




 本文深入探讨大数据挖掘中的关键问题,包括文档相似性检测、推荐系统和降维技术。通过minhashing和locality-sensitive hashing方法找到相似文档,使用协同过滤和内容基推荐来构建个性化推荐系统,并介绍了PCA和SVD在降维中的应用。
本文深入探讨大数据挖掘中的关键问题,包括文档相似性检测、推荐系统和降维技术。通过minhashing和locality-sensitive hashing方法找到相似文档,使用协同过滤和内容基推荐来构建个性化推荐系统,并介绍了PCA和SVD在降维中的应用。
//2019.06.03
一、概述
1、这本书是关于“data mining”的,但是它的关注点是在大数据挖掘上,它的观点是“在大数据上应用算法去挖掘信息,而不是使用ML去训练大数据”
Data mining is about applying algorithms to data, rather than using data to “train” a machine-learning engine of some sort.
2、目录
- 分布式文件系统和Map-reduce
- 相似搜索(包括minhashing和locality-sensitive hashing)
- 流数据处理
- 搜索引擎技术(Google PageRank,Link-spam detection,hubs-and-authorities approach)
- Frequent-itemset mining
- 降维算法
- 网络应用的两个关键问题
- 大规模图结构的分析算法
CH3:Finding Similar Items
一、概述
- data-mining的一个关键问题就是检测“相似”项目的数据。--->如何检测(document---(shingling)-->sets--(minhashing)-->short signatures)
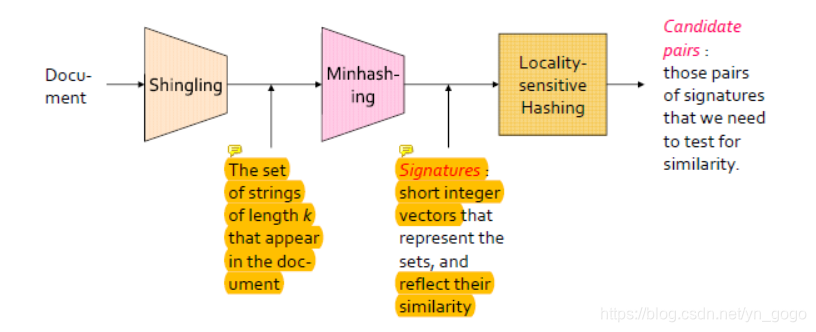
- 当我们搜索任何类似的项目时出现的另一个重要问题是,可能有太多的项目对来测试每一对的相似程度,即使计算任何一对的相似性可以非常容易。---->减少项目(locality-sensitive)
- 判断相似的方法
二、近邻搜索的应用(Applications of Near-Neighbor Search)
1、集合相似性--->Jaccard similarity
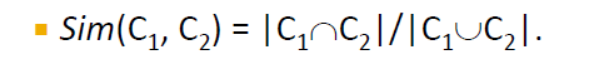
2、Similarity of Documents
Jaccard相似性很好地解决的一类重要问题是在诸如Web或新闻文章集合之类的大型语料库中找到文本上类似的文档。
但是我们这里强调的是“character-level similarity”,不是“similar meaning”,这要求我们去检测文档间的单词或者他们使用的单词。逐词比较,看是否一致,但在很多应用中,基本是不同的。
- 抄袭(找文本相似性)
- 镜像页面(Mirror Pages):镜像页面间是很相似的,很少有不同
- 相同来源的文章
3、协同过滤(Collaborative Filtering as a Similar-Sets Problem)
这是一类常见的应用,在推荐中常被应用,具体如下:
- 在线购物(On-Line Purchases):商品推荐
- 电影评级(Movie Ratings)
三、Shingling of Documents(步骤1:document--->set)
1、K-shingles:Define a k-shingle for a document to be any substring of length k found within the document.
Example:D is "abcdabd" ,k = 2, 2-shingles for D is{ab,bc,cd,da,bd}
Note that the substring ab appears twice within D, but appears only once as a shingle. A variation of shingling produces a bag, rather than a set, so each shingle would appear in the result as many times as it appears in the document. However, we shall not use bags of shingles here.(理解:应该是指子串的类型吧,该shingle应该是出现了多次)
2、k大小的选择设定
k的设定取决于典型文档的长度和典型字符的集合大小,重点要记住,k的选取的足够大以保证任何给定的shingles出现在任何文档的概率很低。
例如:对于emails,k=5
3、Hashing Shingles(Key technoogy)
在整个过程中,不是将子串直接作为元祖,而是选择哈希函数,将长度为k的子串映射到一系列buckets上,然后将相关bucket的标号作为shingle.那么表示的文档的结合是一个整数集合,那个整数,就是k-shingles所在的桶标号。这样使得数据被压缩,存储量大大减少
4、shingles bulit from words
在寻找相似新闻或者文章时,因为写作风格等原因,有些停用词(如“and”,"you"等)对我们的主题判断没有任何意义,,所以我们想忽略这些词,那么对于这个问题,我们要去找有用的shingles.
方法:找到一个shingle为定义的“stop word”,那么紧跟的两个词,不管是不是停用词,都形成了一组有用的shingles
Example:"A spokesperson for the Sudzo Corporation revealed today that studies have shown it is
good for people to buy Sudzo products.”
