










引言
本文主要介绍NLP的主要任务。
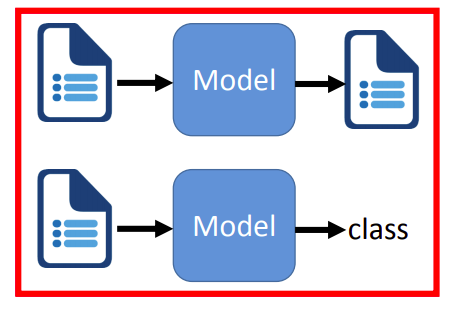
NLP相关的任务主要有两类,如上图所示。第一个是输入一段文字,输出一段文字;第二个是输入一段文字,输出一个类别。
虽然只有两类,但是实现它们的模型变化多端。不过,我们还可以做一些总结。
主要实现模型
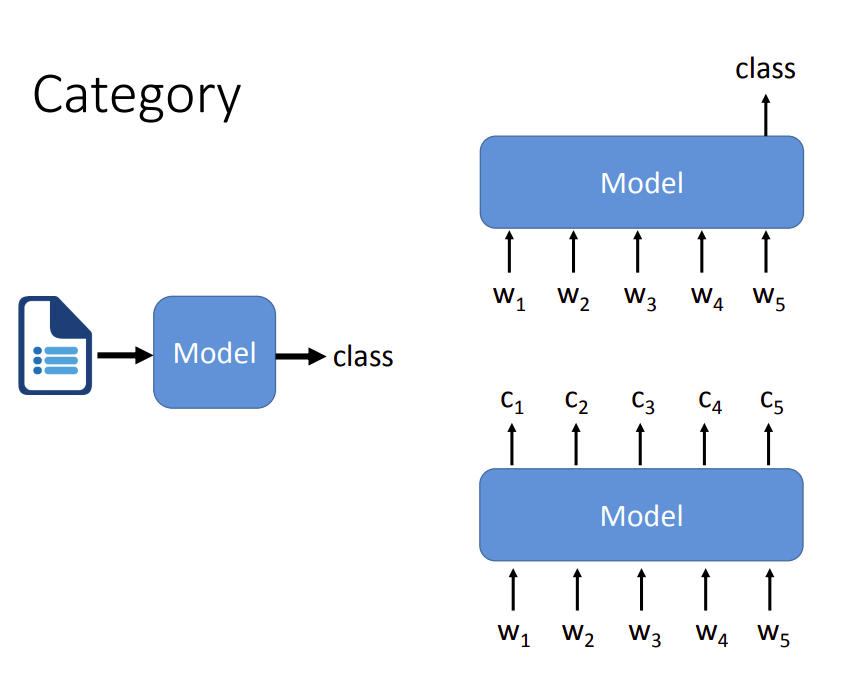
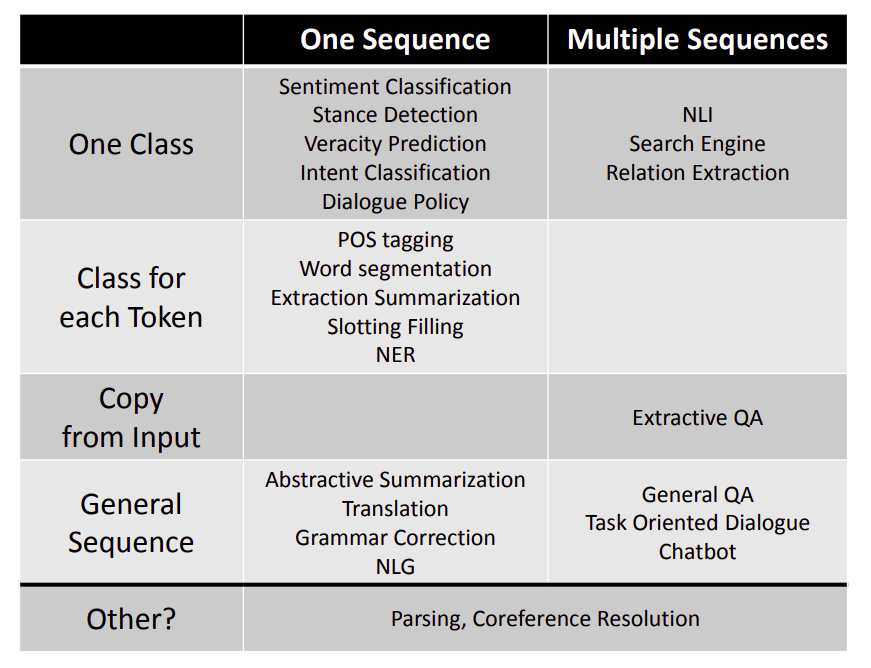
就输入一段文字,输出某个/某些类别来说,有上图右边两种实现。上面那个是输入一段文字,输出一个类别;另一个是输入一段文字,文字中每个单词输出一个类别。
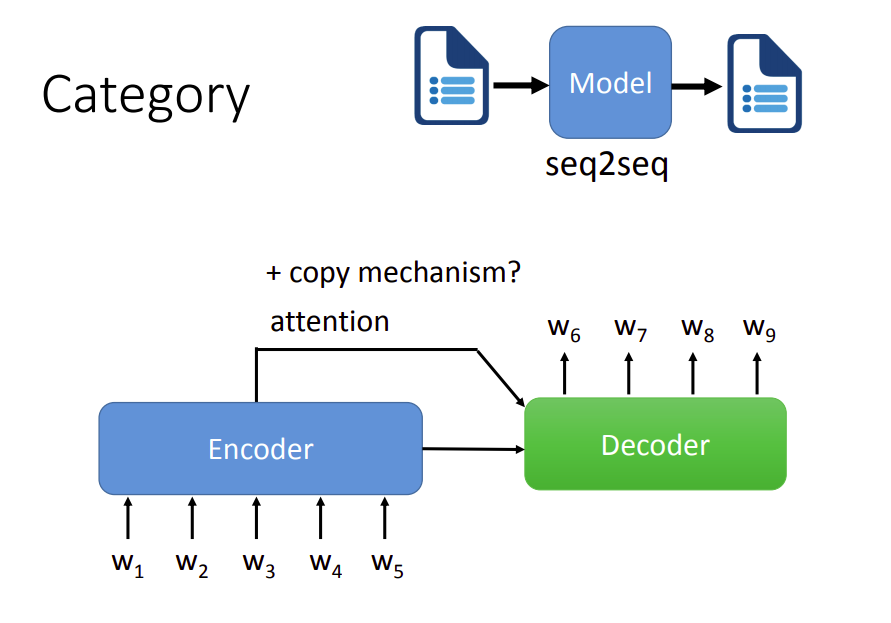
另外一种情况就是输入一段文字,输出一段文字。我们很容易想到Seq2Seq模型。在这种任务中,很多时候我们希望它有复制机制(copy mechanism)。
Decoder的输出不需要完全自己产生,有些词汇可以从Encoder中复制出来。
我们上面讲的是输出的部分,下面我们来看输入的部分。如果输入是一个序列,我们是没有问题的。
但是,如果输入的多个序列呢?

