







所有代码链接:https://gitee.com/hurq5/os-labwork/tree/master/LabWeek15/code
1 相关代码解释和运行
1.1 alg.18-1-syn-fetch-1.c
1.1.1 相关知识点
__sync_fetch_and_add和 __sync_add_and_fetch都是原子性加法操作函数,可以在线程互斥的前提下对全局变量进行自加,不同的是___sync_fetch_and_add返回未进行加法的变量的值,而__sync_add_and_fetch返回进行了加法操作的变量的值。
1.1.2 程序原理以及细节解释
-
程序目的:
测试函数__sync_fetch_and_add和__sync_add_and_fetch的功能以及返回值。 -
程序逻辑及细节:
程序在主函数中定义变量i,赋值变量为i=10,并立即执行语句
printf("ret = %d, i = %d\n", __sync_fetch_and_add(&i, 20), i)来打印执行该语句时调用__sync_fetch_and_add(&i, 20)函数的返回值以及i的值。等上一条打印语句执行结束后,打印i的值;重新在主函数中赋值i的值为10,并立即执行语句
printf("ret = %d, i = %d\n", __sync_add_and_fetch(&i, 20), i);来打印执行该语句时调用__sync_add_and_fetch(&i, 20)函数的返回值以及i的值。等上一条打印语句执行结束后,打印i的值。
1.1.3 执行结果分析
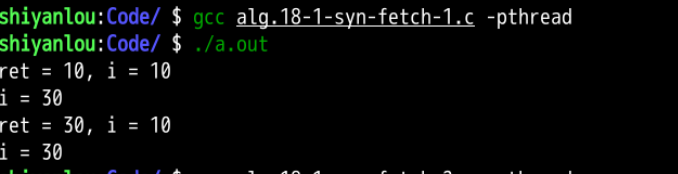
分析: 执行的结果符合函数的功能执行结果,__sync_fetch_and_add(&i, 20)的返回值为未执行加法的i值的大小,为10,函数执行结束i的值增加了20,__sync_add_and_fetch(&i, 20)的返回值为已经执行加法的i值的大小,为30,函数执行结束i的值增加了20.
1.2 alg.18-1-syn-fetch-2.c
1.2.1 程序原理以及细节解释
-
程序目的:
程序定义全局变量count的值,定义多个线程同时对该变量进行加一操作,程序测试__sync_fetch_and_add是否实现了不同线程改变全局变量时的互斥性。 -
程序逻辑及细节:
程序定义了静态全局变量
count,初始化其为0,在主函数中使用for循环调用MAX_N(定义为40)次pthread_create(&ptid[i], NULL, &test_func, NULL)函数创建了MAX_N个线程执行线程函数test_func,该线程函数如下:void *test_func(void *arg) { for (int i = 0; i < 20000; ++i) __sync_fetch_and_add(&count, 1); /* count++; gave a wrong result */ return NULL;线程函数使用
for循环调用了20000次__sync_fetch_and_add(&count, 1)对全局变量count进行加一操作。回到主线程中,主函数使用
for循环多次调用pthread_join(ptid[i], NULL);语句等待所有的线程执行结束。主程序的最后打印全局变量
count的值
1.2.2 执行结果分析

分析: 可以观察到count的结果为800000(40*20000),这说明了所有的40个线程对全局变量count的修改是互斥的,说明了函数__sync_fetch_and_add可以实现的不同线程对同一变量加法的互斥。
1.3 alg.18-1-syn-fetch-3.c
1.3.1 程序原理以及细节解释
-
程序目的:
程序定义全局变量count的值,定义多个线程同时使用count++对该变量进行加一操作,观察多个线程非原子操作同一个全局变量出现的时序混乱的问题。 -
程序逻辑及细节:
对比程序
alg.18-1-syn-fetch-2.c只是将线程函数for循环中__sync_fetch_and_add(&count, 1);对count进行加一操作的语句改成count++;
1.3.2 执行结果分析

分析: result的结果比预期要小很多,说明多个线程同时操作count时存在时序混乱,具体分析原因:
count++这种操作不是原子的,它的本质是分成三步:
1 从缓存取到寄存器
2 在寄存器加1
3 存入缓存。
++过程是在寄存器中进行的,因为不同进程持有CPU的控制权的时间满足时间片轮转,因此在整个过程中会出现混乱,以下举个可能的例子说明这种时序混乱:
一开始,时间片分给线程A执行代码,当count在寄存中中累加到了20000(或者更小),此时 时间片被用完了,而存放在寄存器中的中间变量还没来及写入实际的物理内存,时间片就分配 给线程B,由于线程A算出来的值并没有写回内存,所以实际上此时线程B还是取到的count依 旧等于0,进行20000次 的++ 操作,时间片刚好够用,线程B将得到的等于20000的count写回 了实际的物理内存,时间片再度分配给线程A, 线程A开始执行它在上一个时间片结束时没有执 行完的工作,将等于20000的count写入实际的物理内存,计算机严格按照代码执行指令,殊不 知此时会将由线程B计算出来的等于20000的count覆盖。因此得到的最后的count值偏小。
1.4 alg.18-2-syn-compare-test.c
1.4.1 相关知识点
-
__sync_bool_compare_and_swap(&value,old,new)是原子性操作函数,可以在线程互斥的前提下完成其功能,当旧值与存储中的当前值value一致相等时,把新值写入存储,value的值改变为新值,写入新值成功返回1,失败返回0。 -
___sync_val_compare_and_swap实现的功能和__sync_bool_compare_and_swap(&value,old,new)相同,返回值不同,返回值返回value的原值。 -
T
__sync_lock_test_and_set(T * __p,T __v,...);此功能原子为原子操作,功能是将变量__p指向的值赋给__v,返回值为value的原值。 -
__sync_lock_release(T * __p,...);释放由__sync_lock_test_and_set函数建立的内存屏障,并将零值赋给__p指向的变量。
1.4.2程序原理以及细节解释
-
程序目的:
测试函数__sync_bool_compare_and_swap和__sync_bool_compare_and_swap的功能以及返回值。 -
程序逻辑及细节:
对比程序alg.18-1-syn-fetch-2.c只是将线程函数for循环中
__sync_fetch_and_add(&count, 1);对count进行加一操作的语句改成count++;
1.4.3 执行结果分析

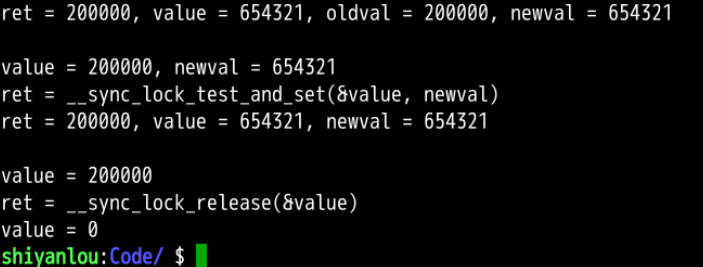
分析: 程序测试了函数__sync_bool_compare_and_swap的功能:
