






TCP协议中的三次握手和四次挥手(图解)
建立TCP需要三次握手才能建立,而断开连接则需要四次握手。整个过程如下图所示:
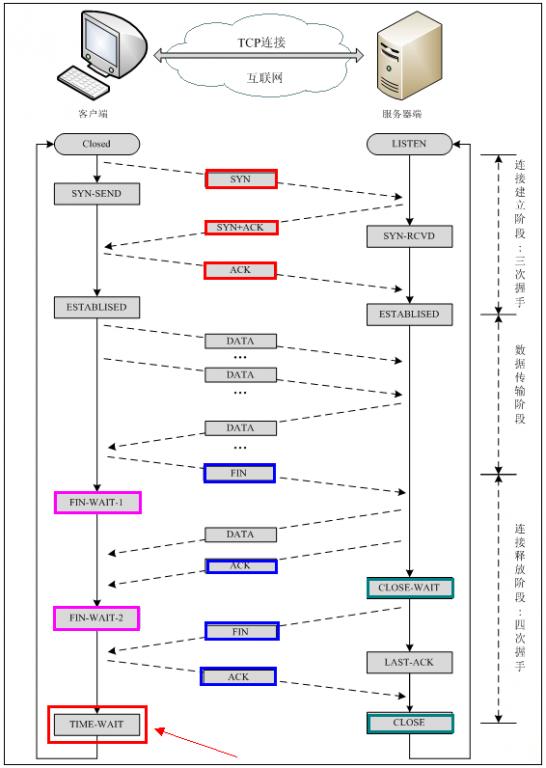
先来看看如何建立连接的。
【更新于2017.01.04 】该部分内容配图有误,请大家见谅,正确的配图如下,错误配图也不删了,大家可以比较下,对比理解效果更好。这么久才来更新,抱歉!!
错误配图如下:

首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。
那如何断开连接呢?简单的过程如下:
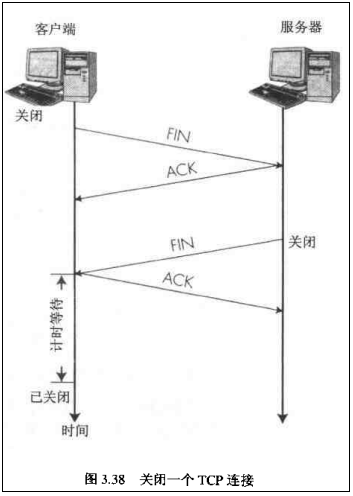
【注意】中断连接端可以是Client端,也可以是Server端。
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了
",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"
告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息
"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"
告诉Client端,好了,我这边数据发完了,准备好关闭连接了
"。Client端收到FIN报文后,"
就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传
。“,Server端收到ACK后,"
就知道可以断开连接了
"。Client端等待了2MSL后依然没有收到回复,则证明
Server端已正常关闭,那好,我Client端也可以关闭连接了
。Ok,TCP连接就这样关闭了!
整个过程Client端所经历的状态如下:
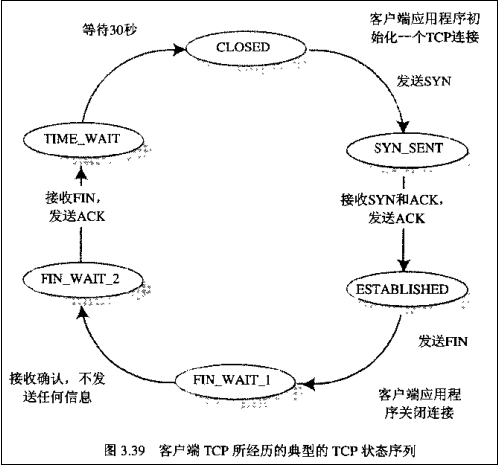
而Server端所经历的过程如下:转载请注明:blog.csdn.net/whuslei

【注意】 在TIME_WAIT状态中,如果TCP client端最后一次发送的ACK丢失了,它将重新发送。TIME_WAIT状态中所需要的时间是依赖于实现方法的。典型的值为30秒、1分钟和2分钟。等待之后连接正式关闭,并且所有的资源(包括端口号)都被释放。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
分类:
Linux网络编程
(10)
版权声明:Free Open Share 自由转载,注明出处!
1:listen()回顾以及问题引入
2:正确的解释
3:实验验证
1:listen()回顾以及问题引入
listen()函数是网络编程中用来
使服务器端开始监听端口的系统调用,首先来回顾下listen()函数的定义:
有关于第二个参数含义的问题网上有好几种说法,我总结了下主要有这么3种:
- Kernel会为LISTEN状态的socket维护一个队列,其中存放SYN RECEIVED和ESTABLISHED状态的套接字,backlog就是这个队列的大小。
- Kernel会为LISTEN状态的socket维护两个队列,一个是SYN RECEIVED状态,另一个是ESTABLISHED状态,而backlog就是这两个队列的大小之和。
- 第三种和第二种模型一样,但是backlog是队列ESTABLISHED的长度。
有关上面说的两个状态SYN RECEIVED状态和ESTABLISHED状态,是TCP三次握手过程中的状态转化,具体可以参考下面的图(在新窗口打开图片):
2:正确的解释
那上面三种说法到底哪个是正确的呢?我下面的说法翻译自这个链接:
http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
下面我翻译下作者的文章:
When an application puts a socket into LISTEN state using the listen syscall, it needs to specify a backlog for that socket. The backlog is usually described as the limit for the queue of incoming connections.
