=1 #定义全局变量a
def func():
a=2 #定义局部变量a,屏蔽全局变量a
print(a) #输出局部变量a即2
#主程序
func()
print(a) #输出全局变量a即1
2、垃圾回收
Python中一切皆为对象,变量本质上都是对象的一个指针。
当一个对象不再调用的时候,也就是当这个对象的引用计数为0的时候(可以简单的理解为没有任何变量再指向它),说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。
def func():
global a
a=[1,2,3]
b=a
print(b) #输出:[1,2,3]
b.append(4) #让列表变为[1,2,3,4],局部变量b超出了作用域,列表引用计数-1,但不是0,因此不会被回收
#主程序
func()
print(a) #输出:[1,2,3,4] #全局变量a超出了作用域,列表[1,2,3,4]引用计数再-1成为0,此时被回收四、算法分析
4.1、算法设计目标:
正确性。 可使用性。 可读性。 健壮性。 高时间性能与低存储量需求。
4.2、算法时间性能分析:
1、分析算法的时间复杂度:
一个算法是由控制结构(顺序、分支和循环三种)和原操作(指固有数据类型的操作,如+、-、*、/、++和--等)构成的。算法执行时间取决于两者的综合效果。
在一个算法中,执行原操作的次数越少,其执行时间也就相对地越少;执行原操作次数越多,其执行时间也就相对地越多。 算法中所有原操作的执行次数称为算法频度,这样一个算法的执行时间可以由算法频度来计量。
(1)计算算法频度:
求两个n阶方阵的相加
def matrixadd(A,B,C,n):
for i in range(n): #语句① n+1
for j in range(n): #语句② n*(n+1)
C[i].append(A[i][j]+B[i][j]) #语句③ n^2
(2)采用时间复杂度表示:
算法中执行时间T(n)是问题规模n的某个函数f(n),记作: T(n) = O(f(n))
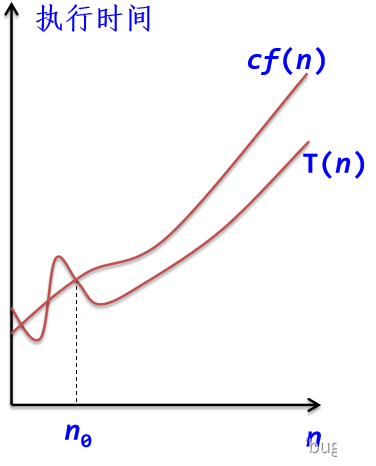
“O”的形式定义为: T(n) = O(f(n))表示存在一个正的常数c,使得当n≥n0时都满足: |T(n)|≤c|f(n)|
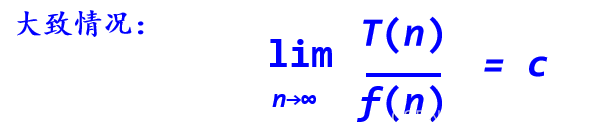
(3)简化算法的时间复杂度分析
分析以下算法的时间复杂度:
def fun(n):
s=0
for i in range(n+1):
for j in range(i+1):
for k in range(j):
s+=1
return s
算法频度为:

4.3、算法空间性能分析
一个算法的存储量包括形参所占空间和临时变量所占空间。在对算法进行存储空间分析时,只考察临时变量所占空间。
空间复杂度是对一个算法在运行过程中临时占用的存储空间大小的量度,一般也作为问题规模n的函数,以数量级形式给出,记作:S(n)=O(g(n))。 其中“O”的含义与时间复杂度分析中的相同。
def Max(a,n):
maxi=0
for i in range(1,n):
if a[i]>a[maxi]:
maxi=i
return a[maxi]
#方法体内分配的变量空间为临时空间,不计形参占用的空间,这里的仅计i、maxi变量的空间。
def matrixadd(A,B,C,n):
for i in range(n): #语句①
for j in range(n): #语句②
C[i].append(A[i][j]+B[i][j]) #语句③
#空间复杂度为O(1)
def fun(n):
s=0
for i in range(n+1):
for j in range(i+1):
for k in range(j):
s+=1
return s
def fun(a,n,k):
i=0
while i<n and a[i]!=k:
i+=1
return i
4.4、数据结构的目标:
存储结构对算法的影响主要在两方面:
存储结构的存储能力
存储结构应与所选择的算法相适应
*构造集合ADT Set,假设其中元素为整型,遵循标准数学定义,基本运算包括: 求集合长度、求第i个元素、判断一个元素是否属于集合、向集合中添加一个元素、从集合中删除一个元素、复制集合和输出集合中所有元素。 另外增加3个集合运算: 求两个集合并Union、集合交Inter和集合差Diff。
ADT Set #集合的抽象数据类型
{ 数据对象:
data={di | 0≤i≤size-1 } #存放集合中元素
数据关系:
无
基本运算:
getsize() #返回集合的长度
get(int i) #返回集合的第i个元素
IsIn(E e) #判断e是否在集合中
