







pytorch 官网有大量数据集,可以通过函数调用的方式直接下载并使用,避免了繁琐的数据集搜集与整理工作。
在官方文档中有详细的 API 说明与数据集介绍:https://pytorch.org/docs/stable/index.html
torchvision中数据集的使用
下载与查看
这里下载 CIFAR10 数据集(用于图像识别,分类任务)。
root 为数据集要保存的根目录,train=True 表示下载训练集,download=True 表示如果本地没有该数据集,才从网上下载。
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=False,download=True)
可以看到,正在下载相应的数据集。如果网速过慢,可以粘贴链接到迅雷进行下载。

下载完毕,我们打个断点 debug 看看得到了个什么东西。

其中,classes 为该数据集的所有类别,targets 为所有图片对应的类别的索引。
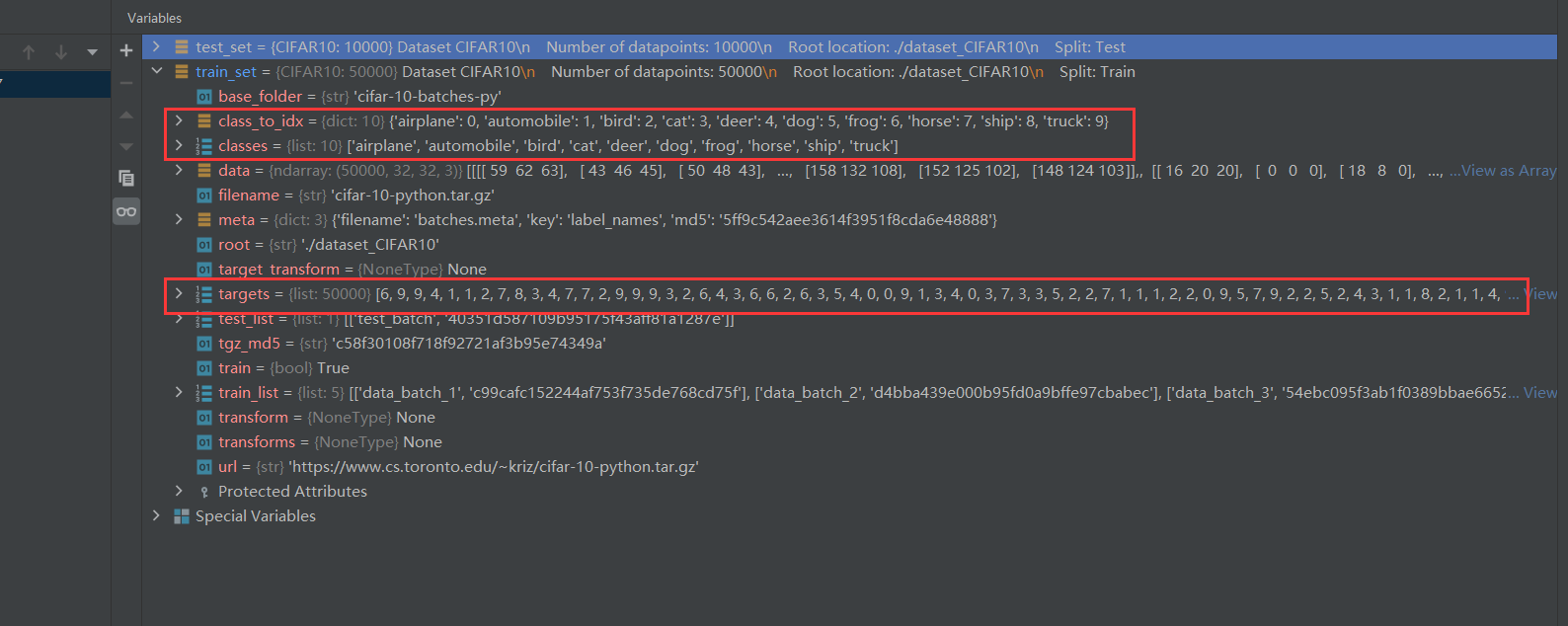
通过 target ,我们就能知道一张图片属于哪个类别。
import torchvision
from PIL import Image
train_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=False,download=True)
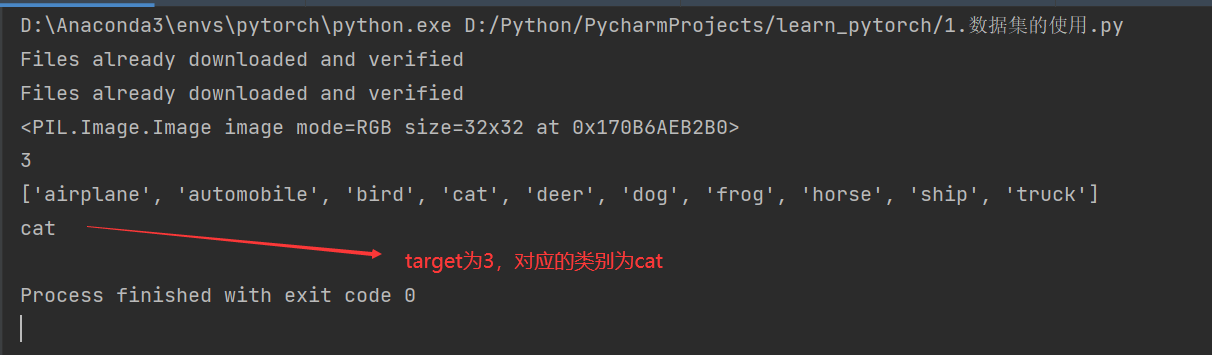
img,target = test_set[0]
print(img)
print(target)
print(test_set.classes)
print(test_set.classes[target])
img.show()
在tensorboard中显示
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 定义数据集要进行的变换
dataset_trans = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=True,
transform=dataset_trans,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=False,
transform=dataset_trans,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target = train_set[i]
print(i)
print(img)
writer.add_image("前十张图片",img,i)
writer.close()
如果出现图片无法显示的问题,那就删掉日志文件,重新运行并输入 tensorboard --logdir=p10 命令。
如果发现 step 不连续,有缺失,很正常,默认只显示十张。
如果想要显示更多图片,输入以下命令:
tensorboard --logdir=p10 --samples_per_plugin=images=100
dataloader的使用
dataset 决定了数据从哪里读取以及如何读取,dataloader 构建可迭代的数据装载器,进一步确定如何加载 dataset 里的数据。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=False,transform=dataset_transform)
# batch_size=4 表示随机四张图片打包
# num_workers=0 表示仅一个主线程
# shuffle=True 表示每次打包的四张图片顺序不同
# drop_last=False 表示打包无法整除时,最后的那几张图片留下
test_loader = DataLoader(test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
print(test_loader)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data # imgs将4张图片打包,3表示RGB targets表示4张图片的所有target
print(imgs.shape)
print(targets)
writer.add_images("test_data",imgs,step)
step += 1
pass
writer.close()
- batch_size=4 表示随机四张图片打包
- num_workers=0 表示仅一个主线程
- shuffle=True 表示每次打包的四张图片顺序不同
- drop_last=False 表示打包无法整除时,最后的那几张图片留下














 2961
2961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