当一个应用使用listen系统调用让socket进入LISTEN状态时,它需要为该套接字指定一个backlog。backlog通常被描述为连接队列的限制。
Because of the 3-way handshake used by TCP, an incoming connection goes through an intermediate state SYN RECEIVED before it reaches the ESTABLISHED state and can be returned by the accept syscall to the application (see the part of the TCP state diagram reproduced above). This means that a TCP/IP stack has two options to implement the backlog queue for a socket in LISTEN state:
由于TCP使用的3次握手,连接在到达ESTABLISHED状态之前经历中间状态SYN RECEIVED,并且可以由accept系统调用返回到应用程序。这意味着TCP / IP堆栈有两个选择来为LISTEN状态的套接字实现backlog队列:
(备注:一种就是两种状态在一个队列,一种是分别在一个队列)
1 : The implementation uses a single queue, the size of which is determined by the backlog argument of the listen syscall. When a SYN packet is received, it sends back a SYN/ACK packet and adds the connection to the queue. When the corresponding ACK is received, the connection changes its state to ESTABLISHED and becomes eligible for handover to the application. This means that the queue can contain connections in two different state: SYN RECEIVED and ESTABLISHED. Only connections in the latter state can be returned to the application by the accept syscall.
1:使用单个队列实现,其大小由listen syscall的backlog参数确定。 当收到SYN数据包时,它发送回SYN/ACK数据包,并将连接添加到队列。 当接收到相应的ACK时,连接将其状态改变为已建立。 这意味着队列可以包含两种不同状态的连接:SYN RECEIVED和ESTABLISHED。 只有处于后一状态的连接才能通过accept syscall返回给应用程序。
2 : The implementation uses two queues, a SYN queue (or incomplete connection queue) and an accept queue (or complete connection queue). Connections in state SYN RECEIVED are added to the SYN queue and later moved to the accept queue when their state changes to ESTABLISHED, i.e. when the ACK packet in the 3-way handshake is received. As the name implies, the accept call is then implemented simply to consume connections from the accept queue. In this case, the backlog argument of the listen syscall determines the size of the accept queue.
2 : 使用两个队列实现,一个SYN队列(或半连接队列)和一个accept队列(或完整的连接队列)。 处于SYN RECEIVED状态的连接被添加到SYN队列,并且当它们的状态改变为ESTABLISHED时,即当接收到3次握手中的ACK分组时,将它们移动到accept队列。 显而易见,accept系统调用只是简单地从完成队列中取出连接。 在这种情况下,listen syscall的backlog参数表示完成队列的大小。
Historically, BSD derived TCP implementations use the first approach. That choice implies that when the maximum backlog is reached, the system will no longer send back SYN/ACK packets in response to SYN packets. Usually the TCP implementation will simply drop the SYN packet (instead of responding with a RST packet) so that the client will retry.
历史上,
BSD 派生系统实现的TCP使用第一种方法。 该选择意味着当达到最大backlog时,系统将不再响应于SYN分组发送回SYN/ACK分组。 通常,TCP的实现将简单地丢弃SYN分组,使得客户端重试。
On Linux, things are different, as mentioned in the man page of the listen syscall:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog.
在
Linux上,是和上面不同的。如在listen系统调用的手册中所提到的:
在Linux内核2.2之后,socket backlog参数的形为改变了, 现在它指等待 accept 的 完全建立 的套接字的队列长度,而不是不完全连接请求的数量。 不完全连接的长度可以使用/proc/sys/net/ipv4/tcp_max_syn_backlog设置。
在Linux内核2.2之后,socket backlog参数的形为改变了, 现在它指等待 accept 的 完全建立 的套接字的队列长度,而不是不完全连接请求的数量。 不完全连接的长度可以使用/proc/sys/net/ipv4/tcp_max_syn_backlog设置。
This means that current Linux versions use the second option with two distinct queues: a SYN queue with a size specified by a system wide setting and an accept queue with a size specified by the application.
这意味着当前Linux版本使用上面第二种说法,有两个队列:具有由系统范围设置指定的大小的SYN队列 和 应用程序(也就是backlog参数)指定的accept队列。
OK,说到这里,相信backlog含义已经解释的非常清楚了,下面我们用实验验证下这种说法:
3:实验验证
验证环境:
RedHat 7
Linux version 3.10.0-514.el7.x86_64
验证思路:
1:客户端开多个线程分别创建socket去连接服务端。
2:服务端在listen之后,不去调用accept,也就是不会从已完成队列中取走socket连接。
3:观察结果,到底服务端会怎么样?处于ESTABLISHED状态的套接字个数是不是就是backlog参数指定的大小呢?
2:服务端在listen之后,不去调用accept,也就是不会从已完成队列中取走socket连接。
3:观察结果,到底服务端会怎么样?处于ESTABLISHED状态的套接字个数是不是就是backlog参数指定的大小呢?