在样例一中,执行ret = __sync_bool_compare_and_swap(&value, oldval, newval);语句,value(= 200000)的值不等于oldval( = 123456)的值,因此value的值不发生修改,仍然为200000,并且函数的返回值ret为0;
在样例二中,执行ret = __sync_bool_compare_and_swap(&value, oldval, newval);语句,value(= 200000)的值等于oldval( = 200000)的值,因此value的值被修改为newval的值,为654321,并且函数的返回值ret为1;
在样例三中,执行ret = __sync_val_compare_and_swap(&value, oldval, newval)语句,value(= 200000)的值不等于oldval( = 123456)的值= 200000,因此value的值不发生修改,仍然为200000,并且函数的返回值ret为value的原值200000;
在样例四中,执行ret = __sync_val_compare_and_swap(&value, oldval, newval)语句,value(= 200000)的值等于oldval( = 200000)的值,因此value的值被修改为newval的值,为654321,并且函数的返回值ret为``value`的原值200000;;
在样例五中,,执行ret = __sync_lock_test_and_set(&value, newval);语句,将value的值修改为newval的值,为654321,并且函数的返回值ret为value的原值200000;
在样例六中,value指向的内存被释放了内存屏障,并且函数的返回值ret为0;
1.5 alg.18-3-syn-pthread-mutex.c
1.5.1 相关知识点:互斥锁
-
简单介绍:
互斥锁是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。 -
创建方法:
-
静态方法:
使用语句
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;将POSIX定义的一个宏PTHREAD_MUTEX_INITIALIZER(结构常量)直接赋值给结构变量mutex,完成互斥锁的静态初始化; -
动态方法:调用
pthread_mutex_init()函数来初始化互斥锁:该函数原型以及相关参数解释如下:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr) //mutexattr:可以用来指定互斥锁属性(如下),也可以为NULL /* * PTHREAD_MUTEX_TIMED_NP,这是缺省值,也就是普通锁。当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。 * PTHREAD_MUTEX_RECURSIVE_NP,嵌套锁,允许同一个线程对同一个锁成功获得多次,并通过多次unlock解锁。如果是不同线程请求,则在加锁线程解锁时重新竞争。 * PTHREAD_MUTEX_ERRORCHECK_NP,检错锁,如果同一个线程请求同一个锁,则返回EDEADLK,否则与PTHREAD_MUTEX_TIMED_NP类型动作相同。这样就保证当不允许多次加锁时不会出现最简单情况下的死锁。 * PTHREAD_MUTEX_ADAPTIVE_NP,适应锁,动作最简单的锁类型,仅等待解锁后重新竞争。 */
-
-
销毁方法:
调用函数pthread_mutex_destroy用于注销一个互斥锁,销毁一个互斥锁即意味着释放它所占用的资源,且要求锁当前处于开放状态. 该函数原型如下:
int pthread_mutex_destroy(pthread_mutex_t *mutex) -
相关操作:
包括加锁 pthread_mutex_lock()、解锁pthread_mutex_unlock()和测试加锁 pthread_mutex_trylock()三个,其函数原型如下:
int pthread_mutex_lock(pthread_mutex_t *mutex) int pthread_mutex_unlock(pthread_mutex_t *mutex) int pthread_mutex_trylock(pthread_mutex_t *mutex)
1.5.2 程序原理以及细节解释
-
程序目的:
测试互斥锁pthread_mutex_t是否能够实现线程之间对同一公共资源(比如全局变量)改变的同步互斥。 -
程序逻辑及细节:
函数在全局使用语句
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;来定义并静态初始化互斥锁mutex。并且定义了静态全局变量count用来测试互斥锁是否实现其功能。主程序使用
if(argc > 1 && !strncmp(argv[1], "syn", 3))语句来判断并执行不同命令行指令输入的情况;当输入的命令行有第二个参数并且第二个参数的值为syn,程序测试互斥锁是否实现同步互斥,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_syn, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_syn,该线程函数的内容如下:void *test_func_syn(void *arg) { for (int i = 0; i < 20000; ++i) { pthread_mutex_lock(&mutex); count++; pthread_mutex_unlock(&mutex); } pthread_exit(NULL); }线程函数使用
for循环执行了20000次count++指令,并且在每次该指令执行前调用pthread_mutex_lock(&mutex)函数对线程进行上互斥锁的操作,在该指令执行后调用函数pthread_mutex_unlock(&mutex);函数对该互斥锁进行解锁。回到主函数
当输入的命令行没有第二个参数或者第二个参数的值不为syn时,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_asy, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_asy,该线程函数的内容如下:void *test_func_asy(void *arg) { for (int i = 0; i < 20000; ++i) { count++; } pthread_exit(NULL); }线程函数只是简单的使用
for循环执行了20000次count++指令,不涉及任何互斥锁操作。回到主函数,程序调用
pthread_join阻塞等待所有线程执行完毕,程序销毁互斥锁,并且输出静态全局变量count的值.
1.5.3 执行结果分析

分析:
- 可以观察到当不使用互斥锁的时候(即命令窗口调用**.
/a.out**指令),多个线程会同时修改静态全局变量count的值,从而造成冲突(具体冲突原因在alg.18-1-syn-fetch-3.c的实验验证内容中有)。 - 当使用互斥锁的时候(即命令窗口调用**.
