






前言
本文介绍了用于红外小目标检测的深度学习方法HCF-Net及其在YOLOv11中的结合应用。HCF-Net采用升级版U-Net架构,包含PPA、DASI和MDCR三个关键模块。PPA模块利用分层特征融合和注意力机制,采用多分支特征提取策略,捕获不同尺度和级别的特征信息;DASI模块增强跳跃连接,实现高低维特征的自适应融合;MDCR模块通过深度可分离卷积捕获空间特征。我们将PPA模块集成进YOLOv11,替换部分原有模块。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
红外小目标检测作为计算机视觉领域的重要研究方向,专注于红外图像中仅包含数个像素的微小目标的识别与定位任务。然而,由于目标尺寸极小且红外图像背景复杂度高,该任务面临严峻的技术挑战。本文提出了一种基于深度学习框架的红外小目标检测方法HCF-Net,通过集成多个创新功能模块显著提升了检测性能。具体而言,该方法包含并行化感知补丁注意力(PPA)模块、维度感知选择性融合(DASI)模块以及多膨胀通道优化(MDCR)模块。PPA模块采用多分支特征提取策略,有效捕获不同尺度与层次的特征信息;DASI模块实现自适应通道选择与融合机制;MDCR模块则通过多层深度可分离卷积操作获取多样化感受野范围的空间特征表达。在SIRST红外单帧图像数据集上进行的大量实验验证表明,所提出的HCF-Net模型展现出卓越的检测性能,显著超越了传统方法及现有深度学习模型的性能水平。相关实现代码已在https://github.com/zhengshuchen/HCFNet平台开源发布。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
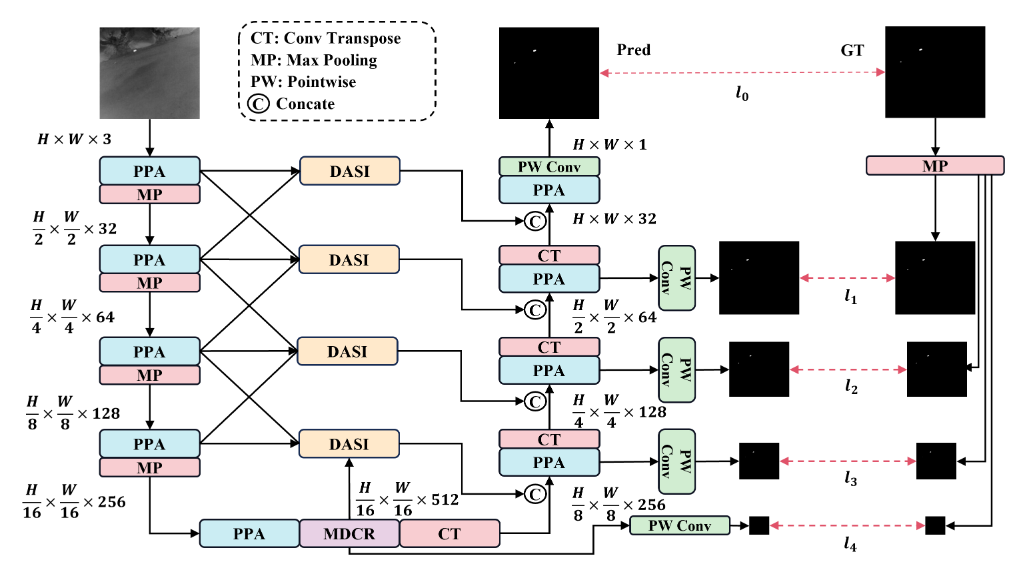
HCF-Net(Hierarchical Context Fusion Network)是一种用于红外小目标检测的深度学习模型,旨在提高对红外图像中微小目标的识别和定位能力。
-
网络架构:HCF-Net采用了一种升级版的U-Net架构,主要由三个关键模块组成:Parallelized Patch-Aware Attention(PPA)模块、Dimension-Aware Selective Integration(DASI)模块和Multi-Dilated Channel Refiner(MDCR)模块。这些模块在不同层级上解决了红外小目标检测中的挑战 。
-
PPA模块:
- Hierarchical Feature Fusion:PPA模块利用分层特征融合和注意力机制,以在多次下采样过程中保持和增强小目标的表示,确保关键信息在整个网络中得以保留[T1]。
- Multi-Branch Feature Extraction:PPA采用多分支特征提取策略,以捕获不同尺度和级别的特征信息,从而提高小目标检测的准确性 。
-
DASI模块:
- Adaptive Feature Fusion:DASI模块增强了U-Net中的跳跃连接,专注于高低维特征的自适应选择和精细融合,以增强小目标的显著性 。
-
MDCR模块:
- Spatial Feature Refinement:MDCR模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征,更细致地建模目标和背景之间的差异,提高了定位小目标的能力 。
PPA
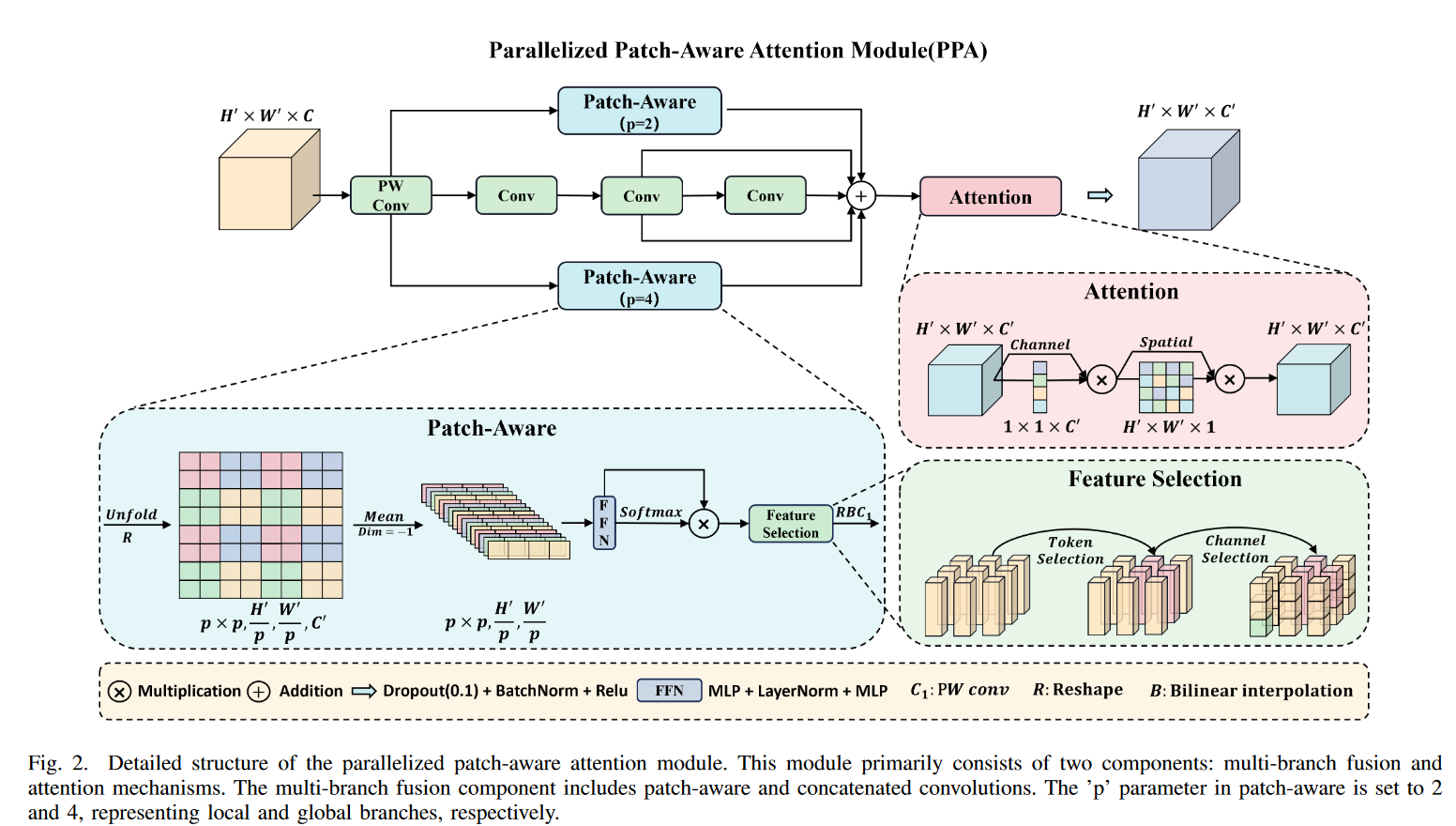
在红外小物体检测任务中,小物体很容易在多次降采样操作中丢失关键信息。 ,PPA 在编码器和解码器的基本组件中取代了传统的卷积运算,从而更好地应对了这一挑战。PPA 主要有两大优势:多分支特征提取和特征融合注意力。
多分支特征提取
PPA 的多分支特征提取策略如下图 所示,采用并行多分支方法,每个分支负责提取不同规模和级别的特征。这种策略有利于捕捉物体的多尺度特征,提高小物体检测的准确性。具体而言,这包括三个并行分支:局部分支、全局分支和串行卷积分支。
-
局部分支:通过调整逐点卷积后的特征张量 F ′ F' F′,分割成一组空间上连续的斑块,进行信道平均和线性计算,再应用激活函数得到空间维度上的概率分布。
-
全局分支:使用高效操作,在斑块中选择与任务相关的特征,通过余弦相似度衡量加权,最终产生局部和全局特征。
-
串行卷积分支:采用三个 3x3 卷积层替代传统的大卷积核,得到多个输出结果,最后相加得到串行卷积输出。
这些分支计算得到的特征分别是 F l o c a l F_{local} Flocal、 F g l o b a l F_{global} Fglobal 和 F c o n v F_{conv} Fconv,它们在尺寸和通道数上保持一致。
