








引言
Pythonic思维代表极简思维,Python开发者不喜欢写复杂的代码,喜欢用直观、简洁且易读的方式来编写。
本文就一些常见常见如何利用Pythonic思维来编程就行说明。
#1 查询自己使用的Python版本
在有些系统中,python是python2.x的别名,而python3是python3.x的别名。可以用--version查找所使用的具体Python版本。
$ python --version
Python 3.8.5
在执行Python代码的过程中,可以通过内置的sys模块查询Python版本:
>>> import sys
>>> print(sys.version_info)
sys.version_info(major=3, minor=8, micro=5, releaselevel='final', serial=0)
>>> print(sys.version)
3.8.5 (default, Sep 4 2020, 07:30:14)
[GCC 7.3.0]
Python2 于2020年1月1日停止维护,因此建议大家都转换到Python3来。
#2 遵循PEP8 风格指南
Python Enhancement Proposal #8 叫作PEP8,是一份针对Python代码格式而编写的风格指南。大家都采用一致的风格可以让代码可读性更好。大家应该把完整指南阅读一遍。
如果你没有阅读完整版,那么下面几条要绝对遵守。
与空白有关的建议
在Python中,空白(空白符,空格或制表符等)在语法上相当重要。大家应该遵循以下几条建议:
-
用空格(space)表示缩进,而不要使用制表符(Tab)
-
和语法相关的每一层缩进都用4个空格表示
-
每行不超过79个字符
- 在PyCharm中,我们只要代码不超过这条线即可:

- 在PyCharm中,我们只要代码不超过这条线即可:
-
对于占据多行的长表达式来说,除了首行之外的其余各行都应该在通常的缩进级别之上再加4个空格
-
在同一份文件中,函数与类之间用两个空行隔开
-
在同一个类中,方法与方法用一个空行隔开
-
使用字典时,键与冒号之间不加空格,写在同一行的冒号和值之间应该加一个空格
-
给变量赋值时,赋值符号的左边和右边各加一个空格,并且只加一个空格就好
-
给变量的类型做注解时,不要把变量名和冒号隔开,但在类型信息前应该有一个空格
与命名有关的建议
PEP8 建议采用不同的方式来给Python代码中的各个部分命名,这样在阅读代码时,就可以根据这些名称看出它们的角色。遵守以下建议:
- 函数、变量及属性用小写字母来拼写,各单词之间用下划线相连,例如:
lowercase_undersoce - 受保护的实例属性,用一个下划线开头,例如:
_leading_underscore - 私有的实例属性,用两个下划线开头,例如:
__double_leading_underscore - 类(包括异常)命名时,每个单词的首字母均大写,例如:
CapitalizedWord - 模块级别的常量,所有字母都大写,各单词之间用下划线相连,例如:
ALL_CAPS - 类中的实例方法,应该把第一个参数命名为
self,用来表示该对象本身 - 类方法的第一个参数,应该命名为
cls,用来表示这个类本身
与表达式和语句有关的建议
- 采用行内否定,即把否定词直接写在要否定的内容前面,而不要放在整个表达式的前面,例如应该写
if a is not b,而不是if not a is b - 不要通过长度判断容器或序列是不是空的,例如不要通过
if len(somelist) == 0判断somelist是否为[]或''等空值,而是应该采用if not somelist这样的写法来判断,因为Python会把空值自动评估为False - 如果要判断容器或序列里有没有内容,也不要通过长度来判断,而是应该采用
if somelist语句,因为Python会把非空的值自动判断为True - 不要把
if语句、for循环、while循环及except复合语句挤在一行。应该把这些语句分成多行来写,这样更清晰 - 如果表达式一行写不下,可以用括号将其括起来,而且要适当地添加换行与缩进以便于阅读
- 多行的表达式,应该用括号括起来,而不要用
\符号续行
与引入有关的建议
import语句总是应该放在文件开头- 引入模块时,总是应该使用绝对名称,而不应该根据当前模块路径来使用相对名称。例如,要引入
bar包中的foo模块,应该完整地写出from bar import foo,即便当前路径为bar包里,也不应该简写为import foo - 如果一定要用相对名称来编写
import语句,那就应该明确地写成:from . import foo - 文件中的
import语句应该按顺序分成三个部分:首先引入标准库里的模块,然后引入第三方模块,最后引入自己的模块。属于同一个部分的import语句按字母顺序排列。
#3 了解bytes与str的区别
Python有两种类型可以表示字符序列:bytes和str。bytes实例包含的是原始数据,即8位的无符号值。
a = b'h\x65llo'
print(list(a)) # [104, 101, 108, 108, 111]
print(a) # b'hello'
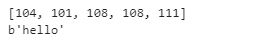
str实例包含的是Unicode码点,这些码点与人类语言之中的文本字符相对应。
a = 'a\u0300 propos'
print(list(a)) # ['a', '̀', ' ', 'p', 'r', 'o', 'p', 'o', 's']
print(a) # à propos
['a', '̀', ' ', 'p', 'r', 'o', 'p', 'o', 's']
à propos
str实例不一定非要用某种固定的方案编码成二进制数据,bytes实例也不一定非要按照某一种固定的方案解码成字符串。要把Unicode数据转换成二进制数据,必须调用str的encode方法。要把二进制数据转换成Unicode数据,必须调用bytes的decode方法。调用这些方法的时候,可以明确指出使用的编码方案。
编写Python程序的时候,一定要把解码和编码操作放在最外层来做,让程序的核心部分可以使用Unicode数据来运作,这种办法通常叫做Unicode三明治。
程序的核心部分,应该用str类型来表示Unicode数据,并且不要锁定到某种字符编码上面。这样可以让程序接受许多种文本编码,并把它们都转换成Unicode。
两种不同的字符类型与Python中两种常见的使用情况相对应:
- 开发者需要操作原始的8位值序列,序列里面的这些8位值合起来表示一个应该按UTF-8或其他标准编码的字符串
- 开发者需要操作通用的Unicode字符串,而不是操作某种特定编码的字符串
我们通常需要编写两个辅助函数,以便在这两种情况之间转换,确保输入值类型符合开发者的预期形式。
第一个辅助函数接受bytes或str实例,并返回str:
def to_str(bytes_or_str):
if isinstance(bytes_or_str, bytes):
value = bytes_or_str.decode('utf-8') # to str
else:
value = bytes_or_str
return value
print(repr(to_str(b'foo'))) # 'foo'
print(repr(to_str('bar'))) # 'bar'
第二个辅助函数也接受bytes或str实例,但它返回的是bytes:
def to_bytes(bytes_or_str):
if isinstance(bytes_or_str, str):
value = bytes_or_str.encode('utf-8') # to bytes
else:
value = bytes_or_str
return value
print(repr(to_str(b'foo'))) # 'foo'
print(repr(to_str('bar'))) # 'bar'