/a.out sym**指令),多个线程会同时修改静态全局变量count的值,结果并没有发生冲突,很好的验证了互斥锁的功能。
1.6 alg.18-4-syn-pthread-sem-unnamed.c
1.6.1 相关知识点:信号量semaphore(无名)
-
简单介绍:
信号量是一种变量或抽象数据类型,用于多个进程(线程)对公共资源的访问。信号量只是一个变量。此变量用于解决关键部分问题,并在多处理环境中实现过程同步。
现实世界中使用信号量的一种有用方法是记录特定资源有多少个单位可用,并结合操作以安全地调整该记录(即避免出现竞争状况)。如果资源可获取,那么线程就获取该资源免费,否则线程等待到有资源可用为止。
允许任意资源计数的信号量称为计数信号量,而将值限制为0和1(或锁定/未锁定,不可用/可用)的信号量称为二进制信号量,并用于实现锁。
-
头文件: #include<semaphore.h>
-
数据类型: 结构sem_t
-
创建方法(初始化):(这里介绍无名信号量)
调用函数
sem_init()用来初始化一个信号量,设置好它的共享选项,并指定一个整数类型的初始值,该函数的原型以及相关参数的介绍如下:int sem_init __P ((sem_t *__sem, int __pshared, unsigned int __value)); //__sem:指向信号量结构的一个指针 //__pshared:不为0时此信号量在进程间共享,否则只能为当前进程的所有线程共享 //__value:信号量的初始值 -
销毁方法:(这里介绍无名信号量)
调用函数
sem_destroy(sem_t *sem)用来释放无名信号量sem, 该函数的原型以及相关参数的介绍如下:int sem_destroy (sem_t *sem); //_sem:指向信号量结构的一个指针 //成功返回0 -
相关操作:
-
调用函数
sem_post( sem_t *sem )用来增加信号量的值,有线程阻塞在这个信号量上时,调用这个函数会使其中的一个线程不在阻塞,选择机制同样是由线程的调度策略决定的。该函数的原型以及相关参数的介绍如下:int sem_post(sem_t *sem);sem_post() //调用成功返回0,错误则信号量的值没有更改,返回-1 -
调用函数
sem_wait( sem_t *sem )被用来阻塞当前线程直到信号量sem的值大于0,解除阻塞后将sem的值减一,表明公共资源经使用后减少.该操作为原子操作,该函数的原型以及相关参数的介绍如下:int sem_wait(sem_t * sem);
-
1.6.2 程序原理以及细节解释
-
程序目的:
测试无名信号量semaphore是否能够实现线程之间对同一公共资源(比如全局变量)改变的同步互斥。 -
程序逻辑及细节:
函数在全局使用语句
sem_t unnamed_sem;来定义无名信号量unnamed_sem。并且定义了静态全局变量count用来测试互斥锁是否实现其功能。主程序执行语句
ret = sem_init(&unnamed_sem, 0, 1);来初始化无名信号量unnamed_sem的属性为默认属性,初始值为1,使用if(argc > 1 && !strncmp(argv[1], "syn", 3))语句来判断并执行不同命令行指令输入的情况;当输入的命令行有第二个参数并且第二个参数的值为syn,程序测试信号量是否实现同步互斥,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_syn, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_syn,该线程函数的内容如下:void *test_func_syn(void *arg) { for (int i = 0; i < 20000; ++i) { sem_wait(&unnamed_sem); count++; sem_post(&unnamed_sem); } pthread_exit(NULL); }线程函数使用
for循环执行了20000次count++指令,并且在每次该指令执行前调用sem_wait(&unnamed_sem);来阻塞当前线程直到信号量unnamed_sem的值大于0,解除阻塞后将unnamed_sem的值减一,在该指令执行后调用函数sem_post(&unnamed_sem);函数用来增加信号量unnamed_sem的值,使得其他等待线程可以访问修改公共资源count。回到主函数
当输入的命令行没有第二个参数或者第二个参数的值不为syn时,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_asy, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_asy,该线程函数的内容如下:void *test_func_asy(void *arg) { for (int i = 0; i < 20000; ++i) { count++; } pthread_exit(NULL); }线程函数只是简单的使用
for循环执行了20000次count++指令,不涉及任何信息量操作。回到主函数,程序调用
pthread_join阻塞等待所有线程执行完毕,销毁互斥锁,并且输出静态全局变量count的值.
1.6.3 执行结果分析
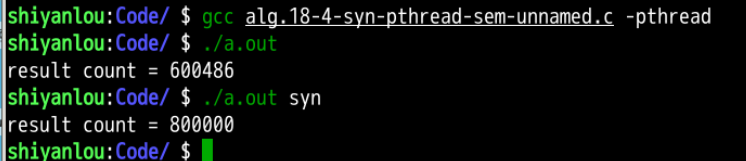
分析:
- 可以观察到当不使用无名信息量的时候(即命令窗口调用**.
/a.out**指令),多个线程会同时修改静态全局变量count的值,从而造成冲突(具体冲突原因在alg.18-1-syn-fetch-3.c的实验验证内容中有) - 当使用无名信息量的时候(即命令窗口调用**.
/a.out sym**指令),多个线程会同时修改静态全局变量count的值,结果并没有发生冲突,很好的验证了无名信息量的功能。
1.7 alg.18-5-syn-pthread-sem-named.c
1.7.1 相关知识点:信号量semaphore(有名)
-
创建方法:
调用函数
sem_open创建并初始化有名信号量,函数原型以及相关变量解释如下:sem_t *sem_open(const char *name,int oflag,mode_t mode,unsigned int value); //name:信号量的外部名字 //oflag:选择创建或打开一个现有的信号量 //mode:权限位 //value:信号量初始值 //成功时返回指向信号量的指针,出错时返回SEM_FAILED /* oflag参数: 0->打开一个已创建的 O_CREAT->创建一个信号量 O_CREAT|O_EXCL->如果没有指定的信号量就创建 */ -
销毁方法:
-
调用函数
sem_close关闭有名信号量,函数原型以及相关变量解释如下:int sem_close(sem_t *sem) //成功则返回0,否则返回-1 -
关闭一个信号量并没有将他从系统中删除,需要调用函数
sem_unlink从系统中删除信号量,每个信号量有一个引用计数器记录当前的打开次数,sem_unlink必须等待这个数为0时才能把name所指的信号量从文件系统中删除。也就是要等待最后一个sem_close发生。函数原型以及相关变量解释如下:int sem_unlink(const char *name) //成功则返回0,否则返回-1
-
-
相关操作:
调用函数
sem_post( sem_t *sem )用来增加信号量的值,调用函数sem_wait( sem_t *sem )被用来阻塞当前线程直到信号量sem的值大于0,解除阻塞后将sem的值减一。
1.7.2 程序原理以及细节解释
-
程序目的:
测试有名信号量是否能够实现线程之间对同一公共资源(比如全局变量)改变的同步互斥。 -
程序逻辑及细节:
函数在全局使用语句
sem_t *named_sem;来定义指向有名信号量的指针named_sem。并且定义了静态全局变量count用来测试互斥锁是否实现其功能。主程序执行语句
named_sem = sem_open("MYSEM", O_CREAT, 0666, 1);来初始化有名信号量named_sem的属性为O_CREAT,表示创建一个信号量,模式为0666表示可读写,初始值为1,程序在/ dev / shm /中创建一个名为“ sem.MYSEM”的文件,以供知道该文件名的进程共享使用
if(argc > 1 && !strncmp(argv[1], "syn", 3))语句来判断并执行不同命令行指令输入的情况;当输入的命令行有第二个参数并且第二个参数的值为syn,程序测试信号量是否实现同步互斥,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_syn, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_syn,该线程函数的内容如下:void *test_func_syn(void *arg) { for (int i = 0; i < 20000; ++i) { sem_wait(named_sem); count++; sem_post(named_sem); } pthread_exit(NULL); }线程函数使用
for循环执行了20000次count++指令,并且在每次该指令执行前调用sem_wait(&named_sem);来阻塞当前线程直到信号量named_sem的值大于0,解除阻塞后将named_sem的值减一,在该指令执行后调用函数sem_post(&named_sem);函数用来增加信号量named_sem的值,使得其他等待线程可以访问修改公共资源count。回到主函数
当输入的命令行没有第二个参数或者第二个参数的值不为syn时,主程序使用for循环调用
MAX_N次pthread_create(&ptid[i], NULL, &test_func_asy, NULL);函数来创建MAX_N线程,同时执行线程函数test_func_asy,该线程函数的内容如下:void *test_func_asy(void *arg) { for (int i = 0; i < 20000; ++i) { count++; } pthread_exit(NULL); }线程函数只是简单的使用
for循环执行了20000次count++指令,不涉及任何信息量操作。回到主函数,程序调用
pthread_join阻塞等待所有线程执行完毕,调用函数sem_close(named_sem)关闭有名信号量named_sem,调用函数sem_unlink("MYSEM"),当/ em / shm /的引用为0时,将其从/ dev / shm /中删除,并且输出静态全局变量count的值.