这里有两种做法,一种做法是把多个序列,比如两个,分别用一个模型去做编码,然后把这两个模型的输出用另一个模型取整合,得到最终的输出。有时候,我们会在编码模型之间增加注意力。

另外一种最近比较潮的做法是,直接把两个句子接起来,中间加上一个特殊的(<SEP>),用来分开两个句子。然后把接起来的句子输入到一个模型中就可以了。
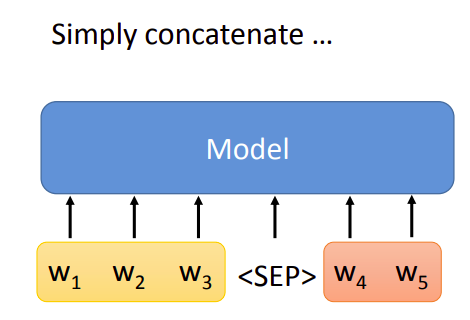
所以,虽然NLP的任务千变万化,但是根据模型的输入/输出可以分成几个大类。
下面就对上面这些任务做一些简单介绍。
Part-of-Speech(POS) Tagging
就是词性标注
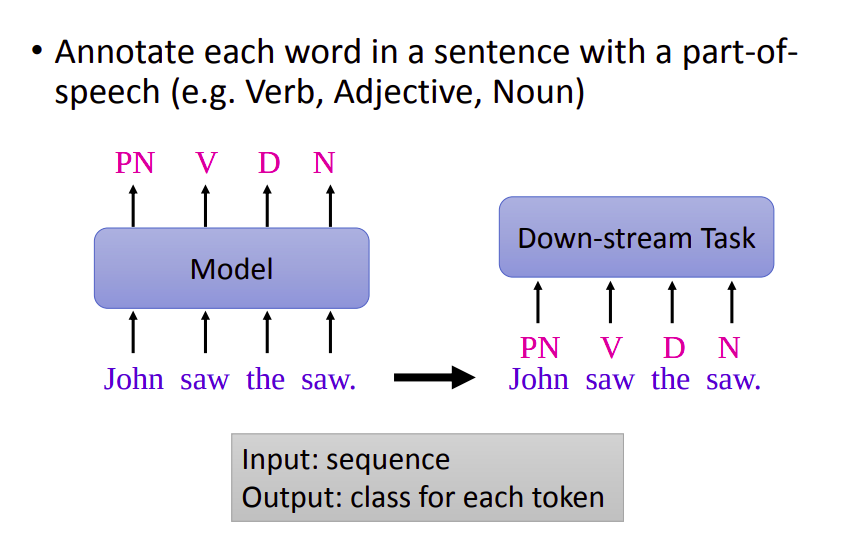
就是输入一个句子,输出句子中每个单词的词性。可能同样的单词需要输出不同的词性。
比如“John saw the saw.”,第一个“saw”(看见)是动词,第二个“saw”(锯子)是名词。
假设我们的模型能成功输出它们的词性,然后我们再把词性信息和单词喂给其他NLP模型中,可能会做的更好。
不过近年来的模型,像BERT,本身就有词性标注的能力,就不需要先做词性标注预处理了。
词性标注任务属于输入一个序列,输出序列中每个单词的类型。
分词
一般是用于中文等语言处理。像英文有空格作为分隔符,而中文字符之间没有分隔符,所以需要特别处理。
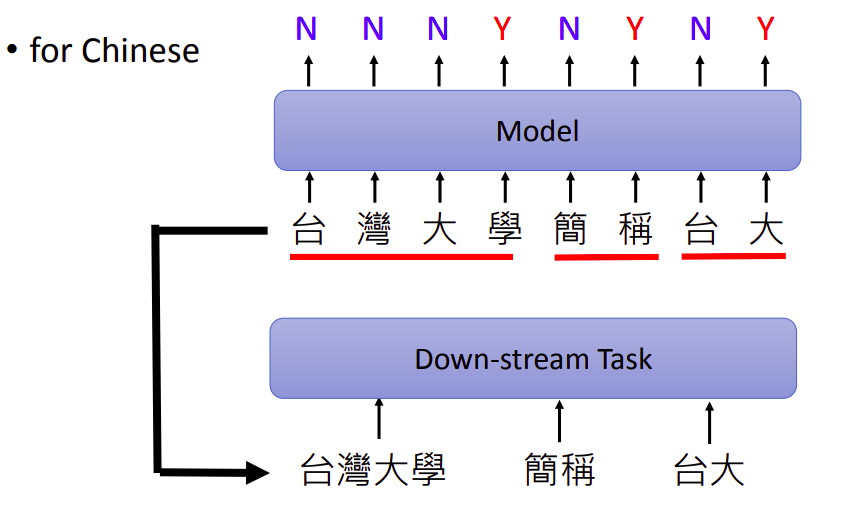
比如输入是“台湾大学简称台大”。我们要分词的话,可以分成“台湾大学/简称/台大”或“台湾/大学/简称/台大”。 有时候还存在一些争议,需要事先定义好边界。
但这也不是一个简单的问题,所以可以训练一个模型来做,输入每个字符,输出一个“Y/N”。
“Y”表示一个词汇的边界,“N”就不是词汇的边界。比如上面的“学”输出“Y”,表示“台湾大学”是一个词汇。
先用这样的分词模型做预处理,然后把属于同一个词汇的字符连起来,当成一个最小单位输入到其他下游模型。
但其实这件事情是否还有必要是一个可以讨论的问题,比如像BERT这种模型,它其实不以词汇作为单位,可以以字作为单位。就是BERT这个模型可能可以学到分词信息。

分词任务也属于输入一个序列,输出序列中每个单词的类型。
Parsing
还有一种也属于前期预处理的任务是句法分析。
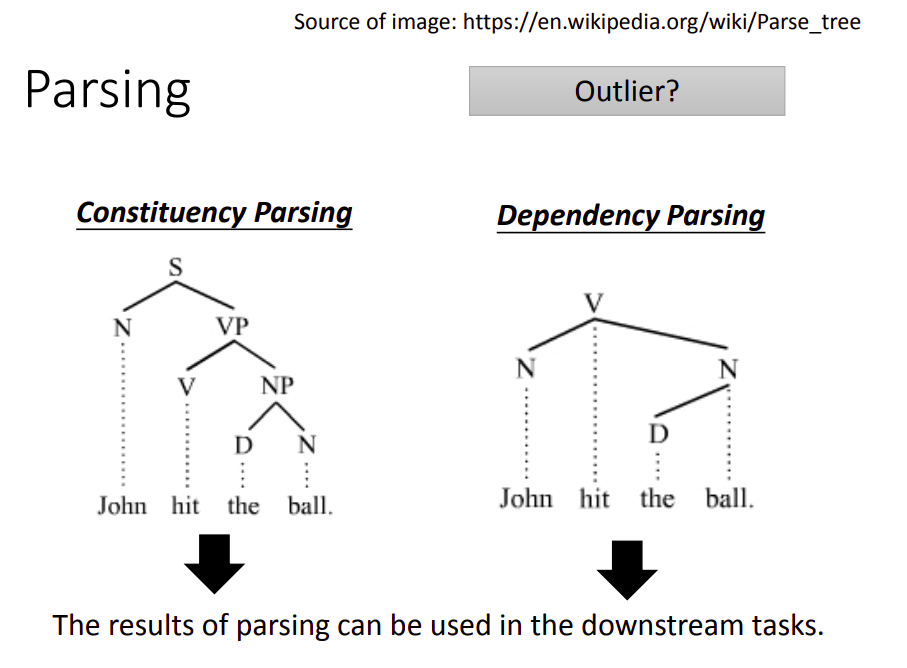
该任务主要有两种,不管哪种都是给一个句子,输出树状结构??!!
