







前面写的那个是老版本的写法,现在更新下,现代人的写法。
精简了许多代码,需要注意的是,在执行job时,要注意将
key和value的值进行下转换,否则map与reduce方法中的值
类型不对应就不能达到预期效果。
1,文件存放的路径与结果路径
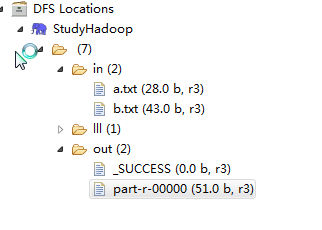
2,文件的具体内容


3,参数路径
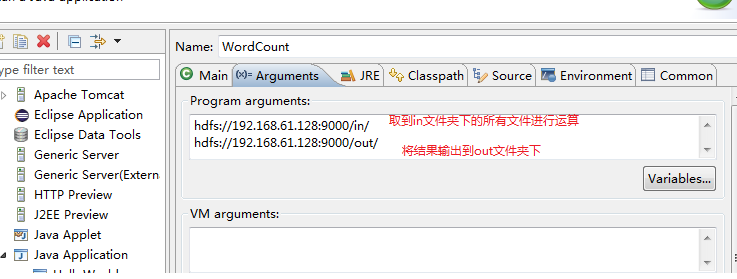
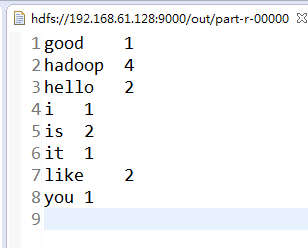
4具体结果
5,详细代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static final IntWritable ONE = new IntWritable(1);
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] vs = value.toString().split("\\s");//正则表达式,表示通过空格分隔
for (String v : vs) {
context.write(new Text(v), ONE);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable v : values) {
count += v.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
String[] paths = new GenericOptionsParser(conf, args).getRemainingArgs();
if(paths.length < 2){
throw new RuntimeException("usage <input> <output>");
}
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
//job.setCombinerClass(WordCountReducer.class);//有多个从机时需要指定reducer类,但是我这里是伪分布的只有一个所以不需要
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class); //因为map中返回的多了个long型的数据,在reduce接受的时候必须要转下字符类型
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReducer.class);
FileInputFormat.addInputPaths(job, paths[0]);//同时写入两个文件的内容
FileOutputFormat.setOutputPath(job, new Path(paths[1]));//整合好结果后输出的位置
System.exit(job.waitForCompletion(true) ? 0 : 1);//执行job
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}














 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