使用原始的8位值与Unicode字符串时,有两个问题要注意。
第一个问题是,bytes与str这两种类型似乎以相同的方式工作,但其实例并不互相兼容,所以在传递字符序列的时候必须考虑好其类型。
可以用+操作符将bytes添加到bytes,str也是如此。
print(b'one' + b'two') # b'onetwo'
print('one' + 'two') # onetwo
但是不能将str实例添加到bytes实例:
b'one' + 'two'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-f531e85f0fca> in <module>
----> 1 b'one' + 'two'
TypeError: can't concat str to bytes
也不能将bytes实例添加到str实例:
'one' + b'two'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-4bf1340b6409> in <module>
----> 1 'one' + b'two'
TypeError: can only concatenate str (not "bytes") to str
bytes与bytes之间可以用二元操作符来比较大小,str之间也可以:
assert b'red' > b'blue'
assert 'red' > 'blue'
但是str不能与bytes实例比较:
assert 'red' > b'blue'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-51b54d0b93a4> in <module>
----> 1 assert 'red' > b'blue'
TypeError: '>' not supported between instances of 'str' and 'bytes'
反过来也一样,bytes实例不能与str实例比较。
判断bytes实例与str实例是否相等,总是返回False,即使它们表示的字符完全相同。
print(b'foo' == 'foo') # False
两种类型的实例都可以出现在%操作符的右侧,用来替换左侧那个格式字符串里的%s。
print(b'red %s' % b'blue') # b'red blue'
print('red %s' % 'blue') # red blue
如果格式字符串是bytes类型,那么不能用str实例来替换其中的%s,因为Python不知道这个str应该按照什么方案来编码。
print(b'red %s' % 'blue')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-996799a8aced> in <module>
----> 1 print(b'red %s' % 'blue')
TypeError: %b requires a bytes-like object, or an object that implements __bytes__, not 'str'
但是反过来却可以,如果格式字符串是str类型,则可以使用bytes实例来替换其中的%s,但是,可能和你想要的结果不一样。
print('red %s' % b'blue') # red b'blue'
因为这样会让系统在bytes实例上调用__repr__方法,然后得到的结果替换格式字符串里目的%s,因此程序会输出b'blue'。
第二个问题发生在操作文件句柄的时候,这里的句柄指由内置的open函数返回的句柄。这样的句柄默认需要使用Unicode字符串操作,而不能采用原始的bytes。
例如,向文件写入二进制文数据的时候,下面这种写法其实是错误的。
with open('data.bin', 'w') as f:
f.write(b'\xf1\xf2\xf3\xf4\xf5')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-17-e42a59df12fe> in <module>
1 with open('data.bin', 'w') as f:
----> 2 f.write(b'\xf1\xf2\xf3\xf4\xf5')
TypeError: write() argument must be str, not bytes
发生异常的原因是在调用open函数时,指定的是w模式,所以系统要求必须以文本模式写入。如果想用二进制模式,则应该指定wb。
在文本模式下,write方法接受的是包含Unicode数据的str实例,不是包含二进制数据的bytes实例。
with open('data.bin', 'wb') as f:
f.write(b'\xf1\xf2\xf3\xf4\xf5')
在读取文件的时候也有类似的问题。例如,如果要把刚才写入的二进制文件读出来,那么不能用下面的写法:
with open('data.bin', 'r') as f:
data = f.read()
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-20-e61b03babdec> in <module>
1 with open('data.bin', 'r') as f:
----> 2 data = f.read()
~/anaconda3/envs/py38/lib/python3.8/codecs.py in decode(self, input, final)
320 # decode input (taking the buffer into account)
321 data = self.buffer + input
--> 322 (result, consumed) = self._buffer_decode(data, self.errors, final)
323 # keep undecoded input until the next call
324 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 0: invalid continuation byte
指定的是r模式,也是文本模式。若要用二进制模式读取,应该指定rb。
以文本模式操纵句柄时,系统会采用默认的文本编码方案处理二进制数据。所以上面的写法会让系统通过bytes.decode把这份数据解码成str字符串,再用str.encode把字符串编码成二进制值。
大多数系统默认的编码方法是UTF-8,所以很可能会把b'\xf1\xf2\xf3\xf4\xf5'当成UTF-8格式的字符串取解码,于是就会出现上面那样的错误。为了修正错误,需要改成rb。
with open('data.bin', 'rb') as f:
data = f.read()
assert data == b'\xf1\xf2\xf3\xf4\xf5'
另一种改法是在调用open函数的时候,通过encoding参数明确指定编码标准。
例如,假设刚才写到文件里的那些二进制数据表示的是一个采用cp1252标准来编码的字符串,则可以这样写:
with open('data.bin', 'r', encoding='cp1252') as f:
data = f.read()
assert data == 'ñòóôõ'
这个例子提醒我们注意当前操作系统默认的编码标准是否与我们期望的一致。如果不确定,那么明确指定encoding参数。
可以通过下面的代码来查看系统默认的编码标准。
import locale print(locale.getpreferredencoding())
#4 用支持插值的f-string取代C风格的格式字符串与str.format写法
用Python对字符串做格式化处理有四种办法可以考虑,但其中三种方法有严重的缺陷,先解释为什么不要使用这三种办法,最后再给出剩下的那一种。
最常用的字符串格式化方式是采用%格式化操作符。
例如,下面通过%操作符把难以阅读的二进制和十六进制,显示成十进制的形式。
