






题目分类
- HTML
- CSS
- JS
- 数据库
- 算法
- 操作系统
- 计算机网络
- 数据结构
- 浏览器
HTML
input的type属性如下:
- button
- checkbox
- file
- hidden
- image
- password
- radio
- reset
- submit
- text
CSS
-
下列哪项可以实现背景在div中的平铺:( )
div{ background-image: url(1.gif); }

图片1.gif向左偏移25px,向下偏移25px;
- 下面哪个标记段将使得在Internet Explorer中时逆时针旋转一些文字(C)
A、 d transform:rotate(30deg)
B、 -o-transform:rotate(-30deg)
C、 -ms-transform:rotate(-30deg)
D、 -ms-transform:rotate(30deg) - 下列关于 CSS 边框 (border) 和阴影 (box-shadow) 的解释,正确的都有哪些?
A/C/D
A.两种方式都可以实现给元素加外边框的效果
B.在盒模型中, border 和 box-shadow 都会占用空间
C. border 支持图片格式,box-shadow 不支持
D.box-shadow 支持内阴影和模糊,因此可以实现毛玻璃效果
JS
-
在开发一个注册页面时,注册内容需要用到表单来实现,那么,如果想要给所有可见的表单设置默认值,该怎么实现(D )
A、 $(“input:enabled”).text(str);
B、 (“input:enabled”).text(str);
C、 (“input:enabled”).val(str);
D、 $(“input:enabled”).val(str); -
有一个数组var arr=[a,b,c,d], 数组 arr 中每项都是一个整数,下面得到其中最大整数语句正确的是哪几项? ABD
A、 Math.max.apply(Math,arr)
B、 Math.max(arr[0], arr[1], arr[2], arr[3])
C、 Math.max(arr)
D、 Math.max.call(Math, arr[0], arr[1], arr[2], arr[3]) -
const first = () => { console.log('first'); return false; } const second = () => { console.log('second'); return true; } console.log( first() && second() ); console.log( second() || first() );执行以上代码后打印的结果为()
first, false, second, true条件语句中 && 为 false 判断为false后面的语句不会执行 ,为true会执行后面的语句 | | 为 true 判断为true
后面的语句不会执行,为false 会执行后面的语句
== &&优先级高于|| == -
const Book = { price: 32 } const book = Object.create(Book); book.type = 'Math'; delete book.price; delete book.type; console.log(book.price); console.log(book.type);执行以上代码后,输出的结果是()
32, undefineddelete操作符可以删除隐式的全局变量、对象的自定义属性,而不能删除显示声明的全局变量,对象的内置和继承属性,而且在严格模式下,删除不能删除的变量或属性时,直接抛出异常.
function side(arr) {
arr[0] = arr[2];
}
function func1(a, b, c = 3) {
c = 10;
side(arguments);
console.log(a + b + c);
}
function func2(a, b, c) {
c = 10;
side(arguments);
console.log(a + b + c);
}
func1(1, 1, 1);
func2(1, 1, 1);
输出 12 21
解释:
一般情况下,也就是非严格模式下,函数的arguments数组里面的内容是会随着函数内赋值而变化的,而改变arguments也会改变abc的值。而为函数形参赋予初始值这个行为会强制该函数内启用严格模式,因此arguments中的c是不会随着c被赋值而改变的。故func1中,调用side会让a被赋值1,而func2中会赋值10.