这看起来不在我们上面归纳的类别之中。是的,恐怕是一个例外。但是也可以强行当成输出一个序列,比如添加不同深度的括号来强行转换成一个序列。
Coreference Resolution
指代消解,就是要找出一篇文字中,哪些词汇指代的是同样的实体。

比如上面这篇文章中,同样的颜色,都是执向同一个实体。
指代消解好像也是一个特例。
Summarization
自动摘要
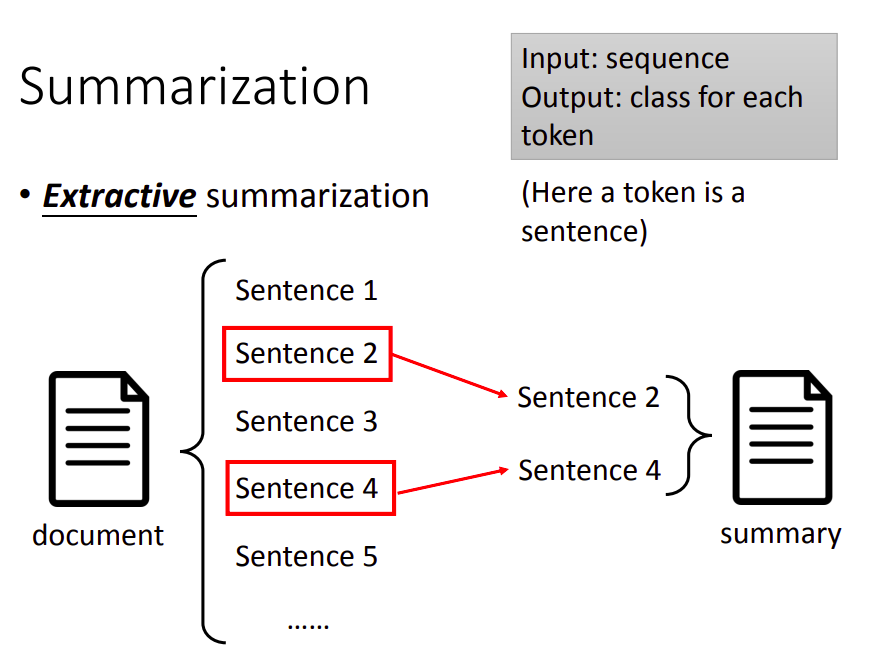
Extractive summarization的方法是从一篇文字中,抽取出一些句子,然后拼起来,作为摘要输出。其实可以看成是一个二分类问题,类型为是否需要将某个句子放到摘要中。
但是这种方法很难产生好的摘要,因为可能两个句子意思很接近,但是如果都放到摘要里面,是不是会重复了。
Extractive summarization可以看成是输入一个序列(文章),输出每个token(句子)的类型。
随着Seq2Seq模型的流行后,可以做Abstractive summarization。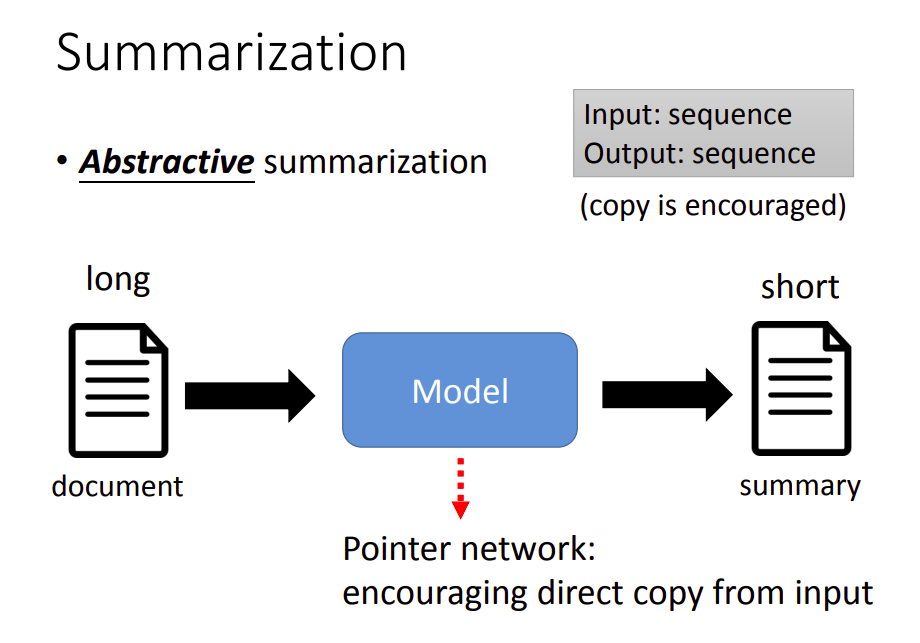
这种方法的思想是,让模型自己组织语言输出摘要,而不是从文章中抽取句子。不过在摘要任务中,复制的能力就很重要了,比如采用Pointer网络,让机器直接从原来的文章中,拷贝一些词汇,整理修饰再输出到摘要中。
这是输入是序列,输出也是序列的问题。
机器翻译
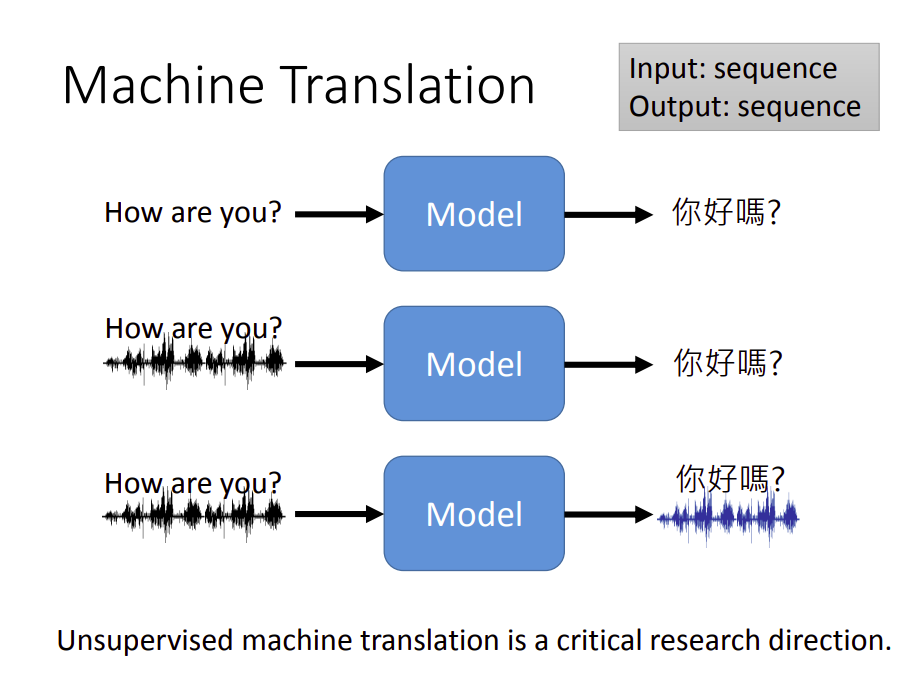
机器翻译是一个常见的序列到序列任务。现在除了可以做到,输入一段文字输出一段文字之外,还可以直接做到输入一段语音,直接输出文字。非常适用于方言翻译,比如将方言语音翻译成普通话,因为方言一般找不到文字去描述。
甚至输入和输出的语音都没有对应的文字,我们还可以做语音对语音的翻译。
对于机器翻译来说,无监督机器翻译是一个重要的研究方向。
Grammar Error Correction
语法纠错。

主流的语法纠错是通过seq2seq模型来实现的,并且鼓励复制能力。
Sentiment Classification
情绪识别。

这是一种输入是序列,输出是类别的任务。
Stance Detection
立场侦测。

立场侦测要做的事情是,给机器看一个评论(或微博),然后有人回复。机器需要检测这个回复,对这个评论的立场是什么。比如有人发了“李宏毅是个型男“,有回复说“他只是个死臭酸宅“。这个回复的立场就是反对。(自黑啊~下面放两张靓照让大家一睹芳容,再做决定)。
一般这种任务的类别即使支持/否定/疑问和Commenting(评论?)