a = 0b10111011
b = 0xc5f
print('Binary is %d, hex is %d' % (a, b)) # Binary is 187, hex is 3167
这种C风格的格式字符串,在Python里有四个缺点。
第一个缺点是,如果%右侧那个元组里面的值在类型或顺序上有变化,那么程序可能会因为转换类型时发生不兼容问题而出现错误。
例如,下面这个简单的格式化表达式是正确的。
key = 'my_var'
value = 1.234
formatted = '%-10s = %.2f' % (key, value)
print(formatted) # my_var = 1.23
但如果把key和value互换位置,那么程序就会出现异常。
reordered_tuple = '%-10s = %.2f' % (value, key)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-3438bf149d3e> in <module>
----> 1 reordered_tuple = '%-10s = %.2f' % (value, key)
TypeError: must be real number, not str
如果%右侧的写法不变,但左侧那个格式字符串里面的两个说明符对调了顺序,那么程序同样会发生这个错误。
reordered_string = '%.2f = %-10s' % (key, value)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-5-7391cce685e6> in <module>
----> 1 reordered_string = '%.2f = %-10s' % (key, value)
TypeError: must be real number, not str
要想避免这种问题,必须经常检查%操作符左右两侧的写法是否相互兼容。
第二个缺点是,在填充模板之前,经常要先对准备填写进去的这个值稍微做一些处理,但这样,整个表达式可能会写得很长,让人觉得比较混乱。
下面这段代码用来罗列厨房里的各种食材,现在的这种写法并没有对填入格式字符串里面的那三个值预先作出调整。
pantry = [
('avocados', 1.25),
('bananas', 2.5),
('cherries', 15),
]
for i, (item, count) in enumerate(pantry):
print('#%d: %-10s = %.2f' % (i, item, count))
#0: avocados = 1.25
#1: bananas = 2.50
#2: cherries = 15.00
如果想让打印出来的信息更好懂,那可能得把这几个值稍微调整一下,但是调整后,%操作符右侧的那个三元组就特别长,所以需要多行拆分才能写的下,这会影响可读性。
for i, (item, count) in enumerate(pantry):
print('#%d: %-10s = %d' % (
i + 1,
item.title(),
round(count)))
#1: Avocados = 1
#2: Bananas = 2
#3: Cherries = 15
第三个缺点是, 如果想用同一个值来填充格式字符串里的多个位置,那么必须在%操作符右侧的元组中相应地多次重复该值。
template = '%s loves food. See %s cook.'
name = 'Max'
formatted = template % (name, name)
print(formatted) # Max loves food. See Max cook.
如果想在填充之前把这个值修改一下,那么必须同时修改多处才行。
name = 'brad'
formatted = template % (name.title(), name.title())
print(formatted) # Brad loves food. See Brad cook.
为了解决上面提到的一些问题。Python的%操作符允许我们用dict取代tuple。
这样,我们可以让格式字符串里面的说明符与dict里面的键以相应的名称对应起来,例如%(key)s这个说明符,意思就是用字符串(s)来表示dict里面名为key的那个键所保存的值。
下面通过这种办法解决刚才讲的第一个缺点,也就是%两侧的顺序不匹配问题。
key = 'my_var'
value = 1.234
old_way = '%-10s = %.2f' % (key, value)
new_way = '%(key)-10s = %(value).2f' % {
'key': key, 'value': value} # Original
reordered = '%(key)-10s = %(value).2f' % {
'value': value, 'key': key} # Swapped
assert old_way == new_way == reordered
这种写法还可以解决第三个缺点,也就是用同一值替换多个格式说明符的问题。改用这种写法后,我们就不用在%右侧重复这个值了。
name = 'Max'
template = '%s loves food. See %s cook.'
before = template % (name, name) # Tuple
template = '%(name)s loves food. See %(name)s cook.'
after = template % {'name': name} # Dictionary
assert before == after
但是, 这种写法会让刚才讲的第二个缺点变得更加严重,因为字典格式字符串的引入,我们必须给每一个值都定义键名,而且要在键名的右侧加冒号,格式化表示变得更加冗长。
我们把不采用dict的写法与采用dict的写法对比一下,就可以看到这种缺点:
for i, (item, count) in enumerate(pantry):
before = '#%d: %-10s = %d' % (
i + 1,
item.title(),
round(count))
after = '#%(loop)d: %(item)-10s = %(count)d' % {
'loop': i + 1,
'item': item.title(),
'count': round(count),
}
assert before == after
应用C风格格式化表达式的第四个缺点是,把dict写到格式化表达式里面会让代码变多。每个键都至少写两次:一次是在格式化说明符中,还有一次是在字典中作为键,另外,定义字典时,可能还要专门用一个变量来表示这个键所对应的值。
soup = 'lentil'
formatted = 'Today\'s soup is %(soup)s.' % {'soup': soup} # 三个soup
print(formatted) # Today's soup is lentil.
除了要反复写键名,在格式化表达式里使用dict的方法还会让表达式变得特别长,通常必须拆分为多行来写。
menu = {
'soup': 'lentil',
'oyster': 'kumamoto',
'special': 'schnitzel',
}
template = ('Today\'s soup is %(soup)s, '
'buy one get two %(oyster)s oysters, '
'and our special entrée is %(special)s.')
formatted = template % menu
print(formatted) # Today's soup is lentil, buy one get two kumamoto oysters, and our special entrée is schnitzel.
