







- 自动拆装箱:java中数据类型分为两种 : 基本数据类型 引用数据类型(对象)
在 java程序中所有的数据都需要当做对象来处理,针对8种基本数据类型提供了包装类,如下:
int –> Integer
byte –> Byte
short –> Short
long –> Long
char –> Character
double –> Double
float –> Float
boolean –> Boolean
jdk5以前基本数据类型和包装类之间需要互转: 基本—引用 Integer x = new Integer(x); 引用—基本 int num = x.intValue();
1)、Integer x = 1; x = x + 1; 经历了什么过程?装箱 拆箱 装箱;
2)、为了优化,虚拟机为包装类提供了缓冲池,Integer池的大小 -128~127 一个字节的大小;
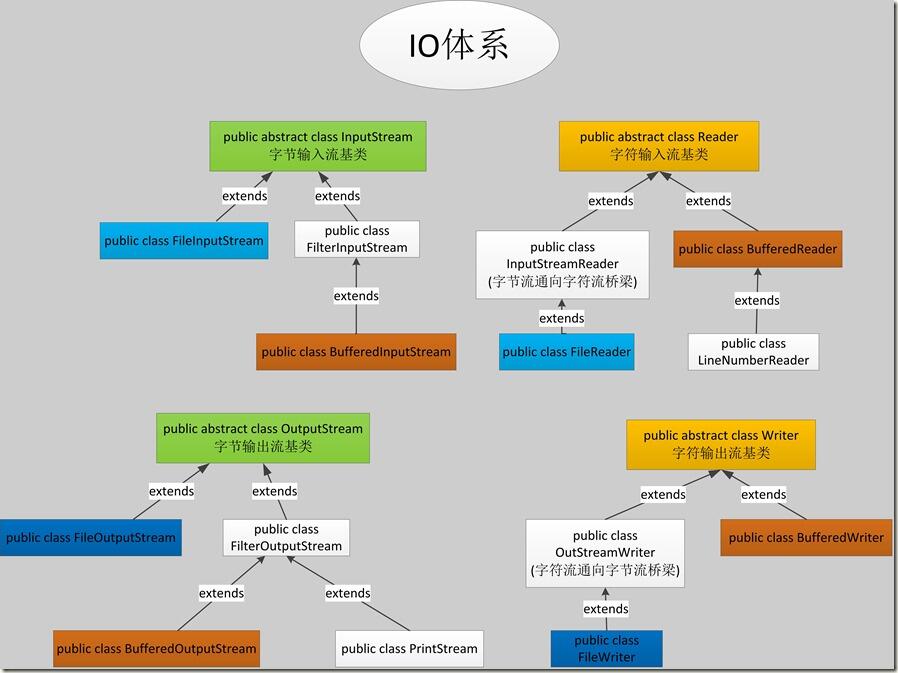
3)、String池:Java为了优化字符串操作 提供了一个缓冲池; - 字节流:
InputStream:是表示字节输入流的所有类的超类。
|— FileInputStream:从文件系统中的某个文件中获得输入字节。哪些文件可用取决于主机环境。FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。
|— FilterInputStream:包含其他一些输入流,它将这些流用作其基本数据源,它可以直接传输数据或提供一些额外的功能。
BufferedInputStream:该类实现缓冲的输入流。
OutputStream:此抽象类是表示输出字节流的所有类的超类。
|— FileOutputStream:文件输出流是用于将数据写入 File 或 FileDescriptor 的输出流。
|— FilterOutputStream:此类是过滤输出流的所有类的超类。
|— BufferedOutputStream:该类实现缓冲的输出流。
|— PrintStream:
|— DataOutputStream - 字符流:
Reader:用于读取字符流的抽象类。子类必须实现的方法只有 read(char[], int, int) 和 close()。
|—BufferedReader:从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。 可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
|—LineNumberReader:跟踪行号的缓冲字符输入流。此类定义了方法 setLineNumber(int) 和 getLineNumber(),它们可分别用于设置和获取当前行号。
|—InputStreamReader:是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。
|—FileReader:用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。 - Writer:写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。
|—BufferedWriter:将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
|—OutputStreamWriter:是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集。
|—FileWriter:用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。
|—PrintWriter - BufferedWriter:是给字符输出流提高效率用的,那就意味着,缓冲区对象建立时,必须要先有流对象。明确要提高具体的流对象的效率。
FileWriter fw = new FileWriter("bufdemo.txt");
BufferedWriter bufw = new BufferedWriter(fw);//让缓冲区和指定流相关联。
for(int x=0; x<4; x++){
bufw.write(x+"abc");
bufw.newLine(); //写入一个换行符,这个换行符可以依据平台的不同写入不同的换行符。
bufw.flush();//对缓冲区进行刷新,可以让数据到目的地中。
}
bufw.close();//关闭缓冲区,其实就是在关闭具体的流。BufferedReader:
FileReader fr = new FileReader("bufdemo.txt");
BufferedReader bufr = new BufferedReader(fr);
String line = null;
while((line=bufr.readLine())!=null){ //readLine方法返回的时候是不带换行符的。
System.out.println(line);
}
bufr.close();- 只要一读取键盘录入,就用这句话。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));//
输出到控制台
String line = null;
while((line=bufr.readLine())!=null){
if("over".equals(line))
break;
bufw.write(line.toUpperCase());//将输入的字符转成大写字符输出
bufw.newLine();
bufw.flush();
}
bufw.close();
bufr.close();- 想要操作文本文件,必须要进行编码转换,而编码转换动作转换流都完成了。所以操作文件的流对象只要继承自转换流就可以读取一个字符了。