-
下列说法正确的是(BC)

for...in循环是遍历对象上的每一个可枚举属性,包括原型链上面可枚举属性
object.keys()只是遍历自身可枚举属性,不可以遍历原型链上的可枚举属性
object.assign()对象的拷贝,用户将所有可枚举属性的值从一个或多个源对象复制到目标对象,将它返回到目标对象 -
下列结果返回 true 的是(AC)
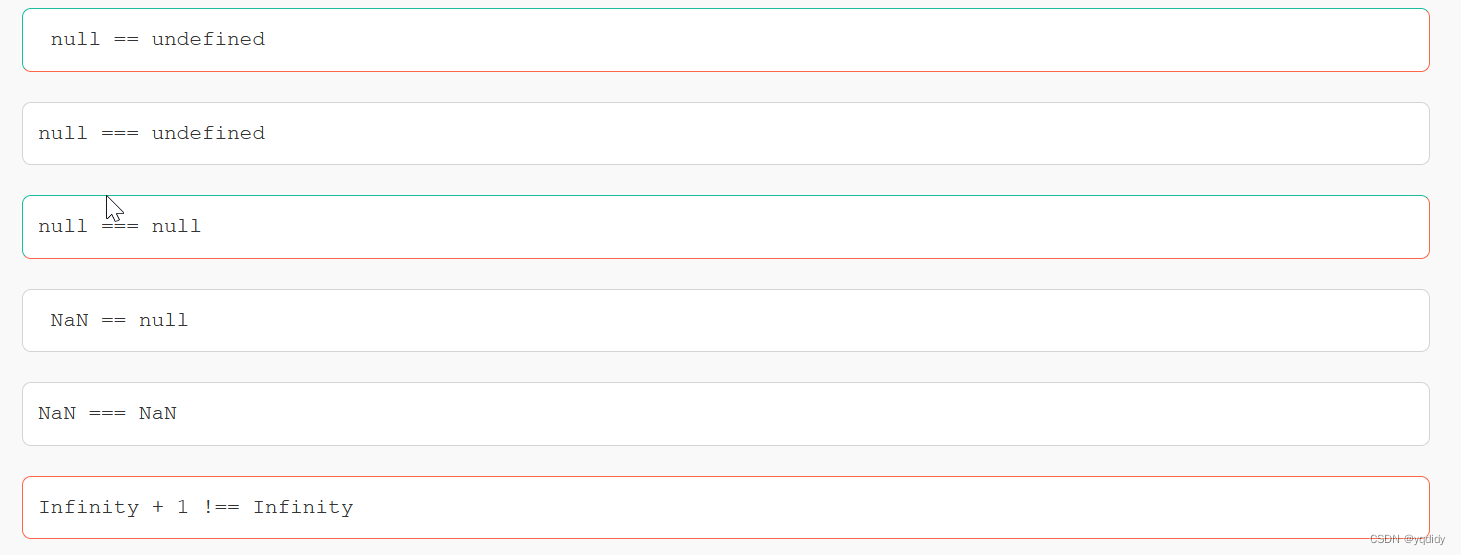
NAN与任何不相等
null===nulltrue
null==undefinedtrue
null===undefinedfalseInfinity + 1 !== Infinity false
Infinity运算法则正数除以 0 得 Infinity。
Infinity 加或减任何有限数字都得 Infinity 。Infinity + Infinity 或 Infinity - -Infinity 也得 Infinity 。
Infinity 乘或除以任何有限正数得 Infinity。
Infinity 乘或除以任何有限负数得 -Infinity 。 Infinity * Infinity 或 Infinity / 0 也得 Infinity 。Infinity * -Infinity 得 -Infinity。
Infinity - Infinity 得 NaN 。 Infinity / Infinity 得 NaN 。 Infinity * 0 得 NaN 。
Infinity == Infinity 为真。 Infinity.isNaN() 为假。 Infinity.isFinite() 为假。
Boolean(Infinity) 为真。


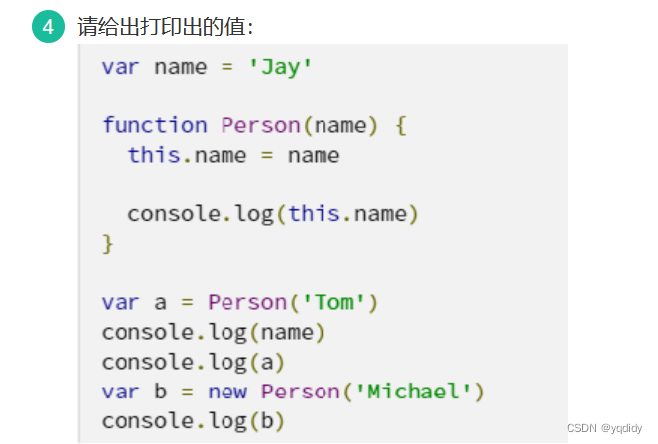
打印如下:
Tom
Tom
undefined
Michale