1.7.3 执行结果分析
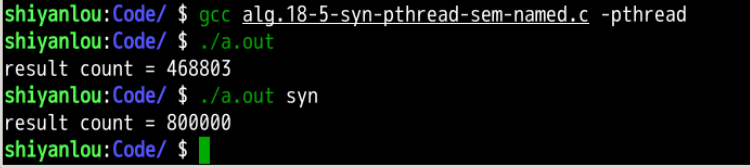
分析:
- 可以观察到当不使用有名信息量的时候(即命令窗口调用**.
/a.out**指令),多个线程会同时修改静态全局变量count的值,从而造成冲突(具体冲突原因在alg.18-1-syn-fetch-3.c的实验验证内容中有) - 当使用有名信息量的时候(即命令窗口调用**.
/a.out sym**指令),多个线程会同时修改静态全局变量count的值,结果并没有发生冲突,很好的验证了有名信息量的功能。
1.8 alg.18-6
1.8.1 相关知识点
1.8.2 程序原理以及细节解释
命令行的第二个参数为共享文件对象,输入共享文件对象则程序自己创立共享文件对象。
程序要求分别输入缓冲区大小buffer_size,最大商品数目max_item_num,生产者线程个数thread_pro,消费者线程个数thread_cons,buffer_size要求大于0小于等于100,max_item_num要求大于0小于等于10000,max_item_num要求大于0小于,buffer_size要求大于0,每个输入变量若不满足条件,程序要求用户立即重新输入。
程序创建共享内存,共享内存的前10个单元保留给控制变量ctln,数据从索引为10的单元开始
循环数据队列由(入队|出队)%buffer_size + BASE_ADDR表示,
对控制变量ctln进行初始化,设置控制变量记录的成员变量缓冲区大小BUFFER_SIZE,最大产品数量MAX_ITEM_NUM,生产者线程数THREAD_PRO,消费者线程数THREAD_CONS,为用户输入的特定对应的值。初始化记录的信息:产品数目item_num为0,消费的产品数目consume_num为0,生产者在产品队列中放置产品的位置enqueue和消费者在产品队列中取出产品的位置dequeue都为0,工作完成标记位END_FLAG为0,表示生产者尚未完成工作(生成足够的产品)
ctln->BUFFER_SIZE = buffer_size;
ctln->MAX_ITEM_NUM = max_item_num;
ctln->THREAD_PRO = thread_pro;
ctln->THREAD_CONS = thread_cons;
ctln->item_num = 0;
ctln->consume_num = 0;
ctln->enqueue = 0;
ctln->dequeue = 0;
ctln->END_FLAG = 0;
初始化ctln成员变量中的互斥信号量sem_mutex,设置其值为1;
初始化表示缓冲区存储数目的信号量stock,设置其值为0,表示缓冲区为空
初始化表示缓冲区未被存储的空闲空间数目的信号量emptyslot,设置其值为BUFFER_SIZE,表示c此时整个缓冲区都为空闲空间
ret = sem_init(&ctln->sem_mutex, 1, 1); /* the second parameter of sem_init must be set to non-zero for inter process sharing */
if (ret == -1) {
perror("sem_init-mutex");
return detachshm();
}
ret = sem_init(&ctln->stock, 1, 0); /* initialize to 0 */
if (ret == -1) {
perror("sem_init-stock");
return detachshm();
}
ret = sem_init(&ctln->emptyslot, 1, ctln->BUFFER_SIZE); /*initialize to BUFFER_SIZE */
if (ret == -1) {
perror("sem_init-emptyslot");
return detachshm();
}
初始化父进程要给子进程传入的参数argv1,如下
char *argv1[3];
char execname[] = "./";
char shmidstring[10];
sprintf(shmidstring, "%d", shmid);
argv1[0] = execname;
argv1[1] = shmidstring;
argv1[2] = NULL;
使用vfork创建父进程执行alg.18-8-syn-pc-consumer-6.o文件,以及子进程执行alg.18-7-syn-pc-producer-6.o文件(alg.18-8-syn-pc-consumer-6.o可执行文件是由源程序alg.18-8-syn-pc-consumer-6.c编译得到的
,alg.18-7-syn-pc-producer-6.o可执行文件是由源程序alg.18-7-syn-pc-producer-6.c编译得到的)
其中在alg.18-7-syn-pc-producer-6.c进程执行程序中:
该程序的开始通过映射连接到共享内存空间得到父进程创建或者打开的共享内存空间的访问限权,通过对内存空间地址的强制转换,赋值给ctln和data变量,来方便实现对控制单元和数据单元的分开访问,相关代码如下:
int shmid;
void *shm = NULL;
shmid = strtol(argv[1], NULL, 10); /* shmid delivered */
shm = shmat(shmid, 0, 0);
if (shm == (void *)-1) {
perror("\nproducer shmat()");
exit(EXIT_FAILURE);
}
ctln = (struct ctln_pc_st *)shm;
data = (struct data_pc_st *)shm;
程序使用for循环调用ctln->THREAD_PRO次pthread_create(&ptid[i], NULL, &producer, shm)函数来实现构建指定个数的生产者线程。
其中线程调用函数producer的程序关键内容如下:
void *producer(void *arg)
{
struct ctln_pc_st *ctln = (struct ctln_pc_st *)arg;
struct data_pc_st *data = (struct data_pc_st *)arg;
while (ctln->item_num < ctln->MAX_ITEM_NUM) {
sem_wait(&ctln->emptyslot);
sem_wait(&ctln->sem_mutex);
if (ctln->item_num < ctln->MAX_ITEM_NUM) {
ctln->item_num++;
ctln->enqueue = (ctln->enqueue + 1) % ctln->BUFFER_SIZE;
