







文章目录
1.简介
Stacking是许多集成方法的综合。其主要思路如下图所示,通过训练数据训练多个base learners(the first-level learners),这些learners的输出作为下一阶段meta-learners(the second-level learners)的输入,最终预测由meta-learners预测结果得到。
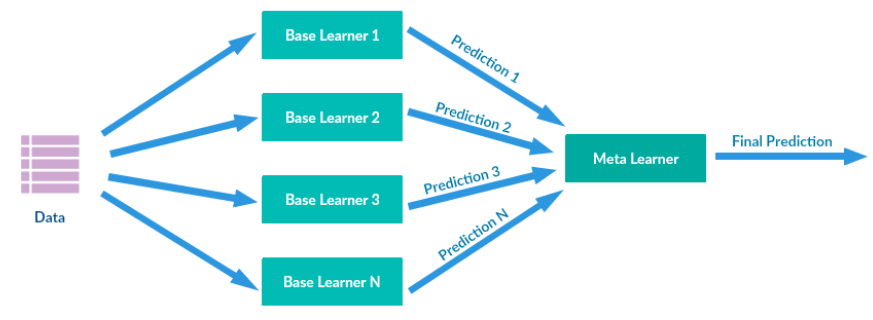
2.stacking 的基本思想
stacking 就是将一系列模型(也称基模型)的输出结果作为新特征输入到其他模型,这种方法由于实现了模型的层叠,即第一层的模型输出作为第二层模型的输入,第二层模型的输出作为第三层模型的输入,依次类推,最后一层模型输出的结果作为最终结果。本文会以两层的 stacking 为例进行说明。
stacking 的思想也很好理解,这里以论文审稿为例,首先是三个审稿人分别对论文进行审稿,然后分别返回审稿意见给总编辑,总编辑会结合审稿人的意见给出最终的判断,即是否录用。对应于stacking,这里的三个审稿人就是第一层的模型,其输出(审稿人意见)会作为第二层模型(总编辑)的输入,然后第二层模型会给出最终的结果。
stacking 的思想很好理解,但是在实现时需要注意不能有泄漏(leak)的情况,也就是说对于训练样本中的每一条数据,基模型输出其结果时并不能用这条数据来训练。否则就是用这条数据来训练,同时用这条数据来测试,这样会造成最终预测时的过拟合现象,即经过stacking后在训练集上进行验证时效果很好,但是在测试集上效果很差。
为了解决这个泄漏的问题,需要通过 K-Fold 方法分别输出各部分样本的结果,这里以 5-Fold 为例,具体步骤如下
(1) 将数据划分为 5 部分,每次用其中 1 部分做验证集,其余 4 部分做训练集,则共可训练出 5 个模型
(2) 对于训练集,每次训练出一个模型时,通过该模型对没有用来训练的验证集进行预测,将预测结果作为验证集对应的样本的第二层输入,则依次遍历5次后,每个训练样本都可得到其输出结果作为第二层模型的输入
(3) 对于测试集,每次训练出一个模型时,都用这个模型对其进行预测,则最终测试集的每个样本都会有5个输出结果,对这些结果取平均作为该样本的第二层输入
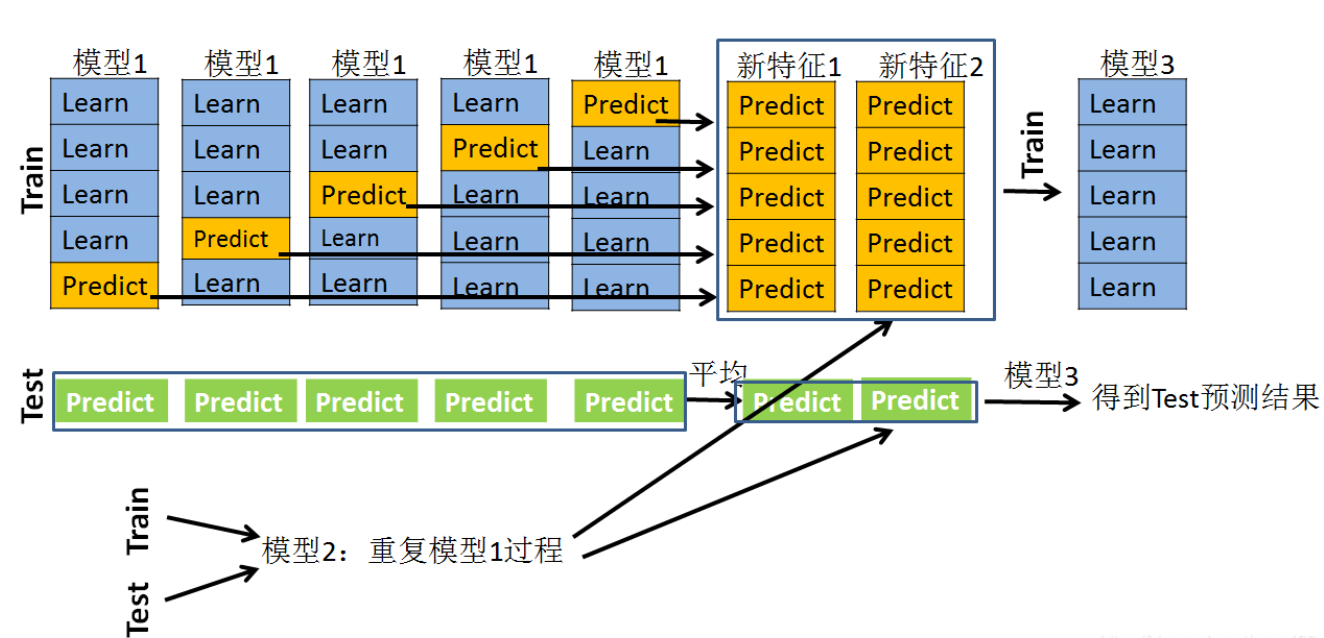
上述过程图示如下:
除此之外,用 stacking 或者说 ensemble 这一类方法时还需要注意以下两点:
1.Base Model 之间的相关性要尽可能的小,从而能够互补模型间的优势
2.Base Model 之间的性能表现不能差距太大,太差的模型会拖后腿
结合上面的图先做一个初步的情景假设,假设采用5折交叉验证:
训练集(Train):训练集是100行,4列(3列特征,1列标签)。
测试集(Test):测试集是30行,3列特征,无标签。
模型1:xgboost。
模型2:lightgbm。
模型3:逻辑回归
第一层xgboost和lightgbm
第一层,也就是xgboost和lightgbm作为第一层
对于模型1来说,先看训练集:
采用5折交叉验证,就是要训练5次并且要预测5次。先把数据分成5份,每一次的训练过程是采用80行做训练,20行做预测,经过5次的训练和预测之后,全部的训练集都已经经过预测了,这时候会产生一个100 ×\times× 1的预测值。暂记为P1。
接下来看一看测试集:
在模型1每次经过80个样本的学习后,不光要预测训练集上的20个样本,同时还会预测Test的30个样本,这样,在一次训练过程中,就会产生一个30 ×\times× 1的预测向量,在5次的训练过程中,就会产生一个30 ×\times× 5的向量矩阵,我们队每一行做一个平均,就得到了30 ×\times× 1的向量。暂记为T1。
模型1到此结束。接下来看模型2,模型2是在重复模型1的过程,同样也会产生一个训练集的预测值和测试集的预测值。记为P2和T2。这样的话,(P1,P2)就是一个100 ×\times× 2的矩阵,(T1,T2)就是一个30 ×\times× 2的矩阵。
第二层逻辑回归LinearRegression()
第二层,也就是逻辑回归LinearRegression()
第二步是采用新的模型3。其训练集是什么呢?就是第一步得到的(P1,P2)加上每个样本所对应的标签,如果第一步的模型非常好的话,那么得到的P1或者P2应该是非常接近这个标签的。有人可能就会对测试集用求平均的方式来直接(T1+T2)/2,或者带权重的平均来求得结果,但是一般是不如stacking方法的。
将(P1,P2)作为模型3训练集的特征,经过模型3的学习,然后再对测试集上的(T1,T2)做出预测,一般就能得到较好的结果了。