Person {name: ‘Michale’}

__proto__指向构造函数constructor
a.__proto__ === A.prototype
b.__proto__ === B.prototype
B.__proto__ === A
B.prototype.__proto__ === A.prototype
b.__proto__.__proto__ === A.prototype b.__proto__.__proto__.__proto__===Object.prototype Object.prototype.__proto__=null
总结:
1、__proto__是对象的具有的属性,而prototype只有函数对象才有。
2、由__proto__组成的复杂关系叫原型链,作用就是放在原型的东西可以直接取到。
3、原型链不会无限循环 它最终指向的是null
4、函数对象Function.prototype,的proto指向的不是自己是Object.prototype,它最终指向的也是null
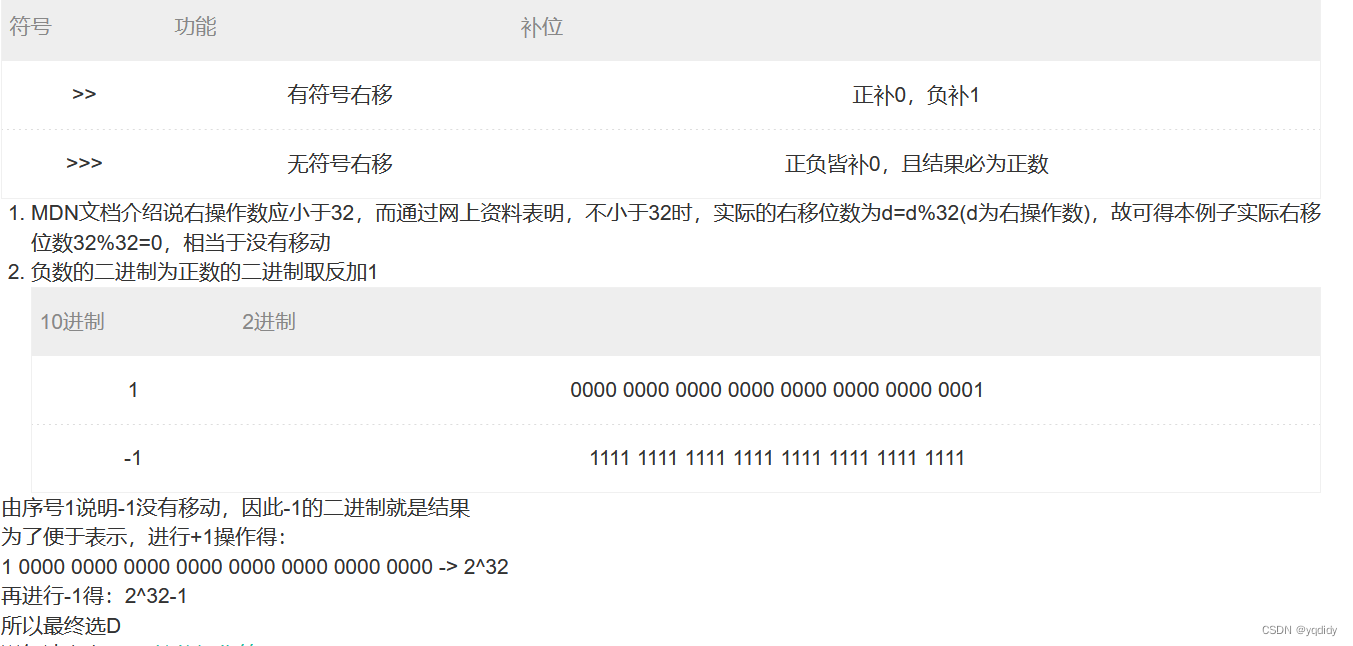
- ‘-1 >>> 32 的值为( 2^32-1 )’
- [‘1’, ‘2’, ‘3’].map(parseInt) ( ) [1, NaN, NaN]
涉及map和praseInt的应用
map((item, index, thisArr) => ( newArr ))
parseInt(string, radix)
【参数解析】
string: 必需。要被解析的字符串。
radix: 可选。表示要解析的字符串的表示的进制数。该值介于 2 ~ 36 之间。如果省略该参数或其值为 0,则数字将以 10 为基础来解析。如果它以 “0x” 或 “0X” 开头,将以 16 为基数。如果该参数小于 2 或者大于 36,则 parseInt() 将返回 NaN。
【返回】