该任务是输入两个序列,输出一个类别的问题。


立场侦测一般用在事实侦测(Veracity Prediction)任务里面。
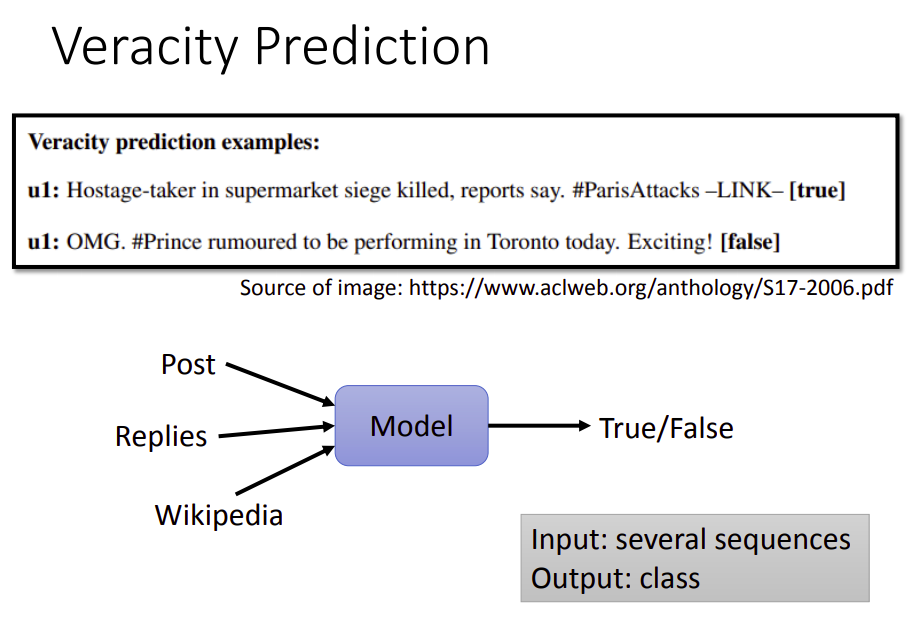
事实侦测做的事情是,让机器看一篇微博,然后判断该微博说的内容的真假。这么牛逼,机器能做到吗?
还是有办法的,具体是输入一篇微博(或者是一个论点)和它的所有回复以及相关的维基百科资料,输入内容的真假。当然效果还没有那么好,还需要继续努力。
整体来说就是输入多个序列,输出一个类别的问题。
Natural Language Inference(NLI)
自然语言推理
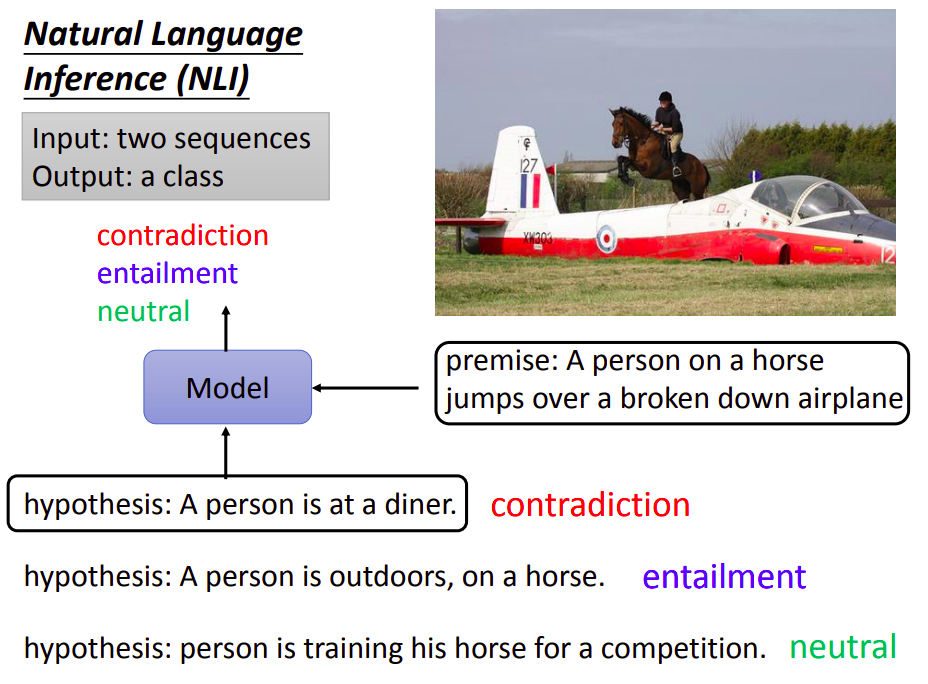
这个任务里面首先给机器一个前提,然后给定一个假设,需要机器判断能否从这个前提推出这个假设。
该任务输入是两个序列,输出是一个类别,类别包括:矛盾(contradiction)、蕴含(entailment)以及中立(neutral)。
Search Engine
搜索引擎
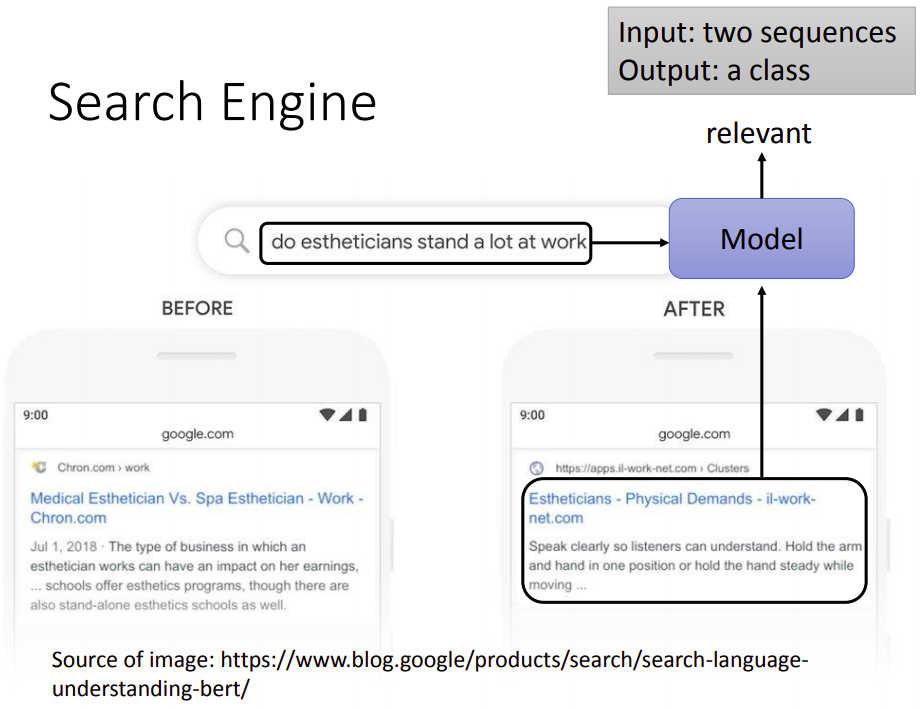
输入是一个搜索语句和一篇文章,输出这篇文章和这个语句的相关性。
这要是输入两个序列,输出一个类别的问题。
https://www.blog.google/products/search/search-languageunderstanding-bert/
Question Answering(QA)
问答
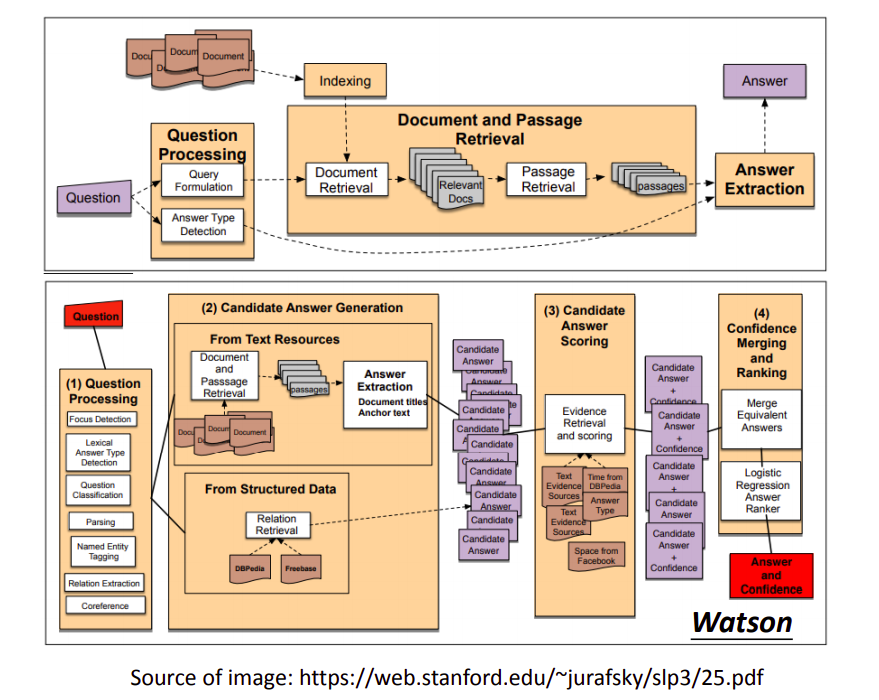
