







博主是基于2021小麦目标检测以及计数比赛提供官方数据集作为例子,将官方提供的含有大量标签的CSV文件转换为VOC格式的XML标注文件,方便算法进行训练。
1、比赛地址以及概况:

2、图像数据集:


3、标签文件数据集:

4、转换代码:
编辑XML文件的函数需要用到xml.etree.ElementTree的函数进行字符串数据的写入,在这里博主编写csvtoxml函数,以图像名、标注框四个坐标、域(domain)作为输入,输出为XML文件信息树,便于接下来的保存。
#编辑xml文件的函数
def csvtoxml(image_name,bbox,domain):
a = Element('annotation')
b = SubElement(a, 'folder')
b.text = 'label'
c = SubElement(a, 'filename')
c.text=image_name+'.png'
c_1 = SubElement(a, 'path')
c_1.text = 'D:/Download/2021wheat_object_dectection/train/%s' %c.text
d = SubElement(a, 'source')
d_1 =SubElement(d,'databases')
d_1.text='Unknown'
d_2 =SubElement(d,'domain')
d_2.text = '%s'%domain
e=SubElement(a,'size') #图片的大小
e_1,e_2,e_3 = SubElement(e,'width'),SubElement(e,'height'),SubElement(e,'depth')
e_1.text,e_2.text,e_3.text='1024','1024','3'
f=SubElement(a,'segmented')
f.text='0'
#依据;分离标准框坐标
str_bbox=bbox.split(";")
#读取每个目标的标注框坐标
for i in str_bbox:
#分离每个标准框的四个坐标点
list_point=i.split()
# 定义object模块
g = SubElement(a, 'object')
g_1, g_2, g_3,g_4 = SubElement(g, 'name'), SubElement(g, 'pose'), \
SubElement(g, 'truncated'),SubElement(g, 'difficult')
# 定义bbox的坐标格式
h=SubElement(g,'bndbox')
h_1, h_2, h_3,h_4 = SubElement(h, 'xmin'), SubElement(h, 'ymin'), SubElement(h, 'xmax'),SubElement(h, 'ymax')
#目标类别为单类别“小麦”
judge = 'Wheat'
h_1.text, h_2.text, h_3.text, h_4.text = list_point[0], list_point[1], list_point[2], list_point[3]
g_1.text, g_2.text, g_3.text, g_4.text = judge, 'Unspecified', '0', '0'
return ElementTree(a)
主函数main则是负责挑出CSV文件中不含标注框(bbox)的标签,利用迭代将标签信息输送给csvtoxml。
def main():
#读取csv文件,不读取表头
df=pd.read_csv(way_1,header=None)
#读取csv中数据的行数
index_num=len(df.index)
for i in tqdm(range(1,index_num)):
# print(i)
row_data_1=df.iloc[i] #1到3657
image_name=row_data_1[0]
bbox=row_data_1[1]
domain=row_data_1[2]
if bbox !='no_box':
tree=csvtoxml(image_name,bbox,domain)
tree.write('%s/%s.xml' % (way_2, image_name), encoding='UTF-8')
整个py文件的完整的代码如下。
import csv
import argparse
import numpy as np
import pandas as pd
from tqdm import tqdm
from xml.etree.ElementTree import Element, ElementTree, tostring,SubElement
parser = argparse.ArgumentParser()
