







2.3 程序语言的语法描述
一、符号和符号串
字母表:字母表Σ是符号元素的非空集合。
符号:字母表中的元素。
符号串:字母表中的符号所组成的任何有穷序列。
例如,若有字母表Σ={a,b}
则a,b是字母表Σ中的元素(符号);
a, b,aa,ab,ba…都是符号串。
注意:符号串中的符号与顺序有关, ab和ba是不同的符号串
特别定义:空符号串——不含任何符号的符号串,用ε表示。
设有字母表Σ={a…z, A…Z,0…9,…, 各种运算符和其它特殊
符号, …}, 则,由这些字母表中的元素(符号)可以组成不同
的符号串:

符号串的运算:
符号串的连接(联结、乘积):符号串x和y的连接是指x和y的符号按先后顺序排列在一起组成一个新的符号串,用xy表示。
例,若字母表Σ={a,b},符号串x=ab,y=ba 则xy=abba
注意: (1)连接运算不满足交换律,即xy≠yx
(2)任何符号串x与空串ε的连接都等于x,即:
εx=xε=x。
符号串的长度:符号串中符号的个数为符号串的长度。
若ab是符号串,则|ab|表示符号串的长度。|ab|=2
符号串的前缀与后缀(头和尾):若有符号串z=xy(x,y是符号串),我们称x为z的前缀,y为z的后缀。
例z=abcd
则:z的头有,ε,a ,ab, abc , abcd
z的尾有,ε,d , cd , bcd, abcd
符号串的幂运算:设X是一个符号串,则:
X0=ε,X1=X,X2=XX,…,Xn=X…X=Xn
例:若有符号串x=ab,则:
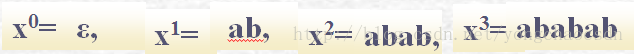
显然,若n>0,则Xn=XXn-1 =Xn-1X。
即:符号串的幂运算服从结合律
符号串集合的运算:
符号串集合的乘积运算:设A、B为符号串集合(集合中各元素都是字母表上的字符串),两个符号串集合的乘积定义为:AB={xy|x∈A , y∈B}(笛卡儿乘积)
设有字母表Σ={a,b,c,d},令A={aa,bb},B={cc,dd}
则AB={aacc,aadd,bbcc,bbdd},
BA={ccaa,ccbb,ddaa,ddbb}。
显然 AB ≠ BA,即符号串集合乘积不满足交换律。
特别定义:空符号串集合:{ε}
空集合:φ={}
注意:因εx=xε=x故,{ε}A=A{ε}=A
A φ= φA= φ
符号串集合的幂运算:设A为符号串集合,则集合的幂运算定义如下:

符号串集合的闭包:设A为符号串集合,则集合的闭包定义如下:
A的正闭包: A+=A1∪A2∪…
A的闭包: A*=A0∪A1∪A2∪…
设集合A={a,b},则 A+={a,b,aa,ab,ba,bb,aaa, …}
A*={ε,a,b,aa,ab,ba,bb,aaa, …}
显然: A*=A0∪A+ A+=AA*
二、上下文无关文法
文法(Grammar):是描述语言的语法结构的形式规则(即语法规则)。
The big monkey ate a banana.
规则:规则又叫产生式(productionrule),它是语法单位结构的一种表示,它引入了符号“::=”或“→”表示“由……组成”,上述句子的结构可以表示如下:
<句子> →<主语> <谓语>
<主语> → <冠词> <形容词> <名词>
<冠词>→the
<形容词>→big
<谓语>→<动词> <直接宾语>
<动词> →ate
<直接宾语>→<冠词><名词>
<冠词> → a
<名词>→monkey
<名词>→banana
句子的推导:用规则(产生式)按一定方式去推导或产生句子的过程。
< 句子 >=><主语> <谓语>=>< 冠词 > < 形容词 > < 名词 > < 谓语 >
=>The < 形容词 > < 名词 > < 谓语 >
=>The big < 名词 > < 谓语 >
=>The big monkey < 谓语 >
=>The big monkey < 动词 > < 直接宾语 >
=>The big monkey ate < 直接宾语 >
=>The big monkey ate < 冠词 >< 名词 >
=>The big monkey ate a < 名词 >
=>The big monkey ate a banana