(data + ctln->enqueue + BASE_ADDR)->item_no = ctln->item_num;
(data + ctln->enqueue + BASE_ADDR)->pro_tid = gettid();
printf("producer tid %ld prepared item no %d, now enqueue = %d\n", (data + ctln->enqueue + BASE_ADDR)->pro_tid, (data + ctln->enqueue + BASE_ADDR)->item_no, ctln->enqueue);
if (ctln->item_num == ctln->MAX_ITEM_NUM)
ctln->END_FLAG = 1;
sem_post(&ctln->stock);
}
else {
sem_post(&ctln->emptyslot);
}
sem_post(&ctln->sem_mutex);
sleep(1);
}
pthread_exit(0);
}
分析: 函数在当前的产品量小于最大的产品量的前提下,循环执行生产代码,只有在满足生产的商品小于最大的产品量的条件下,才能够生产产品,在生产产品插入到数据队列中,以及修改控制单元变量之前,先调用sem_wait(&ctln->emptyslot)和sem_wait(&ctln->sem_mutex),等待数据空间的空位信号量和互斥信号量,如果信号量大于0函数将信号量-1,如果信号量等于0则挂起,等待前者的目的是保证数据队列有空余的空间放置产品,等待后者是为了防止多个线程同时修改数据队列和控制单元。生产产品的过程需要修改控制变量ctln中的成员变量产品数量item_num+1,生产插入产品队列的位置往后移动,修改为(ctln->enqueue + 1) % ctln->BUFFER_SIZE,设置该位置的产品数据单元的编号为当前已经生产的商品的数量,生产其的线程号为当前线程号(通过调用gettid()函数得到),当已生产的产品数量达到最大,生产进程完成任务,设置进程结束标志位END_FLAG为1,结束产品插入和信息修改后,调用sem_post(&ctln->stock);将信号量+1,表示产品队列中多了一件产品资源可待消耗。
相反,当生产的产品量已经达到最大产品量的时候,线程不生产产品,调用函数sem_post(&ctln->emptyslot)直接交出空余位置的资源emptyslot,一轮生产结束后,线程调用函数sem_post(&ctln->sem_mutex)将互斥信号量+1,表示其他线程可以修改数据队列和控制单元。结束一轮生产后线程休眠一秒。
回到生产者进程(主线程)本身:
程序使用for循环调用ctln->THREAD_PRO次pthread_join(ptid[i], NULL);函数阻塞等待所有的生产者线程执行完毕。
程序使用for循环调用ctln->THREAD_CONS - 1次sem_post(&ctln->stock)目的是在所有生产者都停止工作,防止某些消费者拿走最后的存货,以及不超过 THREAD_CON-1个消费线程阻塞在sem_wait(&stock)
for (i = 0; i < ctln->THREAD_CONS - 1; ++i)
/* all producers stop working, in case some consumer takes the last stock
and no more than THREAD_CON-1 consumers stick in the sem_wait(&stock) */
sem_post(&ctln->stock);
最后程序调用shmdt(shm)使得该共享空间脱离该进程的连接。
其中在alg.18-8-syn-pc-consumer-6.c进程执行程序中:
该程序的开始通过映射连接到共享内存空间得到父进程创建或者打开的共享内存空间的访问限权,通过对内存空间地址的强制转换,赋值给ctln和data变量,来方便实现对控制单元和数据单元的分开访问,相关代码如下:
int shmid;
void *shm = NULL;
shmid = strtol(argv[1], NULL, 10); /* shmid delivered */
shm = shmat(shmid, 0, 0);
if (shm == (void *)-1) {
perror("\nproducer shmat()");
exit(EXIT_FAILURE);
}
ctln = (struct ctln_pc_st *)shm;
data = (struct data_pc_st *)shm;
程序使用for循环调用ctln->THREAD_CONS次pthread_create(&ptid[i], NULL, &consumer, shm)函数来实现构建指定个数的消费者线程。
其中线程调用函数producer的程序关键内容如下:
void *consumer(void *arg)
{
struct ctln_pc_st *ctln = (struct ctln_pc_st *)arg;
struct data_pc_st *data = (struct data_pc_st *)arg;
while ((ctln->consume_num < ctln->item_num) || (ctln->END_FLAG == 0)) {
sem_wait(&ctln->stock); /* if stock is empty and all producers stop working at this point, one or more consumers may wait forever */
sem_wait(&ctln->sem_mutex);
if (ctln->consume_num < ctln->item_num) {
ctln->dequeue = (ctln->dequeue + 1) % ctln->BUFFER_SIZE;
printf("\t\t\t\tconsumer tid %ld taken item no %d by pro %ld, now dequeue = %d\n", gettid(), (data + ctln->dequeue + BASE_ADDR)->item_no, (data + ctln->dequeue + BASE_ADDR)->pro_tid, ctln->dequeue);
ctln->consume_num++;
sem_post(&ctln->emptyslot);
}
else {
sem_post(&ctln->stock);
}
sem_post(&ctln->sem_mutex);
}
pthread_exit(0);
}