解析后的数字
parseInt("10"); // 10
parseInt("19",10); // 19 (10+9)
parseInt("11",2); // 3 (2+1)
parseInt("17",8); // 15 (8+7)
parseInt("1f",16); // 31 (16+15)
parseInt("010"); // 10 或 8
本题中[‘1’, ‘2’, ‘3’].map(parseInt) ( ):
map给parseInt传递了三个参数:
parseInt(item, index, thisArr)
parseInt('1', 0)
// radix 为 0,默认以十进制解析字符串,返回 1
parseInt('2', 1)
// radix 为 1,不在 2 ~ 36 之间,返回 NaN
parseInt('3', 2)
// radix 为 2, 字符串却为 3,超出二进制的表示范围,因此要解析的字符串和基数矛盾,返回 NaN
综上,最后返回的数组为 [1, NaN, NaN]
算法
01 背包、矩阵连乘、贪心、动规、分治
- 在一台内存只有4KB的ATM机上,如果打算按照存款金额由大到小对2,000,000笔存款交易进行排序,那么最合适的排序方法是_____B________.
A、 堆排序
B、 归并排序
C、 插入排序
D、 桶排序
操作系统
-
在分页系统中,采用基本地址变换机构方式,CPU每存取一次数据,需要进行( )次访存。
A、 3
B、 0
C、 2
D、 1这一题 答案给的是D 一次,我认为不正确,应该是2次
两种地址变换机构对比:
注:在段页式分配中,取一次数据时先从内存查找段表,再查找相应的页表,最后拼成物理地址后访问内存,共需要3次内存访问。 -
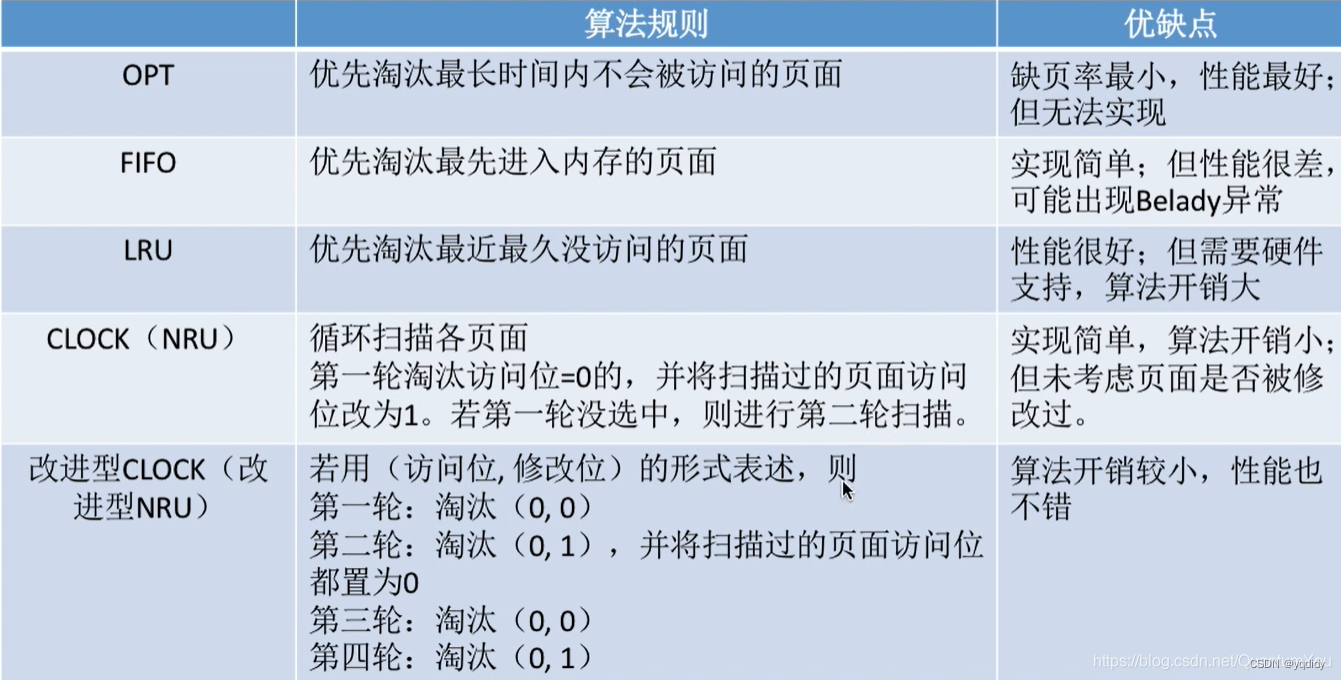
在请求分页管理中,采用FIFO(先进先出)页面置换算法,可能产生( D )
