







在视频或电话会议中,本地用户的声音在被本地麦克风采集后,通过系统传到远端,通过远端的扬声器播放,此时远端麦克风不可避免地会采集到扬声器播放的声音,又通过系统传回本地,并通过本地扬声器播放出来,本地用户就通过本地扬声器听到了自己的声音,这明显降低了会议通信质量。
为了提高语音的质量,就必须进行回声消除。当参考信号已知时,归一化最小均方(Normalized Least Mean Square,NLMS)算法能很好消除回声,它由最小均方算法扩展而来。
1 NLMS算法原理
回声消除系统基本结构如图1所示。
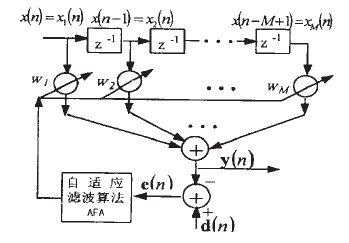
图1 回声消除系统基本结构
设置自适应滤波器系数w的所有初始值为0,即w(0) = 0,其长度为M。对输入信号进行采样,每次迭代取M个数据进行处理,输入矢量为
x(n) = [x1(n) x2(n) … xM(n)]T = [x(n)x(n-1) … x(n-M+1)]T
加权矢量为
w = [w1 w2… w3]
系统输出y(n)为
y(n) = wx(n)
y(n)相对于期望信号d(n)的误差为
e(n) = d(n) – y(n) = d(n) -wx(n)
运用最小均方误差准则,就是求使得E[|e(n)|^2]最小时的w,因为是通过对其求导并令其等于0求得的,而|e(n)|在最小点不可导,所以使用的是|e(n)|^2。对于LMS算法,其滤波器系数迭代公式为
w(n+1) = w(n) + 2µe(n)x(n)
其中µ是步长因子,0 < µ < 1/ xT(n)x(n),在LMS算法中其值是固定的,因而收敛速度较慢。
在LMS的基础上,用可变的步长因子代替固定的步长因子,就得到了NLMS算法,其迭代方程为
w(n+1) = w(n) + µ(n)e(n)x(n)=w(n) +ηe(n)x(n)/(δ+xT(n)x(n))
其中η是修正的步长常量,0 < η < 2,δ为一个较小的整数,一般取0.0001,防止输入数据矢量x(n)的内积过小使得µ(n)过大而引起稳定性能下降。NLMS算法的收敛速度较快,效果较LMS算法好。
2 性能仿真
用matlab编写程序仿真算法性能,分别对比NLMS算法与LMS算法的性能和不同步长参数η下NLMS算法的性能。代码如下:
clear all;
close all;
clc;
snr=20;
order=8;
Hn =[0.8783 -0.5806 0.6537 -0.3223 0.6577 -0.0582 0.2895 -0.2710 0.1278 -0.1508 0.0238 -0.1814 0.2519 -0.0396 0.0423 -0.0152 0.1664 -0.0245 0.1463 -0.0770 0.1304 -0.0148 0.0054 -0.0381 0.0374 -0.0329 0.0313 -0.0253 0.0552 -0.0369 0.0479 -0.0073 0.0305 -0.0138 0.0152 -0.0012 0.0154 -0.0092 0.0177 -0.0161 0.0070 -0.0042 0.0051 -0.0131 0.0059 -0.0041 0.0077 -0.0034 0.0074 -0.0014 0.0025 -0.0056 0.0028 -0.0005 0.0033 -0.0000 0.0022 -0.0032 0.0012 -0.0020 0.0017 -0.0022 0.0004 -0.0011 0 0 ];
Hn=Hn(1:order);
N=1000;
EE=zeros(N,1); Loop=150; mu=0.5;
EE1=zeros(N,1);EE2=zeros(N,1);EE3=zeros(N,1);
for nn=1:Loop
r=sign(rand(N,1)-0.5);
output=conv(r,Hn);
output=awgn(output,snr,'measured');
win=zeros(1,order);
win1=zeros(1,order);
win2=zeros(1,order);
win3=zeros(1,order);
error=zeros(1,N)';
error1=zeros(1,N)';
error2=zeros(1,N)';
error3=zeros(1,N)';
for i=order:N
input=r(i:-1:i-order+1);
y(i)=win*input;
e=output(i)-win*input;
e1=output(i)-win1*input;
e2=output(i)-win2*input;