分析:函数在当前的消耗产品量小于生产的产品量的前提下,循环执行消费代码,只有在消耗产品量小于生产的产品量的条件下,才能够消费产品,在从数据队列取出产品,以及修改控制单元变量之前,先调用sem_wait(&ctln->stock)和sem_wait(&ctln->sem_mutex),等待数据空间的空位信号量和互斥信号量,如果信号量大于0函数将信号量-1,如果信号量等于0则挂起,等待前者的目的是保证数据队列有存储的产品资源可以供消费线程消费,等待后者是为了防止多个线程同时修改数据队列和控制单元。消费者线程从产品队列取出产品的位置往后移动,修改为(ctln->dequeue + 1) % ctln->BUFFER_SIZE,接着程序打印取出产品的消费者线程号,产品编号,生产该产品的生产者线程号,以及当前消费者从产品队列取出产品的位置。
生产产品的过程需要修改控制变量ctln中的成员变量消费的产品数量consume_num+1,结束产品取出和信息修改后,调用sem_post(&ctln->emptyslot);将该信号量+1,表示产品队列多了一个空位。
相反,当当前的消耗产品量大于等于生产的产品量时,线程不消费产品,直接交出产品资源stock,一轮消费结束后,线程调用函数sem_post(&ctln->sem_mutex)将互斥信号量+1,表示其他线程可以修改数据队列和控制单元。
回到生产者进程(主线程)本身:
程序使用for循环调用ctln->THREAD_CONS次pthread_join(ptid[i], NULL);函数阻塞等待所有的消费者线程执行完毕。
最后程序调用shmdt(shm)使得该共享空间脱离该进程的连接。
回到主函数:
程序调用waitpid(pro_pid, 0, 0) != pro_pid和waitpid(cons_pid, 0, 0) != cons_pid)函数分别阻塞等待调用的生产进程和消费进程结束。
程序分别调用函数sem_destroy(&ctln->sem_mutex),sem_destroy(&ctln->stock),sem_destroy(&ctln->emptyslot)销毁控制单元ctln的三个信号量变量。
程序快结束时,通过返回调用函数detachshm来删除回收共享空间。
1.8.3 执行结果分析
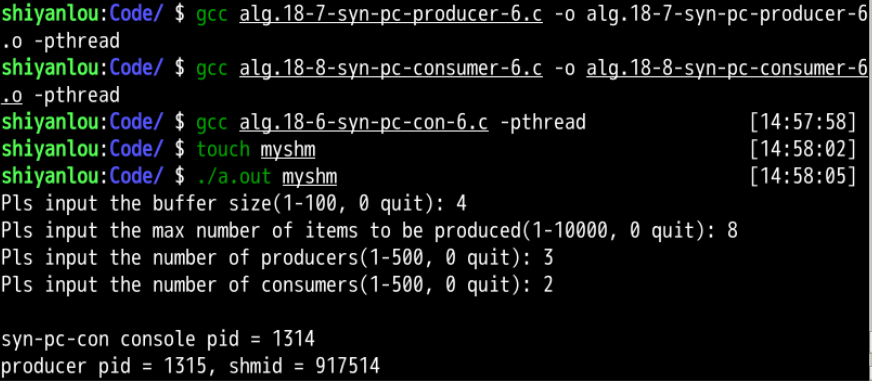

分析: 执行程序,输入缓冲区大小为4,可放置4件产品,输入最大生产者生成产品数量为8,生产者线程数为3,消费者线程数为2,程序输出主进程的pid=1314,生成者进程的pid=1315,消费者进程的pid=1316,主进程,生产者进程,消费者进程共用一块共享内存空间(缓冲区),执行结果显示对缓冲区的访问分别依次是
- 生成者线程(tid=1317)生产产品(编号为1)插入生产队列,其下一次可插入位置为1;
- 生成者线程(tid=1319)生产产品(编号为2)插入生产队列,其下一次可插入位置为2;
- 生成者线程(tid=1318)生产产品(编号为3)插入生产队列,其下一次可插入位置为3;
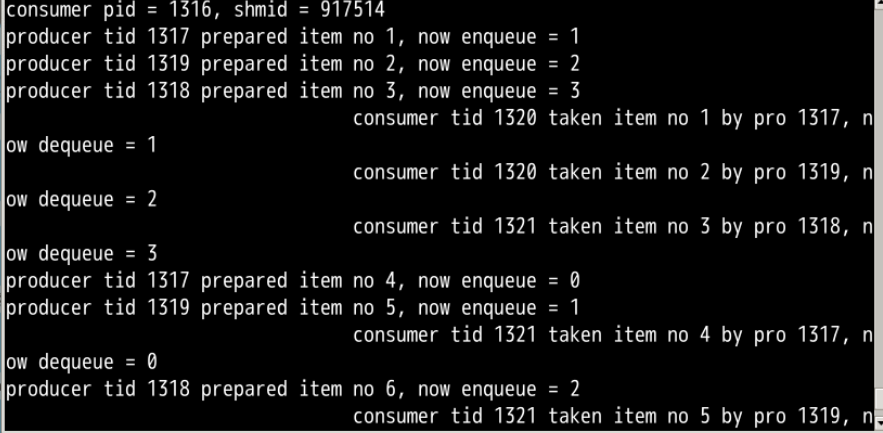
- 消费者线程(tid=1320)消费产品(编号为1,生产自线程标识符tis为1317),其生产队列的下一次可取出位置为1;
- 消费者线程(tid=1320)消费产品(编号为2,生产自线程标识符tis为1319),其生产队列的下一次可取出位置为2;
- 消费者线程(tid=1320)消费产品(编号为3,生产自线程标识符tis为1318),其生产队列的下一次可取出位置为3;
- 生成者线程(tid=1317)生产产品(编号为4)插入生产队列,其下一次可插入位置为0;
- 生成者线程(tid=1319)生产产品(编号为5)插入生产队列,其下一次可插入位置为1;
- 消费者线程(tid=1321)消费产品(编号为4,生产自线程标识符tis为1317),其生产队列的下一次可取出位置为0;
- 生成者线程(tid=1318)生产产品(编号为6)插入生产队列,其下一次可插入位置为2;
- 消费者线程(tid=1321)消费产品(编号为5,生产自线程标识符tis为1319),其生产队列的下一次可取出位置为1;
- 消费者线程(tid=1320)消费产品(编号为6,生产自线程标识符tis为1318),其生产队列的下一次可取出位置为2;
- 生成者线程(tid=1317)生产产品(编号为7)插入生产队列,其下一次可插入位置为3;
- 生成者线程(tid=1319)生产产品(编号为8)插入生产队列,其下一次可插入位置为0;
- 消费者线程(tid=1320)消费产品(编号为7,生产自线程标识符tis为1317),其生产队列的下一次可取出位置为3;
- 消费者线程(tid=1321)消费产品(编号为8,生产自线程标识符tis为1319),其生产队列的下一次可取出位置为0;
程序最后输出消费者进程,和生成者进程执行结束,资源回收。
通过结果观察可以看到生产者和消费者线程对产品队列的访问是同步互斥的。
1.9 alg.18-9-pthread-cond-wait.c
1.9.1 相关知识点
条件变量是可以使得线程间共享全局变量时候实现同步的一种机制,当一个线程条件成立时候,其他线程处于挂起状态,等待条件变量的条件成立。条件变量的使用常常和互斥锁相结合。
与之相关的函数以及功能如下:
| 函数 | 功能 |
|---|---|
| pthread_cond_init | 动态创建条件变量 |
| pthread_mutex_lock | 互斥锁上锁 |
| pthread_mutex_unlock | 互斥锁解锁 |
| pthread_cond_wait | 等待条件变量,挂起线程(挂起过程会解除互斥锁,继续后上锁) |
| pthread_cond_timedwait | 等待条件变量,挂起线程,有时间限制,到了时间上限,自动解除阻塞 |
| pthread_cond_signal | 激活等待列表中的线程 |
| pthread_cond_broadcast | 激活所有等待线程列表中最先入队的线程 |
| pthread_mutex_destroy | 销毁互斥锁 |
| pthread_cond_destroy | 销毁一个条件变量 |
以上函数都是原子操作。
使用函数pthread_cond_wait的原因是因为需要把“把调用线程放到条件等待队列上”以及“释放mutex”两个操作作为一个原子操作同时进行,否则如果先释放mutex,这时候生产者线程向队列中添加数据,然后signal,之后消费者线程才去『把调用线程放到等待队列上』,signal信号就这样被丢失了。如果先把调用线程放到条件等待队列上,这时候另外一个线程发送了pthread_cond_signal(我们知道这个函数的调用是不需要mutex的),然后调用线程立即获取mutex,两次获取mutex会产生deadlock.