我们定义backlog的大小为5:
# define BACKLOG 5
看下我系统上默认的SYN队列大小:
也就是我现在两个队列的大小分别是 :
SYN队列大小:256
ACCEPT队列大小:5
ACCEPT队列大小:5
看看我们的服务端程序 server.c :
#include<stdio.h>#include<sys/types.h>#include<sys/socket.h>#include<sys/time.h>#include<netinet/in.h>#include<arpa/inet.h>#include<errno.h>#include<stdlib.h>#include<string.h>#include<unistd.h>
#define PORT 8888 //端口号#define BACKLOG 5 //BACKLOG大小
void my_err(const char* msg,int line)
{
fprintf(stderr,"line:%d",line);
perror(msg);
}
int main(int argc,char *argv[])
{
int conn_len;
int sock_fd,conn_fd;
struct sockaddr_in serv_addr,conn_addr;
if((sock_fd = socket(AF_INET,SOCK_STREAM,0)) == -1) {
my_err("socket",__LINE__);
exit(1);
}
memset(&serv_addr,0,sizeof(struct sockaddr_in));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if(bind(sock_fd,(struct sockaddr *)&serv_addr,sizeof(struct sockaddr_in)) == -1) {
my_err("bind",__LINE__);
exit(1);
}
if(listen(sock_fd,BACKLOG) == -1) {
my_err("sock",__LINE__);
exit(1);
}
conn_len = sizeof(struct sockaddr_in);
sleep(10); //sleep 10s之后接受一个连接
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
sleep(10); //同理,再接受一个
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
sleep(10); //同理,再次接受一个
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
while(1) {} //之后进入while循环,不释放连接
return 0;
}
#define PORT 8888 //端口号#define BACKLOG 5 //BACKLOG大小
void my_err(const char* msg,int line)
{
fprintf(stderr,"line:%d",line);
perror(msg);
}
int main(int argc,char *argv[])
{
int conn_len;
int sock_fd,conn_fd;
struct sockaddr_in serv_addr,conn_addr;
if((sock_fd = socket(AF_INET,SOCK_STREAM,0)) == -1) {
my_err("socket",__LINE__);
exit(1);
}
memset(&serv_addr,0,sizeof(struct sockaddr_in));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if(bind(sock_fd,(struct sockaddr *)&serv_addr,sizeof(struct sockaddr_in)) == -1) {
my_err("bind",__LINE__);
exit(1);
}
if(listen(sock_fd,BACKLOG) == -1) {
my_err("sock",__LINE__);
exit(1);
}
conn_len = sizeof(struct sockaddr_in);
sleep(10); //sleep 10s之后接受一个连接
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
sleep(10); //同理,再接受一个
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
sleep(10); //同理,再次接受一个
printf("I will accept one\n");
accept(sock_fd,(struct sockaddr *)&conn_addr,(socklen_t *)&conn_len);
while(1) {} //之后进入while循环,不释放连接
return 0;
}
客户端程序 client.c:
#include<stdio.h>#include<sys/types.h>#include<sys/socket.h>#include<netinet/in.h>#include<arpa/inet.h>#include<string.h>#include<strings.h>#include<stdlib.h>#include<unistd.h>#include<pthread.h>
#define PORT 8888#define thread_num 10 //定义创建的线程数量
struct sockaddr_in serv_addr;
void *func()
{
int conn_fd;
conn_fd = socket(AF_INET,SOCK_STREAM,0);
printf("conn_fd : %d\n",conn_fd);
if( connect(conn_fd,(struct sockaddr *)&serv_addr,sizeof(struct sockaddr_in)) == -1) {
printf("connect error\n");
}
while(1) {}
}
int main(int argc,char *argv[])
{
memset(&serv_addr,0,sizeof(struct sockaddr_in));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
inet_aton("192.168.30.155",(struct in_addr *)&serv_addr.sin_addr); //此IP是局域网中的另一台主机
int retval;
//创建线程并且等待线程完成
pthread_t pid[thread_num];
for(int i = 0 ; i < thread_num; ++i)
{
pthread_create(&pid[i],NULL,&func,NULL);
}
for(int i = 0 ; i < thread_num; ++i)
{
pthread_join(pid[i],(void*)&retval);
}
return 0;
}
#define PORT 8888#define thread_num 10 //定义创建的线程数量
struct sockaddr_in serv_addr;
void *func()
{
int conn_fd;
conn_fd = socket(AF_INET,SOCK_STREAM,0);
printf("conn_fd : %d\n",conn_fd);
if( connect(conn_fd,(struct sockaddr *)&serv_addr,sizeof(struct sockaddr_in)) == -1) {
printf("connect error\n");
}
while(1) {}
}
int main(int argc,char *argv[])
{
memset(&serv_addr,0,sizeof(struct sockaddr_in));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
inet_aton("192.168.30.155",(struct in_addr *)&serv_addr.sin_addr); //此IP是局域网中的另一台主机
int retval;
//创建线程并且等待线程完成
pthread_t pid[thread_num];
for(int i = 0 ; i < thread_num; ++i)
{
pthread_create(&pid[i],NULL,&func,NULL);
}
for(int i = 0 ; i < thread_num; ++i)
{
pthread_join(pid[i],(void*)&retval);
}
return 0;
}
编译运行程序,并用netstat命令监控服务端8888端口的情况:
$ gcc server.c -o server$ gcc client.c -o client -lpthread -std=c99# watch -n 1 “netstat -natp | grep 8888” //root执行
//watch -n 1 表示每秒显示一次引号中命令的结果
//netstat n: 以数字化显示 a:all t:tcp p:显示pid和进程名字 然后我们grep端口号8888就行了。$ ./server$ ./client
结果如下:
首先是watch的情况:
- 因为我们客户端用10个线程去连接服务器,因此服务器上有10条连接。
- 第一行的./server状态是LISTEN,这是服务器进程。
- 倒数第三行的./server是服务器已经执行了一次accept。
- 6条ESTABLISHED状态比我们的BACKLOG参数5大1。
- 剩余的SYN_RECV状态即使收到了客户端第三次握手回应的ACK也不能成为ESTABLISHED状态,因为BACKLOG队列中没有位置。
然后过了10s左右,等到服务器执行了第二个accept之后,服务器情况如下,它执行了第二个accept:
此时watch监控的画面如下:
- 和上面相比,服务器再次accept之后,多了一条./server的连接。
- 有一条连接从SYN_RECV状态转换到了ESTABLISHED状态,原因是accept函数从BACKlOG完成的队列中取出了一个连接,接着有空间之后,SYN队列的一个链接就可以转换成ESTABLISHED状态然后放入BACKlOG完成队列了。
好了,分析到这里,有关BACKLOG的问题已经解决了,至于继续上面的实验将backlog的参数调大会怎么样呢?我试过了,就是ESTABLISHED状态的数量也会增大,值会是BACKLOG+1,
至于为什么是
BACKLOG+1
呢???我也没有搞懂。欢迎指教。
当然,还有别的有意思的问题是 : 如果ESTABLISHED队列满了,可是有连接需要从SYN队列转移过来时会发生什么?
