







本文中的project是做了两方面的工作,首先是读取netcdf文件,并将其转成.CSV格式的数据(此处省略)。下面主要介绍的是如何利用scala开发spark程序,实现sparksql数据表的读取。
下面附上工程中所使用的.csv文件如下:
1.NELE_POINT.csv
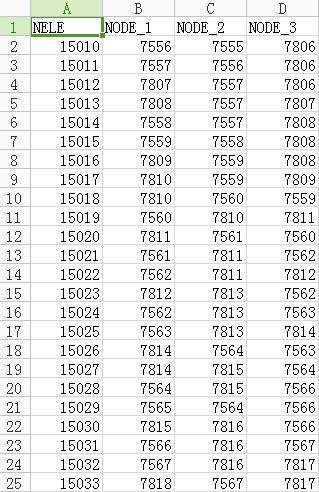
2.NODE.csv
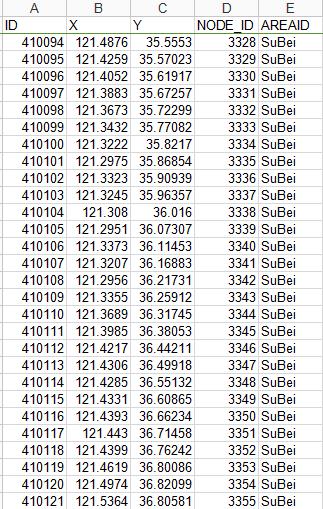
假设你已经下载或者配置好scala,在IDEA下新建一个scala工程,并将spark的安装目录下的lib添加到library中: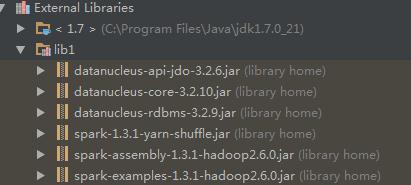
在工程中新建scala object,如下:
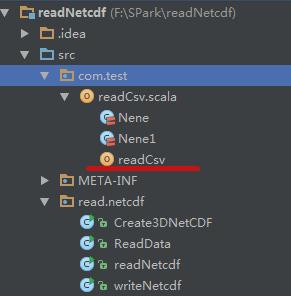