1.9.2 程序原理以及细节解释
-
程序目的:
测试条件变量是否能够实现线程之间对同一公共资源(比如全局变量)改变的同步互斥。 -
程序逻辑及细节:
函数在全局使用语句pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;来静态创建和初始化互斥锁,使用语句pthread_cond_t cond = PTHREAD_COND_INITIALIZER;来静态创建和初始化条件变量,并且定义了静态全局变量count用来测试条件变量是否实现其功能。主程序调用
pthread_create(&ptid_de, NULL, &decrement, NULL);和pthread_create(&ptid_in, NULL, &increment, NULL);函数来创建2个线程,一个线程执行线程函数decrement,另一个线程执行线程函数increment,线程函数
decrement的内容如下:void *decrement(void *arg) { for (int i = 0; i < 4; i++) { pthread_mutex_lock(&mutex); while (count <= 0) /* wait until count > 0 */ pthread_cond_wait(&cond, &mutex); count--; printf("\t\t\t\tcount = %d.\n", count); printf("\t\t\t\tUnlock decrement.\n"); pthread_mutex_unlock(&mutex); } return NULL; }线程函数使用
for循环执行了4次count--指令,并且在每次执行该指令count--,执行前调用pthread_mutex_lock(&mutex);来对互斥锁上锁,循环等待count>0(即在count可减的阶段),线程函数调用pthread_cond_wait(&cond, &mutex)等待条件变量并同时解除对互斥锁的上锁, 等待到可访问变量的限权后,程序执行了``count–`, 并打印count的值以及需要的解释信息,线程函数
increment的内容和线程函数decrement大致相同,只是把语句count--改成count++回到主函数,程序调用
pthread_join阻塞等待所有线程执行完毕,调用函数pthread_mutex_destroy(&mutex)销毁互斥锁mutex,调用函数pthread_cond_destroy(&cond)销毁条件变量cond。
1.9.3 执行结果分析

分析: 多个线程异步执行,逐个接管CPU,修改静态全局变量count的值,结果并没有发生冲突,很好的验证了条件变量的功能。
2 用信号量解决线程池分配的互斥问题。
2.1 解决互斥问题的设计思路:
用线程信号量queue_sem来控制多个线程的任务分配问题,该信号量表示任务队列中的任务资源。每个线程在开始线程函数的一开始,都会循环中循环等待一个任务资源信号量,等到信号量大于0(即有任务资源的时候)则互斥地从任务队列中摘取一个任务结点开始执行。在摘取完执行完之后进入下一轮循环。
线程工作函数以及任务加入任务队列的函数使用互斥锁来保证对公共访问资源任务队列的互斥访问。
2.2 代码修改添加的地方
相比较与原来的函数:
-
在全局中执行语句
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER定义并初始化了互斥锁,并且定义了静态全局变量count用来测试条件变量是否实现其功能。 -
在线程池结构体中加入成员变量——线程信号量
queue_sem。 -
在调用初始化函数
pool_init,调用函数sem_init(pool->queue_sem, 0, 0);来初始化信号量。 -
在