通过这种策略,PPA 不仅能有效捕获不同尺度下的特征,还能提升特征的表达能力和模型的整体性能。
核心代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class conv_block(nn.Module):
def __init__(self,
in_features, # 输入特征数量
out_features, # 输出特征数量
kernel_size=(3, 3), # 卷积核大小
stride=(1, 1), # 步长
padding=(1, 1), # 填充
dilation=(1, 1), # 空洞卷积率
norm_type='bn', # 归一化类型
activation=True, # 是否使用激活函数
use_bias=True, # 是否使用偏置
groups=1 # 分组卷积数量
):
super().__init__()
# 定义卷积层
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
# 定义归一化层
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
# 定义激活函数
if self.act:
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 重新排列张量维度 (B, H, W, C)
B, H, W, C = x.shape
P = self.patch_size
# 局部分支
local_patches = x.unfold(1, P, P).unfold(2, P, P) # 将特征分块 (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # 重新调整形状 (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # 对最后一维取均值 (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # 全连接层 (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # 层归一化 (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # 全连接层 (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # 计算注意力 (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # 应用注意力权重 (B, H/P*W/P, output_dim)
# 计算与提示向量的余弦相似度
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # (B, N, 1)
mask = cos_sim.clamp(0, 1) # 计算掩码
local_out = local_out * mask # 应用掩码
local_out = local_out @ self.top_down_transform # 变换
# 恢复形状
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False) # 插值恢复原始尺寸
output = self.conv(local_out) # 卷积层
return output
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k = int(abs((math.log(in_channel,2)+b)/gamma)) # 计算卷积核大小
kernel_size = k if k % 2 else k+1 # 保证卷积核大小为奇数
padding = kernel_size // 2 # 填充
self.pool = nn.AdaptiveAvgPool2d(output_size=1) # 自适应平均池化
self.conv = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size, padding=padding, bias=False), # 1D卷积层
nn.Sigmoid() # Sigmoid激活函数
)
def forward(self, x):
out = self.pool(x) # 平均池化