一边在喊:让我过来!我满足条件了。
一边淡淡的说:过个毛啊,没看没地方‘ 住 ‘ 吗?~
改天再细说吧,欢迎评论交流~
分类:
计算机网络
(17)
版权声明:Free Open Share 自由转载,注明出处!
由于标题长度有限制,我把想要描述的问题再次描述下:
内核通常会为每一个LISTEN状态的Socket维护两个队列:
1 accept队列: listen()函数第二个参数BACKLOG指定,表示已完成连接的队列,等待被accept函数取走。
2 SYN队列:由/proc/sys/net/ipv4/tcp_max_syn_backlog指定,表示处于SYN_RECV状态的队列。
2 SYN队列:由/proc/sys/net/ipv4/tcp_max_syn_backlog指定,表示处于SYN_RECV状态的队列。
现在的问题是:
如果accept队列已经满了,并且服务器没有使用accept函数取走任何连接,那么当一个连接需要从SYN队列移动到accept队列时会发生什么?
正确的解释
下面的部分我翻译自作者原文:
This case is handled by the tcp_check_req function in net/ipv4/tcp_minisocks.c, The relevant code reads:
这种情况由net/ipv4/tcp_minisocks.c中的tcp_check_req函数处理,相关代码如下:
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
if (child == NULL)
goto listen_overflow;
- 1
- 2
- 3
For IPv4, the first line of code will actually call tcp_v4_syn_recv_sock in net/ipv4/tcp_ipv4.c, which contains the following code:
对于IPv4,第一行代码实际上将调用net/ipv4/tcp_ipv4.c中的tcp_v4_syn_recv_sock,其中包含以下代码:
if (sk_acceptq_is_full(sk))
goto exit_overflow;
goto exit_overflow;
- 1
- 2
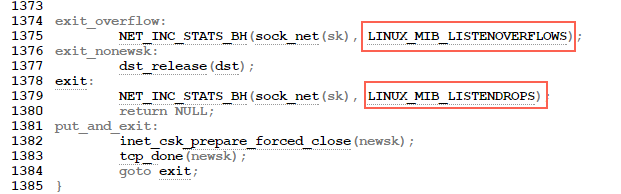
We see here the check for the accept queue. The code after the exit_overflowlabel will perform some cleanup, update the ListenOverflowsand ListenDrops statistics in /proc/net/netstat and then return NULL. This will trigger the execution of thelisten_overflowcode in tcp_check_req:
我们在这里看到了对于accept队列的检查。 exit_overflow的代码将执行一些清理,更新/proc/net/netstat中的ListenOverflows和ListenDrops统计信息,然后返回NULL。 这将触发在tcp_check_req中执行listen_overflow代码:
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
- 1
- 2
- 3
- 4
- 5
This means that unless /proc/sys/net/ipv4/tcp_abort_on_overflow is set to 1 , the implementation basically does… nothing!
这意味着只要/proc/sys/net/ipv4/tcp_abort_on_overflow被设置为1,在上面的if (!sysctl_tcp_abort_on_overflow)判断中为0,就不会执行下面代码,也就是Linux的策略是 :
什么都不干!!!!
备注:
这里的什么都不干对应的是:回应RST包,客户端出现connection reset by peer。
这里的什么都不干对应的是:回应RST包,客户端出现connection reset by peer。
To summarize, if the TCP implementation in Linux receives the ACK packet of the 3-way handshake and the accept queue is full, it will basically ignore that packet. At first, this sounds strange, but remember that there is a timer associated with the SYN RECEIVED state: if the ACK packet is not received (or if it is ignored, as in the case considered here), then the TCP implementation will resend the SYN/ACK packet (with a certain number of retries specified by /proc/sys/net/ipv4/tcp_synack_retries and using an exponential backoff algorithm).
总而言之,如果Linux中的TCP接收到3次握手的ACK数据包,并且接受队列已满,它将基本上忽略该数据包。 这听起来很奇怪,但是记住
有一个与SYN RECEIVED状态相关联的定时器:如果没有收到ACK分组(在这里我们考虑的情况是ACK被忽略,就和没有收到是一样的),则TCP将重新发送 SYN/ACK数据包(由/proc/sys/net/ipv4/tcp_synack_retries指定次数)。
备注:我的电脑是5
Since the TCP implementation on the client side gets multiple SYN/ACK packets, it will assume that the ACK packet was lost and resend it (see the lines with TCP Dup ACK in the above trace). If the application on the server side reduces the backlog (i.e. consumes an entry from the accept queue) before the maximum number of SYN/ACK retries has been reached, then the TCP implementation will eventually process one of the duplicate ACKs, transition the state of the connection from SYN RECEIVED to ESTABLISHED and add it to the accept queue. Otherwise, the client will eventually get a RST packet (as in the sample shown above).
