









1.常用的非线性激活函数: sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全链接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下
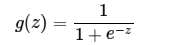
其中z是一个线性组合,比如z可以等于:b +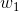
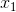
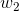
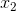
因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):
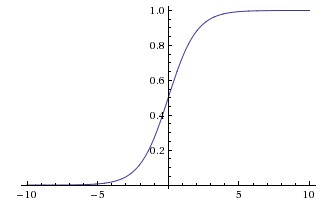
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常大的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)

z = b +
- 如果
- 如果
- 如果
换言之,只有
2.什么是卷积: 对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
3.两大机制:
- 左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
- 打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来。当然,即便是看局部,针对局部里的信息人类双眼也是有偏重、偏好的。比如看美女,对脸、胸、腿是重点关注,所以这3个输入的权重相对较大。
- 与此同时,数据窗口滑动,导致输入在变化,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
- 再打个比方,某人环游全世界,所看到的信息在变,但采集信息的双眼不变。btw,不同人的双眼 看同一个局部信息 所感受到的不同,即一千个读者有一千个哈姆雷特,所以不同的滤波器 就像不同的双眼,不同的人有着不同的反馈结果。
附经典动图理解多通道卷积:
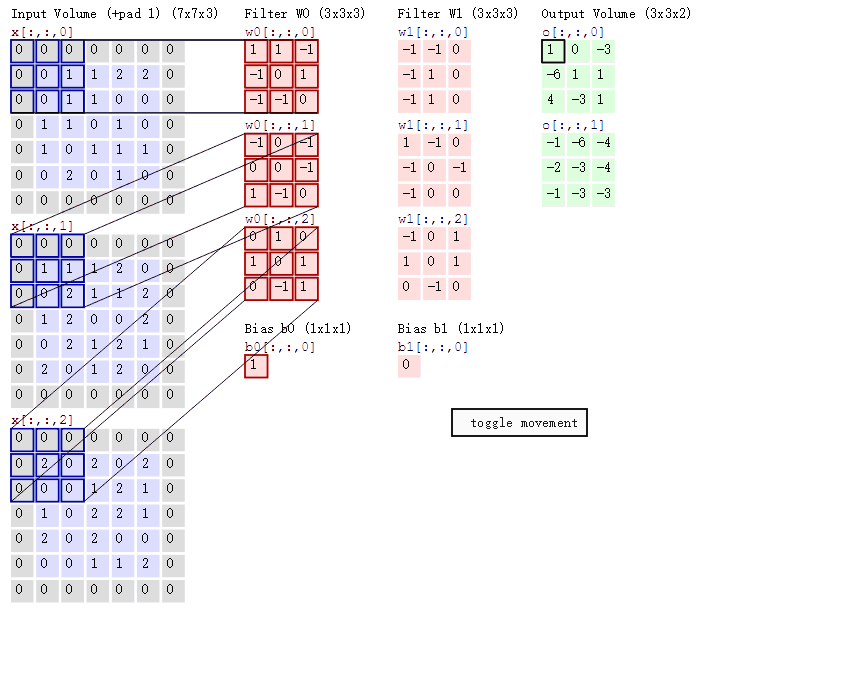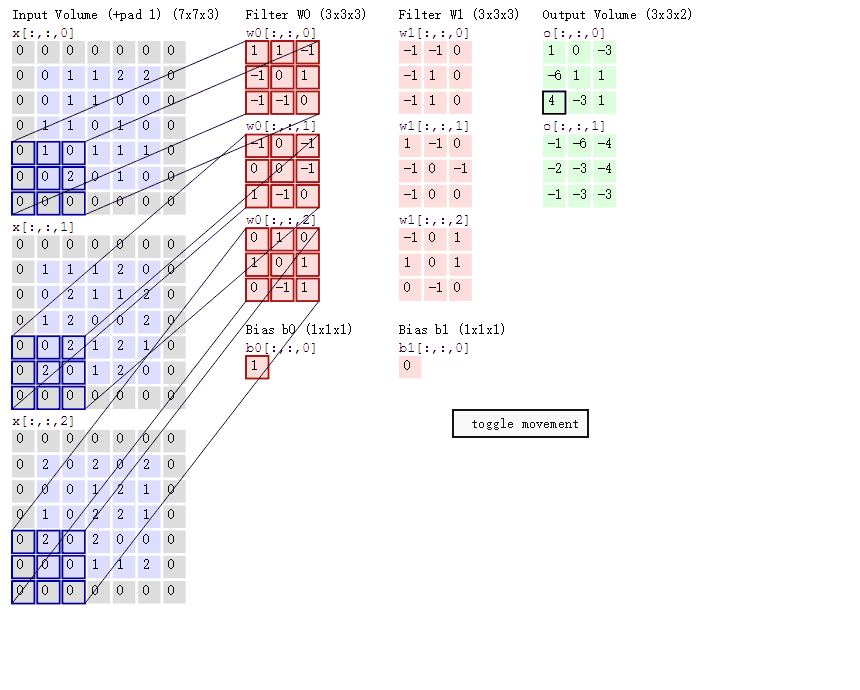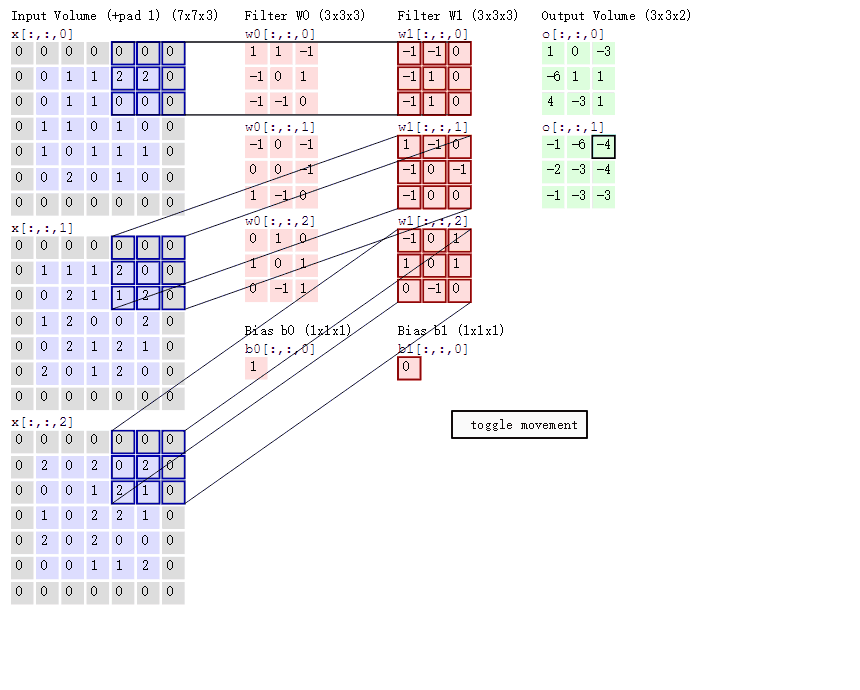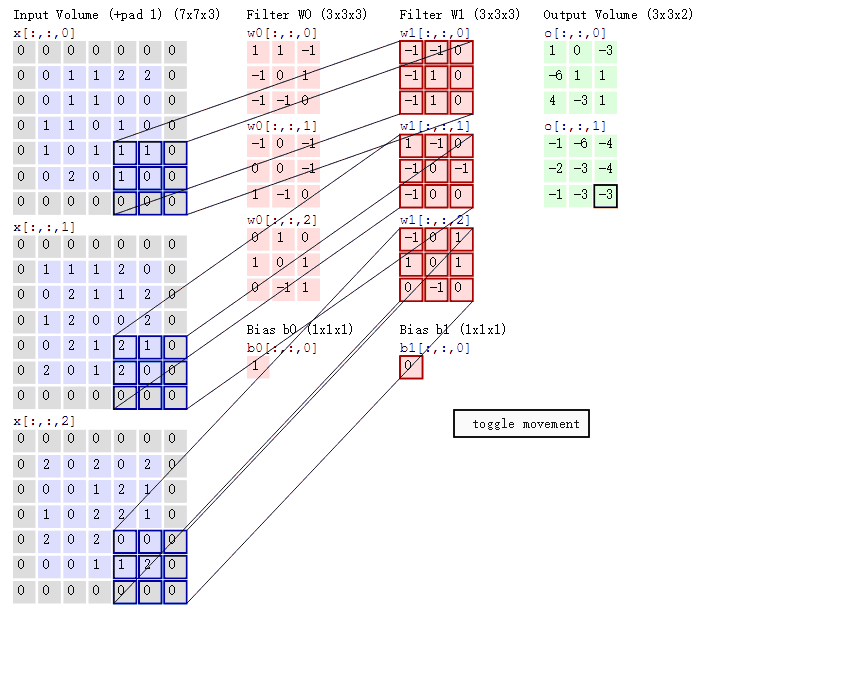
4.cnn层级结构:
- 最左边是数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间是
- CONV:卷积计算层,线性乘积求和。
- RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。(特征数大大减少)
最右边是
- FC:全连接层
参考原博客:http://blog.csdn.net/v_july_v/article/details/51812459#comments















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









