






体系结构
概述
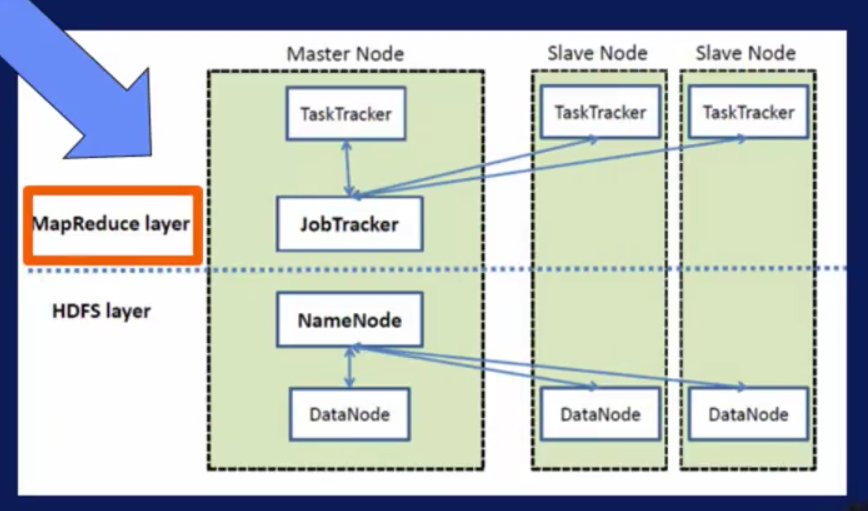
hadoop主要包括两部分:
- hdfs,文件操作系统
- mapreduce,分布式的计算框架
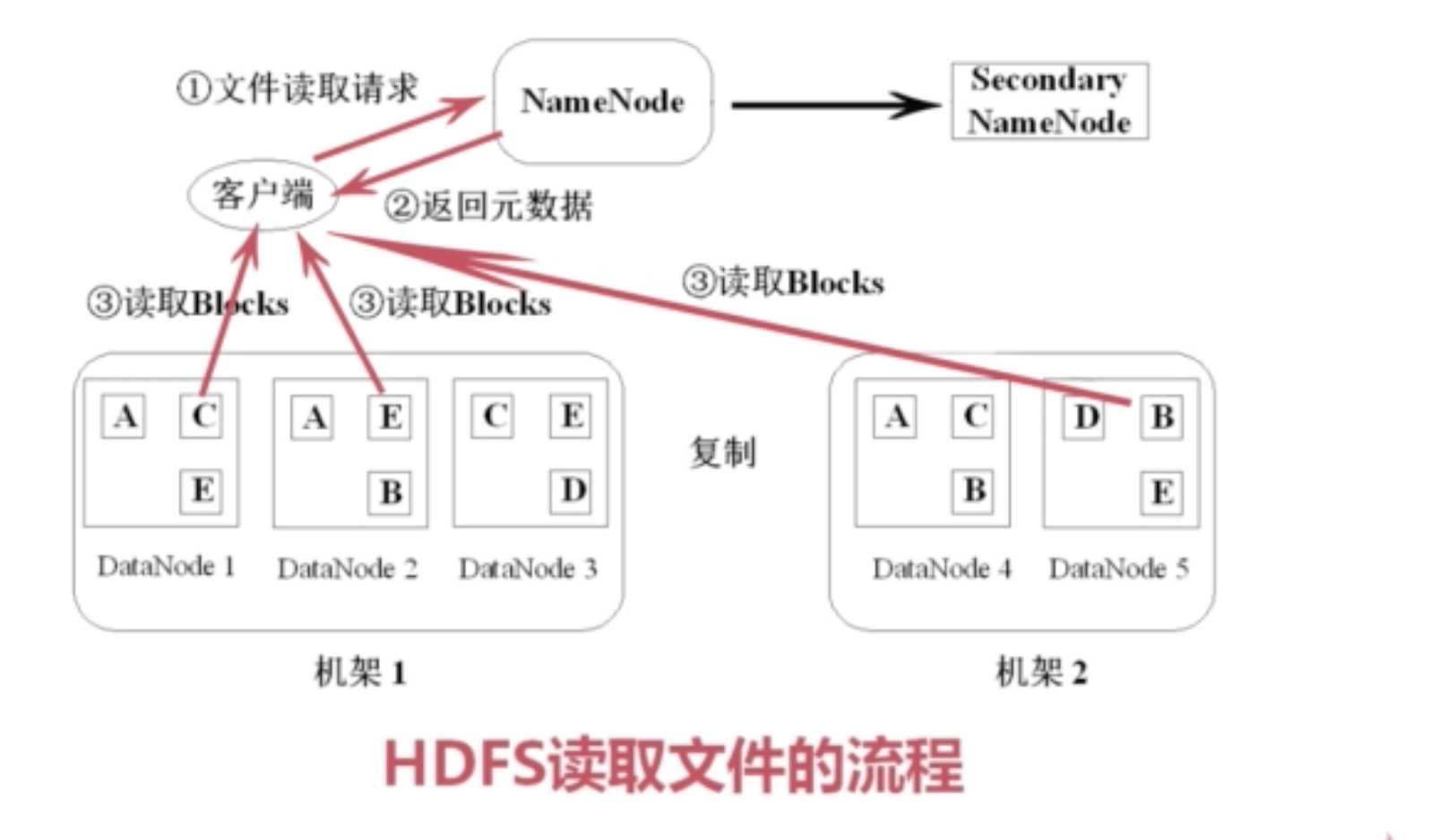
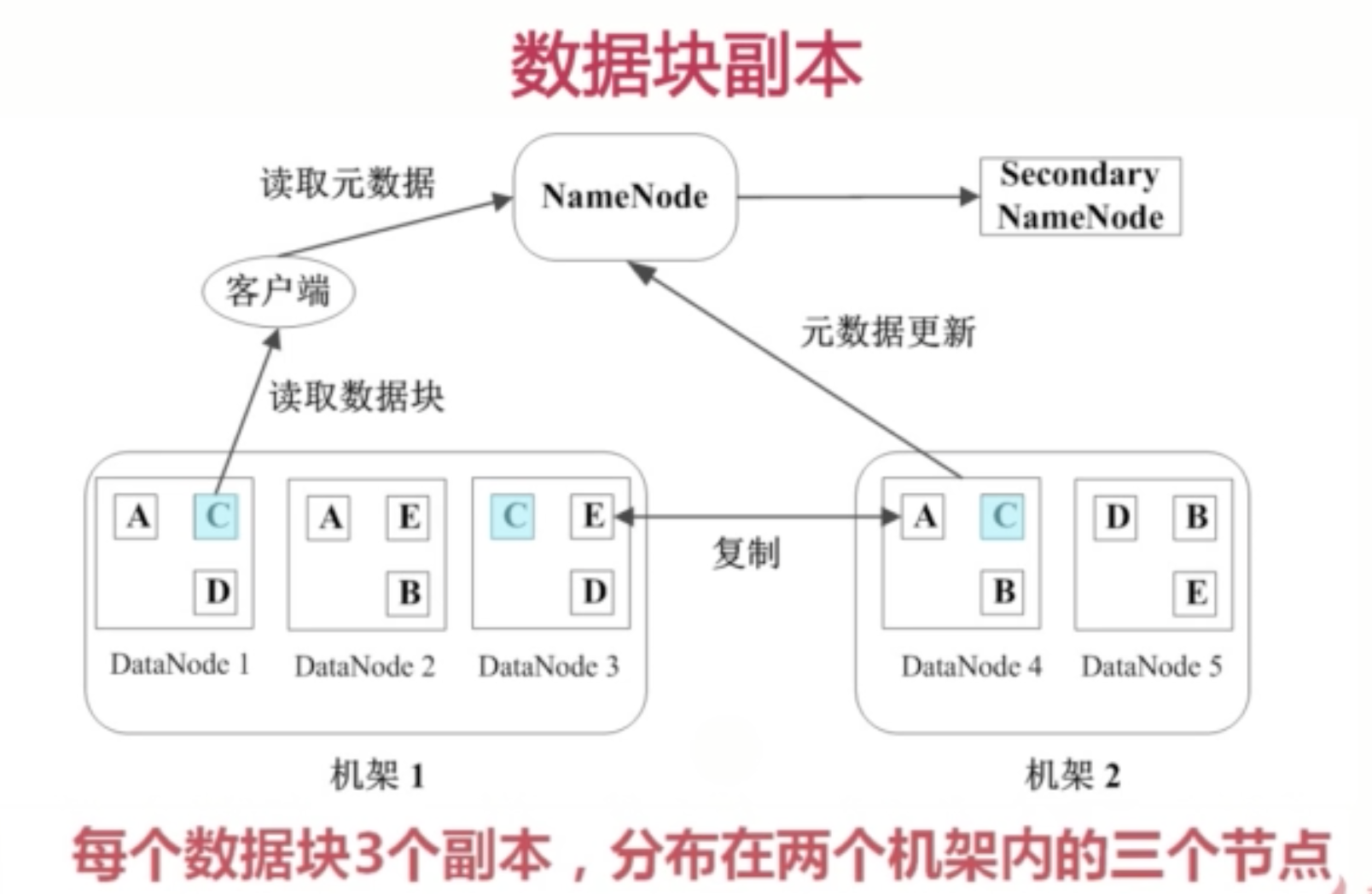
读的过程,客户端先从namenode读取metadata,然后根据metadata知道所需文件对应的数据块,以及数据块对应的datanode的位置。然后读取。
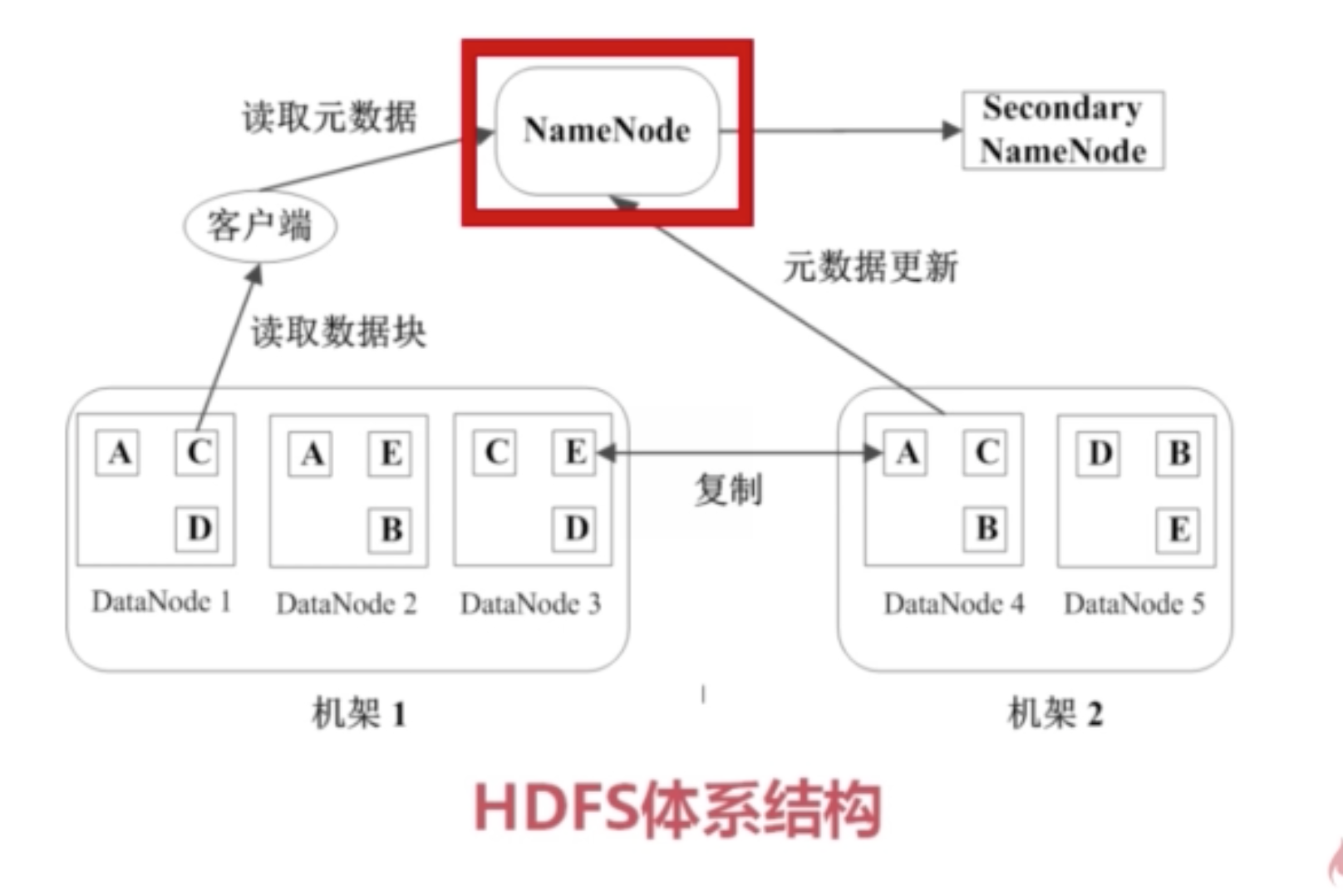
hdfs
主要由3部分组成
- block
- namenode
- datanode