parser.add_argument('--big_csv', type=str, default='D:/Download/2021wheat_object_dectection/train.csv', help='')
parser.add_argument('--csv_way', type=str, default='D:/Download/2021wheat_object_dectection/label_xml', help='')
opt=parser.parse_args()
way_1=opt.big_csv
way_2=opt.csv_way
print(opt)
#编辑xml文件的函数
def csvtoxml(image_name,bbox,domain):
a = Element('annotation')
b = SubElement(a, 'folder')
b.text = 'label'
c = SubElement(a, 'filename')
c.text=image_name+'.png'
c_1 = SubElement(a, 'path')
c_1.text = 'D:/Download/2021wheat_object_dectection/train/%s' %c.text
d = SubElement(a, 'source')
d_1 =SubElement(d,'databases')
d_1.text='Unknown'
d_2 =SubElement(d,'domain')
d_2.text = '%s'%domain
e=SubElement(a,'size') #图片的大小
e_1,e_2,e_3 = SubElement(e,'width'),SubElement(e,'height'),SubElement(e,'depth')
e_1.text,e_2.text,e_3.text='1024','1024','3'
f=SubElement(a,'segmented')
f.text='0'
#依据;分离标准框坐标
str_bbox=bbox.split(";")
#读取每个目标的标注框坐标
for i in str_bbox:
#分离每个标准框的四个坐标点
list_point=i.split()
# 定义object模块
g = SubElement(a, 'object')
g_1, g_2, g_3,g_4 = SubElement(g, 'name'), SubElement(g, 'pose'), \
SubElement(g, 'truncated'),SubElement(g, 'difficult')
# 定义bbox的坐标格式
h=SubElement(g,'bndbox')
h_1, h_2, h_3,h_4 = SubElement(h, 'xmin'), SubElement(h, 'ymin'), SubElement(h, 'xmax'),SubElement(h, 'ymax')
#目标类别为单类别“小麦”
judge = 'Wheat'
h_1.text, h_2.text, h_3.text, h_4.text = list_point[0], list_point[1], list_point[2], list_point[3]
g_1.text, g_2.text, g_3.text, g_4.text = judge, 'Unspecified', '0', '0'
return ElementTree(a)
def main():
#读取csv文件,不读取表头
df=pd.read_csv(way_1,header=None)
#读取csv中数据的行数
index_num=len(df.index)
for i in tqdm(range(1,index_num)):
# print(i)
row_data_1=df.iloc[i] #1到3657
image_name=row_data_1[0]
bbox=row_data_1[1]
domain=row_data_1[2]
if bbox !='no_box':
tree=csvtoxml(image_name,bbox,domain)
tree.write('%s/%s.xml' % (way_2, image_name), encoding='UTF-8')
if __name__ == '__main__':
main()
5、转换效果:
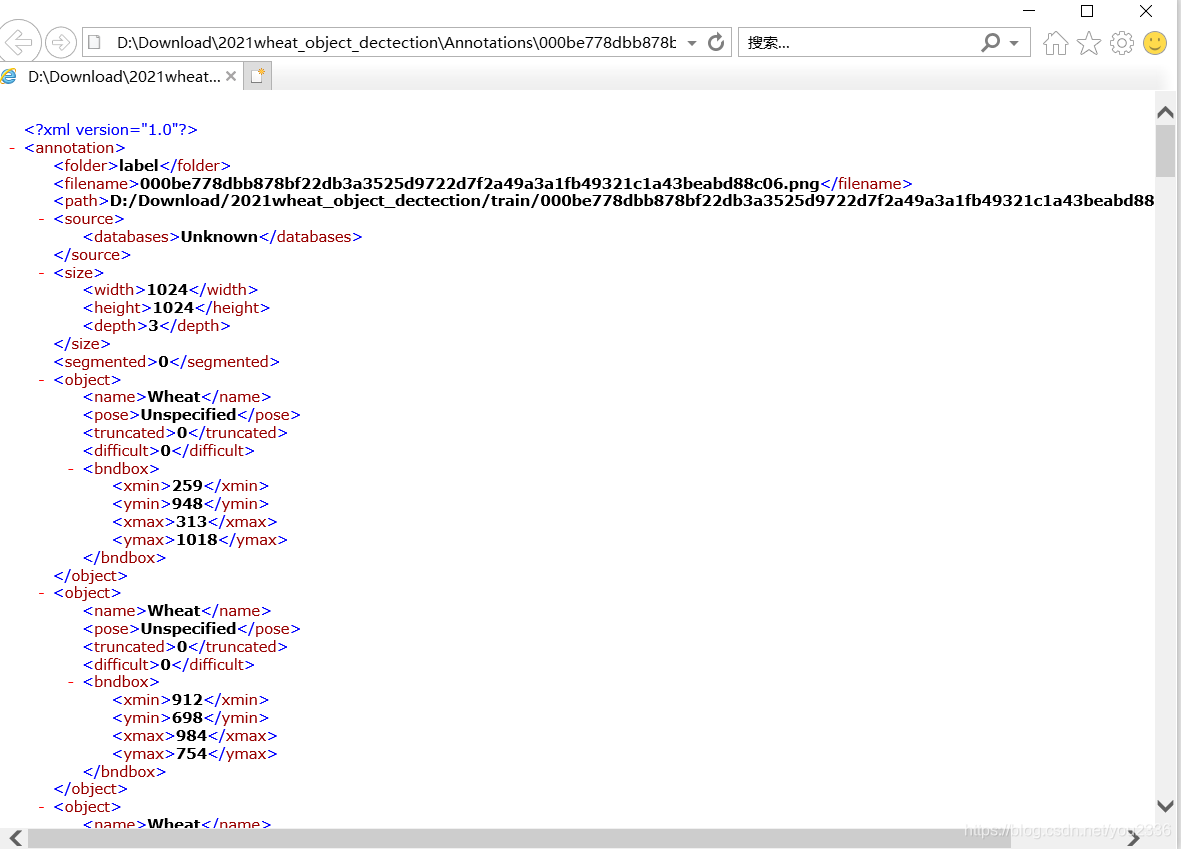
6、标签可视化:
关于标签可视化,博主有一篇编码好的py文件,可以改一下路径直接拿来用,色彩等细节可以自己调。
可视化效果也挺好的。















 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