A、 内碎片
B、 抖动现象
C、 外碎片
D、 Belady现象各个页面置换算法:最佳置换算法(OPT, Optimal)、先进先出置换算法(FIFO)、最近最久未使用置换算法(LRU, least recently used)、时钟置换算法
-
下面哪项叙述是分布式事务2PC模式的特点( B )
A、 适用于高并发场景
B、 以牺牲可用性为代价来保证数据的一致性
C、 将事务处理的同步阻塞操作变为异步操作
D、 将分布式事务拆分成本地事务后再进行处理## 计算机网络 -
下列哪种方式( )可以将程序分配到不连续的存储区中.
动态运行时装入 -
进程从运行状态进入就绪状态的原因可能是 时间片用完。
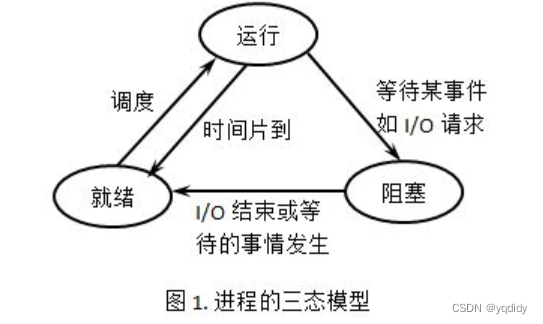
-
在可变式分区分配方案中,将空白区在空白区表中按地址递增次序排列是(最先适应)
最佳适应:空闲区按容量大小递增
最差适应:空闲区按容量大小递减
最先适应:空闲区按地址大小递增 -
在计算机操作系统中信号量可以用来保证两个或多个关键代码段不被并发调用,而在进入一个关键代码段之前,线程必须获取到一个信号量,现假设有4个进程共享同一程序段,而且每次最多允许3个进程进入该程序段,则信号量的变化范围是( -1~3)
允许3个进程同时进入程序段,因此信号量S设为3.这里的信号量P操作应该是等待时,将其挂到信号量等待队列中,因此可以为负数。先对信号量执行减1操作,如果为负数,将进程添加到信号量等待队列,并挂起进程。
本题中,当3个线程进入程序段后,S=0;第4个进程再想进入时,S=-1,因此取值范围是[3,-1](整数)。
计算机网络
- 某应用软件传输层协议指定为TCP时,则对应socket应指定为( D )类型
A、 SOCK_DGRAM
B、 SOCK_RAW
C、 SOCK_PACKET
D、 SOCK_STREAM
什么是Socket TCP?
