







Yarn(yet another resource negotiator 另一种资源协调者)
核心思想:资源的管理和Job的调度/监控进行分离
Yarn产生的原因
比较:Hadoop v1.0
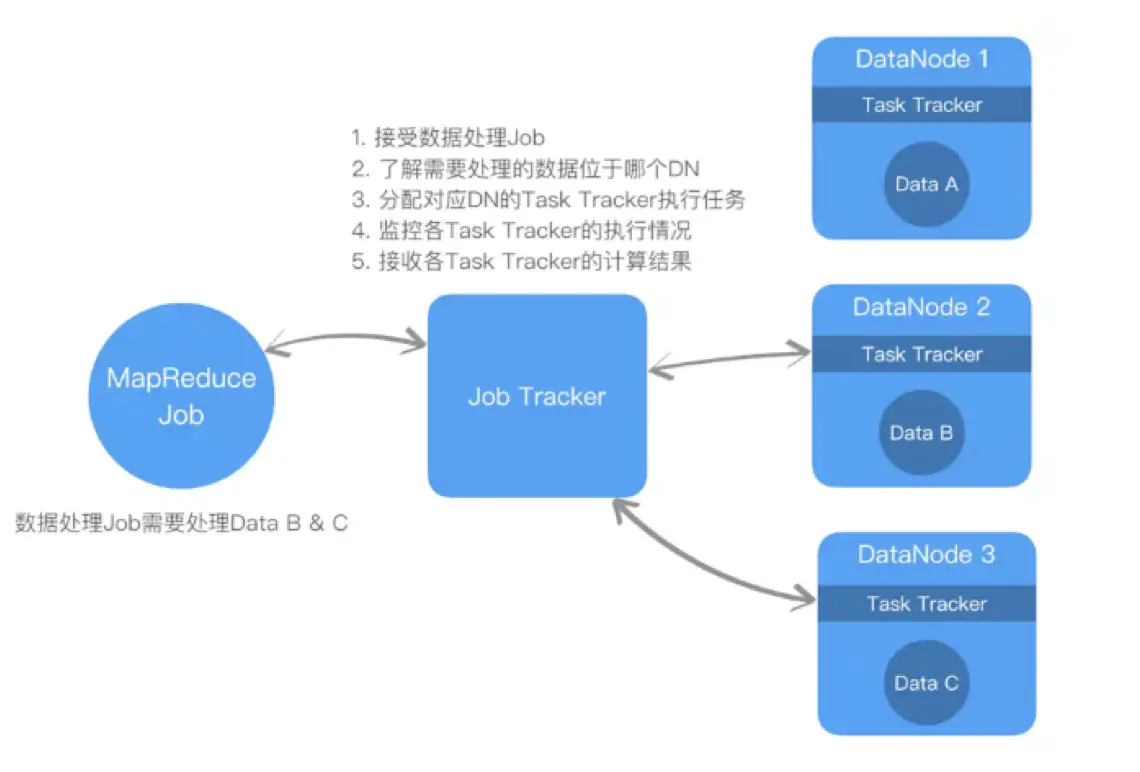
- 大量的数据提交给Job Tracker,JT需要协调无数的DN,导致JT可能成为性能瓶颈
- 假设用户提交了6个job,每个job需要1g内存,且数据都在DN2上,但是DN2只有4g内存,所以只有job1-4在DN2上运行,job5、6在等待,而DN1和DN3的资源没有使用。
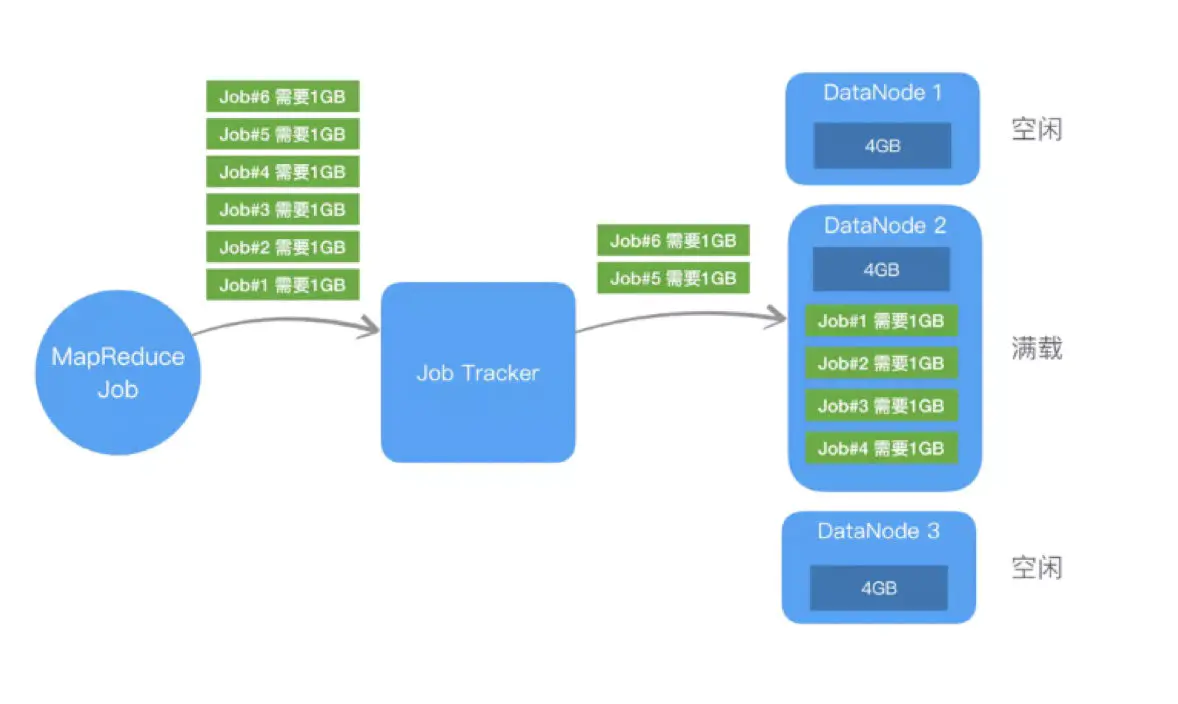
为了减少Job Tracker的性能负担和更好地分配资源,就出现了Yarn
Yarn框架
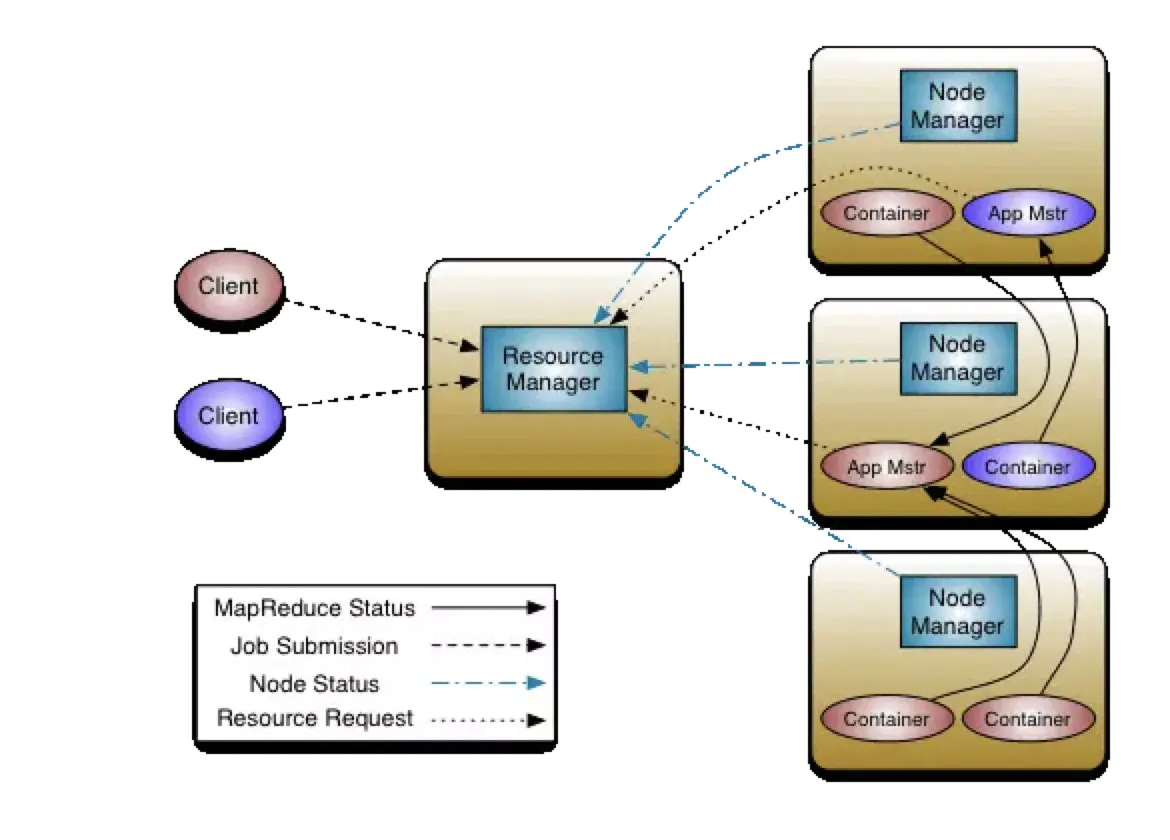