肯定有更好的办法才对。
内置的format函数与str类的format方法
Python 3添加了高级字符串格式化机制,它的表达能力比老式C风格的格式化字符串要强,且不再使用%操作符。我们针对需要调整格式的这个Python值,调用内置的format函数,并把这个值所应具备的格式也传给该函数,即可实现格式化。
a = 1234.5678
formatted =format(a , ',.2f') #,表示显示千位分隔符
print(formatted) # 1,234.57
b = 'my string'
formatted = format(b, '^20s') # ^表示居中对齐
print('*', formatted, '*') # * my string *
如果str类型的字符串里面有许多值都需要调整格式,则可以调用str的新format方法。
该方法把格式有待调整的那些位置在字符串里先用{}代替,然后按从左到右的顺序,把需要填写到那些位置的值传给format方法,使这些值依次出现在字符串中的相应位置。
key = 'my_var'
value = 1.234
formatted = '{} = {}'.format(key, value)
print(formatted) # my_var = 1.234
你可以在{}里面写个冒号,然后把格式说明符写在冒号的左边:
formatted = '{:<10} = {:.2f}'.format(key, value)
print(formatted) # my_var = 1.23
在调用str.format的时候,如果想把str里面的{、}照原样输出,那么也得转义。
print('%.2f%%' % 12.5) # 12.50%
print('{} replaces {{}}'.format(1.23)) # 1.23 replaces {}
调用str.foramt时,可以给str的{}里面写上数字,指代format方法在这个位置所接收到的参数值位置索引。
以后即使这些{}格式字符串中的词序有所变动,也不用调换传给format方法的那些参数。这样就避免了前面说的第一个缺点。
formatted = '{1} = {0}'.format(key, value)
print(formatted) # 1.234 = my_var
同一个位置索引可以出现在str里面的多个{}里面,这些{}指代的都是format方法在对应位置所收到的值。
不需要重复地传给format方法,也就解决了第三个缺点。
formatted = '{0} loves food. See {0} cook.'.format(name)
print(formatted) # Max loves food. See Max cook.
然后,这个新的str.format方法并没有解决第二个问题。如果在对值做填充之前要先对这个值做出调整,那么用这种方法写出来的代码还是跟原来一样乱,可读性差。
把原来那种写法和现在的新写法对比一下,大家就会看到新写法并不比原来好多少。
for i, (item, count) in enumerate(pantry):
old_style = '#%d: %-10s = %d' % (
i + 1,
item.title(),
round(count))
new_style = '#{}: {:<10s} = {}'.format(
i + 1,
item.title(),
round(count))
assert old_style == new_style
但是这些特性,依然不能解决前面提到的第四个缺点,即键名需要多次重复的问题。
下面把C风格的格式化表达式与新的str.format方法对比一下,看看这两种写法在处理键值对形式的数据时有什么区别。
old_template = (
'Today\'s soup is %(soup)s, '
'buy one get two %(oyster)s oysters, '
'and our special entrée is %(special)s.')
old_formatted = old_template % {
'soup': 'lentil',
'oyster': 'kumamoto',
'special': 'schnitzel',
}
new_template = (
'Today\'s soup is {soup}, '
'buy one get two {oyster} oysters, '
'and our special entrée is {special}.')
new_formatted = new_template.format(
soup='lentil',
oyster='kumamoto',
special='schnitzel',
)
assert old_formatted == new_formatted
因为str.format方法有这样的一些缺点,而且没办法解决第二个与第四个缺点,总体来说,不推荐大家使用。
插值格式字符串
Python3.6 添加了一种新特性,叫作插值格式字符串(interpolated format string,f-string)。可以解决上面提到的所有问题,新语法特性要求在格式字符串的前面加字母f作为前缀,这跟字母b与字母r的用法类似,它们分别表示字节形式的字符串于原始的(未经转义的)字符串的前缀。
f-string把格式化字符串的表达能力发挥到了极致,彻底解决了上文提到的第四个缺点,也就是键名重复导致的程序冗余问题。
可以直接在f-string的{}里面引用当前Python范围内的所有名称,从而达到简化的目的。
key = 'my_var'
value = 1.234
formatted = f'{key} = {value}'
print(formatted) # my_var = 1.234
str.format方法所支持的那套迷你语言,也就是在{}内的冒号右侧所采用的那套规则,现在也可以用到f-string里面,而且还可以像早前使用str.format那样,通过!符号把值转换成Unicode及repr形式的字符串。
formatted = f'{key!r:<10} = {value:.2f}'
print(formatted) # 'my_var' = 1.23
同一个问题,使用f-string来解决总是比通过%简单,而且也比str.format方法简单。下面按照从短到长的顺序把这几种写法所占的篇幅对比一下:
f_string = f'{key:<10} = {value:.2f}'
c_tuple = '%-10s = %.2f' % (key, value)
str_args = '{:<10} = {:.2f}'.format(key, value)
str_kw = '{key:<10} = {value:.2f}'.format(key=key, value=value)
c_dict = '%(key)-10s = %(value).2f' % {'key': key, 'value': value}
assert c_tuple == c_dict == f_string
assert str_args == str_kw == f_string
在f-string方法中,各种Python表达式都可以出现在{}里,于是这就解决了前面提到的第二个缺点。
我们现在可以用相当简洁的写法对需要填充到字符串里面的值做出微调。
C风格的写法与采用str.format方法的写法可能会让表达式变得很长,但如果改用f-string,或许一行就能完成。
for i, (item, count) in enumerate(pantry):
old_style = '#%d: %-10s = %d' % (
i + 1,
item.title(),
round(count))
new_style = '#{}: {:<10s} = {}'.format(
i + 1,
item.title(),
round(count))
f_string = f'#{i+1}: {item.title():<10s} = {round(count)}'
assert old_style == new_style == f_string
要是想表达得更清楚一些,可以把f-string写成多行的形式。这样仍然好过另外那两种多行的写法。
for i, (item, count) in enumerate(pantry):
print(f'#{i+1}: '
f'{item.title():<10s} = '
f'{round(count)}')
#1: Avocados = 1