python实现
第一层:模型1采用xgboost,模型2采用lightgbm
第二层:模型3用逻辑回归LinearRegression()。
3.代码实现
第一层
3.1xgboost
##### xgb
xgb_params = {'eta': 0.005,
'max_depth': 10,
'subsample': 0.8,
'colsample_bytree': 0.8,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'silent': True,
'nthread': 4}#xgb的参数,可以自己改
folds = KFold(n_splits=5, shuffle=True, random_state=2018)#5折交叉验证
oof_xgb = np.zeros(len(train))#用于存放训练集的预测
predictions_xgb = np.zeros(len(test))#用于存放测试集的预测
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
trn_data = xgb.DMatrix(X_train[trn_idx], y_train[trn_idx])#训练集的80%
val_data = xgb.DMatrix(X_train[val_idx], y_train[val_idx])#训练集的20%,验证集
watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]
clf = xgb.train(dtrain=trn_data, num_boost_round=20000, evals=watchlist, early_stopping_rounds=200, verbose_eval=100, params=xgb_params)#80%用于训练过程
oof_xgb[val_idx] = clf.predict(xgb.DMatrix(X_train[val_idx]), ntree_limit=clf.best_ntree_limit)#预测20%的验证集
predictions_xgb += clf.predict(xgb.DMatrix(X_test), ntree_limit=clf.best_ntree_limit) / folds.n_splits#预测测试集,并且取平均
print("CV score: {:<8.8f}".format(mean_squared_error(oof_xgb, target)))
这样我们就得到了训练集的预测结果oof_xgb这一列,这一列是作为模型3训练集的第一个特征列,并且得到了测试集的预测结果predictions_xgb。
3.2lightgbm
和xgboost非常的相似
##### lgb
param = {'num_leaves': 120,
'min_data_in_leaf': 30,
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.01,
"min_child_samples": 30,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9 ,
"bagging_seed": 11,
"metric": 'mse',
"lambda_l1": 0.1,
"verbosity": -1}#模型参数,可以修改
folds = KFold(n_splits=5, shuffle=True, random_state=2018)#5折交叉验证
oof_lgb = np.zeros(len(train))#存放训练集的预测结果
predictions_lgb = np.zeros(len(test))#存放测试集的预测结果
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
trn_data = lgb.Dataset(X_train[trn_idx], y_train[trn_idx])#80%的训练集用于训练
val_data = lgb.Dataset(X_train[val_idx], y_train[val_idx])#20%的训练集做验证集
num_round = 10000
clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=200, early_stopping_rounds = 100)#训练过程