传统的问答系统如上图所示,其实说的有点像是阅读理解了,不是简单的相似问题搜索,而是利用简单的机器学习模型,从相关文章中抽取答案。
现在用深度学习方法来做的话,如下图所示。
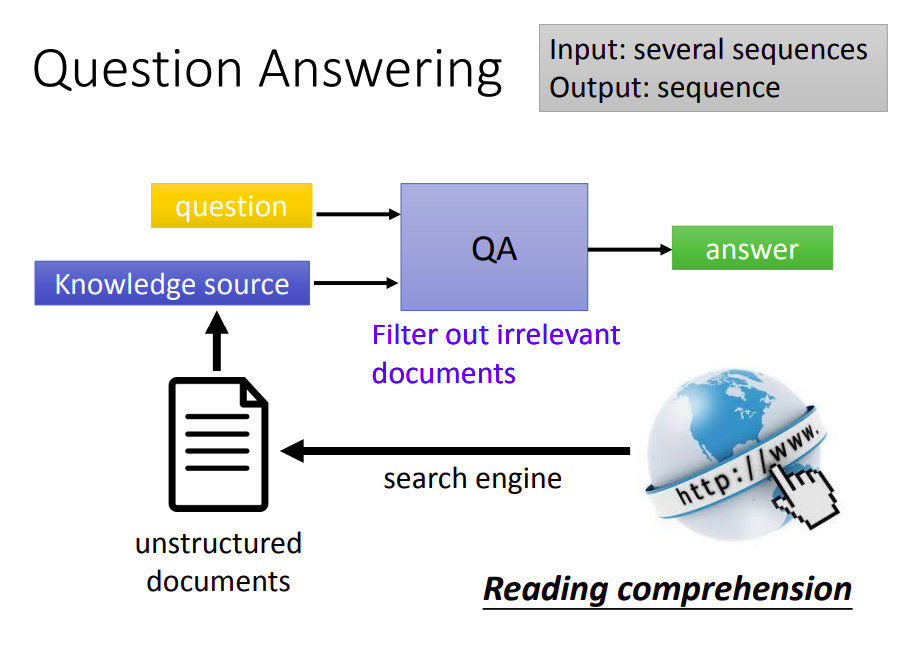
给定一个模型,输入是一个问题,和一个资料的来源(可以是结构化的资料库,或是无结构的文章,比如通过百度这种搜索引擎直接查询相关网页),输出是一个答案序列。这用任务现在叫做阅读理解,我们希望机器能够阅读无结构化的网页资料,从中抽出答案。
这要是一个输入多个序列,输出一个序列的问题。
不过要让机器输出一个完整答案,还有很长的路要走。
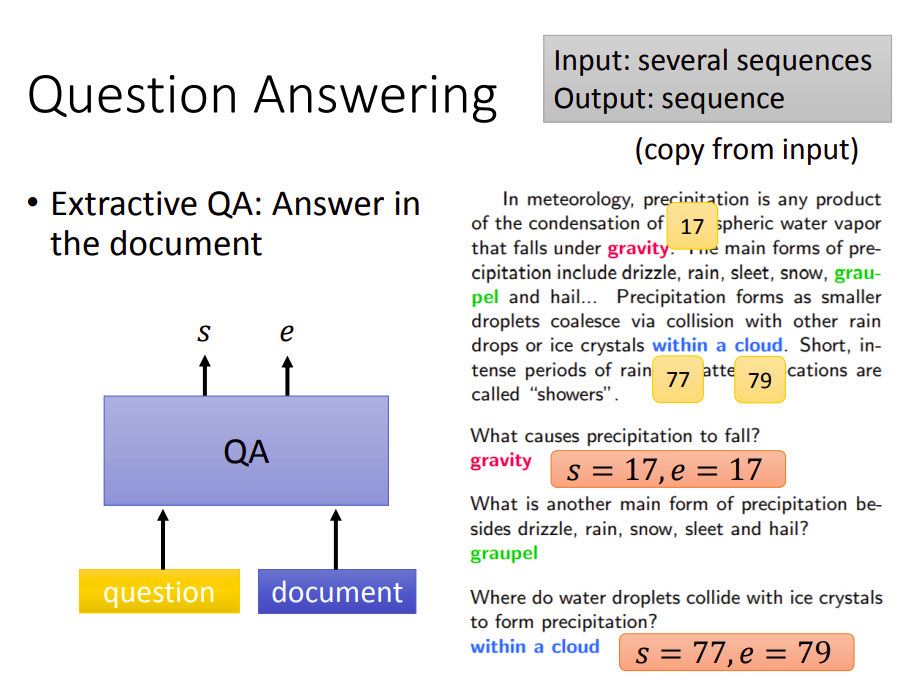
现在阅读理解主流的模型,还无法做到这一点。常做的是抽取式QA,即答案已经出现在文章里面了。
比如上面输入一篇文字,假设问题的正确答案是“gravity”,并且该词汇在文章中是提到的。所以可以简化模型,在这里需要强制使用复制功能,输入是问题和文章,直接输出两个数字,表示正确答案在文章中的起止位置(单词索引)。
Dialogue
对话

这里主要分析两种——尬聊(闲聊)的和任务导向的。
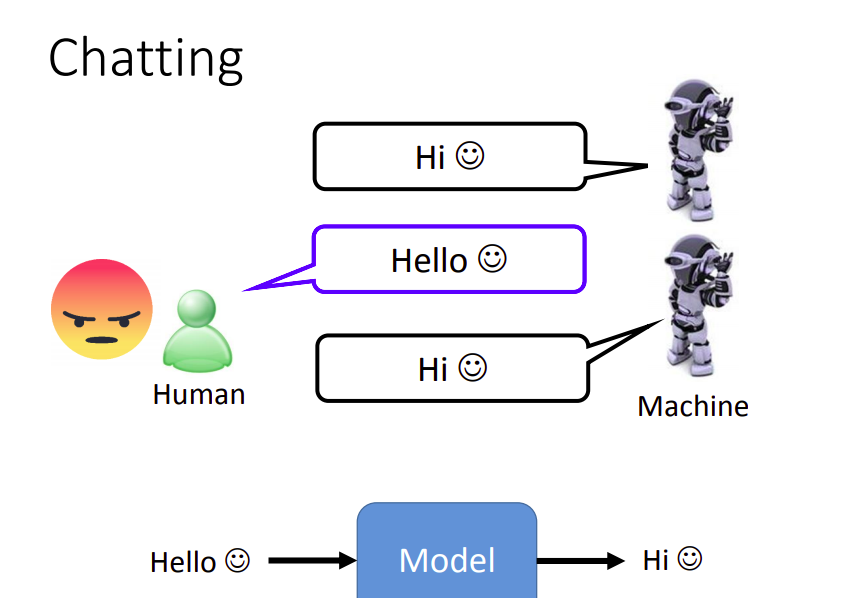
一般用Seq2Seq模型来训练闲聊机器人。但是如果不记得之前说过的话,可能得出的回答会比较奇怪。
比如假设机器说了“Hi”,人类回答“Hello”,但是机器不知道是因为它自己说了“Hi”,人来才回“Hello”,还是因为人类主动和它打招呼,从而导致可能又回复一个“Hi”做为“Hello”的回应。