add(E e) #将元素e添加到集合中
delete(E e) #从集合中删除元素e
Copy(s) #返回当前集合的复制集合
display() #输出集合中的元素
Union(Set s2) #求s3=s1∪s2 (s1为当前集合)
Inter(Set s2) #求s3=s1∩s2 (s1为当前集合)
Diff(Set s2) #求s3=s1-s2 (s1为当前集合)
} ADT Set
设计存储结构:
class Set: #集合类
MaxSize=100 #集合的最多元素个数
def __init__(self): #构造方法
self.data=[None]*Set.MaxSize #data存放集合元素
self.size=0 #size为集合的长度
设计运算算法:
def getsize(self): #返回集合的长度
return self.size;
def get(self,i): #返回集合的第i个元素
assert i>=0 and i<self.size #检测参数i的正确性
return self.data[i]
def IsIn(self,e): #判断e是否在集合中
for i in range(self.size):
if self.data[i]==e:
return True
return False
def add(self,e): #将元素e添加到集合中
if not self.IsIn(e): #元素e不在集合中
self.data[self.size]=e
self.size+=1
def delete(self,e): #从集合中删除元素e
i=0
while i<self.size and self.data[i]!=e:
i+=1
if i>=self.size:
return #未找到元素e直接返回
for j in range(i+1,self.size): #找到元素e后通过移动实现删除
self.data[j-1]=self.data[j]
self.size-=1
def Copy(self): #返回当前集合的复制集合
s1=Set()
s1.data=self.data
s1.size=self.size
return s1
def display(self): #输出集合中的元素
for i in range(self.size):
print(self.data[i],end=' ')
print()
def Union(self,s2): #求s3=s1∪s2(s1为当前集合)
s3=self.Copy() #将当前集合复制到s3
for i in range(s2.getsize()): #将s2中不在当前集合中的元素添加到s3中
e=s2.get(i)
if not self.IsIn(e):
s3.add(e)
return s3 #返回s3
def Inter(self,s2): #求s3=s1∩s2(s1为当前集合)
s3=Set()
for i in range(self.size): #将s1中出现在s2中的元素复制到s3中
e=self.data[i]
if s2.IsIn(e):
s3.add(e)
return s3 #返回s3
def Diff(self,s2): #求s3=s1-s2(s1为当前集合)
s3=Set()
for i in range(self.size): #将s1中不出现在s2中的元素复制到s3中
e=self.data[i]
if not s2.IsIn(e):
s3.add(e)
return s3 #返回s3
设计主程序:
s1=Set()
s1.add(1)
s1.add(4)
s1.add(2)
s1.add(6)
s1.add(8)
print("集合s1:",end=' '),s1.display()
print("s1的长度为%d" %(s1.getsize()))
s2=Set()
s2.add(2)
s2.add(5)
s2.add(3)
s2.add(6)
print("集合s2:",end=' '),s2.display()
print("集合s1和s2的并集->s3")
s3=s1.Union(s2);
print("集合s3:",end=' '),s3.display()
print("集合s1和s2的差集->s4")
s4=s1.Diff(s2)
print("集合s4:",end=' '),s4.display()
print("集合s1和s2的交集->s5")
s5=s1.Inter(s2)
print("集合s5:",end=' '),s5.display()
程序执行结果:
















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









