







涉及的numpy Api
学了一个学期数据分析与可视化,numpy还不会用,惭愧惭愧
np.loadtxt(参数说明太多了截图不下,介绍常用的)
参数fname ------> 文件路径
参数delimiter --------> 分割符号

numpy.reshape、numpyarray.reshape
作用:保持原始数据,改变数组的长度
(static)参数a就是原数组,如果使用Numpyarray成员函数的reshape是没有这个方法的
参数:newshape ------->可以是整数型和整数型的元组
当输入整数的时候,结果是1维数组
当输入元组的时候,如果某一维参数为-1,那么数组这一维的实际值是根据数据和剩余的维度进行自动推断的
参数order:叽叽歪歪说了一堆没看懂啥意思,可能和运算时的速度、运算数组的风格有关?反正可选的,不用也罢

numpy.average
作用是计算平均值
参数a ----> 需要操作的数组
参数axis -----> 运算的方向
可以是整数: 0表示纵向,1表示横向(in 2-D array)
可以是整数元组,整数元组的情形下,会求给定轴向所有值的平均值
参数weight -----> 权重,可选参数,按照某一个轴方向时,某一个记录所占的比例,必须配合axis使用
参数return ------> 是否返回权重和

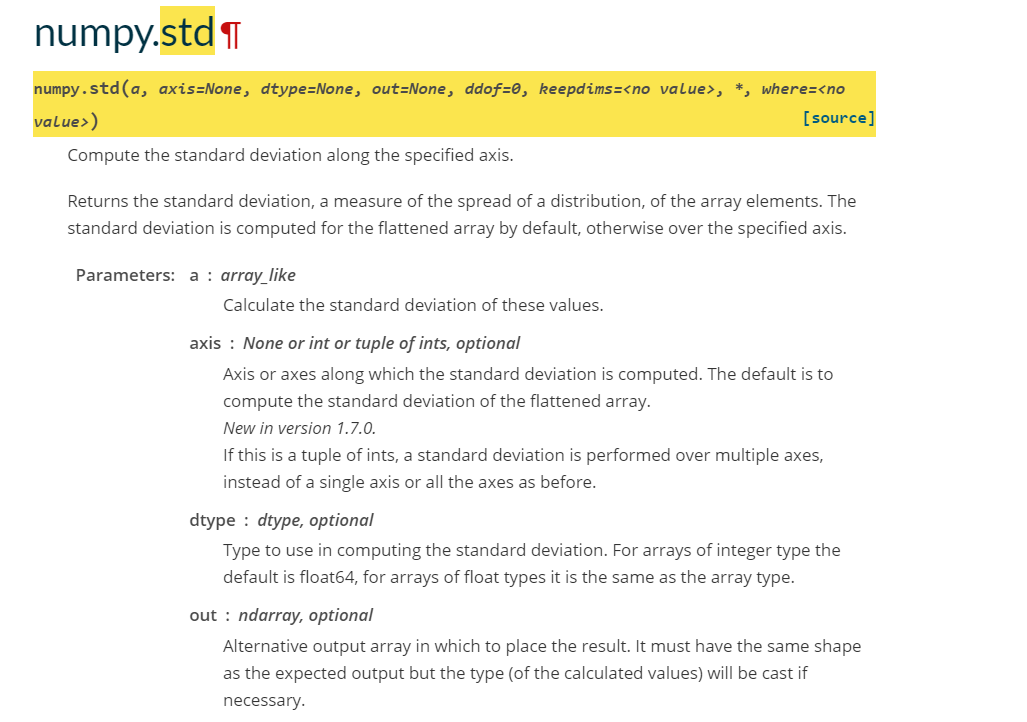
numpy.std
作用:计算标准差
参数a -----> 进行计算的数组
参数axis ------> 可选 计算的轴向,可以是整数或者整数型元组,具体作用和上一个函数说明相同
参数dtype ------> 可选 返回值的类型,默认为float64
参数out --------> 可选 放置结果的数组
参数 ddof ------> Delta Degrees of Freedom 和自由度相关的参数,自由度=N-ddof,由此算出ddof参数值,也就是不自由度(我起的名字)
参数where --------> 运算作用的数

np.zeros
作用:根据条件构建一个0矩阵
参数shape -----> 构建的0矩阵的形状
参数dtype -------> 类型

numpy.random.random
返回指定长度的随机小数值数组
参数size ------> 长度

numpy.insert
根据所给的轴向插入值
参数arr ------> 操作的源数组
参数obj --------> 整数,切片 整数序列,插入的位置
参数axis ------> 插入的轴向