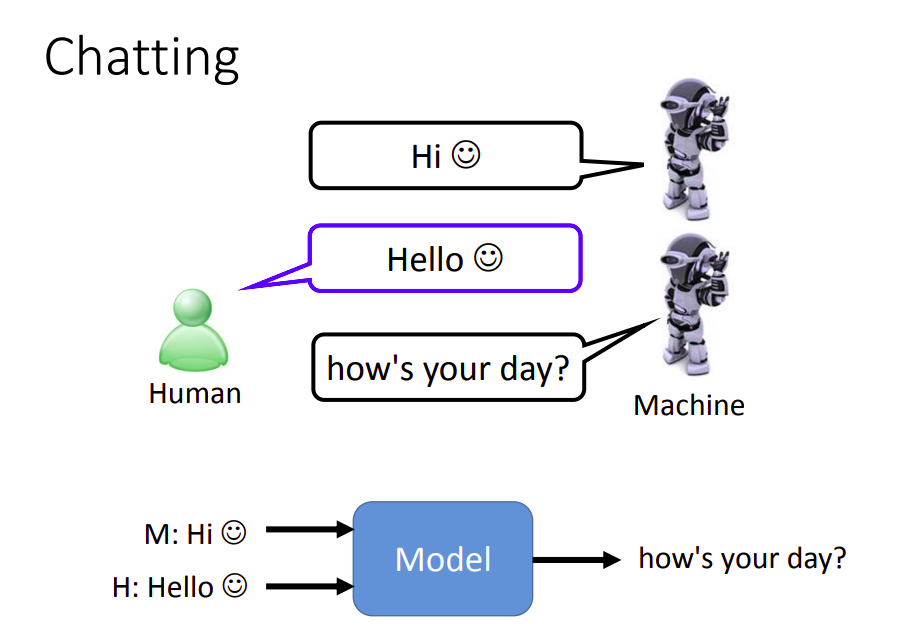
所以你的模型需要记住之前自己说过的话,和人类说过的话,即会话信息。
所以模型需要把之前对话的结果,多个句子,做为输入,然后才得到输出。
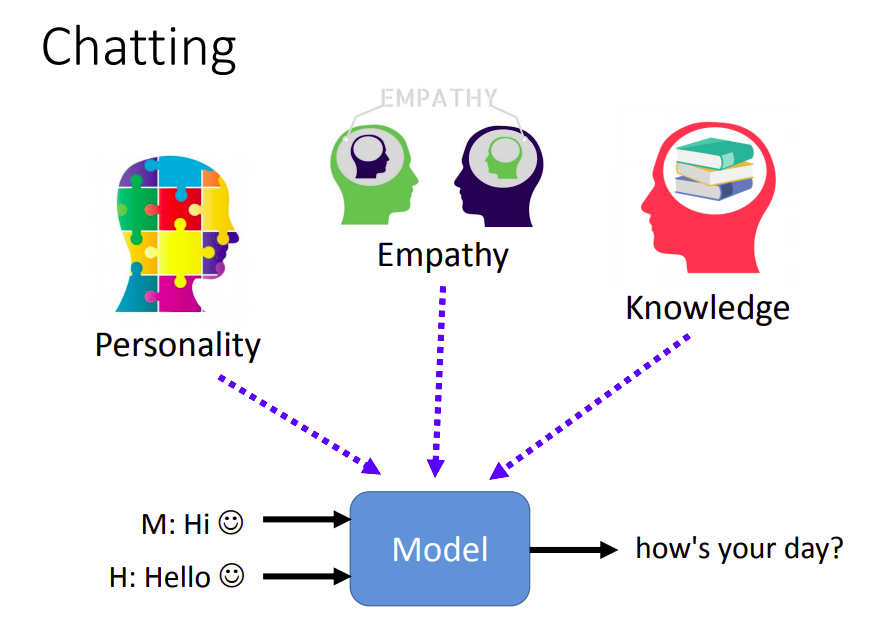
我们不仅希望机器人能记住会话信息,我们还希望它有个性(外向/内向)、同理心、博学多才等。
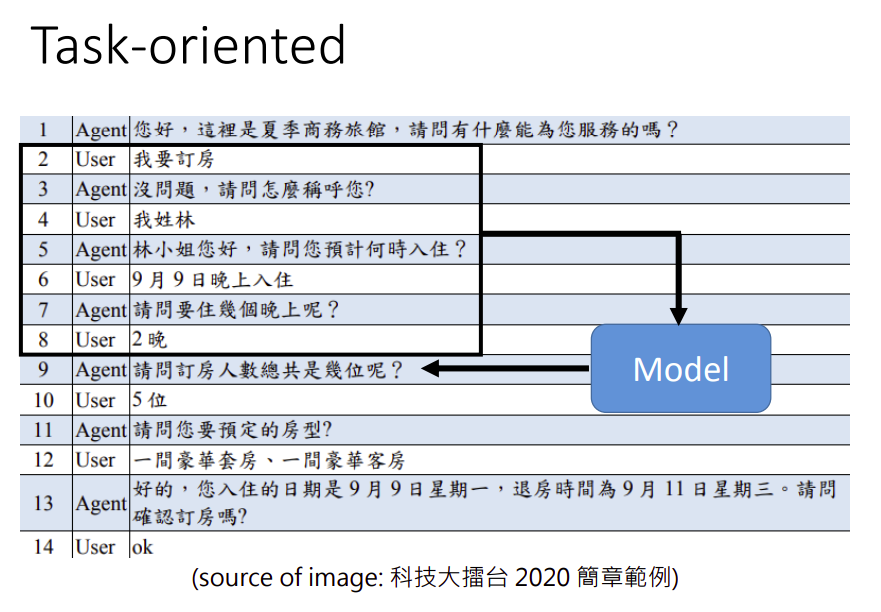
任务导向的对话一般是为了帮人完成某事,比如订票机器人。
这里神奇的地方是还能判断性别,可能是语音聊天。
这里的问题是输入过去的对话,输出是现在的回复。但是这样的模型我们会继续细分下去。
常见的细分方法首先会独立出一个自言语音生成(NLG)模块,比如在这个订房系统里面,机器要讲的话是有限的,不能尬聊。一开始需要设定好机器可以采取的行为(Action),比如可以打招呼,可以问入住日和退房日等。
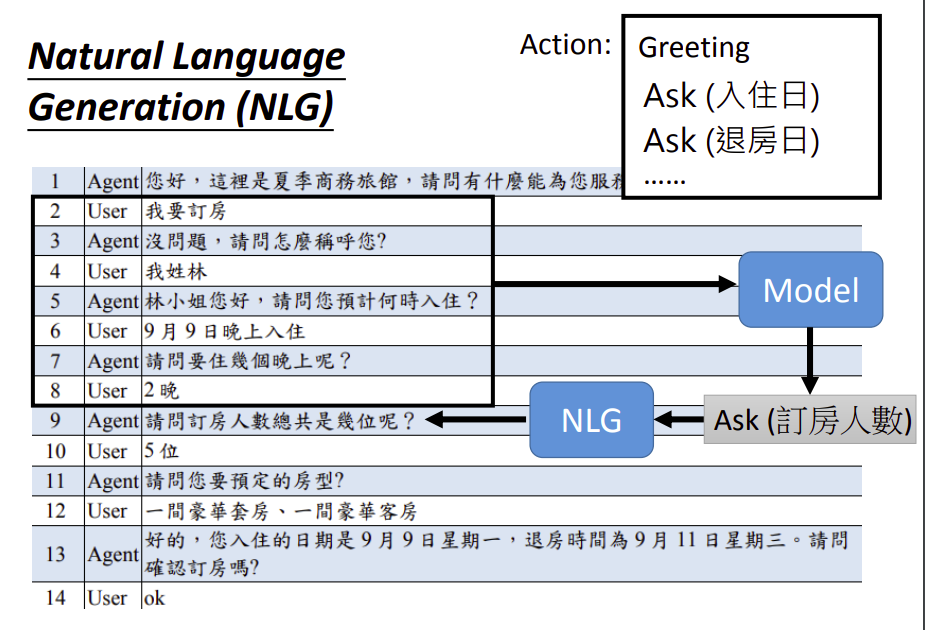
把会话信息输入给模型,接下来输出要采取哪个Action,然后喂给NLG模型,最后输出一串文字。
接下来还可以继续拆分,比如把上面的模型拆分成两个模块。
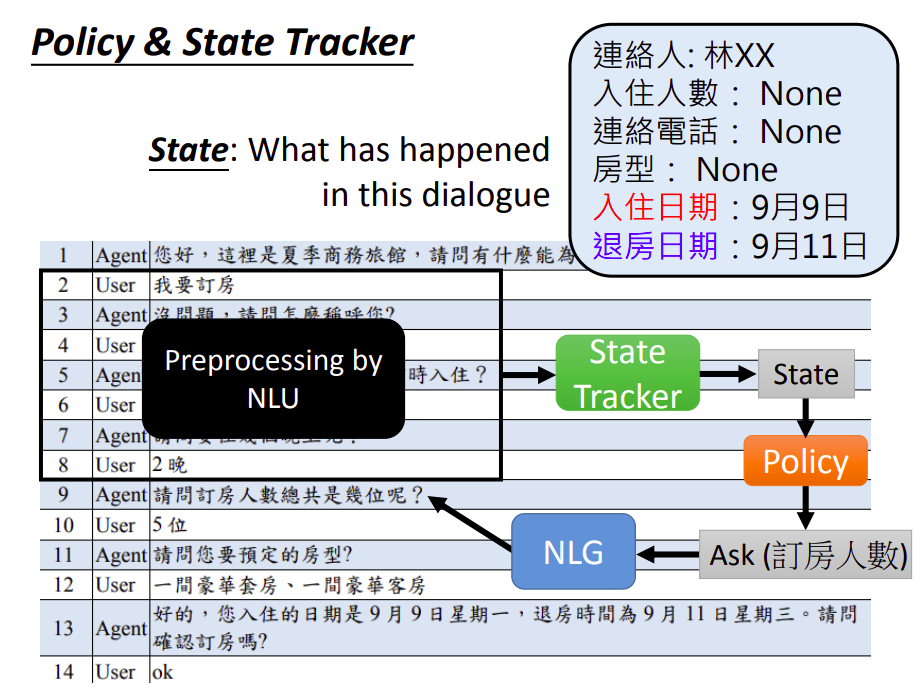
一个是Policy,另一个是State Tracker。