由于客户端收到多个SYN/ACK分组,它将假定ACK分组丢失并重新发送它。 如果在达到最大SYN/ACK重试次数之前,服务器侧的应用程序减少了Accept队列大小(即调用accept来取接受队列的条目),则TCP将最终处理重复ACK中的一个,转变状态从SYN RECEIVED到ESTABLISHED的连接,并将其添加到accept队列。 否则,客户端将最终收到RST分组。
实验验证
验证环境:
RedHat 7
Linux version 3.10.0-514.el7.x86_64
验证思路:
- 模拟一个”忙”的服务器,保证它的accept队列被占满。
- 再用客户端连接。
使用wireshark抓包情况如下所示(在新的标签页打开图片):
- 前三个包是三次握手,143是客户端,155是服务器。
- 但是155服务器此时accept队列是满的,虽然143和它完成了三次握手,但是它仍然不能从SYN RECEIVED状态转换到ESTABLISHED状态。
- 此时由于SYN RECEIVED状态的定时器机制,服务器155没有收到ACK分组的时候(实际上是直接扔掉了),会继续给客户端143发送SYN/ACK数据包,143以为服务器没有收到ACK,然后回复ACK,这也就是”黑色”的包为什么有10个的原因了,服务器发送的SYN/ACK有5个,客户端回复的ACK有5个,就是/proc/sys/net/ipv4/tcp_synack_retries定义的。
我的疑问:
按道理,客户端最后是会收到服务器端发送的RST数据包的。但是我不知道多长时间之后会发,于是我等了很久(2小时)。此时服务器端通过netstat命令查看已经没有任何客户端的连接信息了,但是客户端查看和服务器的连接却是ESTABLISHED状态。很奇怪,这样的话客户端什么时候退出呢? 难道它一直卡在那里?
ps : 重新测了以下,服务器丢掉SYN RECEIVED状态的客户端时间大概是1分钟,也就是客户端连接过来,服务器Accept队列满的话,大概一分钟之后服务器就会丢失这个连接。但是此时客户端维持着一条ESTABLISHED状态的连接~~,它到底什么时候释放呢?
Linux协议栈accept和syn队列问题
Linux协议栈accept和syn队列问题
转载 2014年08月23日 20:38:32
环境:
Client
通过
tcp
连接
server
,
server
端只是
listen
,但是不调用
accept
。通过
netstat –ant
查看两端的连接情况。
server端listen,不调用accept。
client一直去connect server。
问题:
运行一段时间后,为什么
server
端的
ESTABLISHED
连接的个数基本是固定的
129
个,但是
client
端的
ESTABLISHED
连接的个数却在不断增加?
分析
Linux内核协议栈为一个tcp连接管理使用两个队列,一个是半链接队列(用来保存处于SYN_SENT和SYN_RECV状态的请求),一个是accpetd队列(用来保存处于established状态,但是应用层没有调用accept取走的请求)。
第一个队列的长度是/proc/sys/net/ipv4/tcp_max_syn_backlog,默认是1024。如果开启了syncookies,那么基本上没有限制。
第二个队列的长度是/proc/sys/net/core/somaxconn,默认是128,表示最多有129个established链接等待accept。(为什么是129?详见下面的附录1)。
现在假设acceptd队列已经达到129的情况:
client发送syn到server。client(SYN_SENT),server(SYN_RECV)
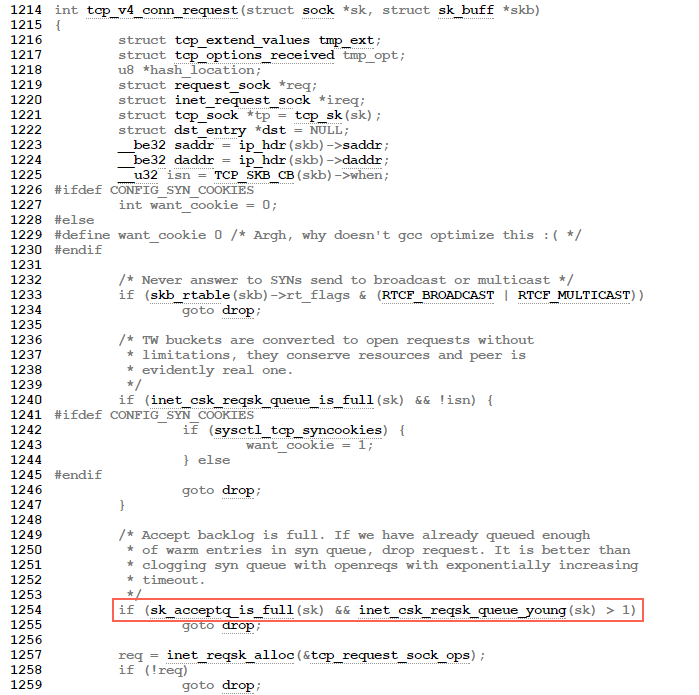
server端处理流程:tcp_v4_do_rcv--->tcp_rcv_state_process--->tcp_v4_conn_request
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_yong(sk)>1)
goto drop;
inet_csk_reqsk_queue_yong(sk)的含义是请求队列中有多少个握手过程中没有重传过的段。
在第一次的时候,之前的握手过程都没有重传过,所以这个syn包server端会直接drop掉,之后client会重传syn,当inet_csk_reqsk_queue_yong(sk) < 1,那么这个syn被server端接受。server会回复synack给client。这样一来两边的状态就变为client(ESTABLISHED), server(SYN_SENT)
Client收到synack后回复ack给server。
server端处理流程: tcp_check_req--->syn_recv_sock-->tcp_v4_syn_recv_sock
if(sk_acceptq_is_full(sk)
goto exit_overflow;
如果server端设置了sysctl_tcp_abort_on_overflow,那么server会发送rst给client,并删除掉这个链接;否则server端只是记录一下LINUX_MIB_LISTENOVERFLOWS(详见附录2),然后返回。默认情况下是不会设置的,server端只是标记连接请求块的acked标志,之后连接建立定时器,会遍历半连接表,重新发送synack,重复上面的过程(具体的函数是inet_csk_reqsk_queue_prune),如果重传次数超过synack重传的阀值(/proc/sys/net/ipv4/tcp_synack_retries),会把该连接从半连接链表中删除。
一次异常问题分析
Nginx
通过
FASTCGI
协议连接
cgi
程序,出现
cgi
程序
read
读取
socket
内容的时候永远
block
。通过
netstat
查看,
cgi
程序所在的服务器上显示连接存在,但是
nginx
所在的服务器上显示不存在该连接。
下面是原始数据图:
我们从上面的数据流来分析一下:
出现问题的时候,
cgi
程序(
tcp server
端)处理非常慢,导致大量的连接请求放到
accept
队列,把
accept
队列阻塞。
148021 nginx(tcp client
