










public void getStudentName() throws IOException {
Properties properties = new Properties();
properties.put("driver", ApplicationYmlUtils.getDataSourceDriverClassName());
properties.put("user", ApplicationYmlUtils.getDataSourceUsername());
properties.put("password", ApplicationYmlUtils.getDataSourcePassword());
Dataset<Row> loadData = sqlContext.read().jdbc(ApplicationYmlUtils.getDataSourceUrl(), "t_student", properties);
/*
DataFrameReader reader = sqlContext.read().format("jdbc")
.option("url", ApplicationYmlUtils.getDataSourceUrl())
.option("dbtable", sql)
.option("driver", ApplicationYmlUtils.getDataSourceDriverClassName())
.option("user", ApplicationYmlUtils.getDataSourceUsername())
.option("password", ApplicationYmlUtils.getDataSourcePassword());
Dataset<Row> loadData = reader.load();
*/
System.out.println(loadData.count());
loadData.write().mode(SaveMode.Overwrite).json("E:/11.json");如果是百万级甚至千万级乙级数据呢,这里以120W数据为例,数据库确实存在120W数据,输出成JSON文件为例
一次性读取
有OOM风险
public void getStudentName() throws IOException {
long startTime = System.currentTimeMillis();
Properties properties = new Properties();
properties.put("driver", ApplicationYmlUtils.getDataSourceDriverClassName());
properties.put("user", ApplicationYmlUtils.getDataSourceUsername());
properties.put("password", ApplicationYmlUtils.getDataSourcePassword());
Dataset<Row> loadData = sqlContext.read().jdbc(ApplicationYmlUtils.getDataSourceUrl(), "sys_operation_log", properties);
System.out.println(loadData.count());
loadData.write().mode(SaveMode.Overwrite).json("E:/11.json");
long endTime = System.currentTimeMillis();
System.err.println("120W数据大概用时"+(endTime-startTime));
}
生成的JSON文件是只有一个JSON文件
分批次/分区
无OOM风险,但总时长比较长
public void getStudentName() throws IOException {
long startTime = System.currentTimeMillis();
Properties properties = new Properties();
properties.put("driver", ApplicationYmlUtils.getDataSourceDriverClassName());
properties.put("user", ApplicationYmlUtils.getDataSourceUsername());
properties.put("password", ApplicationYmlUtils.getDataSourcePassword());
String[] predicates=new String[120];
Integer num=120;
Integer index=0;
for (int i = 0; i <num ; i++) {
predicates[i]=" 1=1 LIMIT "+index+","+10000;
index+=10000;
}
Dataset<Row> loadData = sqlContext.read().jdbc(ApplicationYmlUtils.getDataSourceUrl(), "sys_operation_log",predicates ,properties);
System.out.println(loadData.count());
loadData.write().mode(SaveMode.Overwrite).json("E:/11.json");
long endTime = System.currentTimeMillis();
System.err.println("120W数据大概用时"+(endTime-startTime));
}下面是任务部分日志截图



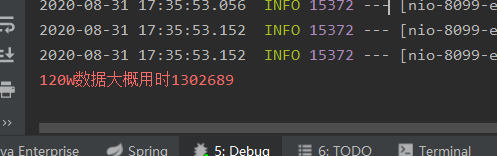
足足用了二十多分钟
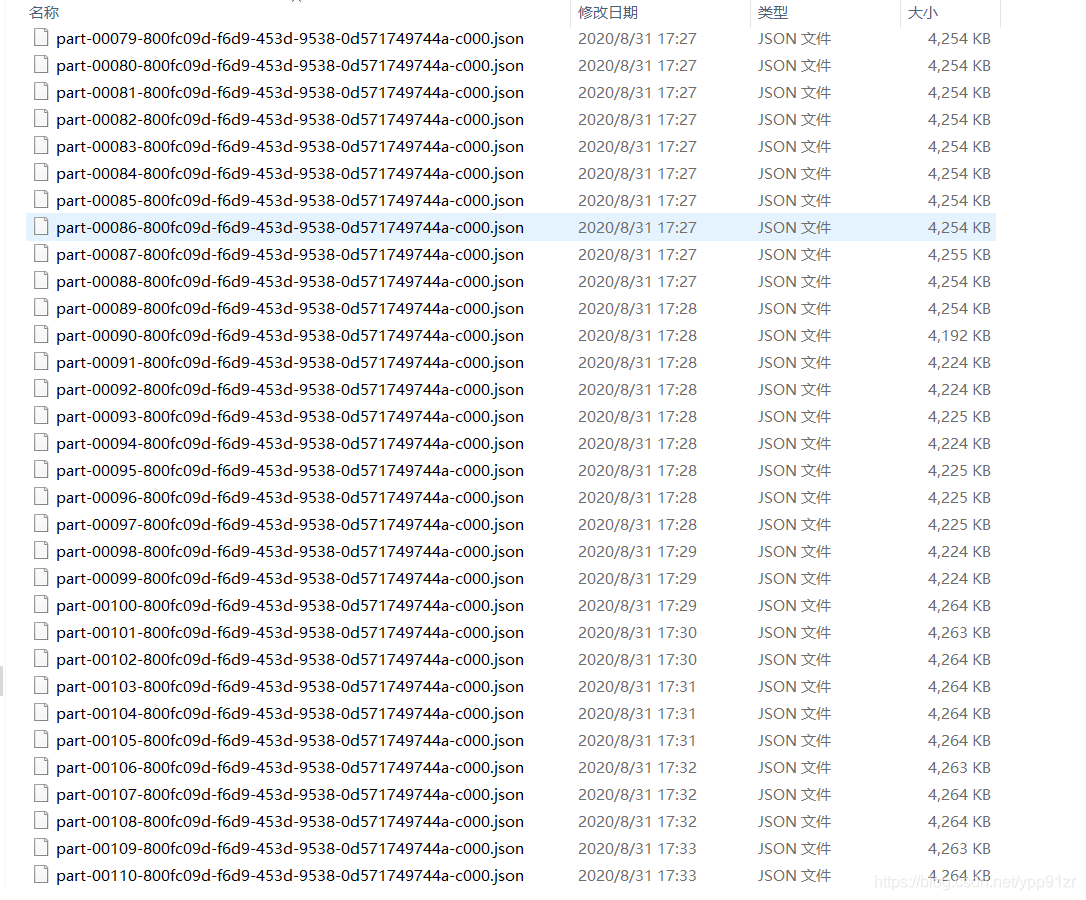
JSON文件也是按任务分散的,并不是一个文件
数据量大还不如传统的mysql查询,毕竟是先查询数据放入内存再做相应的操作,可以用sqoop将mysql数据放进HDFS等再使用Spark来进行计算
所以海量数据Spark还是比较适用HDFS/Hive/Hbase这些来做数据源














 4617
4617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