State是对历史对话信息进行一个总结。以这个订房系统为例,机器需要关心的可能非常有限,比如只需要关注订房人、入住人数、客户电话、房屋类型、入住日期和退房日期。
State Tracker需要输入一段对话,抽取出现在的State。
知道了State之后,会有一个Policy(策略),即根据State,决定后面要做什么事情。比如继续问关于未知状态信息。
State Tracker现在比较流行硬Train一发,但过去需要先做自言语言理解(NLU)。
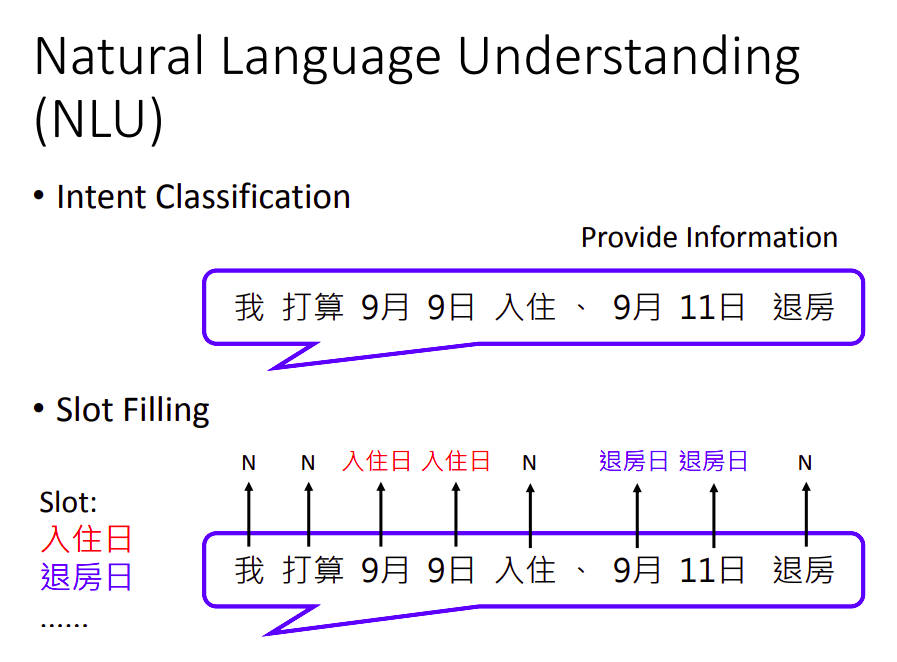
NLU通常指两个模块,一个是意图分类,另一个是填槽。
填槽任务需要先定义好Slot(槽位),然后给定一个句子,需要模型输出该句子中,哪些单词属于Slot,哪些不属于。
然后把得到的Slot输入给State Tracker。
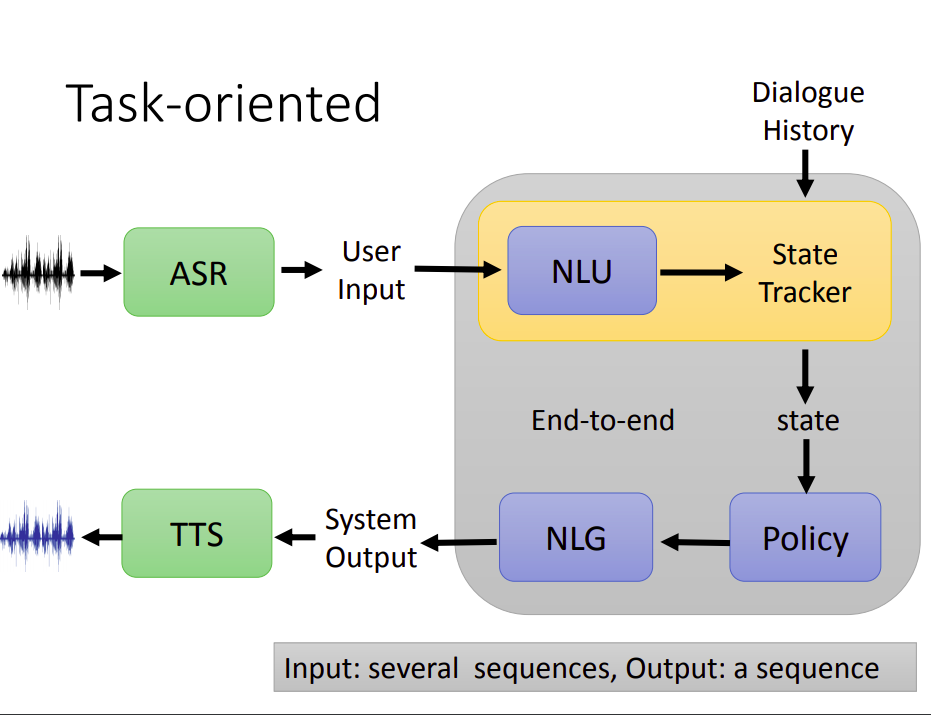
整个任务导向的对话如上图所示。当然可以直接端到端的学习,输入过去所有的对话,输出一个序列。
也可以把整个模型拆分成很多小的模块。
Knowledge Graph
知识图谱
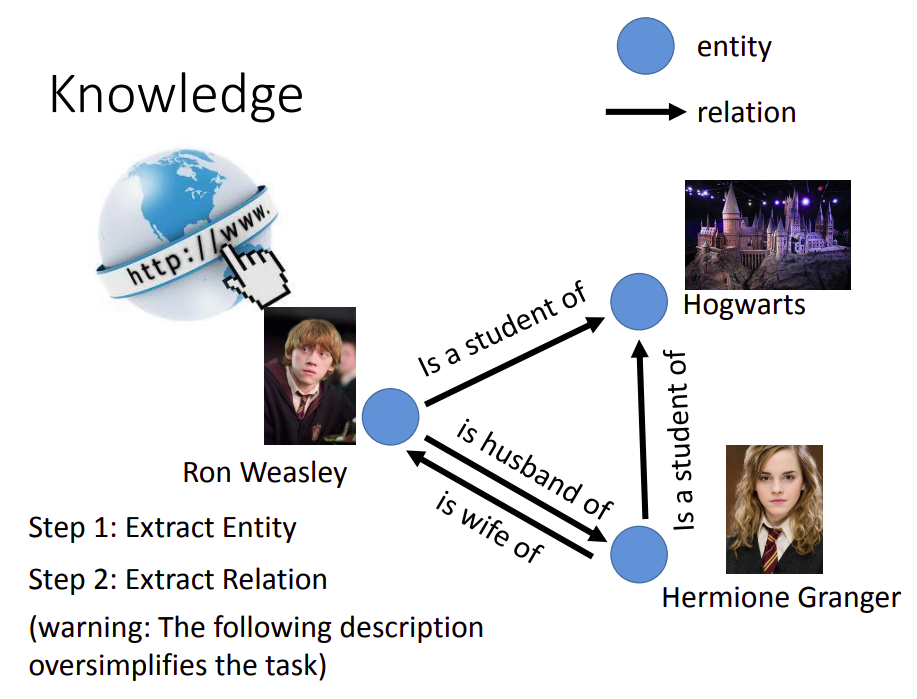
它就是一种图结构,其中的节点是实体,节点之间的有向边是关系。
现在有一个研究方法是输入大量的文档中让机器自己输出知识图谱。
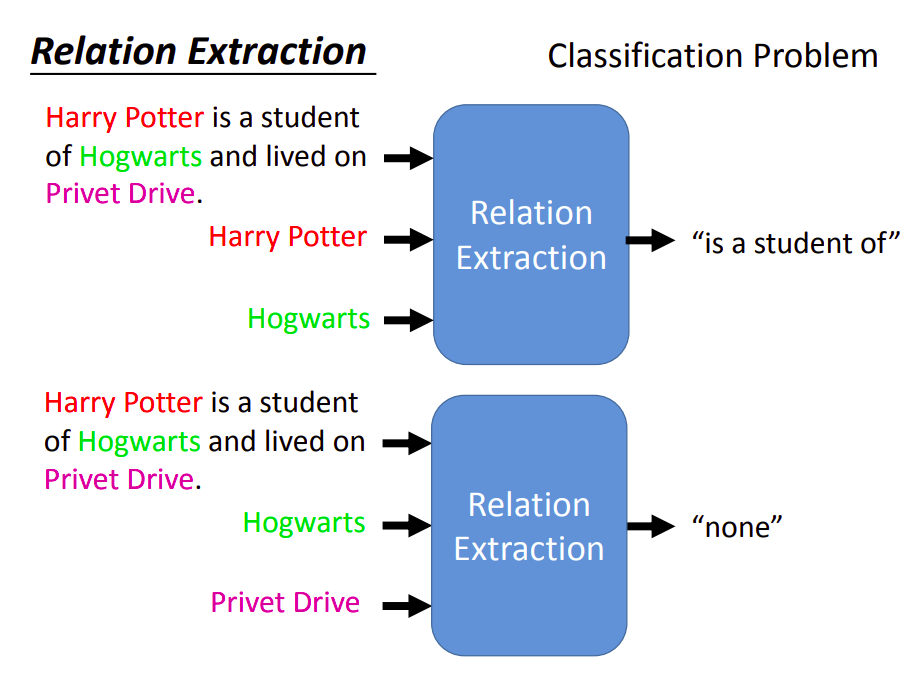
解决这个问题主要有两步:1. 抽取实体 2.抽取关系
要抽取实体,需要用到命名实体识别。

然后需要用到关系抽取。
