







文章截图均来自中国大学mooc Python网络爬虫与信息提取的教程,以上仅作为我的个人学习笔记。
下面是教程链接:https://www.icourse163.org/learn/BIT-1001870001?tid=1450316449#/learn/content?type=detail&id=1214620493&cid=1218397635&replay=true
中国最好大学(科软2020)
http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html
功能:输入网站的url、输出排名信息
技术路线:requests+bs4 库来实现
定向爬虫:只对于给定的url网页进行爬取不扩张爬取其他的url
非定向爬虫:可以从某一个url爬取更多url的信息
定向爬虫的可行性分析:判断我们需要提取的信息是不是包含在html页面中,部分信息可能通过Javascript等脚本语言生成。
动态脚本信息的爬取:这两个库完成不了,后续会用到其他的方法
过程:
- 先看下源码:要查询的数据是不是在html页面的源码中
- 看看是否有对应的Robots协议:www.zuihaodaxue.cn/robots.txt :发现网页不存在,说明并没有相关的爬虫限制
- 功能描述:

- 程序结构设计:采取二维列表

步骤1:getHTMLText() 、步骤2:fillUnivList() 、步骤3:printUnivList()
示例编写:

观察封装信息:tbody标签里面有多个tr标签各自对应一个大学、tr标签内部有包含了多个td标签各自对应大学基本信息。
可以使用遍历查找方法来进行获得,实际上我们的标签中可能出现字符串类型,所以做好事要过滤掉。
格式化输出:
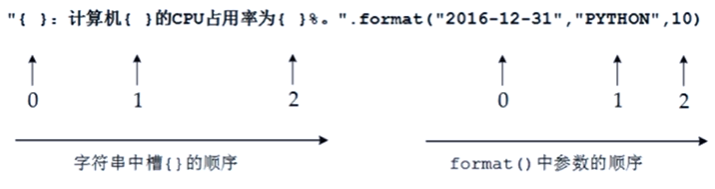
#CrawUnivRankingA.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[4].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
实例优化:字符填充有问题,采用中文字符填充
#CrawUnivRankingB.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming-zongbang-2020.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
单元小结:
















 7932
7932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