#2: Bananas = 2
#3: Cherries = 15
Python表达式也可以出现在格式说明符中。例如,下面的代码把小数点之后的位数用变量来表示,然后把这个变量的名字places用{}括起来放到格式说明符中,这样写比硬编码更灵活。
places = 3
number = 1.23456
print(f'My number is {number:.{places}f}')
在Python内置的四种字符串格式方法里,建议优先考虑使用f-string。
#5 用辅助函数取代复杂的表达式
Python的语法相当简明,所以有时只用一条表达式就能实现许多逻辑。例如要把URL之中的查询字符串拆分成键值对,那么只需要使用parse_qs函数就可以了。
from urllib.parse import parse_qs
my_values = parse_qs('red=5&blue=0&green=',keep_blank_values=True)
print(repr(my_values)) # {'red': ['5'], 'blue': ['0'], 'green': ['']}
在解析查询字符串时,可以发现,有的参数可能带有多个值,有的参数可能只有一个值,还有的参数可能是空白值,另外也遇到没有这个参数的情况。下面的代码刚好对应这个三种不同的情况。
print('Red: ', my_values.get('red'))
print('Green: ', my_values.get('green'))
print('Opacity: ', my_values.get('opacity'))
Red: ['5']
Green: ['']
Opacity: None
我们现在把参数缺失与参数为空白这两种情况都默认当成0。但这样一个小逻辑,似乎不值得专门写if语句或辅助函数,所以有人会直接用布尔表达式实现。
布尔表达式用Python的语法写起来很简单,因为Python在对这种表达式求值的时候,会把空白字符串、空白list以及0值,全部当成False看待。
red = my_values.get('red', [''])[0] or 0
green = my_values.get('green', [''])[0] or 0
opacity = my_values.get('opacity', [''])[0] or 0
print(f'Red: {red!r}')
print(f'Green: {green!r}')
print(f'Opacity: {opacity!r}')
Red: '5'
Green: 0
Opacity: 0
这种写法可以实现,问题在于很ugly,而且我们还需要将它们转换成整数。
red = int(my_values.get('red', [''])[0] or 0)
green = int(my_values.get('green', [''])[0] or 0)
opacity = int(my_values.get('opacity', [''])[0] or 0)
print(f'Red: {red!r}')
print(f'Green: {green!r}')
print(f'Opacity: {opacity!r}')
Red: 5
Green: 0
Opacity: 0
这样的代码更加难读了。Python可以用if/else结构实现三元的条件表达式,这样能更清晰和简短。
red_str = my_values.get('red',[''])
red = int(red_str[0] if red_str[0] else 0)
这样写确实比原来好,但是这种写法还不如完整的多行if/else结构好,虽然要多写几行,但是非常易懂。
green_str = my_values.get('green', [''])
if green_str[0]:
green = int(green_str[0])
else:
green = 0
print(f'Green: {green!r}')
Green: 0
如果要反复使用这套逻辑,那还是写成辅助函数比较好,即使本例中我们只要重复两三次。
def get_first_int(values, key, default=0):
found = values.get(key, [''])
if found[0]:
return int(found[0])
return default
有了辅助函数,就可以通过更简单的代码来调用它了。这种写法比使用or的复杂表达式与使用if/else的条件表达式清晰得多。
green = get_first_int(my_values, 'green')
复杂的表达式,尤其是那种需要重复使用的复杂表达式,应该写到辅助函数里面。
#6 把数据结构直接拆分到多个变量里,不要专门通过下标访问
Python内置的元组类型可以创建不可变的序列,把许多元素依次保存起来。最简单的用法是只用元组保存两个值,例如字典里面的键值对。
snack_calories = {
'chips': 140,
'popcorn': 80,
'nuts': 190,
}
items = tuple(snack_calories.items())
print(items) # (('chips', 140), ('popcorn', 80), ('nuts', 190))
我们可以用整数作下标,通过下标来访问元组里面对应的元素。
item = ('Peanut butter', 'Jelly')
first = item[0]
second = item[1]
print(first, 'and', second) # Peanut butter and Jelly
Python还有一种写法,叫作拆包。这种写法让我们只用一条语句,就可以把元组离开吗的元素分别赋给多个变量。
item = ('Peanut butter', 'Jelly')
first, second = item # 拆包
print(first, 'and', second) # Peanut butter and Jelly
通过拆包来赋值要比通过下标访问元组内的元素更清晰,而且这种写法所需的代码通常比较少。
赋值操作的左边除了可以罗列单个变量,也可以写成列表、序列或任意深度的可迭代对象。例如,下面的这种写法是成立的,然后并不推荐这么写,只是让大脚了解支持这样的写法。
favorite_snacks = {
'salty': ('pretzels', 100),
'sweet': ('cookies', 180),
'veggie': ('carrots', 20),
}
((type1, (name1, cals1)),
(type2, (name2, cals2)),
(type3, (name3, cals3))) = favorite_snacks.items()
print(f'Favorite {type1} is {name1} with {cals1} calories')
print(f'Favorite {type2} is {name2} with {cals2} calories')
print(f'Favorite {type3} is {name3} with {cals3} calories')
Favorite salty is pretzels with 100 calories
Favorite sweet is cookies with 180 calories
Favorite veggie is carrots with 20 calories
我们还可以通过拆包原地交换两个变量。先看下面排序中这种传统的写法。
def bubble_sort(a):
for _ in range(len(a)):
for i in range(1, len(a)):
# 通过创建临时变量
if a[i] < a[i-1]:
temp = a[i]
a[i] = a[i-1]
a[i-1] = temp
names = ['pretzels', 'carrots', 'arugula', 'bacon']
bubble_sort(names)
print(names) # ['arugula', 'bacon', 'carrots', 'pretzels']
有了拆包机制后,只需要写一行代码就可以交换这两个元素。
def bubble_sort(a):
for _ in range(len(a)):
for i in range(1, len(a)):
if a[i] < a[i-1]:
a[i-1], a[i] = a[i], a[i-1] # Swap