- 全局组件
- Resource Manager(RM)
- 处理客户请求
- 监控NodeManeger
- 启动或监控Application Master
- 资源的分配与调度
- Node Manager(NM)
- 管理单个节点上的资源
- 处理来自Resource Manager的命令
- 处理来自Applicaiton Manager的命令
- Resource Manager(RM)
- Per-application组件
- Applicaiton Master
- 负责数据的切分
- 为应用程序申请资源并分配给内部任务
- 任务的监控与容错
- Container:Yarn中资源的抽象,封装了某个节点的多个维度的资源(内存、CPU、磁盘、网络)
- Applicaiton Master
Yarn的工作机制
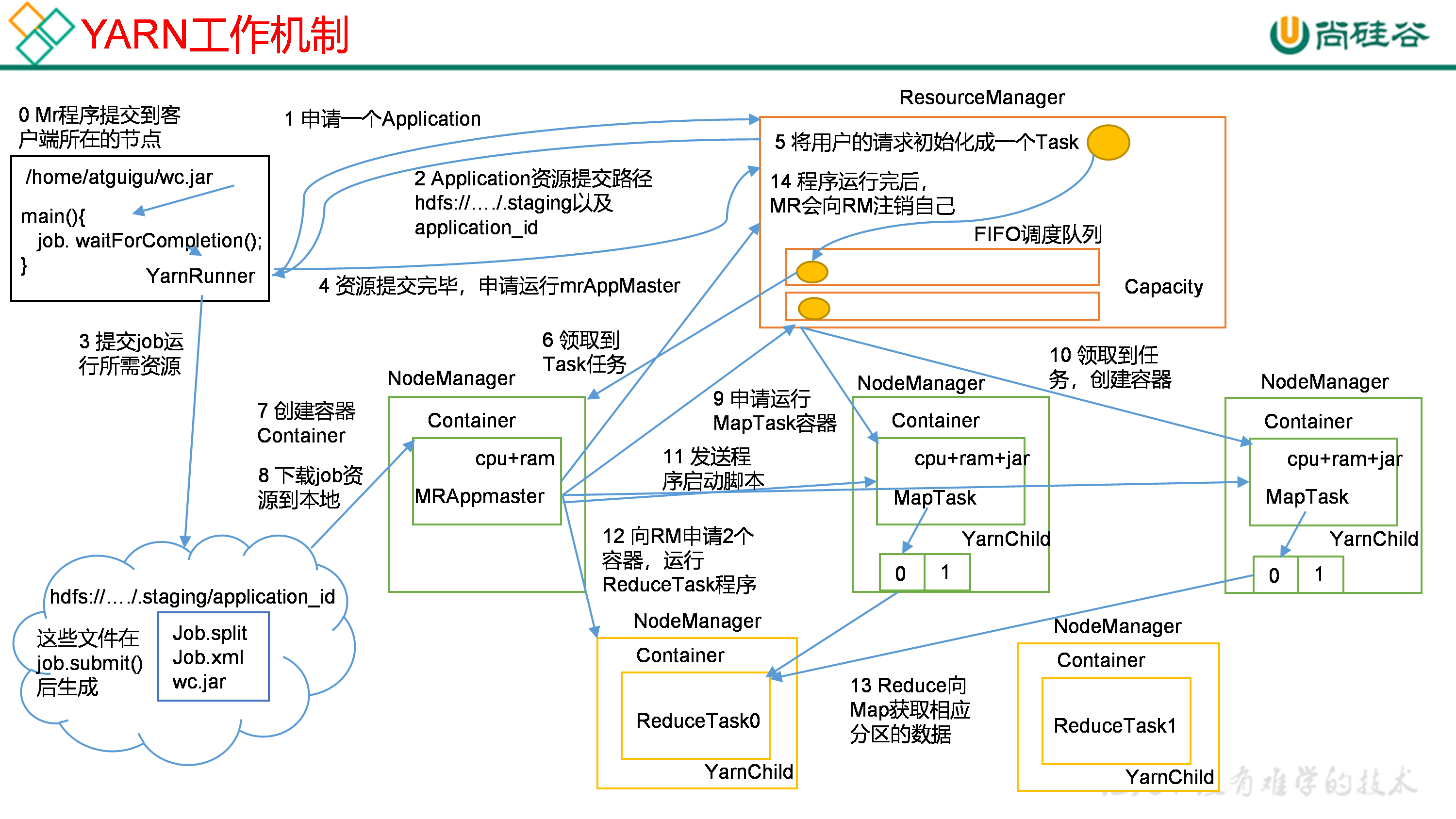