端
)
连接
cgi
程序,发送
syn
此时
server
端
accpet
队列已满,并且
inet_csk_reqsk_queue_yong(sk) > 1
,
server
端直接丢弃该数据包
148840 client
端等待
3
秒后,重传
SYN
此时
server
端状态与之前送变化,仍然丢弃该数据包
150163 client
端又等待
6
秒后,重传
SYN
此时
server
端
accept
队列仍然是满的,但是存在了重传握手的连接请求,
server
端接受连接请求,并发送
synack
给
client
端(
150164
)
150166 client
端收到
synack
,标记本地连接为
ESTABLISHED
状态,给
server
端应答
ack
,
connect
系统调用完成。
Server
收到
ack
后,尝试将连接放到
accept
队列,但是因为
accept
队列已满,所以只是标记连接为
acked
,并不会将连接移动到
accept
队列中,也不会为连接分配
sendbuf
和
recvbuf
等资源。
150167 client
端的应用程序,检测到
connect
系统调用完成,开始向该连接发送数据。
Server
端收到数据包,由于
acept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回。
150225 client
端由于没有收到刚才发送数据的
ack
,所以会重传刚才的数据包
150296
同上
150496
同上
150920
同上
151112 server
端连接建立定时器生效,遍历半连接链表,发现刚才
acked
的连接,重新发送
synack
给
client
端。
151113 client
端收到
synack
后,根据
ack
值,使用
SACK
算法,只重传最后一个
ack
内容。
Server
端收到数据包,由于
accept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回。
151896 client
端等待
3
秒后,没有收到对应的
ack
,认为之前的数据包也丢失,所以重传之前的内容数据包。
152579 server
端连接建立定时器生效,遍历半连接链表,发现刚才
acked
的连接,
synack
重传次数在阀值以内,重新发送
synack
给
client
端。
152581 cient
端收到
synack
后,根据
ack
值,使用
SACK
算法,只重传最后一个
ack
内容。
Server
端收到数据包,由于
accept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回
153455 client
端等待
3
秒后,没有收到对应的
ack
,认为之前的数据包也丢失,所以重传之前的内容数据包。
155399 server
端连接建立定时器生效,遍历半连接链表,发现刚才
acked
的连接,
synack
重传次数在阀值以内,重新发送
synack
给
client
端。
155400 cient
端收到
synack
后,根据
ack
值,使用
SACK
算法,只重传最后一个
ack
内容。
Server
端收到数据包,由于
accept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回。
156468 client
端等待几秒后,没有收到对应的
ack
,认为之前的数据包也丢失,所以重传之前的内容数据包。
161309 server
端连接建立定时器生效,遍历半连接链表,发现刚才
acked
的连接,
synack
重传次数在阀值以内,重新发送
synack
给
client
端。
161310 cient
端收到
synack
后,根据
ack
值,使用
SACK
算法,只重传最后一个
ack
内容。
Server
端收到数据包,由于
accept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回。
162884 client
端等待几秒后,没有收到对应的
ack
,认为之前的数据包也丢失,所以重传之前的内容数据包。
Server
端收到数据包,由于
accept
队列仍然是满的,所以
server
端处理也只是标记
acked
,然后返回。
164828 client
端等待一段时间后,认为连接不可用,于是发送
FIN
、
ACK
给
server
端。
Client
端的状态变为
FIN_WAIT1
,等待一段时间后,
client
端将看不到该链接。
164829 server
端收到
ACK
后,此时
cgi
程序处理完一个请求,从
accept
队列中取走一个连接,此时
accept
队列中有了空闲,
server
端将请求的连接放到
accept
队列中。
这样
cgi
所在的服务器上显示该链接是
established
的,但是
nginx(client
端
)
所在的服务器上已经没有该链接了。
之后,当
cgi
程序从
accept
队列中取到该连接后,调用
read
去读取
sock
中的内容,但是由于
client
端早就退出了,所以
read
就会
block
那里了。
问题解决
或许你会认为在
164829
中,
server
端不应该建立连接,这是内核的
bug
。但是内核是按照
RFC
来实现的,在
3
次握手的过程中,是不会判断
FIN
标志位的,只会处理
SYN
、
ACK
、
RST
这三种标志位。
从应用层的角度来考虑解决问题的方法,那就是使用非阻塞的方式
read
,或者使用
select
超时方式
read
;亦或者
nginx
中关闭连接的时候使用
RST
方式,而不是
FIN
方式。
附录1
when I use linux TCP socket, and find there is a bug in function sk_acceptq_is_full()
:
When a new SYN comes, TCP module first checks its validation. If valid,send SYN,ACK to the client and add the sock
to the syn hash table.