语法树(ParseTree):句子结构的图形表示方式

归纳:什么是文法
<句子> →<主语> <谓语>
<主语> → <冠词> <形容词> <名词>
<冠词>→the
<形容词>→big
<谓词>→<动词> <直接宾语>
<动词> →ate
<直接宾语>→<冠词><名词>
<冠词> → a
<名词>→monkey
<名词>→banana
三、文法和语言的形式定义
定义1 产生式(或规则)是一有序对(A,α),通常写为:
A→ α或A∷= α
其中A是一个符号作为产生式左部,α为有穷符号串作为产生式的右部,“→”或“∷=”表示“定义为…”或“由…组成”。
定义2 文法是一个四元组:G[S]=(VN,VT, P, S)
其中:
VN为非终结符集合;
在规则左部出现的符号称为非终结符,它们的全体形成VN
VT为终结符集合;VN∩VT =Ф,一般令V=VN∪VT,V中的符号称为文法符号;(V字汇表)
在规则中只在右部出现的符号称为终结符,它们的全体形成VT
P为产生式集合;
P中的每个产生式写为:α→β或α∷=β。
S为开始符号(或称根符号,识别符号)。
另外:G[S]也可简写为G
例 G 1 =({N},{0 , 1},{N→0N,N→1N,N→0,N→1},N )其中 : 非终结符 V N ={N}
终结符 V T ={0 , 1} V={N , 0 , 1}
P={N→0N , N→1N , N→0 , N→1}
开始符号 S 为 N
通常情况下,文法只用产生式集合表示:
G1[N]:
N→0N
N→1N
N→0
N→1
定义3 符号串的推导与归约:已给文法G=(VN,VT,P,S), V= VN∪VT,令x,y,α,β∈V*,且α→β∈P,此时,由符号串xαy能够直接产生出符号串xβy,我们称:
符号串xβy是符号串xαy的直接推导;
符号串xαy是符号串xβy的直接归约;
记作: xαy=>xβy
对于上例中文法:
G1[N]:
N→0N
N→1N
N→0
N→1




引用巴科斯范式(BNF)表示文法:
对于具有相同左部的那些产生式,如:U→x,U→y,…,U→z可以缩写为:U→x|y|…|z (“|”可理解为“或”)
(1)<无符号整数> →<数字串>
(2)<数字串>→<数字串><数字>
(3)<数字串>→<数字>
(4)<数字>→0
(5)<数字>→1
(6)<数字>→2
(7)<数字>→3
(8)<数字>→4
(9)<数字>→5
(10)<数字>→6
(11)<数字>→7
(12)<数字>→8
(13)<数字>→9
(1)<无符号整数> →<数字串>
(2)<数字串>→<数字串><数字> |<数字>
(3)<数字>→0 |1 |2 |3 |4 |5 |6 |7 |8 |9|
用此文法和直接推导的定义可以推导出任一无符号整数(56)
<无符号整数>=><数字串>
=><数字串> <数字>
=><数字> <数字>
=>5<数字>
=>56

定义4 句型和句子:设G=(VN,VT,P,S)是一文法,若
α∈V*,则称α为文法G的句型
α∈VT*,则称α为文法G的句子
例:前面提到的文法G ={ VN,VT,P,〈无符号整数〉}
其中,VT ={0,1,2,3,4,5,6,7,8,9}
VN={〈无符号整数〉,〈数字串〉,〈数字〉}
P:<无符号整数>→<数字串>
<数字串>→<数字串><数字>┃<数字>
<数字>→0┃1┃2┃3┃4┃5┃6┃7┃8┃9
<无符号整数>=><数字串>
=><数字串> <数字>
=><数字> <数字>
=>5<数字>
=>56
由此我们可以看出,文法和语言是密切相关的,根据文法可以推导出任一句型和句子,而所有句子的集合则为该文法所对应的语言,即语言是所有句子构成的集合,它是所有终结符号串所组成的集合VT*的子集:

定义5 规范推导(归约):对于直接推导xαy=> xβy,如果y只包含终结符号或为空符号串,那么就把这种直接推导称为规范(最右)推导,跟其对应的归约称为规范(最左)归约,且记作:
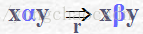

形式语言理论可以证明以下两点:
(1)给定一个文法G, 就可以从结构上唯一地确定其语言:
G->L(G)
(2)给定一种语言L, 能确定其文法,但这种文法可能不
是唯一的:
L->G1或G2
例1:有文法G[Z]:
(1)Z→aZb
(2)Z →ab
它确定的语言是什么?
用BNF表示: Z →aZb|ab
| 由产生式(2)知:z=>ab故ab是文法的一个句子 |
| 用产生式(1)(2):z=>aZb=>a2b2故a2b2是文法的一个句子 |
| 反复使用产生式(1):z=>aZb=>a2Zb2…=>an-1Zbn-1=>anbn |
所以,文法所确定的语言为: L(G[Z])={a n b n | n >= 1}
例 2 :已知语言为 L(G)={ab n a | n >= 1} 试给出其文法。
G 1 [Z]:
Z →aBa
B →bB|b
G 2 [Z]:
Z →aBa
B →Bb|b
定义 6 等价文法 :如果 L(G 1 )=L(G 2 ) , 那么称 G 1 和 G 2
为等价文法。
定义 7 递归产生式和递归文法 :设给定文法 G=(V N ,V T ,P,S)