out = out.view(x.size(0), 1, x.size(1)) # 调整形状
out = self.conv(out) # 1D卷积
out = out.view(x.size(0), x.size(1), 1, 1) # 调整形状
return out * x # 注意力加权
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3) # 2D卷积层
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True) # 平均池化
maxout, _ = torch.max(x, dim=1, keepdim=True) # 最大池化
out = torch.cat([avgout, maxout], dim=1) # 连接
out = self.sigmoid(self.conv2d(out)) # 卷积和激活
return out * x # 注意力加权
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
# 定义跳跃连接卷积块
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
# 定义连续卷积块
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
# 定义空间注意力模块
self.sa = SpatialAttentionModule()
# 定义ECA模块
self.cn = ECA(filters)
# 定义局部和全局注意力模块
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
# 定义批归一化层、dropout层和激活函数
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x) # 跳跃连接输出
x_lga2 = self.lga2(x_skip) # 局部和全局注意力输出(大小为2的patch)
x_lga4 = self.lga4(x_skip) # 局部和全局注意力输出(大小为4的patch)
x1 = self.c1(x) # 第一个卷积块输出
x2 = self.c2(x1) # 第二个卷积块输出
x3 = self.c3(x2) # 第三个卷积块输出
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4 # 合并所有输出
x = self.cn(x) # ECA模块
x = self.sa(x) # 空间注意力模块
x = self.drop(x) # Dropout层
x = self.bn1(x) # 批归一化层
x = self.relu(x) # 激活函数
return x
YOLOv11引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 PPA为文件名的py文件, 把代码拷贝进去。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class conv_block(nn.Module):
def __init__(self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type='bn',
activation=True,
use_bias=True,
groups=1
):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
P = self.patch_size
# Local branch
local_patches = x.unfold(1, P, P).unfold(2, P, P) # (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # (B, H/P*W/P, output_dim)
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1)
local_out = local_out * mask
local_out = local_out @ self.top_down_transform
# Restore shapes
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False)
output = self.conv(local_out)