Socket 详细解读
-
主机A与主机B已建立TCP连接,A的cwnd(拥塞窗口)大小初始值为1KB,ssthresh (阈值)为16KB,B的rwnd (接收缓存窗口)初始值为8KB,一个最大报文段为1KB,假设数据传输过程中未出现超时,经过3个RTT(3轮传输)后,且B尚未从缓存中取出任何数据时候,主机A的发送窗口大小为(1kb)
A在发送数据的过程中,A的cwnd大小始终没有达到阈值(16KB),所以A每经过一轮传输,cwnd就翻倍,所以A一共发送了1KB+2KB+4KB=7KB的数据,但是题目中说明了B并未从接收缓存中取出数据,所以B的接收缓存为8KB-7KB=1KB。A的发送窗口同时受cwnd和rwnd限制,即A=min{cwnd,rwnd},所以A的发送窗口为1KB
-
以下主机可以和202.115.112.218/28直接通信的是( 202.115.112.212/28 )。
——子网掩码的读法——
把子网掩码转换成二进制,看到有多少个1斜杠/后面就填写多少数字 例如:192.168.1.0
255.255.255.0转换成二进制后为11111111.11111111.11111111.00000000里面共有24个1则可以写成192.1681.0/24
——回到本题——
前面三个字段每个8个字节,一共24个字节都一样,不用看,只需要关注最后一个字段的八个字节,也就是218 218也即1101 1010 而 28 - 24 = 4,只需要看1101 1010的前四个字节,也就是1101****
因为
1101 0000(208)<1101****<1110 0000(224),
所以只能选D。 -
网络协议之间有规定的层次关系,下面选项中层次关系正确的是,上一层的网络的底层应该有下一层( )
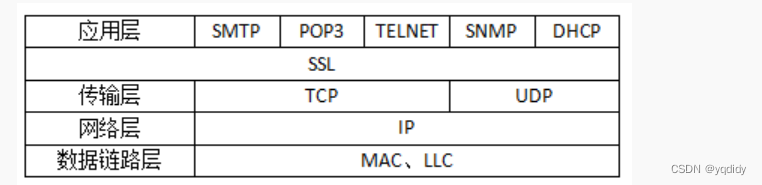
数据结构
完全二叉树
完全二叉树的叶节点只能出现在后两层
- 一棵完全二叉树,第5层有2个叶节点,则该二叉树最多有多少结点(59)。
哈夫曼树
- 给定n个权值作为n个叶子节点,构造一棵二叉树,若该树的带权路径长度达到最小,这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree),哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近,若一个哈夫曼树有N个叶子节点,则其节点总数为( 2N-1 )
哈夫曼树所有的分支节点均为双分支节点,根据二叉树的性质,双分支节点等于叶子节点的个数减1,因此总节点数为n+n-1=2n-1。
二叉排序树
- 后序遍历为二叉树遍历方式中的一种,假设将{ 3, 8, 9, 1, 2, 6 }依次插入初始为空的二叉排序树。则该树的后序遍历结果是多少( )?