e3=output(i)-win3*input;
fai=0.0001;
if i<200
mu=0.32;
else
mu=0.15;
end
win=win+0.3*e*input'/(fai+input'*input); % 不同步长的NLMS
win1=win1+0.8*e1*input'/(fai+input'*input);
win2=win2+1.3*e2*input'/(fai+input'*input);
win3=win3+1.8*e3*input'/(fai+input'*input);
error(i)=error(i)+e^2;
error1(i)=error1(i)+e1^2;
error2(i)=error2(i)+e2^2;
error3(i)=error3(i)+e3^2;
% y1(i)=win1*input;
% e1=output(i)-win1*input;
% win1=win1+0.2*e1*input'; % LMS
% error1(i)=error1(i)+e1^2;
end
EE=EE+error;
EE1=EE1+error1;
EE2=EE2+error2;
EE3=EE3+error3;
end
error=EE/Loop;
error1=EE1/Loop;
error2=EE2/Loop;
error3=EE3/Loop;
% figure;
% error=10*log10(error(order:N));
% error1=10*log10(error1(order:N));
% plot(error,'r');
% hold on;
% plot(error1,'b.');
% axis tight;
% legend('NLMS算法','LMS算法');
% title('NLMS算法和LMS算法误差曲线');
% xlabel('样本');
% ylabel('误差/dB');
% grid on;
%
% figure;
% plot(win,'r');
% hold on;
% plot(Hn,'b');
% grid on;
% axis tight;
% figure;
% subplot(2,1,1);
% plot(y,'r');
% subplot(2,1,2);
% plot(y1,'b');
figure;
error=10*log10(error(order:N));
error1=10*log10(error1(order:N));
error2=10*log10(error2(order:N));
error3=10*log10(error3(order:N));
hold on;
plot(error,'r');
hold on;
plot(error1,'b');
hold on;
plot(error2,'y');
hold on;
plot(error3,'g');
axis tight;
legend('η = 0.3','η = 0.8','η = 1.3','η = 1.8');
title('不同步长对NLMS算法的影响');
xlabel('样本');
ylabel('误差/dB');
grid on;
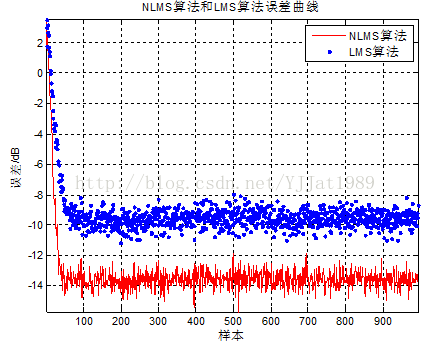
图2 NLMS算法和LMS算法误差曲线
图2中下降曲线的斜率反映了算法的收敛速度,稳定后的误差反映了算法的精度。由图可知,NLMS算法的收敛速度快于LMS算法,且NLMS算法精度也大于LMS算法。
然后分析步长大小对算法性能的影响。以NLMS算法为基础,分别分析当η= 0.3,η = 0.9,η = 1.3,η = 1.8(0< η < 2)时算法的收敛特性,得到误差曲线如图3所示。
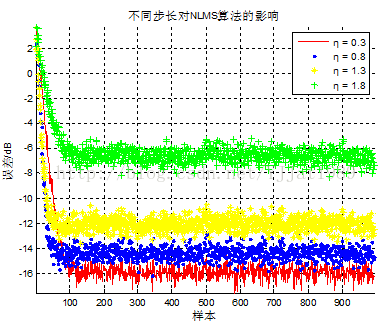
图3 不同步长对NLMS算法的影响
由图3可看出,随着步长的增大,算法收敛速度先有所提高,之后又下降,而算法精度却逐渐减小。
由以上两组仿真实验可以看出,算法自适应收敛时收敛速度和精度是一对矛盾,步长大,即收敛系数大,收敛速度可能有所改善,但精度却变差,反之亦然。
由于LMS算法中步长是不变的,所以很难找到一个适当的步长来解决这一矛盾;而NLMS算法则采用变步长的方式在保证精度的情况下缩短自适应收敛过程。实际应用中要不断调整步长,以得到算法的最优性能。
3 算法效果
分别采用NLMS算法和LMS算法来处理混响语音信号。此时输入信号是一段混响9秒的语音信号,参考信号是无混响的语音信号。为了有较快的收敛速度和精度,在NLMS迭代开始时设置步长η为0.32使算法较快收敛,之后设置步长η为0.15以得到较高精度。在LMS迭代中设置步长µ=0.1。代码如下:
clear all
close all
clc
hold off
sysorder=50; %抽头数
[inp,sr]=mp3read('T60=9.0.mp3'); %输入
inp=inp(:);
[d,sr] = mp3read('T60=0.mp3');
d=d(:);
totallength=size(d,1); %步长
N=length(inp);
%k=0:1382493;
k=0:691246;
%算法开始
w=zeros(sysorder,1); %初始化
w1=zeros(sysorder,1); %初始化
error=zeros(N,1); %初始化
EE=zeros(N,1);
Loop=15000;
for n=sysorder:N
u=inp(n:-1:n-sysorder+1); %u的矩阵
%u=inp(n-sysorder+1:n);
%NLMS算法
y(n)=w'*u; %系统输出
r(n)=u'*u; %自相关矩阵
e(n)=d(n)-y(n); %误差
srr(n)=10*log10(d(n)/(inp(n)-d(n)));
srr1(n)=10*log10(d(n)/(y(n)-d(n)));
%e(n)=inp(n)-y(n); %误差
fai=1e-10; %修正参数,防止r(n)过小导致步长值太大
if n<2000
mu=0.32;
else
mu=0.15;
end
w=0.8*w+mu*u*e(n)/(r(n)+fai); %NLMS迭代方程
error(n)=error(n)+e(n)^2;
%LMS算法
y1(n)=w1'*u;
e1(n)=d(n)-y1(n);
w1=0.8*w1+0.1*u*e1(n); %LMS迭代方程
end
EE=EE+error;
error=EE/Loop;
error=error.^2;
error(n)=error'*error;
% for i=sysorder:N1
% u1=inp2(i:-1:i-sysorder+1);
% y_out(i)=w'*u1;
% end
%srr=10*log10(d/(inp-d));
%srr1=10*log10(d/(y-d));
y=y(:);
y1=y1(:);
e=e(:);
e1=e1(:);
srr=srr(:);
srr1=srr1(:);
%y_out=y_out(:);
inp1=reshape(inp,691247,2);
%inp3=reshape(inp2,342191,2);
d1=reshape(d,691247,2);
y_nlms=2*reshape(y,691247,2);
y_lms=2*reshape(y1,691247,2);
%y_out1=20*reshape(y_out,342191,2);
error=10*log10(error);
e_nlms=reshape(e,691247,2);
e_lms=reshape(e1,691247,2);
error_nlms=reshape(error,691247,2);
srr2=reshape(srr,691247,2);
srr3=reshape(srr1,691247,2);
figure(1);
subplot(3,1,1);
plot(k,inp1);
title('系统输出波形对比');
xlabel('样本n');
ylabel('混响9秒信号波形');
subplot(3,1,2);
plot(k,y_nlms,'r');
xlabel('样本n');
ylabel('NLMS输出信号波形');
subplot(3,1,3);
plot(k,y_lms,'g');
axis([0 691246 -1 1]);
xlabel('样本n');
ylabel('LMS输出信号波形');
sound(d1,sr);
sound(inp1,sr);
sound(y_nlms,sr);
mp3write(y_nlms,sr,'nlms.mp3');
sound(y_lms,sr);
mp3write(y_lms,sr,'lms.mp3');
其处理后波形图如图4所示。
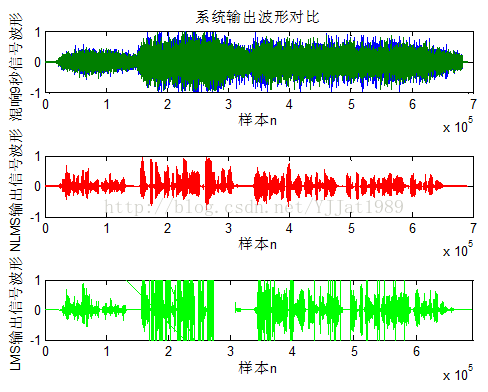
图4 NLMS算法和LMS算法去混响
由图4可看出,NLMS算法和LMS算法均成功的去掉了混响,实际听音表明NLMS算法得到的语音很清晰,LMS算法得到语音则有些失真。















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