若x=ε且y≠ε,则称产生式A→α是左递归产生式;
B →Bb
若x≠ε且y=ε,则称产生式A→α是右递归产生式。
B →bB
若α具有xAy形式,则称产生式A→α是直接递归产生式。
(2)递归文法:
若文法中至少存在一条直接递归产生式则称该文法是直接递归的文法;否则

则称文法为间接递归的文法。
可见,对于文法中任一非终结符号,若能建立一个推导过程,在推导所得的符号串中又出现了该非终结符号本身,则文法是递归的。应当注意,一般的文法都是递归的,文法G只有递归定义,L(G)中句子才是无穷的
例:有文法G[S]:
S →aB|bB
B →a|b
是否是递归文法,确定什么语言?
非递归文法,L(G[S])={aa,ab,ba,bb}
例:有文法G<无符号整数>
(1)<无符号整数> →<数字串>
(2)<数字串> →<数字串><数字> |<数字>
(3)<数字> →0 |1 |2 |3 |4 |5 |6 |7 |8 |9|
它是否为递归文法,确定的语言是什么?
该文法中有直接左递归产生式:
<数字串> →<数字串><数字>
所以是递归文法。
所确定的语言为:所有无符号整数。L(G)=VT+
若不用递归规则表示文法,就要用到无穷多条产生式:
<数字串> →<数字> |<数字> <数字> |<数字> <数字> <数字> |……
总之,使用递归文法,可用有穷的产生式来描述无穷的语言,反之,一个语言若是无穷的,则描述语言的文法必定是递归的。(程序设计语言一般是无穷的)。
定义8 短语、简单短语和句柄:设文法 G=(VN,VT,P,S) ,

则u称为句型xuy的相对于U的短语 ;

则u称为句型xuy的相对于U的简单(直接)短语;
例:有文法G<无符号整数>
(1)<无符号整数> →<数字串>
(2)<数字串> →<数字串><数字> |<数字>
(3)<数字> →0 |1 |2 |3 |4 |5 |6 |7 |8 |9|
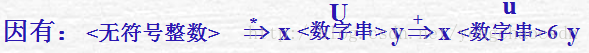
U= <数字串>
u= <数字串>6
x,y=e
<数字串>6是句型<数字串>6相对于<数字串>的短语