但是子类有一个局限性,就是子类中使用的编码是固定的,是本机默认的编码表,对于简体中文版的系统默认码表是GBK。 FileReader fr = new FileReader(“a.txt”);
InputStreamReader isr = new InputStreamReader(new FileInputStream(“a.txt”),”gbk”); 以上两句代码功能一致,
如果仅仅使用平台默认码表,就使用FileReader fr = new FileReader(“a.txt”); //因为简化。 如果需要制定码表,必须用转换流。
转换流 = 字节流+编码表。
转换流的子类File = 字节流 + 默认编码表。
凡是操作设备上的文本数据,涉及编码转换,必须使用转换流。 - Java.util.Properties:一个可以将键值进行持久化存储的对象。Map–Hashtable
的子类。
Map
|–Hashtable
|–Properties:用于属性配置文件,键和值都是字符串类型。
特点:1:可以持久化存储数据。2:键值都是字符串。3:一般用于配置文件。
|– load():将流中的数据加载进集合。
原理:其实就是将读取流和指定文件相关联,并读取一行数据,因为数据是规则的key=value,所以获取一行后,通过 = 对该行数据进行切割,左边就是键,右边就是值,将键、值存储到properties集合中。
|– store():写入各个项后,刷新输出流。
|– list():将集合的键值数据列出到指定的目的地。 - 反射
反射技术:其实就是动态加载一个指定的类,并获取该类中的所有的内容。而且将字节码文件封装成对象,并将字节码文件中的内容都封装成对象,这样便于操作这些成员。
简单说:反射技术可以对一个类进行解剖。 反射的好处:大大的增强了程序的扩展性。
反射的基本步骤:
1、获得Class对象,就是获取到指定的名称的字节码文件对象。
2、实例化对象,获得类的属性、方法或构造函数。
3、访问属性、调用方法、调用构造函数创建对象。
获取这个Class对象,有三种方式:
1:通过每个对象都具备的方法getClass来获取。弊端:必须要创建该类对象,才可以调用getClass方法。
2:每一个数据类型(基本数据类型和引用数据类型)都有一个静态的属性class。弊端:必须要先明确该类。
前两种方式不利于程序的扩展,因为都需要在程序使用具体的类来完成。
3:使用的Class类中的方法,静态的forName方法。
指定什么类名,就获取什么类字节码文件对象,这种方式的扩展性最强,只要将类名的字符串传入即可。 - // 1. 根据给定的类名来获得 用于类加载
String classname = “cn.itcast.reflect.Person”;// 来自配置文件
Class clazz = Class.forName(classname);// 此对象代表Person.class
// 2. 如果拿到了对象,不知道是什么类型 用于获得对象的类型
Object obj = new Person();
Class clazz1 = obj.getClass();// 获得对象具体的类型
// 3. 如果是明确地获得某个类的Class对象 主要用于传参
Class clazz2 = Person.class; - 反射的用法:
1)、需要获得java类的各个组成部分,首先需要获得类的Class对象,获得Class对象的三种方式:
Class.forName(classname) 用于做类加载
obj.getClass() 用于获得对象的类型
类名.class 用于获得指定的类型,传参用
2)、反射类的成员方法:
Class clazz = Person.class;
Method method = clazz.getMethod(methodName, new Class[]{paramClazz1, paramClazz2});
method.invoke();
3)、反射类的构造函数:
Constructor con = clazz.getConstructor(new Class[]{paramClazz1, paramClazz2,…}) con.newInstance(params…)
4)、反射类的属性:
Field field = clazz.getField(fieldName);
field.setAccessible(true);
field.setObject(value);
获取了字节码文件对象后,最终都需要创建指定类的对象:
创建对象的两种方式(其实就是对象在进行实例化时的初始化方式):
1,调用空参数的构造函数:使用了Class类中的newInstance()方法。
2,调用带参数的构造函数:先要获取指定参数列表的构造函数对象,然后通过该构造函数的对象的newInstance(实际参数) 进行对象的初始化。
综上所述,第二种方式,必须要先明确具体的构造函数的参数类型,不便于扩展。
所以一般情况下,被反射的类,内部通常都会提供一个公有的空参数的构造函数。 - //获取一个带参数的构造器。
Constructor constructor = clazz.getConstructor(String.class,int.class);
//想要对对象进行初始化,使用构造器的方法newInstance();
Object obj = constructor.newInstance("zhagnsan",30);
//获取所有构造器。
Constructor[] constructors = clazz.getConstructors();//只包含公共的
constructors = clazz.getDeclaredConstructors();//包含私有的
for(Constructor con : constructors) { System.out.println(con);
}
} 














 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