pool_add_worker函数中,在构造新任务后,准备将任务插入到任务队列之前,调用函数pthread_mutex_lock(&mutex)将互斥锁上锁,防止其他线程进入临界区同时修改任务队列,在将任务插入到任务队列后,调用函数sem_post(pool->queue_sem)将任务资源信号量+1,并调用函数pthread_mutex_unlock(&mutex)解开互斥锁,具体代码如下:pthread_mutex_lock(&mutex); /*将任务加入到任务队列中,也就是链表末端*/ CThread_worker* worker = pool->queue_head; if (worker != NULL) { while (worker->next != NULL) worker = worker->next; worker->next = newworker; } else { pool->queue_head = newworker; } pool->cur_queue_size += 1; /*计数+1*/ sem_post(pool->queue_sem); pthread_mutex_unlock(&mutex); -
在调用函数
pool_destroy中,在关闭线程池开关(即设置pool的成员变量shutdown为1)后,只用以下代码唤醒所有的线程并且销毁信息量queue_sem。/*唤醒所有等待线程*/ int i; /*因为创建线程比作业多,未执行任务,一直循环等待信号量的线程将会成为僵尸,所以通过给出足够的信号,来唤醒所有线程从而避免这种情况的发生*/ for(i = 0; i < pool->max_thread_num; i++) { sem_post(pool->queue_sem); } sleep(1); sem_destroy(pool->queue_sem); -
在线程工作函数
thread_routine中,在函数的开始函数执行一下代码块来等待任务资源信号量queue_semif(sem_wait(pool->queue_sem)) { perror("thread waiting for semaphore"); exit(EXIT_FAILURE); }线程从任务队列中取出可执行的任务前,需要先调用
pthread_mutex_lock(&mutex)函数将互斥锁上锁,防止其他线程进入临界区同时修改任务队列,在将任务从任务队列取出后,调用pthread_mutex_unlock(&mutex)解开互斥锁,并执行线程函数。 -
主函数执行结束的最后执行语句
printf("The total number of tasks executed by the thread pool is %d\n",tesk_count);来打印线程完成的任务数,若线程完成的任务数等于用户指派的任务数,那么就可以说明程序在一定程度上用信号量解决线程池分配的互斥问题。
2.3 执行样例分析:
-
样例一:
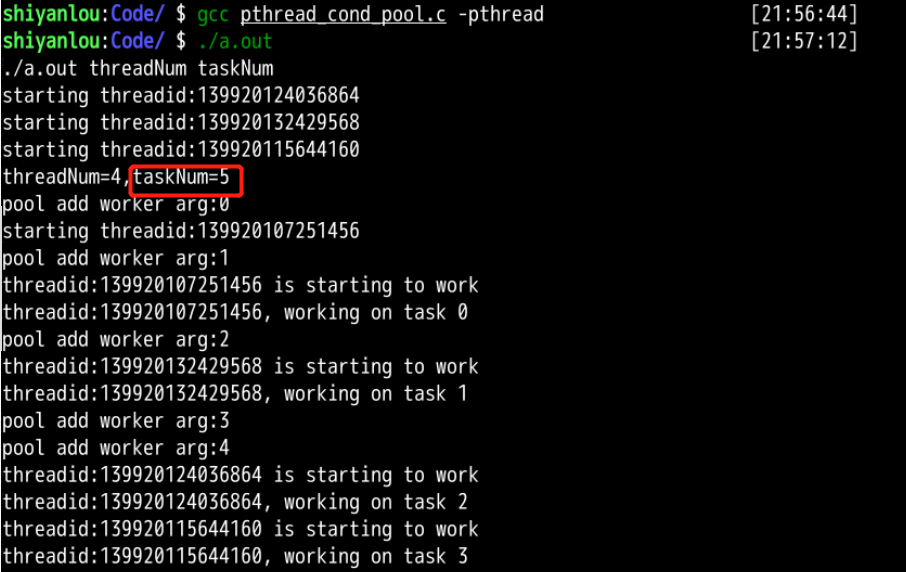
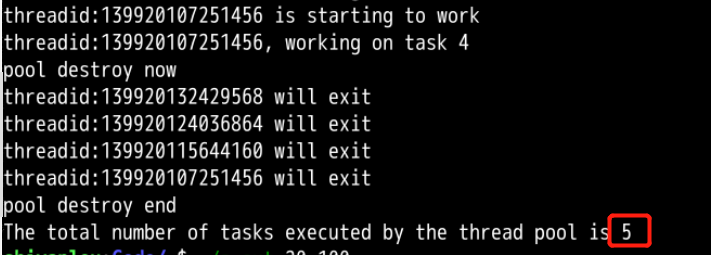
分析: 可以观察到命令行没有第三个参数时,程序默认任务数量为5,线程完成的任务数也等于5,线程池很好的有序的完成了分配给线程池的所有任务,可以说明程序在一定程度上用信号量解决线程池分配的互斥问题。
-
样例二:
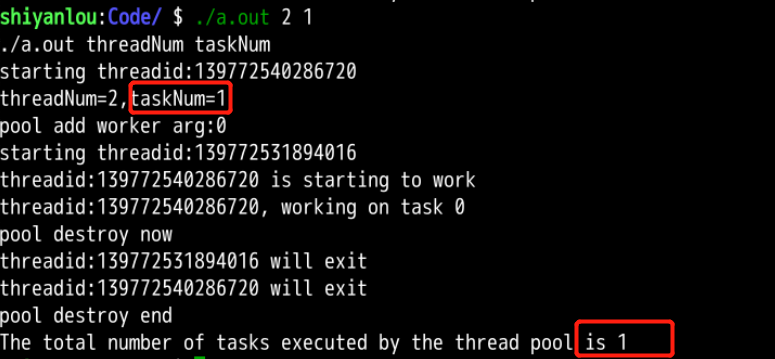
分析: 可以观察到命令行的第三个参数为1,即用户需要线程池执行的任务数为1,线程分配一个线程去完成该任务,其间没有出现任务资源竞争的情况,可以知道程序在一定程度上用信号量解决线程池分配的互斥问题。
-
样例三:

。。。。
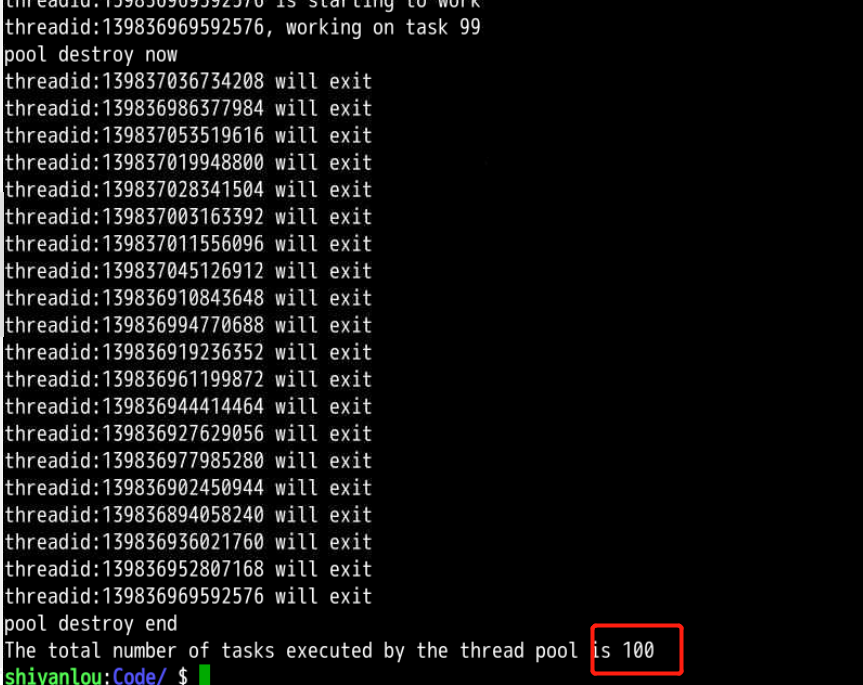
分析: 可以观察到命令行的第三个参数为100,即用户需要线程池执行的任务数为100,线程分配线程去互斥地完成该任务,其间没有出现任务资源竞争的情况,线程最终完成的任务数也等于100,线程池很好的有序的完成了分配给线程池的所有任务,可以说明程序在一定程度上用信号量解决线程池分配的互斥问题。















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









