







Finding Similar Sets
在数据挖掘中有一个很基础的问题就是寻找相似项。比如“查找具有相似爱好的用户“等应用的本质就是查找相似项。
这一节介绍的就是如何寻找相似项。采用的相似度衡量概念为“Jaccard 相似度”,具体的意思在后文介绍,其主要思想就是两个集合的交集所占的比例越大则认为两者越相似。
对于数据量非常庞大的情况来讲逐一计算相似度肯定是不现实的,联系hash表的(可以快速寻找到特定元素而不用搜寻所有元素)的特性,首先使用Shingling算法,然后提出MinHashing来compress large sets以及
locality-sensitive Hashing 来 find similar documents or similar sets without doing anything that involves searching all pairs.
Applications of Set-Similarity
- 寻找相似主题或相似内容的网页
- 推荐系统:对同一用户按口味推荐可能喜欢的电影
- 寻找有相似受众的电影
- 实体解析
Similar Documents
以寻找具有相似的text or words的文档为例(不是相似topic),这一例子有很多现实应用:
- 寻找镜像网页,从而避免在搜索结果中重复出现
- 找到抄袭页面,包括只是大量引用且有改动的情况
- 将描写相同事件的网页聚在一起,呈现在结果页面
这些例子中虽然各个页面的内容大部分是一致的,但是各自有各自的改动或特点,比如同一新闻在不同新闻网站上logo、link甚至标题都会有轻微不同,单纯进行逐个单词的比较来计算相似肯定是不对的。
对于处理相似文本,我们需要三种技术:

1. Shingling:Jaccard相似度需要计算集合的交集,因此需要将文档转换为集合形式,这一步称为Shingling;
2. Minhashing:将上一步得到的sets转变为一些短的signatures同时保留sets之间的相似度;
3. Locality-sensitive Hashing:我们知道即使文本的数量只是million级的,要计算signatures间的相似度则有trillion级别的pairs要计算,而LSH可以实现只计算部分相似度很高的signature pairs就可以几乎得到所有的相似项。
这是整体的流程图:
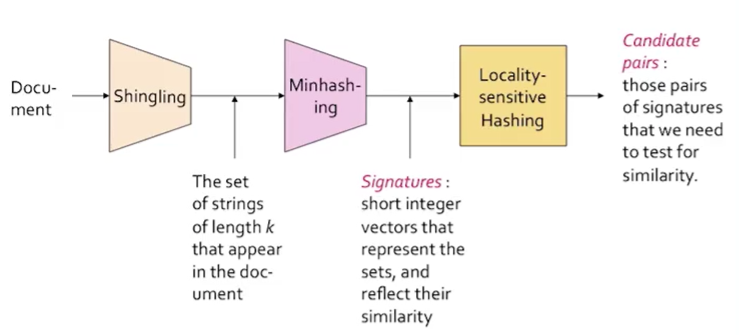
下面我们分别讲解这三个步骤的实现方式
Shingles
把相邻的k个字符作为一个元素,从而将整篇文档变为一个集合,通常将k值设在5~10之间。对于K值的选择依赖于文档的长度以及文档中词语的评价长度,最好保证任一shingle在文档中所占的比例都很小。

Shingles and Similarity

shingles:Compress Option

Minhashing
Jaccard similarity Measure
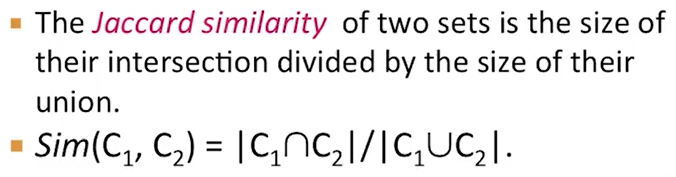
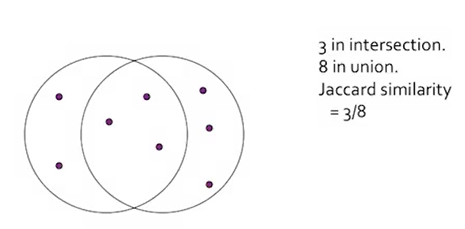
Example:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