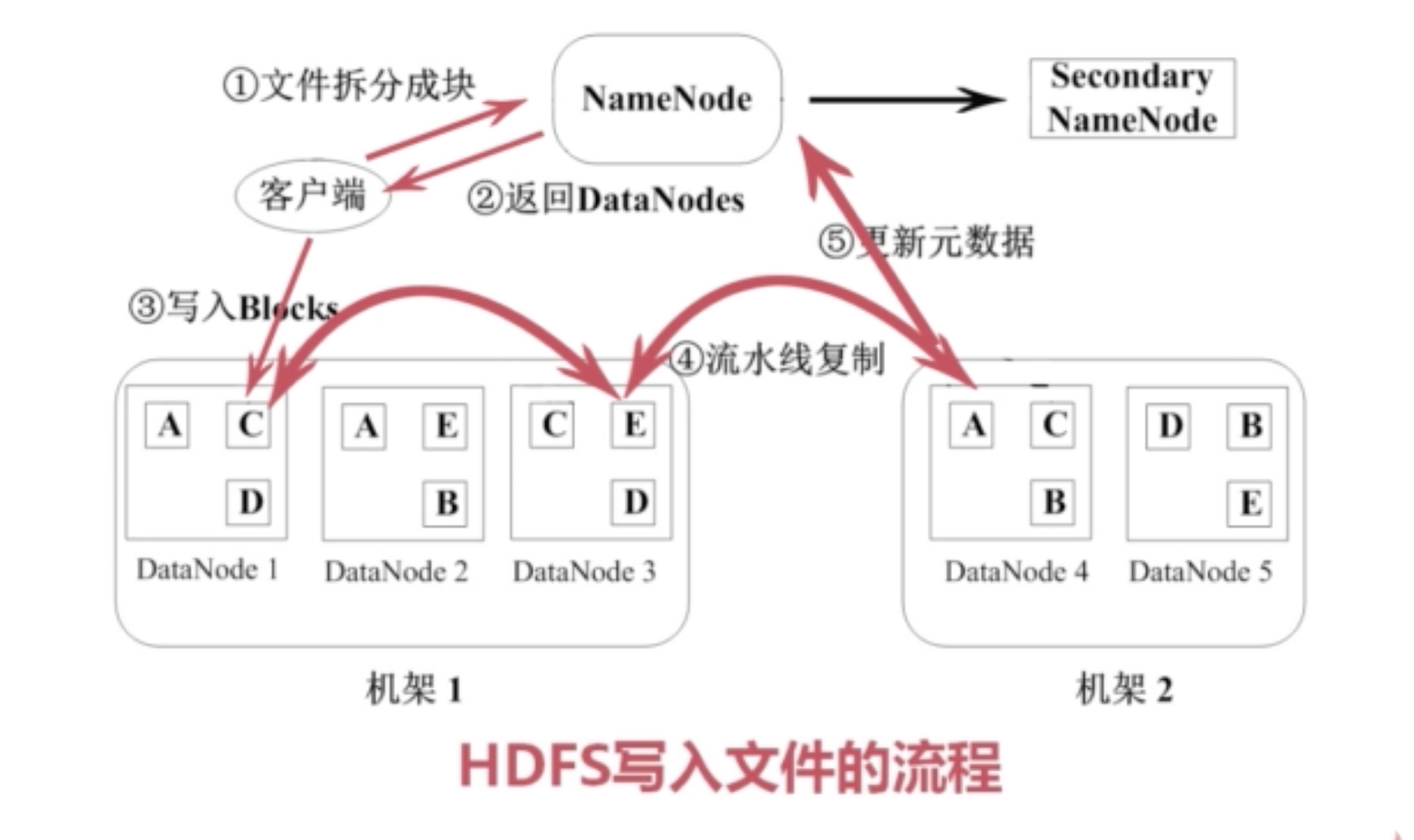
hdfs的文件被分成块进行存储,块的默认大小是64MB,块是文件存储处理的逻辑单元。
两类节点,namenode和datanode。
namenode是管理节点,存放文件元数据。
- 文件与数据块的映射表
- 数据块与数据节点的映射表
datanode是HDFS的工作节点,存放数据块。
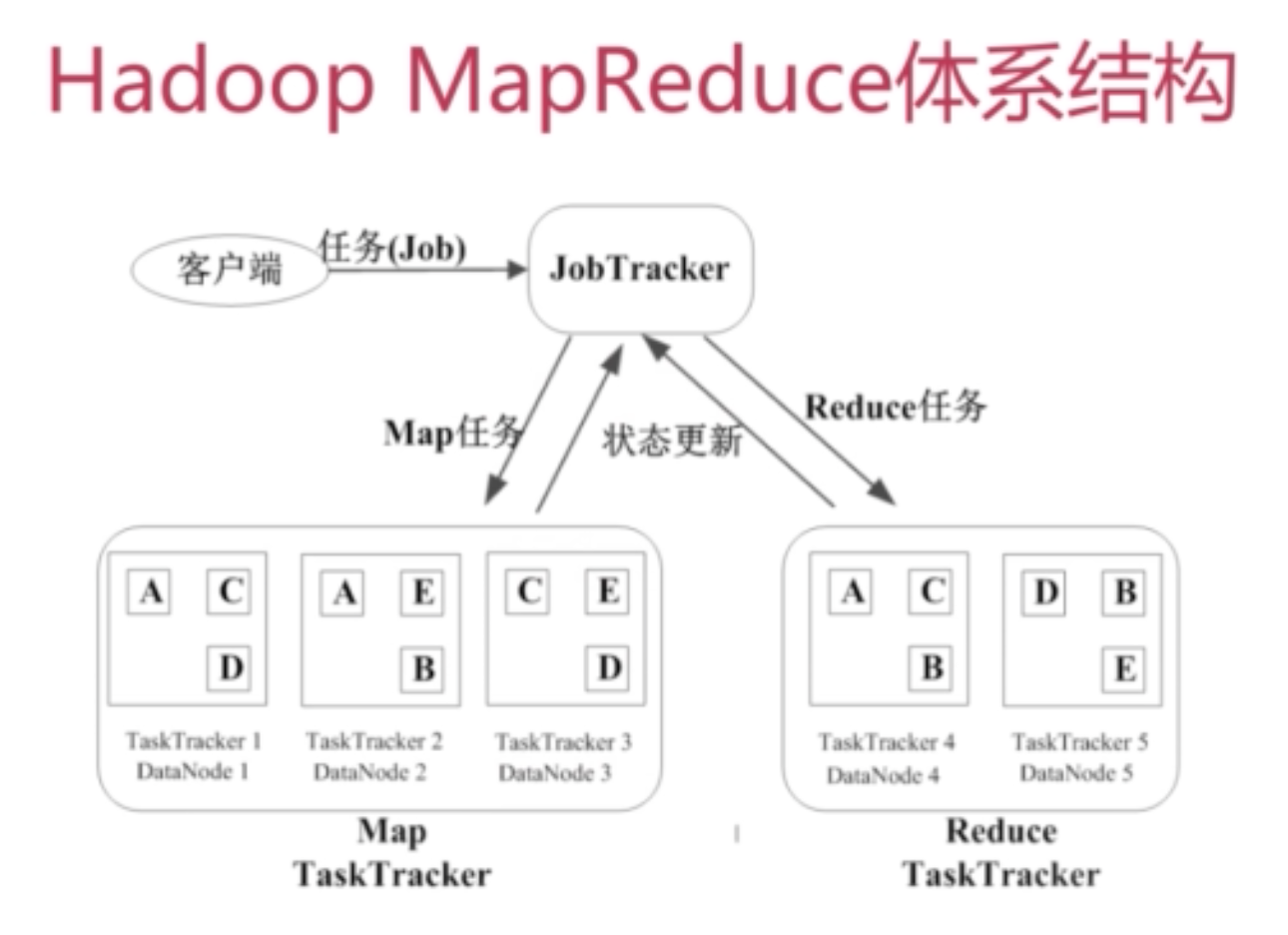
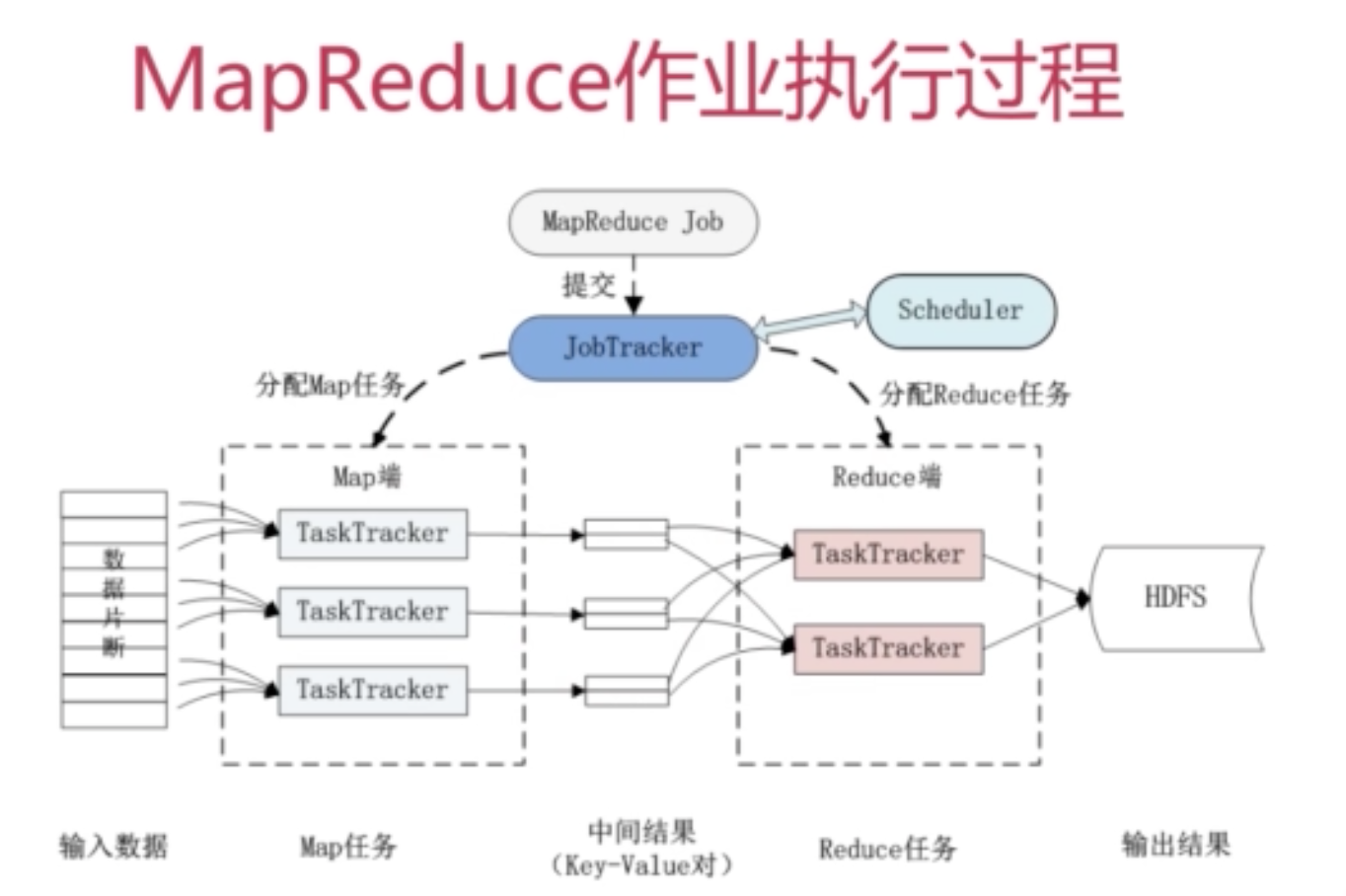
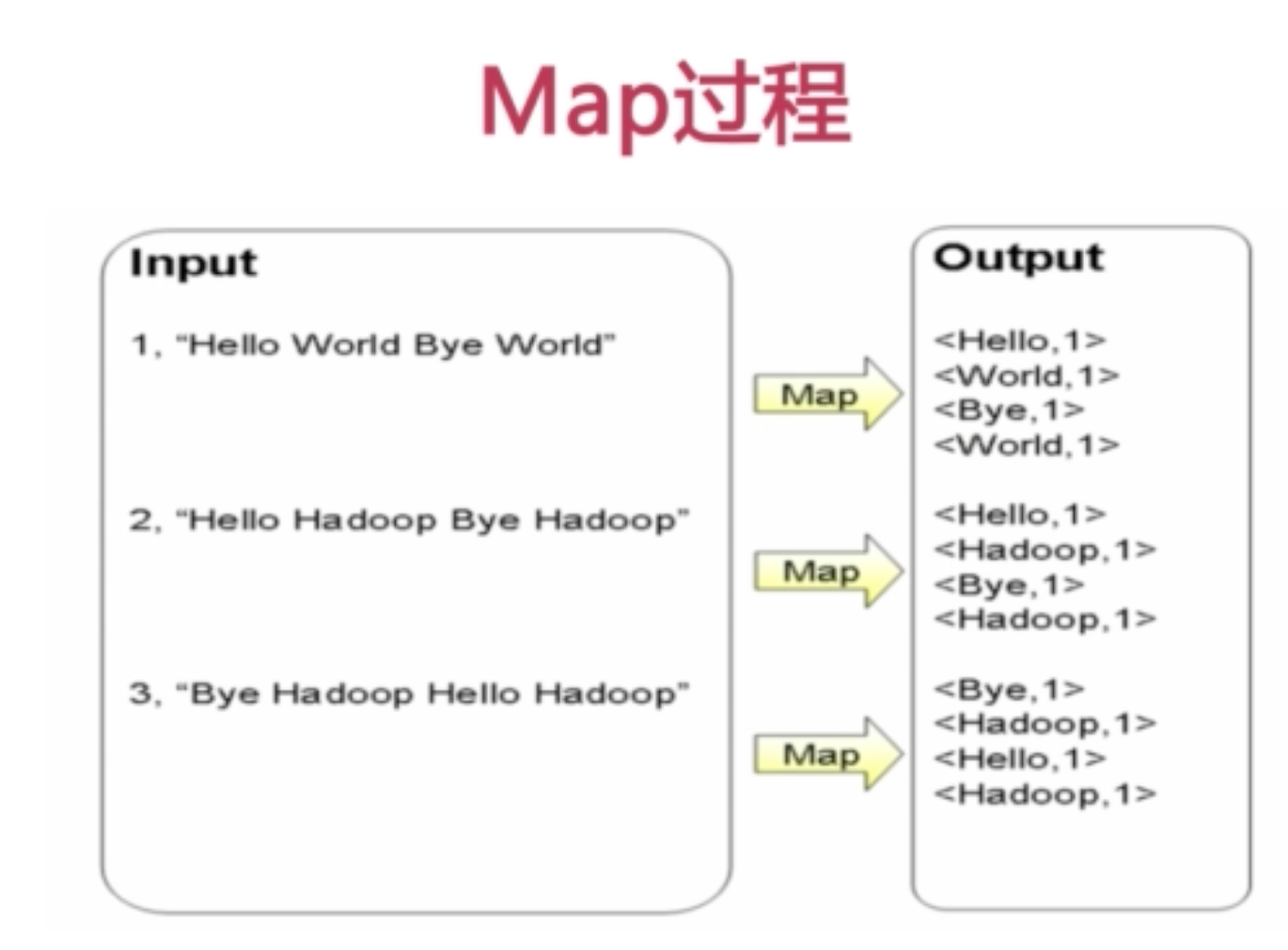
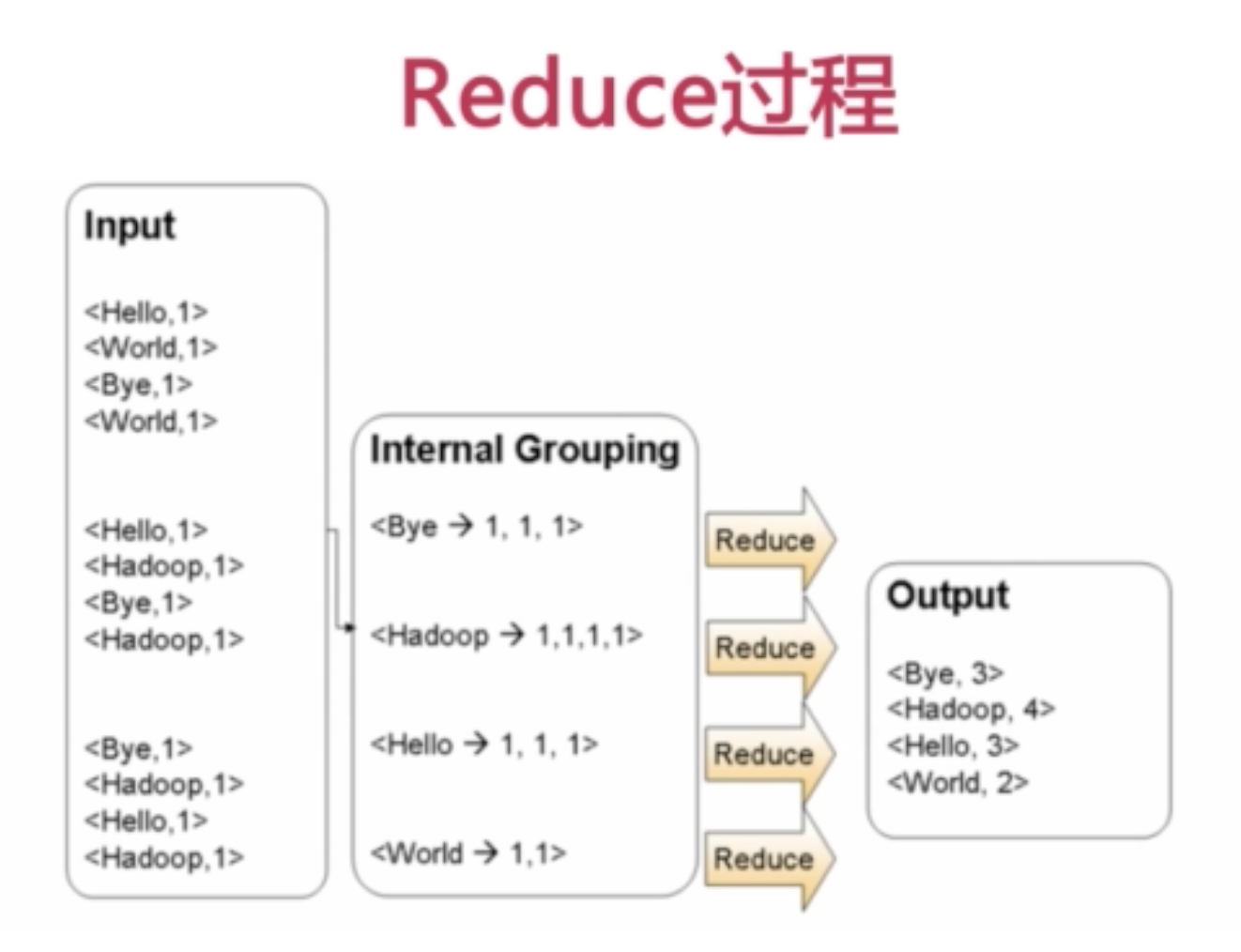
mapreduce