oof_lgb[val_idx] = clf.predict(X_train[val_idx], num_iteration=clf.best_iteration)#对验证集得到预测结果
predictions_lgb += clf.predict(X_test, num_iteration=clf.best_iteration) / folds.n_splits#对测试集5次取平均值
print("CV score: {:<8.8f}".format(mean_squared_error(oof_lgb, target)))
这样我们得到了模型3训练集的又一个特征oof_lgb,还有测试集的又一个特征predictions_lgb 。
3.3逻辑回归LinearRegression()
下一个步骤就是将模型1,模型2的输出作为第二层模型的输入,这里选用的第二层模型是 LogisticsRegression
然后用第二层模型进行训练和预测
# 将lgb和xgb的结果进行stacking(叠加)
train_stack = np.vstack([oof_lgb,oof_xgb]).transpose()#训练集2列特征
test_stack = np.vstack([predictions_lgb, predictions_xgb]).transpose()#测试集2列特征
#贝叶斯分类器也使用交叉验证的方法,5折,重复2次,主要是避免过拟合
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2018)
oof_stack = np.zeros(train_stack.shape[0])#存放训练集中验证集的预测结果
predictions = np.zeros(test_stack.shape[0])#存放测试集的预测结果
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack,target)):#target就是每一行样本的标签值
print("fold {}".format(fold_))
trn_data, trn_y = train_stack[trn_idx], target.iloc[trn_idx].values#划分训练集的80%
val_data, val_y = train_stack[val_idx], target.iloc[val_idx].values#划分训练集的20%做验证集
clf_3 = LinearRegression()
clf_3.fit(trn_data, trn_y)#贝叶斯训练过程,sklearn中的。
oof_stack[val_idx] = clf_3.predict(val_data)#对验证集有一个预测,用于后面计算模型的偏差
predictions += clf_3.predict(test_stack) / 10#对测试集的预测,除以10是因为5折交叉验证重复了2次
mean_squared_error(target.values, oof_stack)#计算出模型在训练集上的均方误差
print("CV score: {:<8.8f}".format(mean_squared_error(target.values, oof_stack)))
4.Stacking特点
使用stacking,组合1000多个模型,有时甚至要计算几十个小时。但是,这些怪物般的集成方法同样有着它的用处:
(1)它可以帮你打败当前学术界性能最好的算法
(2)我们有可能将集成的知识迁移到到简单的分类器上
(3)自动化的大型集成策略可以通过添加正则项有效的对抗过拟合,而且并不需要太多的调参和特征选择。所以从原则上讲,stacking非常适合于那些“懒人”
(4)这是目前提升机器学习效果最好的方法,或者说是最效率的方法human ensemble learning 。

个人微信公众号,专注于学习资源、笔记分享,欢迎关注。我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活,,如果觉得有点用的话,请不要吝啬你手中点赞的权力,谢谢我亲爱的读者朋友。

Life’s a little bit messy. We all make mistakes. No matter what type of animal you are, change starts with you.
生活总会有点不顺意,我们都会犯错。天性如何并不重要,重要的是你开始改变。
2020年3月24日于重庆城口
好好学习,天天向上,终有所获














 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