return output
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k=int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
padding=kernel_size//2
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.conv=nn.Sequential(
nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0),1,x.size(1))
out=self.conv(out)
out=out.view(x.size(0),x.size(1),1,1)
return out*x
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out * x
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.sa = SpatialAttentionModule()
self.cn = ECA(filters)
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x)
x_lga2 = self.lga2(x_skip)
x_lga4 = self.lga4(x_skip)
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.cn(x)
x = self.sa(x)
x = self.drop(x)
x = self.bn1(x)
x = self.relu(x)
return x
tasks注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.PPA import PPA
步骤2
修改def parse_model(d, ch, verbose=True):
if m in {
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, C2fPSA, C2PSA, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3k2, RepNCSPELAN4, ELAN1, ADown, AConv, SPPELAN, C2fAttn, C3, C3TR, C3Ghost,
nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, PSA, SCDown, C2fCIB, AKConv, DynamicConv, ODConv2d, SAConv2d,
DualConv, SPConv,RFAConv, RFCBAMConv, RFCAConv, CAConv, CBAMConv, CoordAtt, ContextAggregation, S2Attention,
CPCA, BasicRFB, MCALayer, PPA
}:

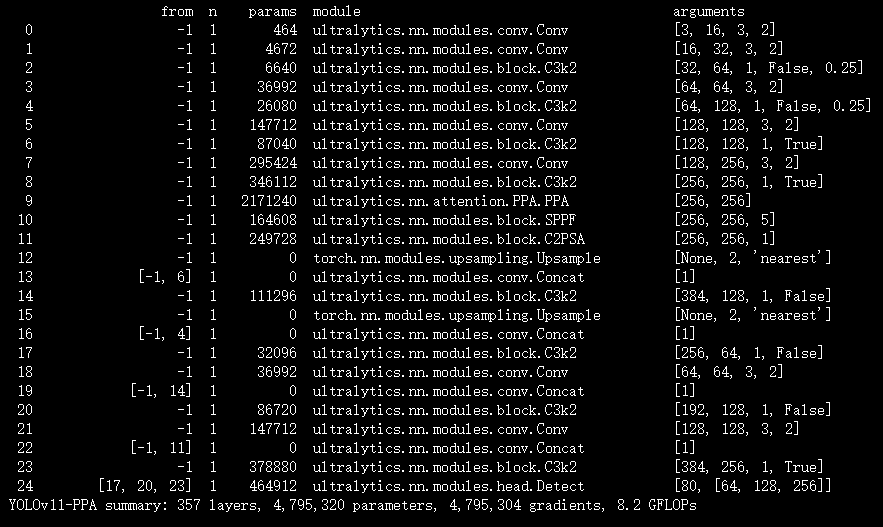
配置yolov11-PPA.yaml
ultralytics/cfg/models/11/yolov11-PPA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, PPA, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
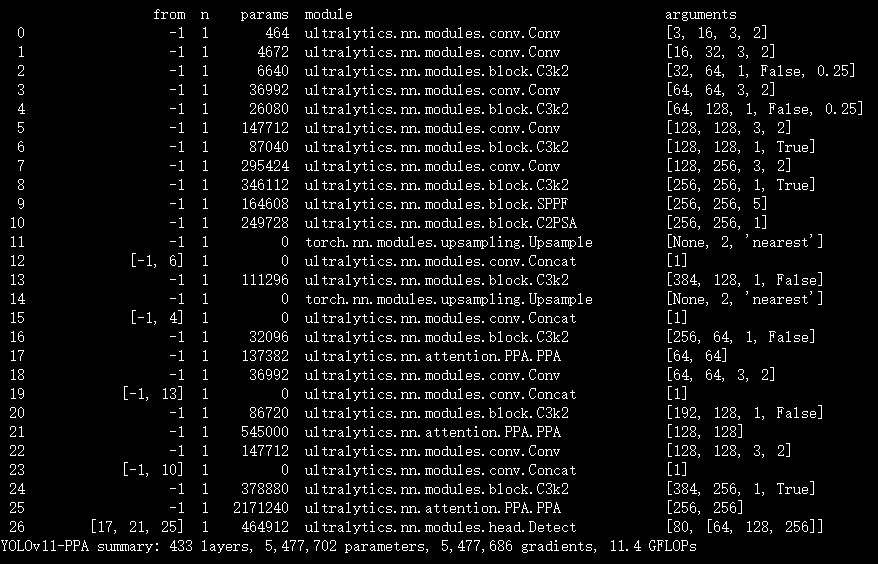
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, PPA, [256]] #17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, PPA, [512]] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, PPA, [1024]] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-PPA.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='PPA',
)

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