names = ['pretzels', 'carrots', 'arugula', 'bacon']
bubble_sort(names)
print(names) # ['arugula', 'bacon', 'carrots', 'pretzels']
这样写为什么可以成立呢?因为Python处理赋值操作的时候,要先对=号右侧求值,于是,它会创建一个临时的元组,把a[i]和a[i-1]这两个元素放到这个元组里去。
例如,第一次进入内部的for循环时,这两个元素分别时’carrots’于’pretzels’,于是系统就会创建出('carrots‘,’pretzels')这样一个临时的元组。
然后Python会对这个临时元组做拆包,把里面的两个元素分别放到=号左侧的那两个地方。做完拆包后,Python会扔掉这个临时的元组。
拆包机制还有一个重要的用法,就是在for循环或类似的结构里面,把复杂的数据拆分到相关的变量之中。下面这段代码没有采用拆包机制。
snacks = [('bacon', 350), ('donut', 240), ('muffin', 190)]
for i in range(len(snacks)):
item = snacks[i]
name = item[0]
calories = item[1]
print(f'#{i+1}: {name} has {calories} calories')
#1: bacon has 350 calories
#2: donut has 240 calories
#3: muffin has 190 calories
这样写看起来很乱,下面换一种写法,首先调用内置的enumerate函数获得当前要迭代的元组,然后针对这个元组做拆包,这样就可以直接得到具体的name与calories了。
for rank, (name, calories) in enumerate(snacks, start=1): # 得到的下标由1开始
print(f'#{rank}: {name} has {calories} calories')
#1: bacon has 350 calories
#2: donut has 240 calories
#3: muffin has 190 calories
#7 尽量用enumerate取代range
Python内置的range函数适合用来迭代一系列整数。
from random import randint
random_bits = 0
for i in range(32):
if randint(0, 1):
random_bits |= 1 << i
print(bin(random_bits)) # 0b100010100000011001110111100000
如果要迭代的是某种数据解耦股,例如字符串列表,那么可以直接在这个序列上迭代,不需要专门通过range设定一个取值范围。
flavor_list = ['vanilla', 'chocolate', 'pecan', 'strawberry']
for flavor in flavor_list:
print(f'{flavor} is delicious')
vanilla is delicious
chocolate is delicious
pecan is delicious
strawberry is delicious
有时,在迭代list的过程中需要知道当前处理的这个元素在list里面的位置。为了实现这种方式,可以用传统的range来实现。
for i in range(len(flavor_list)):
flavor = flavor_list[i]
print(f'{i + 1}: {flavor}')
1: vanilla
2: chocolate
3: pecan
4: strawberry
这种写法跟前面的那几个例子相比显得有点乱。因为我们要先知道列表的长度,然后调用range函数得到下标,这样写步骤太多。
Python有个内置函数,叫enumerate,可以解决刚才的问题。enumerate可以把任何一种迭代器封装成惰性生成器,这样,每次循环的时候,只需要从迭代器里面获取下一个值就可以了,同时还会给出本轮循环的序号。
it = enumerate(flavor_list)
print(next(it))
print(next(it))
(0, 'vanilla')
(1, 'chocolate')
enumerate输出的每一对数据,都可以拆包到for语句的那两个变量里面,这样会让代码更清晰。
for i, flavor in enumerate(flavor_list):
print(f'{i + 1}: {flavor}')
1: vanilla
2: chocolate
3: pecan
4: strawberry
#8 用zip函数同时遍历两个迭代器
我们经常会根据某份列表中的对象创建许多与这份列表有关的新列表。下面这样的列表推导机制,可以把表达式运用到源列表的每个元素上面,从而生成一份派生列表。
names = ['Cecilia', 'Lise', 'Marie']
counts = [len(n) for n in names]
print(counts) # [7, 4, 5]
派生列表中的元素与源列表中对应位置上面的元素有一定的关系。如果想同时遍历这两份列表,那可以根据源列表的长度做迭代。
longest_name = None
max_count = 0
for i in range(len(names)):
count = counts[i]
if count > max_count:
longest_name = names[i]
max_count = count
print(longest_name) # Cecilia
这种写法的问题在于,整个代码看起来很乱。我们要通过下标访问names与counts这两个列表里面的元素。改用enumerate实现会好一点,但仍然不够理想。
for i, name in enumerate(names):
count = counts[i]
if count > max_count:
longest_name = name
max_count = count
为了更清晰,可以用Python内置的zip函数来实现。这个函数能把两个或更多的iterator封装成惰性生成器。每次循环时,它会分别从这些迭代器里获取各自的下一个元素,并把这些值放在一个元组里。这样写要清晰的多。
for name, count in zip(names, counts):
if count > max_count:
longest_name = name
max_count = count
zip每次只从它封装的那些迭代器里各取一个元素,所以即使源列表很长,程序也不会因为占用内存过多而崩溃。
但是,如果输入zip的那些列表长度不一致,那就得小心了。例如,我给names列表里有添加了一个名字,但是忘了把它的长度更新到counts列表中。在这种情况下,用zip同时遍历这两份列表,会产生奇怪的结果。
names.append('Rosalind')
for name, count in zip(names, counts):
print(name)
Cecilia
Lise
Marie
新添加的那个’Rosalind’元素为什么没有打印出来呢?因为zip函数就是这样设计的:只要其中任一迭代器处理完毕,它就不再往下走了。于是,循环的次数实际上等于最短的那份列表所具备的长度。
在列表长度不一的情况下,zip函数的提前终止行为可能会与你预期不同。所以,如果无法确定这些列表的长度相同,那就不要传给zip,而是应该传给另一个叫zip_longest函数。
import itertools
for name, count in itertools.zip_longest(names, counts):
print(f'{name}: {count}')
Cecilia: 7
Lise: 4
Marie: 5
Rosalind: None
如果有些列表遍历完了,zip_longest会用当初传给fillvalue参数的那个值来填补空缺,默认为None。
#9 不要在for与while循环后面写else块
Python的循环有一项大多数编程语言都不支持的特性,即可以把else块紧跟在整个循环结构的后面。
for i in range(3):
print('Loop', i)
else:
print('Else block!')
Loop 0
Loop 1
Loop 2
Else block!