Next time if received the valid ACK for SYN,ACK from the client. server will accept this connection and increase the
sk->sk_ack_backlog -- which is done in function tcp_check_req().
We check wether acceptq is full in function tcp_v4_syn_recv_sock().
Consider an example:
After listen(sockfd, 1) system call, sk->sk_max_ack_backlog is set to
As we know, sk->sk_ack_backlog is initialized to 0. Assuming accept() system call is not invoked now
1. 1st connection comes. invoke sk_acceptq_is_full(). sk->sk_ack_backlog=0 sk->sk_max_ack_backlog=1, function return 0 accept this connection. Increase the sk->sk_ack_backlog
2. 2nd connection comes. invoke sk_acceptq_is_full(). sk->sk_ack_backlog=1 sk->sk_max_ack_backlog=1, function return 0 accept this connection. Increase the sk->sk_ack_backlog
3. 3rd connection comes. invoke sk_acceptq_is_full(). sk->sk_ack_backlog=2 sk->sk_max_ack_backlog=1, function return 1. Refuse this connection. I think it has bugs. after listen system call. sk->sk_max_ack_backlog=1
but now it can accept 2 connections.
3. 3rd connection comes. invoke sk_acceptq_is_full(). sk->sk_ack_backlog=2 sk->sk_max_ack_backlog=1, function return 1. Refuse this connection. I think it has bugs. after listen system call. sk->sk_max_ack_backlog=1
but now it can accept 2 connections.
附录2
netstat -s
cat /proc/net/netstat
最后感谢Tiger提供的测试数据
最后感谢Tiger提供的测试数据
转自:http://blog.chinaunix.net/uid-20662820-id-4154399.html
关于TCP 半连接队列和全连接队列
发表于 2017-05-25 | 作者 蛰剑 | 分类于
网络 |
最近碰到一个client端连接异常问题,然后定位分析并查阅各种资料文章,对TCP连接队列有个深入的理解查资料过程中发现没有文章把这两个队列以及怎么观察他们的指标说清楚,希望通过这篇文章能把他们说清楚一点
问题描述
JAVA的client和server,使用socket通信。server使用NIO。
1.间歇性的出现client向server建立连接三次握手已经完成,但server的selector没有响应到这连接。
2.出问题的时间点,会同时有很多连接出现这个问题。
3.selector没有销毁重建,一直用的都是一个。
4.程序刚启动的时候必会出现一些,之后会间歇性出现。
1.间歇性的出现client向server建立连接三次握手已经完成,但server的selector没有响应到这连接。
2.出问题的时间点,会同时有很多连接出现这个问题。
3.selector没有销毁重建,一直用的都是一个。
4.程序刚启动的时候必会出现一些,之后会间歇性出现。
分析问题
正常TCP建连接三次握手过程:
- 第一步:client 发送 syn 到server 发起握手;
- 第二步:server 收到 syn后回复syn+ack给client;
- 第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的56911端口的连接已经是established)
从问题的描述来看,有点像TCP建连接的时候全连接队列(accept队列)满了,尤其是症状2、4. 为了证明是这个原因,马上通过 ss -s 去看队列的溢出统计数据:
667399 times the listen queue of a socket overflowed
反复看了几次之后发现这个overflowed 一直在增加,那么可以明确的是server上全连接队列一定溢出了
接着查看溢出后,OS怎么处理:
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
0
tcp_abort_on_overflow 为0表示如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack(在server端认为连接还没建立起来)
为了证明客户端应用代码的异常跟全连接队列满有关系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。
接着测试然后在客户端异常中可以看到很多connection reset by peer的错误,到此证明客户端错误是这个原因导致的。
于是开发同学翻看java 源代码发现socket 默认的backlog(这个值控制全连接队列的大小,后面再详述)是50,于是改大重新跑,经过12个小时以上的压测,这个错误一次都没出现过,同时 overflowed 也不再增加了。
到此问题解决,简单来说TCP三次握手后有个accept队列,进到这个队列才能从Listen变成accept,默认backlog 值是50,很容易就满了。满了之后握手第三步的时候server就忽略了client发过来的ack包(隔一段时间server重发握手第二步的syn+ack包给client),如果这个连接一直排不上队就异常了。
深入理解TCP握手过程中建连接的流程和队列
如上图所示,这里有两个队列:syns queue(半连接队列);accept queue(全连接队列)
三次握手中,在第一步server收到client的syn后,把相关信息放到半连接队列中,同时回复syn+ack给client(第二步);
比如syn floods 攻击就是针对半连接队列的,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个队列满其它正常请求无法进来
第三步的时候server收到client的ack,如果这时全连接队列没满,那么从半连接队列拿出相关信息放入到全连接队列中,否则按tcp_abort_on_overflow指示的执行。
这时如果全连接队列满了并且tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,就很容易异常了。
在我们的os中retry 第二步的默认次数是2(centos默认是5次):
net.ipv4.tcp_synack_retries = 2
如果TCP连接队列溢出,有哪些指标可以看呢?