- MR程序提交到客户端所在的节点,调用job.waitForCompletion()
- YarnRunner向RM申请一个Applitcaion
- RM将该应用程序的资源路径以及application_id返回给YarnRunner
- 该程序将运行所需的资源提交到HDFS上(有了id,就知道job需要的临时文件提交到对应文件夹(在本地模式:C:\tmp;在HDFS模式下:HDFS根目录/tmp)在下面,临时文件夹存放的文件跟DN里的是一样的)
临时申请的工作目录里面存放:Job.split,Job.xml,wc.jar(Yarn模式需要提交jar包,而本地不需要) - 资源提交完毕,申请运行Application Master
- 所有的资源申请进入到RM都会被包装成一个Task(RM里面有一个资源调度器)
- 找到一个拥有相应资源(例如2核1G)的DN,然后将Task任务分配给NM
- DN创建Container,Container包含(例如2核1G)
- APPMaster下载job资源到本地
- APPMaster根据Job.split的切片信息,向RM申请(资源调度器)运行MapTask的容器
- MapTask所在节点领取到任务,创建容器
- APPMaster向MapTask所在节点发送程序启动脚本(jar包)
- (APPMaster不停询问MapTask执行的情况,当所有MapTask都已经生成输出文件(Container在生成文件后会被回收))APPMaster向RM申请分区号个ReduceTask程序
- ReduceTask向MapTask获取相应分区的数据
- 处理完的数据写回HDFS,处理完后,APPMaster会向RM申请注销自己
参考:















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