奇怪的是,整个for循环结束后,还会打印else块里面的内容。既然这样,那为什么要叫"else"呢,应该叫"and"才对。
实际上,如果循环没有执行完,那么else块里的代码是不会执行的。比如,在循环中使用break语句实际上会跳过else块。
for i in range(3):
print('Loop', i)
if i == 1:
break
else:
print('Else block!')
Loop 0
Loop 1
还有一个奇怪的地方是,如果对空白序列做for循环,那么程序立刻就会执行else块。
for x in []:
print('Never runs')
else:
print('For Else block!')
For Else block!
while循环也是这样,如果首次循环就遇到False,那么程序也会立刻运行else块。
while False:
print('Never runs')
else:
print('While Else block!')
While Else block!
把else设计成这样,是想让你利用它实现搜索逻辑。例如,如果要判断两个数是否互质,就可以用这种结构实现。
先把有可能同时整除它们的数逐个试一遍,如果全部都试过之后还是没找到这样的数,那么程序就会执行else块里面的内容。
a = 4
b = 9
for i in range(2, min(a, b) + 1):
print('Testing', i)
if a % i == 0 and b % i == 0:
print('Not coprime')
break
else:
print('Coprime')
Testing 2
Testing 3
Testing 4
Coprime
但在实际工作中,不建议这么写。而是改用辅助函数完成计算。这样的辅助函数有两种写法。
第一种写法,只要发现某个条件成立,就立刻返回,否则程序返回函数末尾的值作为默认返回值。
def coprime(a, b):
for i in range(2, min(a, b) + 1):
if a % i == 0 and b % i == 0:
return False
return True
assert coprime(4, 9)
assert not coprime(3, 6)
第二种写法,用变量来记录循环过程中有没有碰到这样的情况,如果有,那就用break提前跳出循环,如果没有,循环就会完整地执行,无论如何,最后都会返回这个变量的值。
def coprime_alternate(a, b):
is_coprime = True
for i in range(2, min(a, b) + 1):
if a % i == 0 and b % i == 0:
is_coprime = False
break
return is_coprime
assert coprime_alternate(4, 9)
assert not coprime_alternate(3, 6)
把else写在for或while循环后,会产生歧义,请不要这么写。
#10 用赋值表达式减少重复代码
赋值表达式(assignment expression)是Python3.8新引入的语法,它会用到海象操作符(walrus operator)。这种写法可以解决某些持续已久的代码重复问题。a = b是一条普通的赋值语句,读取’a equals b’,而a := b是赋值表达式,读作’a walrus b’。
这个符号为什么叫walrus呢?因为把:=顺时针旋转90°之后,冒号就像海象的一双眼睛,等号就是它的一対獠牙。
这种表达式很有用,可以在普通的赋值语句无法应用的场景实现赋值,例如可以用在条件表达式的if语句里面。赋值表达式的值,就是赋值给海象操作符左侧的那个标识符的值。
举个例子,如果有一筐新鲜水果给果汁店做食材,那我们就可以这样定义其中的内容:
fresh_fruit = {
'apple': 10,
'banana': 8,
'lemon': 5,
}
顾客点lemon之前,我们先得确认现在还有没有lemon可以榨汁。所以,要先查出lemon的数量,然后用if语句判断它是不是非零的值。
def make_lemonade(count):
print(f'Making {count} lemons into lemonade')
def out_of_stock():
print('Out of stock!')
count = fresh_fruit.get('lemon', 0)
if count:
make_lemonade(count)
else:
out_of_stock()
Making 5 lemons into lemonade
这段代码看上去虽然简单,但还是显得有些松散,因为count变量虽然定义在整个if/else结构之上,然而只有if语句才会用到它,else块根本就不需要使用这个变量。
所以,这种写法让人误认为count是个很重要的变量,if和else都得用它,但实际上并非如此。
我们再Python里面经常要先获取某个值,然后判断它是否非零,如果是就执行某段代码。对于这种用法,我们以前总是要通过各种技巧,来避免count这样的变量重复出现在代码之中,这些技巧有时会让代码变得难懂。
Python引入赋值表达式正是为了解决这样的问题。下面改用海象操作符来写:
if count := fresh_fruit.get('lemon', 0):
make_lemonade(count)
else:
out_of_stock()
Making 5 lemons into lemonade
这种写法明确体现出count变量只与if有关。这个赋值表达式先把:=右边的赋值给左边的count变量,然后对自身求值,也就是把变量的值当成整个表达式的值。由于表达式紧跟着if,程序会根据它的值是否非零来决定该不该执行if块。 这种先赋值再判断的做法,正是海象操作符想要表达的意思。
假设客人点的是苹果汁(apple),需要4个苹果。按照传统的写法:
def make_cider(count):
print(f'Making cider with {count} apples')
count = fresh_fruit.get('apple', 0)
if count >= 4:
make_cider(count)
else:
out_of_stock()
Making cider with 10 apples
下面再通过海象操作符,把代码写得更清晰一些。
if (count := fresh_fruit.get('apple', 0)) >= 4:
make_cider(count)
else:
out_of_stock()
Making cider with 10 apples
与上面的例子类似。但是,我们这次赋值表达式放到了一対括号里面。为什么?因为我们要在if语句里面把这个赋值表达式的结果与4这个值比较。
刚才lemon的例子没有加括号,因为那时只凭赋值表达式本身的值就能决定if/else的走向:只要表达式的值不是0,程序就进入if分支。
但是这次不行,折次要把这个赋值表达式放在更大的表达式里面,所以必须用括号括起来。
还有一种类似的逻辑也会出现刚才说的重复代码:我们要根据情况给某个变量赋予不同的值,紧接着要用这个变量做参数来调用某个函数。例如,若顾客要点香蕉冰沙,
那我们首先得把香蕉切成好几份,然后用其中的两份来制作这道冰沙。如果不够两份,那就抛出香蕉不足异常。下面先用传统的写法来实现:
def slice_bananas(count):
print(f'Slicing {count} bananas')
return count * 4
class OutOfBananas(Exception):
pass
def make_smoothies(count):
print(f'Making a smoothies with {count} banana slices')
pieces = 0
count = fresh_fruit.get('banana', 0)
if count >= 2:
pieces = slice_bananas(count)
try:
smoothies = make_smoothies(pieces)
except OutOfBananas:
out_of_stock()
Slicing 8 bananas
Making a smoothies with 32 banana slices