上述解决过程有点绕,那么下次再出现类似问题有什么更快更明确的手段来确认这个问题呢?
netstat -s
[root@server ~]# netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
比如上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
ss 命令
[root@server ~]# ss -lnt
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 50 *:3306 *:*
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 50 *:3306 *:*
上面看到的第二列Send-Q 表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。 不同版本的os会有些差异
实践验证下上面的理解
把java中backlog改成10(越小越容易溢出),继续跑压力,这个时候client又开始报异常了,然后在server上通过 ss 命令观察到:
Fri May 5 13:50:23 CST 2017
Recv-Q Send-QLocal Address:Port Peer Address:Port
11 10 *:3306 *:*
Recv-Q Send-QLocal Address:Port Peer Address:Port
11 10 *:3306 *:*
按照前面的理解,这个时候我们能看到3306这个端口上的服务全连接队列最大是10,但是现在有11个在队列中和等待进队列的,肯定有一个连接进不去队列要overflow掉
容器中的Accept队列参数
Tomcat默认短连接,backlog(Tomcat里面的术语是Accept count)Ali-tomcat默认是200, Apache Tomcat默认100.
#ss -lnt
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 100 *:8080 *:*
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 100 *:8080 *:*
Nginx默认是511
$sudo ss -lnt
State Recv-Q Send-Q Local Address:PortPeer Address:Port
LISTEN 0 511 *:8085 *:*
LISTEN 0 511 *:8085 *:*
State Recv-Q Send-Q Local Address:PortPeer Address:Port
LISTEN 0 511 *:8085 *:*
LISTEN 0 511 *:8085 *:*
因为Nginx是多进程模式,也就是多个进程都监听同一个端口以尽量避免上下文切换来提升性能
进一步思考
如果client走完第三步在client看来连接已经建立好了,但是server上的对应连接实际没有准备好,这个时候如果client发数据给server,server会怎么处理呢?(有同学说会reset,还是实践看看)
先来看一个例子:
如上图,150166号包是三次握手中的第三步client发送ack给server,然后150167号包中client发送了一个长度为816的包给server,因为在这个时候client认为连接建立成功,但是server上这个连接实际没有ready,所以server没有回复,一段时间后client认为丢包了然后重传这816个字节的包,一直到超时,client主动发fin包断开该连接。
这个问题也叫client fooling,可以看这里:
https://github.com/torvalds/linux/commit/5ea8ea2cb7f1d0db15762c9b0bb9e7330425a071 (感谢浅奕的提示)
从上面的实际抓包来看不是reset,而是server忽略这些包,然后client重传,一定次数后client认为异常,然后断开连接。
过程中发现的一个奇怪问题
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:58 CST 2017
1641685 times the listen queue of a socket overflowed
1641685 SYNs to LISTEN sockets ignored
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:59 CST 2017
1641906 times the listen queue of a socket overflowed
1641906 SYNs to LISTEN sockets ignored
Fri May 5 15:39:58 CST 2017
1641685 times the listen queue of a socket overflowed
1641685 SYNs to LISTEN sockets ignored
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:59 CST 2017
1641906 times the listen queue of a socket overflowed
1641906 SYNs to LISTEN sockets ignored
如上所示:
overflowed和ignored居然总是一样多,并且都是同步增加,overflowed表示全连接队列溢出次数,socket ignored表示半连接队列溢出次数,没这么巧吧。
overflowed和ignored居然总是一样多,并且都是同步增加,overflowed表示全连接队列溢出次数,socket ignored表示半连接队列溢出次数,没这么巧吧。
可以看到overflow的时候一定会drop++(socket ignored),也就是drop一定大于等于overflow。
同时我也查看了另外几台server的这两个值来证明drop一定大于等于overflow:
server1
150 SYNs to LISTEN sockets dropped
server2
193 SYNs to LISTEN sockets dropped
server3
16329 times the listen queue of a socket overflowed
16422 SYNs to LISTEN sockets dropped
server4
20 times the listen queue of a socket overflowed
51 SYNs to LISTEN sockets dropped
server5
984932 times the listen queue of a socket overflowed
988003 SYNs to LISTEN sockets dropped
150 SYNs to LISTEN sockets dropped
server2
193 SYNs to LISTEN sockets dropped
server3
16329 times the listen queue of a socket overflowed
16422 SYNs to LISTEN sockets dropped
server4
20 times the listen queue of a socket overflowed
51 SYNs to LISTEN sockets dropped
server5
984932 times the listen queue of a socket overflowed
988003 SYNs to LISTEN sockets dropped
那么全连接队列满了会影响半连接队列吗?
TCP三次握手第一步的时候如果全连接队列满了会影响第一步drop 半连接的发生。大概流程的如下:
tcp_v4_do_rcv->tcp_rcv_state_process->tcp_v4_conn_request
//如果accept backlog队列已满,且未超时的request socket的数量大于1,则丢弃当前请求
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_yong(sk)>1)
goto drop;
//如果accept backlog队列已满,且未超时的request socket的数量大于1,则丢弃当前请求
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_yong(sk)>1)
goto drop;
总结
全连接队列、半连接队列溢出这种问题很容易被忽视,但是又很关键,特别是对于一些短连接应用(比如Nginx、PHP,当然他们也是支持长连接的)更容易爆发。 一旦溢出,从cpu、线程状态看起来都比较正常,但是压力上不去,在client看来rt也比较高(rt=网络+排队+真正服务时间),但是从server日志记录的真正服务时间来看rt又很短。
希望通过本文能够帮大家理解TCP连接过程中的半连接队列和全连接队列的概念、原理和作用,更关键的是有哪些指标可以明确看到这些问题。
另外每个具体问题都是最好学习的机会,光看书理解肯定是不够深刻的,请珍惜每个具体问题,碰到后能够把来龙去脉弄清楚。
参考文章:
企业级互联网架构Aliware,让您的业务能力云化:
https://www.aliyun.com/aliware















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}