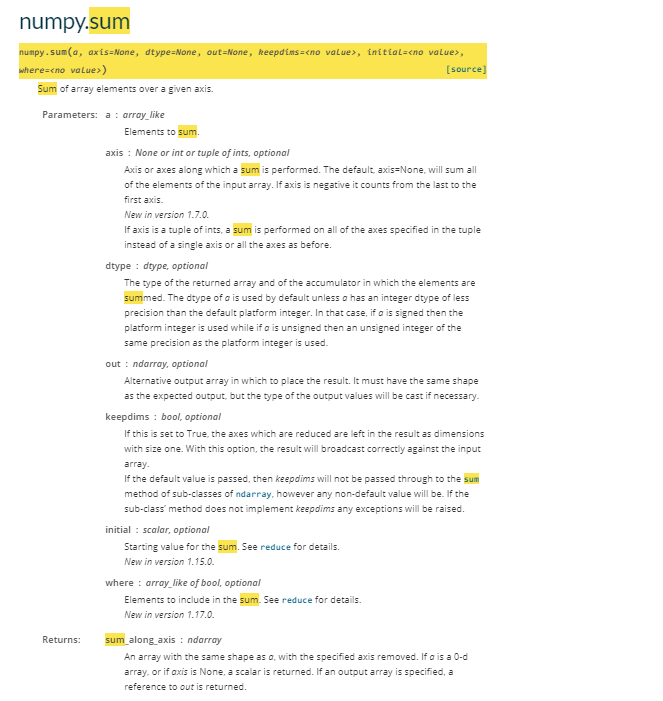
numpy.sum
参数a ------> 原数组
参数axis ------> 运算的轴向
参数dtype --------> 结果返回值
参数initial ---------> sum的起始值
参数where ---------> 沿着axis方向的索引
numpy.dot和*乘
用法都比较简单,这里做一下区分
dot运算:遵循矩阵的点乘运算
*运算: 两个矩阵对应位置相乘得到结果矩阵对应部分

代码部分(多特征、矩阵)
构建整个代码的过程:
- 读取数据
- 正则化数据(加快收敛速度)
- 计算cost函数
- 梯度下降
读取数据:
def load_data():
data = np.loadtxt(r"C:/Users/yeyeyeping/Desktop/data1.txt", delimiter=",")
#第一行到倒数第二行为特征数据
#改变形状成
x = data[:,:-1]
#最后一行为标签数据
y = data[:,-1]
return x,y
正则化数据:
def featureNormalize(x):
#按列的方向求每一列的自由度为N-1的标准差
std = np.std(x,axis=0,ddof=1)
#按列的方向求每一个特征的平均值
avg = np.average(x,axis=0)
#对每一个特征标准化
return (x-avg)/std,avg,std
计算损失的函数(字丑人懒将就看)
线性模型:
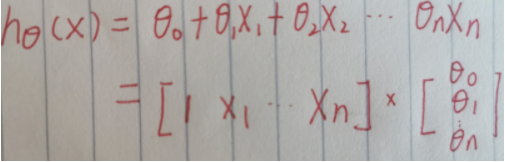
计算损失的公式:
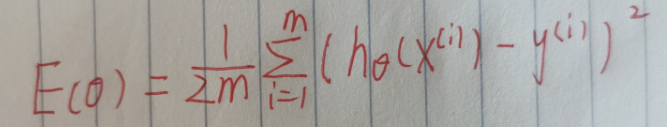
X1、X2·······Xn为n个特征,当然在实际运算的过程中,每一个特征在后面就是许多的样本的实际值,因此,也可以看做成列向量,这样举例:

这样想就可以用numpy简化运算:
#效率嘎嘎高
def computeCost(x,y,theta):
#这里x已经插入过了第一列
m = len(x)
return np.sum((np.dot(x,theta)-y)**2)/2/m
梯度下降算法
公式:

def gradientDescent(x,y,iterations,lr):
m = len(x)
#在x第一列插入1
x = np.insert(x,0,np.ones(m),axis=1)
#记录每一次迭代的损失值
costs = np.ones(iterations)
#初始化theta,注意因为后面的矩阵运算这里不要忘记reshape
theta = np.zeros(x.shape[1]).reshape((-1,1))
for i in range(iterations):
for j in range(len(theta)):
theta[j] = theta[j] +(lr/m)*(np.sum(y-np.dot(x,theta)*x[:,j].reshape((-1,1)))
cost[i] = computeCost(x,y,theta)
return theta,cost
X_orgin,y = load_data()
X,avg,std = featureNormalize(X_orgin)
iterations = 400
lr = 0.01
theta,costs = gradientDescent(X,y,iterations,lr)
画俩图
#绘制损失函数图变换趋势图
plt.plot(x_axis,costs)
plt.show()
#绘制散点图
plt.scatter(X_orgin,y)
h_theta = theta[0]+theta[1]*X_orgin
plt.plot(X_orgin,h_theta, c='black')
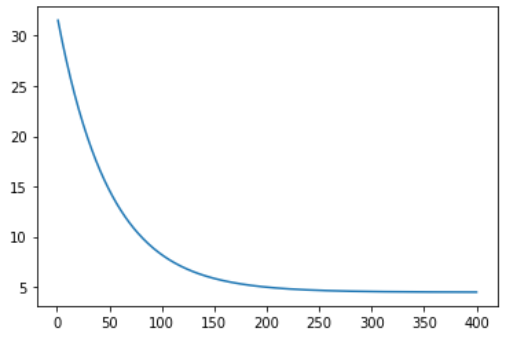
损失函数的变化图

预测一哈:
def predict(X):
X = (X-avg)/std
c = np.ones(X.shape[0]).transpose()
X = np.insert(X, 0, values=c, axis=1)
return np.dot(X,theta)
print(predict([[6.1891]]))















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