还有一种传统的写法也很常见,就是把if/else结构上那条pieces = 0的赋值语句移动else块中:
count = fresh_fruit.get('banana', 0)
if count >= 2:
pieces = slice_bananas(count)
else:
pieces = 0
try:
smoothies = make_smoothies(pieces)
except OutOfBananas:
out_of_stock()
Slicing 8 bananas
Making a smoothies with 32 banana slices
这种写法看起来有点怪,因为if与else这两个分支都给pieces变量定义了初始值。根据Python的作用域规则,这种写法是成立的。虽然成立,但是看起来别扭,所以很多人喜欢用第一种写法。
改用海象操作符实现,可以少写一行代码,而且能压低count变量的地位,让它只出现在if块里:
pieces = 0
if (count := fresh_fruit.get('banana', 0)) >= 2:
pieces = slice_bananas(count)
try:
smoothies = make_smoothies(pieces)
except OutOfBananas:
out_of_stock()
Slicing 8 bananas
Making a smoothies with 32 banana slices
对于在if与else分支里面分别定义pieces变量的写法来说,海象操作符也能让代码变得清晰:
if (count := fresh_fruit.get('banana', 0)) >= 2:
pieces = slice_bananas(count)
else:
pieces = 0
try:
smoothies = make_smoothies(pieces)
except OutOfBananas:
out_of_stock()
Slicing 8 bananas
Making a smoothies with 32 banana slices
Python新手经常找不到好办法来实现switch/case结构。最接近这种结构的做法是在if/else结构里面嵌套if/else结构,或使用if/elif/else结构。
例如,我们想按照一定的顺序给客人制作饮品。下面这段代码先判断能不能做香蕉冰沙,若不能,就做苹果汁,还不行,就做柠檬(lemon)汁:
count = fresh_fruit.get('banana', 0)
if count >= 2:
pieces = slice_bananas(count)
to_enjoy = make_smoothies(pieces)
else:
count = fresh_fruit.get('apple', 0)
if count >= 4:
to_enjoy = make_cider(count)
else:
count = fresh_fruit.get('lemon', 0)
if count:
to_enjoy = make_lemonade(count)
else:
to_enjoy = 'Nothing'
Slicing 8 bananas
Making a smoothies with 32 banana slices
这种难看的写法其实很常见。幸好有了海象操作符,让我们能轻松地模拟出接近switch/case的方案。
if (count := fresh_fruit.get('banana', 0)) >= 2:
pieces = slice_bananas(count)
to_enjoy = make_smoothies(pieces)
elif (count := fresh_fruit.get('apple', 0)) >= 4:
to_enjoy = make_cider(count)
elif count := fresh_fruit.get('lemon', 0):
to_enjoy = make_lemonade(count)
else:
to_enjoy = 'Nothing'
Slicing 8 bananas
Making a smoothies with 32 banana slices
Python新手还会遇到一个困难,就是缺少do/while循环结构。例如,我们要把新来的水果做成果汁并且装到瓶子里面,直到水果用完为止。下面先用while循环来实现:
FRUIT_TO_PICK = [
{'apple': 1, 'banana': 3},
{'lemon': 2, 'lime': 5},
{'orange': 3, 'melon': 2},
]
def pick_fruit():
if FRUIT_TO_PICK:
return FRUIT_TO_PICK.pop(0)
else:
return []
def make_juice(fruit, count):
return [(fruit, count)]
bottles = []
fresh_fruit = pick_fruit()
while fresh_fruit:
for fruit, count in fresh_fruit.items():
batch = make_juice(fruit, count)
bottles.extend(batch)
fresh_fruit = pick_fruit()
print(bottles)
[('apple', 1), ('banana', 3), ('lemon', 2), ('lime', 5), ('orange', 3), ('melon', 2)]
这种写法必须把fresh_fruit = pick_fruit()写两次。
如果想复用这行代码,可以考虑loop-and-a-half模式。这个模式虽然能消除重复,但是会让while循环看起来很笨,因为它成了无限循环,只能通过break跳出循环。
loop-and-a-half模式:在循环体执行到一半的时候,判断要不要退出。
FRUIT_TO_PICK = [
{'apple': 1, 'banana': 3},
{'lemon': 2, 'lime': 5},
{'orange': 3, 'melon': 2},
]
bottles = []
while True: # Loop
fresh_fruit = pick_fruit()
if not fresh_fruit: # And a half
break
for fruit, count in fresh_fruit.items():
batch = make_juice(fruit, count)
bottles.extend(batch)
print(bottles)
[('apple', 1), ('banana', 3), ('lemon', 2), ('lime', 5), ('orange', 3), ('melon', 2)]
有了海象操作符,就不需要使用这种模式了,我们可以在每轮循环的开头给fresh_fruit变量赋值,并根据变量的值来决定要不要继续循环。
FRUIT_TO_PICK = [
{'apple': 1, 'banana': 3},
{'lemon': 2, 'lime': 5},
{'orange': 3, 'melon': 2},
]
bottles = []
while fresh_fruit := pick_fruit(): # 如果碰到 [] ,则while循环结束 。很简单易读。
for fruit, count in fresh_fruit.items():
batch = make_juice(fruit, count)
bottles.extend(batch)
print(bottles) # [('apple', 1), ('banana', 3), ('lemon', 2), ('lime', 5), ('orange', 3), ('melon', 2)]
[('apple', 1), ('banana', 3), ('lemon', 2), ('lime', 5), ('orange', 3), ('melon', 2)]
总之,如果某个表达式或赋值操作多次出现在一组代码里面,那就可以考虑用赋值表达式把这段diam改得简单一些。


















 3971
3971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