job and task
job分发给每个节点的task,具体有map task和reduce task
每个datanode都伴随着一个tasktracker,这样让计算跟着数据走,减少了很大的开销。
jobtracker
作业调度
分配任务,监控任务的执行进度
监控tasktracker的状态
tasktracker
执行任务
向jobtracker汇报状态
yarn
yarn是一个资源管理器,是在hadoop 2.0后添加的主要部件。
cloudera


读取文件
数据管理与容错
容错机制
1. 重复执行
2. 推测执行,有一个算的慢的话再找一个和它一起算,保证reduce不会因为map没做完不开始效率低。
数据块复制
数据块有副本,默认数据块保留三份。
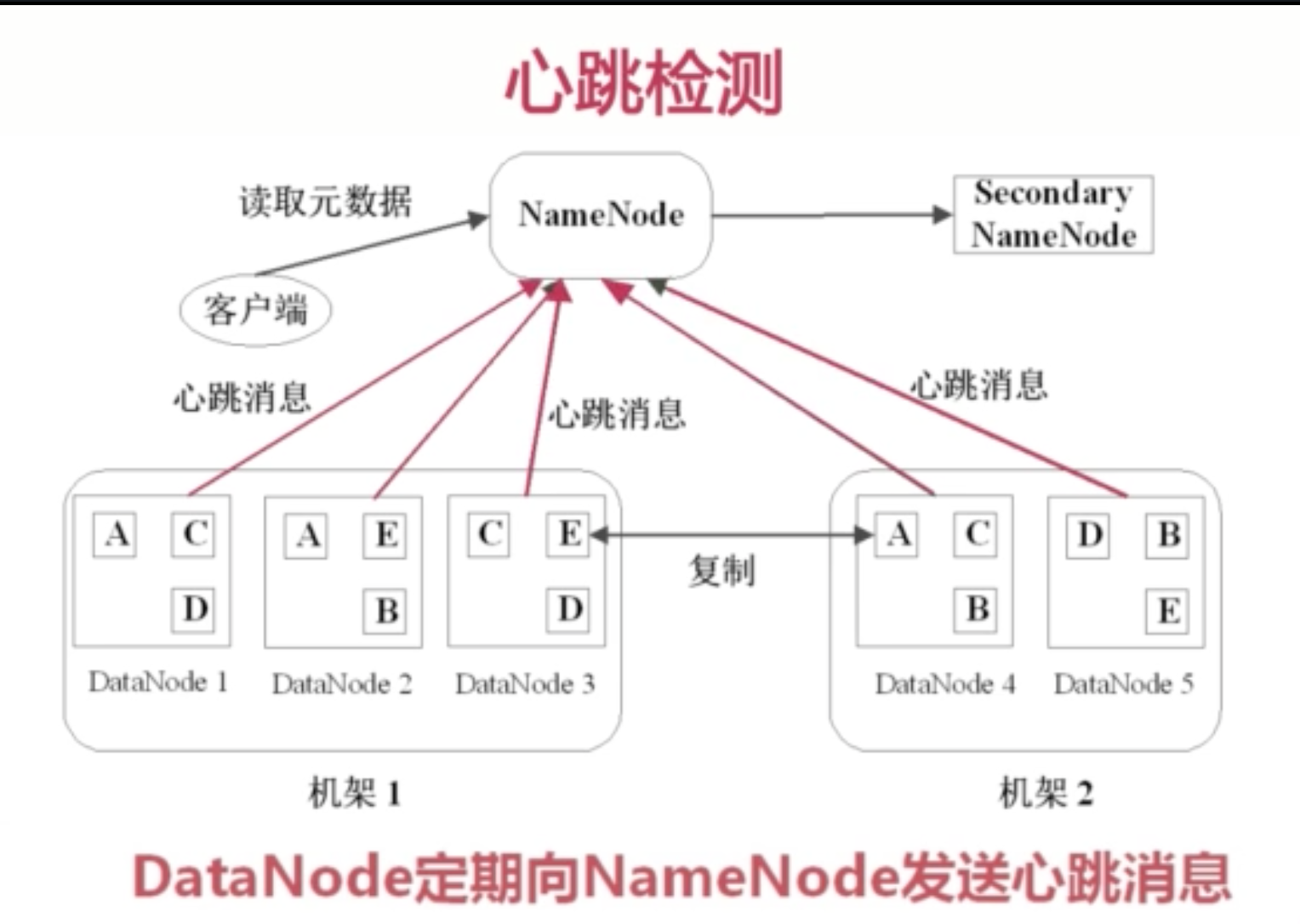
心跳检测
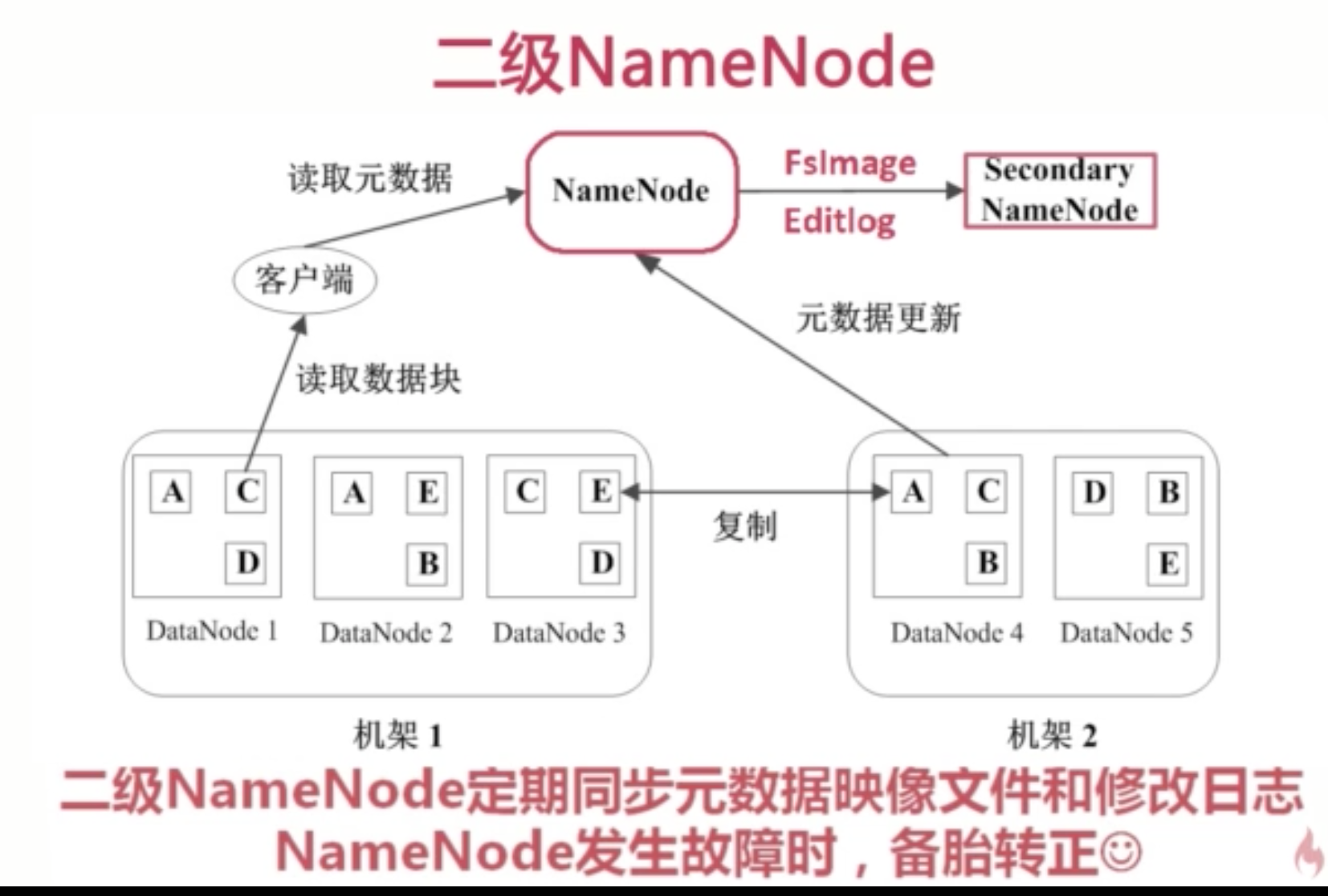
二级namenode,主要用于备份
HDFS特点
- 数据冗余,硬件容错
- 流式的数据访问,一次写入,多次读
- 存储大文件,如果大量的小文件那么对namenode上的元数据存储压力会很大
适用性和局限性
- 适合数据批量读写,吞吐量高;
- 不适合交互式应用,低延迟很难满足
- 适合一次写入多次读取,顺序读写
- 不支持多用户并发写相同文件
应用
单词计数
计算文件中每个单词的频数
输出结果按照字母顺序排序
- 编写WordCount.java,包含Mapper类和Reducer类
- 编译WordCount.java,javac -classpath need1.jar:need2.jar -d directory WordCount.java
- 打包 jar -cvf WordCount.jar *.class
- 作业提交 hadoop jar WordCount.jar WordCount input output
//WordCount.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
排序
对reduce进行分区

//Sort.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
public static class Map extends
Mapper<Object, Text, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class Reduce extends
Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable linenum = new IntWritable(1);
public void reduce(IntWritable key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
for (IntWritable val : values) {
context.write(linenum, key);
linenum = new IntWritable(linenum.get() + 1);
}
}
}
public static class Partition extends Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable key, IntWritable value,
int numPartitions) {
int MaxNumber = 65223;
int bound = MaxNumber / numPartitions + 1;
int keynumber = key.get();
for (int i = 0; i < numPartitions; i++) {
if (keynumber < bound * i && keynumber >= bound * (i - 1))
return i - 1;
}
return 0;
}
}
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage WordCount <int> <out>");
System.exit(2);
}
Job job = new Job(conf, "Sort");
job.setJarByClass(Sort.class);
job.setMapperClass(Map.class);
job.setPartitionerClass(Partition.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 4375
4375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