答: 2, 1, 6, 9, 8, 3
二叉排序树要么是空二叉树,要么具有如下特点:
- 二叉排序树中,如果其根结点有左子树,那么左子树上所有结点的值都小于根结点的值;
- 二叉排序树中,如果其根结点有右子树,那么右子树上所有结点的值都大小根结点的值;
- 二叉排序树的左右子树也要求都是二叉排序树;
所以一次插入二叉排序树:
3
1 8
2 6 9
大根堆 小根堆
- 请问以下序列中能构成最小堆的是

如果每个节点的值都大于等于左右孩子节点的值,这样的堆叫 大顶堆;
如果每个节点的值都小于等于左右孩子节点的值,这样的堆叫 小顶堆。
线性探查解决hash冲突
线性探查解决hash冲突是从冲突位置向后找到不冲突的位置然后,将值放到这个位置
数据库
-
数据库系统设计时在哪种情况下可以考虑建立非聚集索引( 频繁作为查询条件的列 )
-
如下图所示,事务T1和T2按时间序列依次执行,则会发生什么问题( A )

A、 不可重读
B、 读了“脏数据”
C、 丢失更新
D、 写错误不可重复读: 不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。
丢失修改: 两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致了T1的修改失效了。飞机订票的例子就属于此类。
脏读: 读"脏"数据是指当事务T1修改某一数据时,事务T2读取同一数据后,T1由于某种原因撤销修改了,这时T1已修改过的数据恢复原值,而T2读到的数据是撤销修改之前的数据,那么此时T2的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。
虚读: 事务A首先根据条件索引得到N条数据,然后事务B在N条之外删除或者增加了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了虚读。 -
在MySQL中Replace在相同的主键或者唯一键的时候相当于 (DELETE+INSERT)
replace具备替换拥有唯一索引或者主键索引重复数据的能力,也就是如果使用replace
into插入的数据的唯一索引或者主键索引与之前的数据有重复的情况,将会删除原先的数据,然后再进行添加 -
最近小明搬到了新家,他正在粉刷墙壁,但是不幸的是他粉刷的墙壁并不理想。他的墙壁是一个长度为 的格子,每个格子用0表示红色,用1表示蓝色。现在墙壁是一个非常混乱的颜色。他想将墙壁涂成左边全是蓝色右边全是红色,可以将墙壁刷成全是红色或者蓝色。请问他至少需要粉刷多少个格子墙壁刷成他想要的样子?
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cmath>
using namespace std;
int n;
char arr[100001];
int main(){
cin>>n;
int br=0,allb=0,allr=0;
for(int i=0;i<n;i++){
cin>>arr[i];
if(arr[i]=='1') allr++;
else allb++;
}
int res = min(allr,allb);
int l = 0;
for(int i=0;i<n;i++){ //以第i个元素为分割点 ,计算左边1
if(arr[i]=='1'){
l++;
}//左边0=i+1-l 右边1:allr-l
int s = i+1-l+ allr-l;
res = s < res ? s : res;
}
cout<<res;
return 0;
}
浏览器
1、 关于DOMContentLoaded和load事件说法正确的是?
DOMContentLoaded事件比load事件更早执行
DOMContentLoaded
当纯HTML被完全加载以及解析时,DOMContentLoaded事件会被触发,而不必等待样式表,图片或者子框架完成加载。
Load
当一个资源及其依赖资源已完成加载时,将触发load事件。
readyState:loading -> 静态script 执行 -> readystatechange:interacitve -> DOMContentLoaded -> readystatechange:complete -> load -> 动态script
- defer 和sync 属性对脚本执行的影响
defer
- defer 特性告诉浏览器不要等待脚本,等待DOM构建完之后再执行;具有defer属性的脚本不会阻塞页面。
- 具有 defer 特性的脚本总是要等到 DOM 解析完毕,但在 DOMContentLoaded 事件之前执行。
async
async特性意味着脚本是完全独立的,脚本下载完后会立即执行并且是无序的
- 浏览器不会因async脚本而阻塞
- DOMContentLoaded和async脚本不会彼此等待
defer和async的区别在于前者加载的脚本的顺序是同步的,后者则是异步的。















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