6是句型<数字串>6相对于<数字>的短语,且为简单短语
(3)任一句型的最左简单短语称为该句型的句柄.
说明:当句型有两个以上的简单短语同时存在时,我们把位于最左边的那个简单短语称为“最左简单短语”,即该句型的句柄;若句型只有一个简单短语,那么,它就是最左简单短语,即句柄。
例1:在“<数字串>6”中,6是句型<数字串>6中唯一的一个简单短语,所以它是句柄.
例2:在“<数字串> <数字>78”中, <数字串> <数字> 、7和8都是是句型简单短语,所以位于左边的<数字串><数字>是句柄.
2.4语法树和文法的二义性
语法树: 设文法G=(VN,VT,P,S) ,所谓语法树是一张图,这张图表示一个句型的推导过程。语法树结构是一棵倒立的树结构,其中,结点的名字N∈V,根结点的名字S是文法G的开始符号,树中的中间结点是句型推导过程中使用的非终结符,树的端末结点自左向右排列就是所给句型。
例2.7 文法G[E]:
E→E+T│T
T→T*F│F
F→〔E〕│i
句型E+F*i对应的语法树如右图所示:
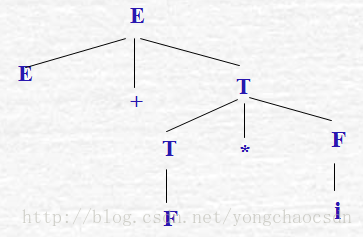
可以看出,语法树的生成过程直观的给出了句型的推导过程。
子树:由语法树的某个结点(子树的根)连同它下面发出的部分组成语法树的子树。只含有单层分支的子树为简单子树。
子树与短语:在句型所对应的语法树中,若某些符号按从左到右的顺序组成某棵子树的末端结点,那么由这些末端结点所组成的符号串是相对于子树根结点的短语。
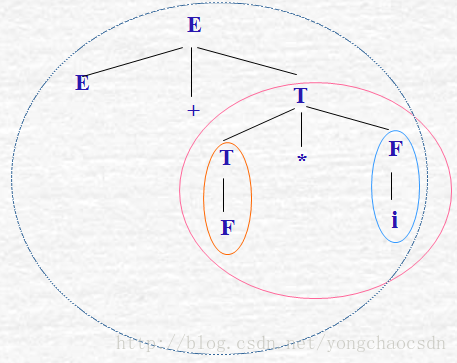
例如:F是句型相对于T的短语,且为简单短语;
i是句型相对于F的短语,且为简单短语;
F*i 是句型相对于T的短语;
E+F*i是句型相对于E的短语.
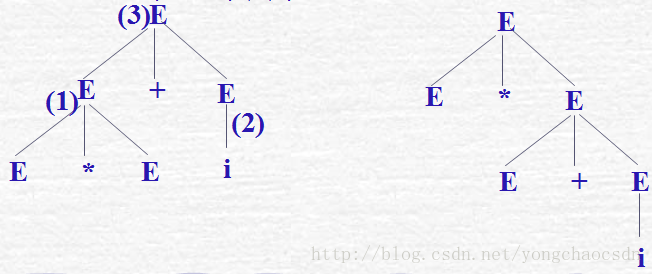
文法的二义性:若一个文法存在某个句子对应两棵不同的语法树,则称此文法是二义性文法,运用文法描述程序设计语言的语句成份,一般希望所给文法是非二义文法,但是,有时候采用二义性文法比非二义文法要简单的多,所以,经常用二义性文法描述程序设计语言。
例1: 文法G[E] :
E→E+E | E*E | (E) | i 试为符号串E*E+i构造语法树.
2.5文法的分类
按照文法中产生式的不同情况,Chomsky把文法分成四种类型,四种类型的文法对应着四种类型的语言。
0型文法: 产生式形式为: u →v 且u∈V+ v∈V*
u中应至少含有一个非终结符号,这种文法又叫短语文法,它所确定的语言称为0型语言。
1型文法: 产生式形式为 xUy →xuy 且U∈VN u∈V+ x,y∈V* 则称该文法为1型文法,也称为上下文敏感文法或上下文有关文法。
即只有在U的左部为符号串x而右部为符号串y时,才允许把非终结符U用符号串u来代替,即U必须在上下文x…y中才行。这种文法所对应的语言为1型语言。
2型文法: 产生式形式为 U →u 且U∈VN u∈V*
则称该文法为2型文法,也称为上下文无关文法。2型文法所确定的语言为2型语言,大部分程序设计语言都是2型语言。
例: 文法G =({S},{a,b},{S→aSb,S→ab},S)
3型文法: 产生式形式为 U→xV|y 或 U→Vx|y
且U,V ∈VN,x,y∈VT+
则称该文法为3型文法,也称线性文法、正则文法或正规文法。这种文法所对应的语言称为3型语言(正则语言、正规语言),大多数程序设计语言的单词(标识符、无符号整数) 的文法都是3型文法。
u →v
xUy →xuy
U →u
U→xV|y
从0型文法到3型文法是逐渐增加限制的,而它们所确定的语言是逐步缩小的。
2.6 有关文法的实用限制
1.不能有形如: U →U的产生式;
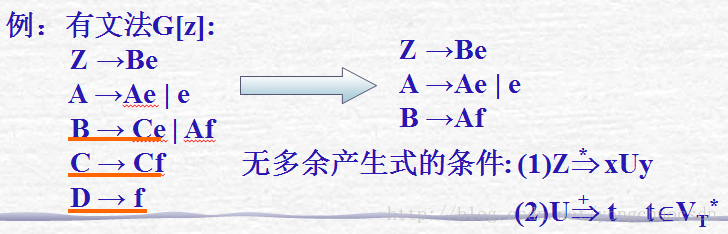
2.不能有多余产生式,多余产生式可以从文法中删掉,所谓多余产生式有这样的特点:
(1)在推导文法的所有句子时,始终都用不到的产生式;
(2)在推导过程中,一旦使用此产生式,将无法推出任何句子的的产生式;
2.7 扩充的巴科斯范式(EBNF)表示
1. 产生式的花括号表示法
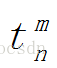
表示符号串t可重复出现n次到m次(n<m),一般约定n=0;
例:若有产生式 S→xS│x,其中:S∈VN,x∈VT,则可用花括号表示为:
S→x{x}
2. 产生式的方括号表示法 [t]
表示符号串t为可选项,即可出现0次或1次:
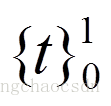
例1:设有两个产生式T→T*F│F,可用方括号表示成:
T→ [T*]F
例2:<条件语句> → if <条件> then <语句> [else <语句>]
3. 使用圆括号( )——提取候选式的公用因子
例1:若有产生式 A→xW1y│xW2y│┄│xWny
则可表示成:
A→x(W1│W2│ ┄│Wn )y
例2:S→if B then S│if B then S else S
提取左公因子,可写成:
S→if B then S (ε│else S)















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