General Language Understanding Evaluation(GLUE)
通用语言理解评估

过去都是为一个任务训练一个模型,现在比较流行训练一个模型能应用于多个任务。
通用语言理解评估
中文语言理解测评基准(CLUE),包括代表性的数据集、基准(预训练)模型、语料库、排行榜。我们会选择一系列有一定代表性的任务对应的数据集,做为我们测试基准的数据集。这些数据集会覆盖不同的任务、数据量、任务难度。
GLUE有三大任务:输入一个句子,输出句子类别;输入两个句子,输出两个句子是否相似;输入两个句子,输出这两个句子是否具有(矛盾、蕴含、中立)。
有了BERT之后,BERT在GLUE上面的表现已经很好了,主要是GLUE任务比较简单。因此,又有Super GLUE。
Super GLUE


Super GLUE有8个任务,主要和QA有关。
DecalNLP
Decal来自Decathlon(十项全能运动),希望通过一个模型来解决10个任务。
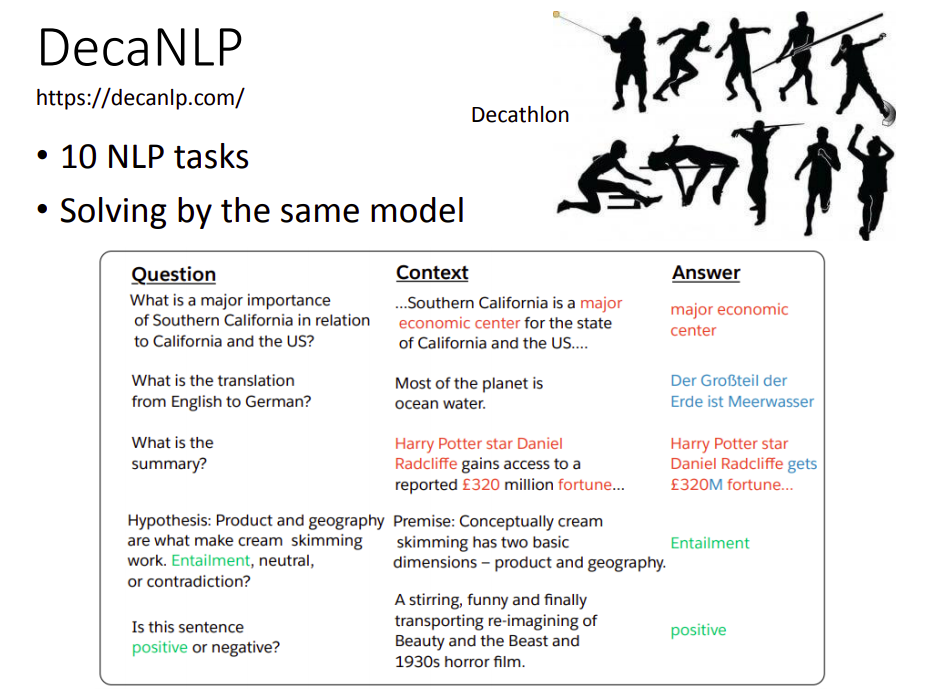
它有一个非常有趣的想法,所有不同的任务都是一个QA问题。
比如给机器一篇文字,然后再给一个输入“这篇文章的德文翻译是什么”,然后机器输出德文翻译。——机器翻译
给机器一篇文字,然后问机器“这篇文章的摘要是什么”,机器输出这篇文章的摘要。——自动摘要


















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