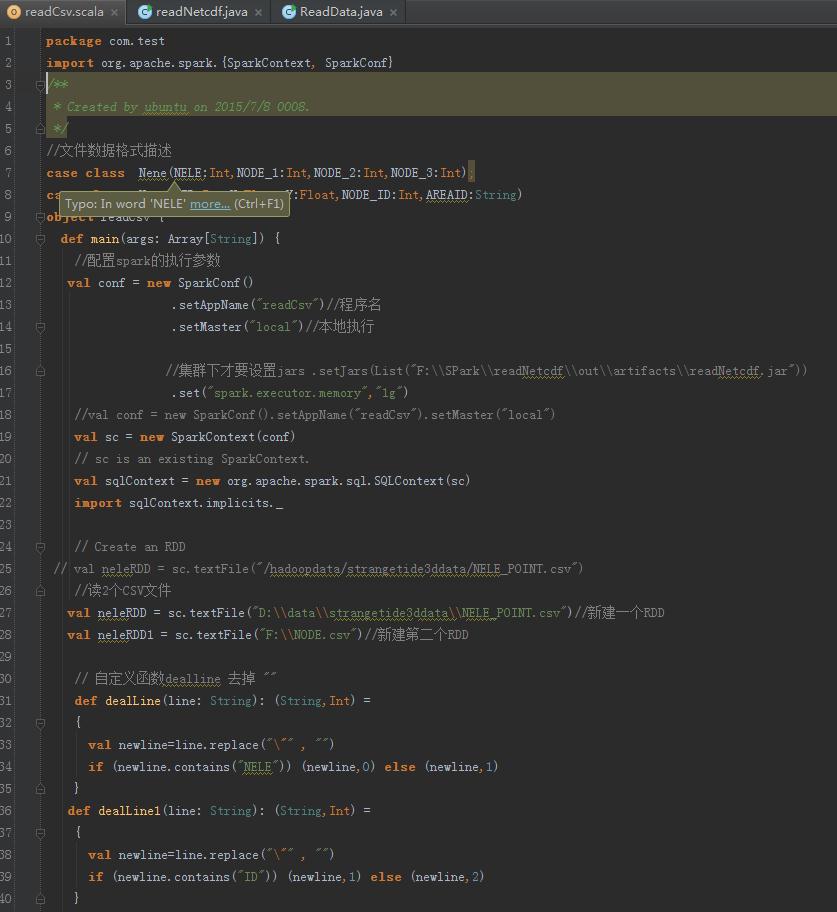
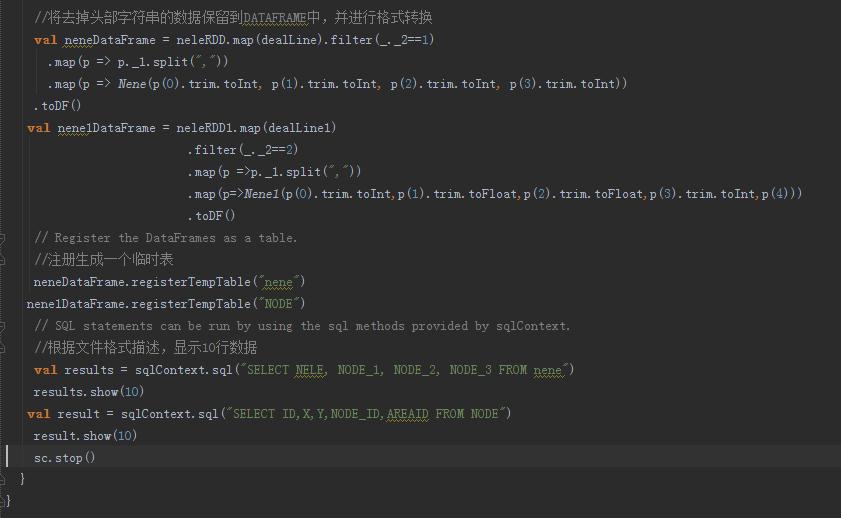
代码如下:(这里建立了两个RDD)
运行结果如下:
表1: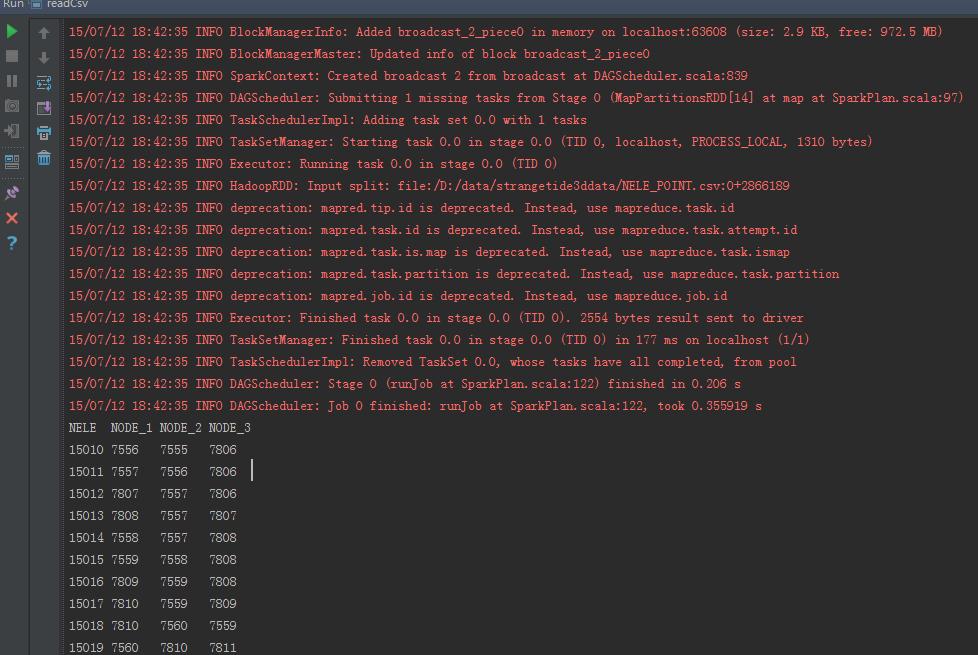
表2:
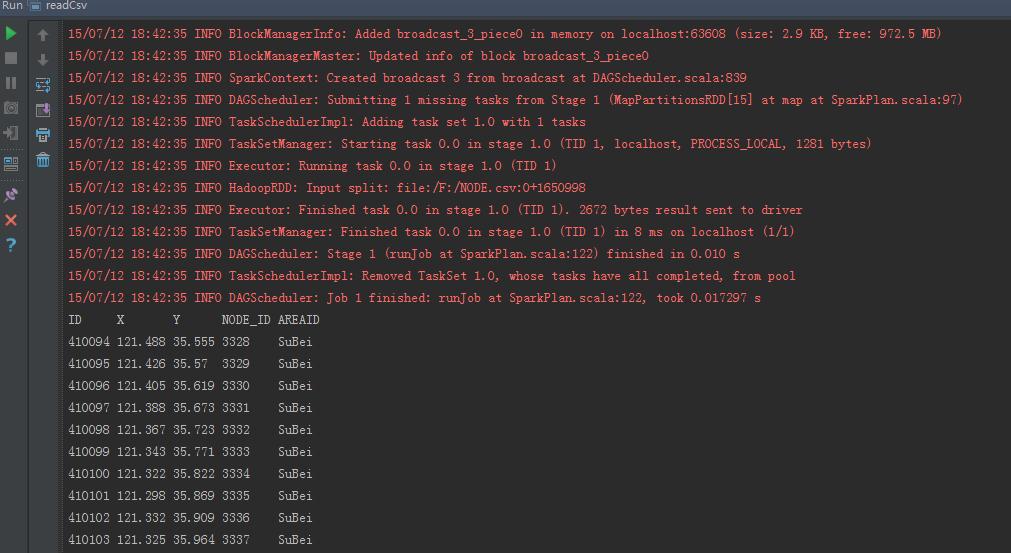
备注:
如果想提交到集群上,一方面是要改setmaster(“spark://ip:port”)还要设置jars(”.jar”),才能提交到集群上,同时要求你的scala版本与集群上的一致才可以。
如果你不嫌麻烦,那就打成jar包,上传的集群上,用spark-submit来提交job也可以。















 3188
3188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