Here, we have italicized all the likely stop words,there are nine shingles from the sentence:
A spokesperson for
for the Sudzo
the Sudzo Corporation
that studies have
have shown it
it is good
is good for
for people to
to buy Sudzo
四、Similarity-Preserving Summaries of Sets(set----->signatures)
元组的集合太大了,尽管用标号来表示,也还是会很大。因而我们想减少他的存储量,这里引入“Signatures”,利用Signature 来比较两个集合的相似度。
1、集合的矩阵表示
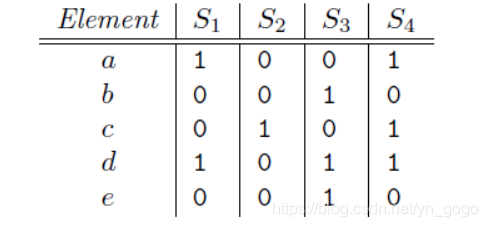
column:sets
rows:elements of the universal set from which elements of the sets are drawn
但是注意:矩阵不太可能作为数据的存储方式,因为它总是稀疏的,存储太浪费了,但是它可以用作数据的可视化。
2、Minhashing
(1)原理:对矩阵进行置换行排序,对于不同的行有不同minhash值,每次选择colum值为1的最小置换序号
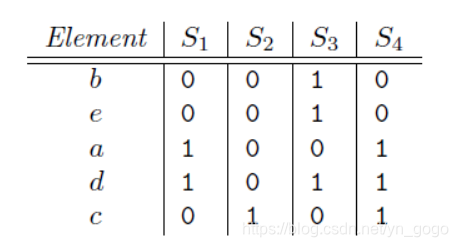 (例如对上图进行置换排列,顺序如左图)
(例如对上图进行置换排列,顺序如左图)
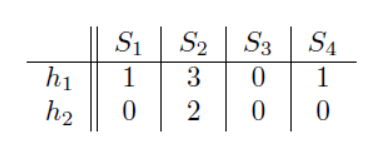
那么对于minhash(S1)=a,minhash(S2)=C,minhash(S3)=b,minhash(S4)=a
3、Minhashing and Jaccard Similarity
(1)所有随机顺序的的minhash最后产生的相同的概率值,与两个集合的Jaccard 相似度值相同。
(2)一般我们是用其来估计,选择100过或几百个来做,而不是把所有情况都给列出来。‘
(3)但是(2)中方式并不合理,明确置换是不可行的,每次做都要遍历一遍大数据集,这样非常耗时。
*但我们可以通过随机散列函数来模拟随机排列的效果,该函数将行数映射到和行数一样多的桶中
那么我们不需要置换列,只需要计算一次就可以把所有的请款计算得到
 (这里的行号可能会冲突)
(这里的行号可能会冲突)
那么此时我们就遍历一遍,每次都计算其minhash,每次更新,其值
a)初始状态
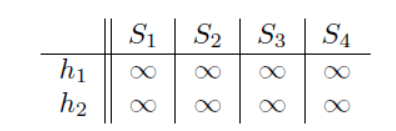
b)第一行(这两个函数的计算都是1,那么他们的minhash肯定是1,记录下来,但是S2,S3在此取不到minhash值,所以不用管)
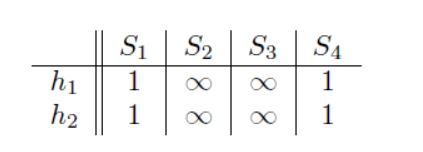
c)第二行(此时只有S3能取到一个排列的序号值,所以此时他的minhash是2,4)
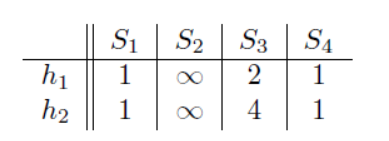
d)第三行(这里S2,S4取到,更新S2,但是S4取到的h值大于原来,所以不更新)

e)第四行(S1,S3,S4)
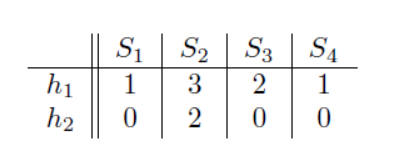
f)第五行
五、Locality-Sensitive Hashing for documents(LSH)
尽管用minhash将大的文档压缩成小的signature,来保存文档对的相似性,但是有特别多的文档pairs时,去寻找相似度还是不够高效的。但是如果目标是要计算每一个pair对,那么即使用同步计算,工作量也没有减少。
那么此时更换角度,大多数情况下,我们是想要计算那些高度相似或者说相似度高于某个值的pair对的相似度,换句话说,看起来可能相似的那些pair对的相似度,有些看起来就不相似的,其实可以忽略。
--->Locality-sensitive hashing(LSH)或者叫做near-neighbor search
(1)LSH的方法:通用方法是对项目多次hash,使得类似项目更可能被散列到相同的桶(排除了部分不相似的pair)。然后,考虑任何hash到同一个桶中的buckets是一个候选对,检查这些候选对的相似性。(我们希望,在这个桶里不相似的pair尽可能的少,即FP小,同时希望那些FN尽可能的小)
(2)choose hashing:
*把signature 矩阵划分为b bands(每个段有r行),那么我们对每个band设置一个hash 函数,采用r个整数的向量(该band内一列的部分行),并将其散列到一些桶中。可以对每个band使用相同的hash,但是我们为每个band使用单独的桶阵列,因此在不同band中具有相同矢量的列将不会hash到同一个桶(避免了一些不必要的相似错误)---><
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









