







书接上回,现在已经得到了数据了,接下来就是解析了
一、json.loads()模块
返回的数据都是以字符串的格式,这对于我们对其进行分析和解析使用是非常不利的,毕竟没人想要用正则来匹配这么多字符。
在python的内置模块中,有一个json模块可以帮助我们将response.text由字符串转为json格式
json_text = json.loads(response.text)然后我们将每一次得到的数据放到支持json格式化的网页上,进行解析分析。
二、用json规则提取我们需要的信息
(一)解析结果
使用解析工具,每一次请求我们就得到了类似
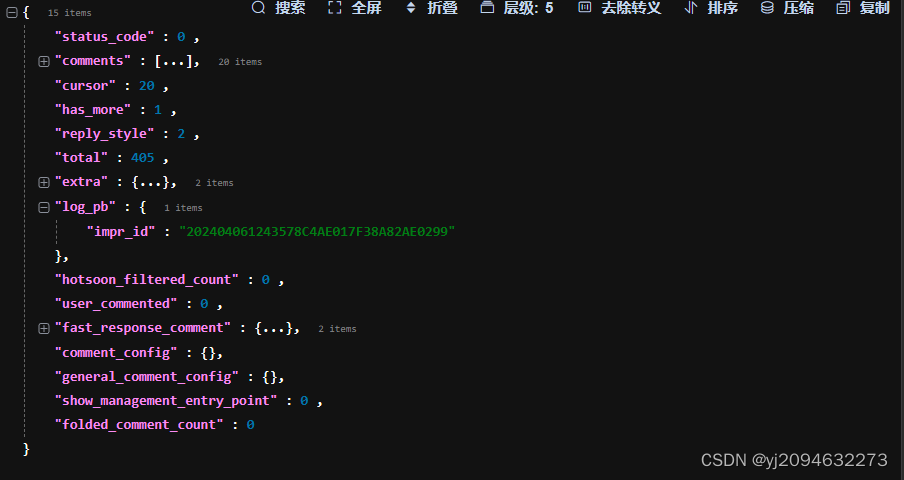
这样格式的数据内容,然后就是分析这些内容在浏览器的渲染出的结果是什么,并进行提取。
(二)提取评论
1.其实找出每个对象它所对应的位置就是重复的对比以及用变量名去猜测以及对应。
2.在本例中评论就是在comments中,所以我们直接
comments = json_text["comments"]得到的内容就是请求得到的评论内容以及一些其他属性,继续进行json格式化分析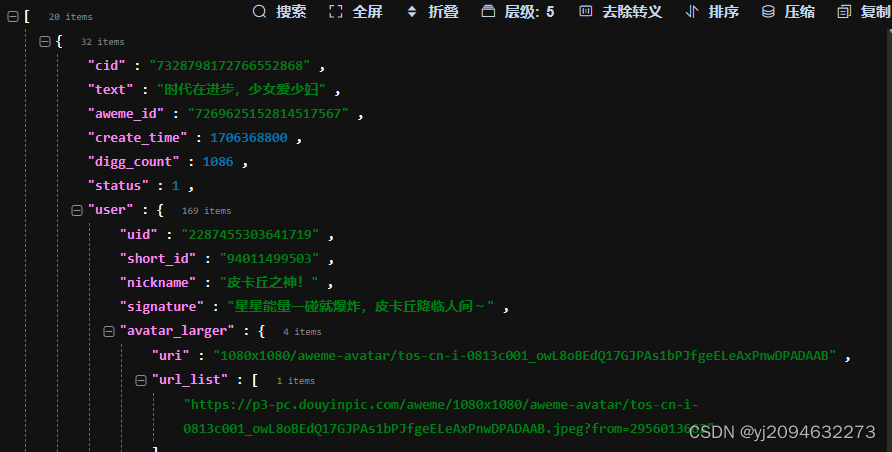
可以看到其实就是一个comments列表,只需要对这个列表进行循环处理其中的每一个字字典,就可以得到想要的评论和其他数据内容了。就类似于上述的取到comments的步骤一样,这里不做演示了哈!但是注意cid这个属性内容,下一篇会用到。















 1972
1972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









