







 本文介绍了声音特征提取中的MFCC(梅尔频率倒谱系数)技术,包括预加重、加窗、离散傅里叶变换、Mel滤波器组、倒谱变换以及能量和差分的处理步骤。MFCC模拟人耳听觉特性,用于提高语音识别的准确性,常用于语音处理和识别系统。
本文介绍了声音特征提取中的MFCC(梅尔频率倒谱系数)技术,包括预加重、加窗、离散傅里叶变换、Mel滤波器组、倒谱变换以及能量和差分的处理步骤。MFCC模拟人耳听觉特性,用于提高语音识别的准确性,常用于语音处理和识别系统。
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好的代表声音的特征,因此,必须将声音波形转换为声学特征向量。目前有许多声音特征提取方法,如梅尔频率倒谱系数MFCC、线性预测倒谱系数LPCC、多媒体内容描述接口MPEG7等,其中MFCC是基于倒谱的,更符合人的听觉原理,因而是最普遍、最有效的声音特征提取算法。在提取MFCC前,需要对声音做前期处理,包括模数转换、预加重和加窗。
模数转换就是把模拟信号转换为数字信号,包括两个步骤:采样和量化,即以一定的采样率和采样位数把声音连续波形转换为离散的数据点。由于日常生活中的声音一般都在8kHz以下,根据Nyquist定律,16kHz采样率足以使得采样出来的数据包含大多数声音信息。16kHz意味着1s的时间内采样16k个样本,这些样本都是以幅度值存储,为了有效存储幅度值,需要将其量化为整数。对于16位采样位数来说,可以表示-32768~32767之间的整数值,所以可以将采样幅度值量化为最近的整数值。
采样和量化后的波形表示为x[n],其中n是时间索引。然后可以对x[n]做MFCC特征提取,算法流程图如图:
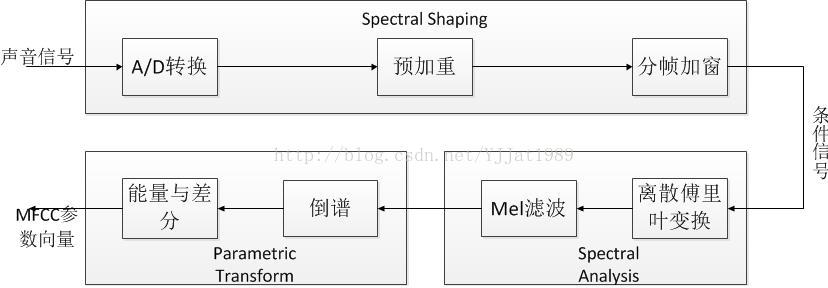
一、预加重
MFCC特征提取的第一步是增加声音高频部分的能量。对于声音信号的频谱来说,往往低频部分的能量高于高频部分的能量,每经过10倍Hz,频谱能量就会衰减20dB,而且由于麦克风在采集声音信号时电路本底噪声的影响,也会增加低频部分的能量,为使高频部分的能量和低频部分能量有相似的幅度,需要预加强采集到声音的高频能量。加强高频部分的能量能使声学模型更好的利用高频共振峰,从而提高识别准确率。
预加重可以通过一个一阶高通滤波器实现,在时域,如果输入信号是x[n]并且0.9<=a<=1.0,滤波器表示为y[n]=x[n]-ax[n-1];在频域则
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









