







torch.tensor()
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False) → Tensor
#注意
这个经常是复制data。如果要避免复制,并且,如果data是一个tensor,使用torch.Tensor.requires_grad_()
或者torch.Tensor.detach(). 如果data是NumPy ndarray 用torch.as_tensor()
#注意
当 data 是 tensor x, torch.tensor() 读出 ‘the data’不管x“经历”了什么, 并构建一个叶子变量.
因此
torch.tensor(x) 等价于 x.clone().detach() ,
torch.tensor(x, requires_grad=True)等价于x.clone().detach().requires_grad_(True).
#参数
data (array_like) 为tensor初始化数据 list, tuple, NumPy ndarray, scalar, and other types都行
dtype (torch.dtype, optional) 生成的 tensor的数据类型. 如果是 None,就从data中推测数据类型
device (torch.device, optional) 设备,如果没设置, 用默认 tensor 类型所在的设备,例如'cuda:0'
requires_grad (bool, optional) 是否要记录生成tensor的梯度
pin_memory (bool, optional) 只有CPU tensor可用,生成的tensor放在锁页内存中
本文作者注:设备内存充裕时可以使用,一定程度上提高了交互、操作的速度
#使用示例
生成空tensor
torch.tensor([]) # Create an empty tensor (of size (0,))tensor([])
torch.sparse_coo_tensor()
torch.sparse_coo_tensor(indices, values, size=None, dtype=None, device=None, requires_grad=False) → Tensor
#这个,本文作者目前还不知到有啥用(才疏学浅),就先放官方文档简介了,之后持续更新
Constructs a sparse tensors in COO(rdinate) format with non-zero elements at the given indices with the given values. A sparse tensor can be uncoalesced, in that case, there are duplicate coordinates in the indices, and the value at that index is the sum of all duplicate value entries: torch.sparse.
Parameters
indices (array_like) – Initial data for the tensor. Can be a list, tuple, NumPy ndarray, scalar, and other types. Will be cast to a torch.LongTensor internally. The indices are the coordinates of the non-zero values in the matrix, and thus should be two-dimensional where the first dimension is the number of tensor dimensions and the second dimension is the number of non-zero values.
values (array_like) – Initial values for the tensor. Can be a list, tuple, NumPy ndarray, scalar, and other types.
size (list, tuple, or torch.Size, optional) – Size of the sparse tensor. If not provided the size will be inferred as the minimum size big enough to hold all non-zero elements.
dtype (torch.dtype, optional) – the desired data type of returned tensor. Default: if None, infers data type from values.
device (torch.device, optional) – the desired device of returned tensor. Default: if None, uses the current device for the default tensor type (see torch.set_default_tensor_type()). device will be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types.
requires_grad (bool, optional) – If autograd should record operations on the returned tensor. Default: False.
torch.as_tensor()
torch.as_tensor(data, dtype=None, device=None) → Tensor
#将data转换为torch.Tensor,
只有data和要生成的tensor的dtype和device都一致时,不会执行复制
(本文作者注:不执行复制指的是共享内存)
其他情况返回一个新tensor,当data的requires_grad=True时,datad的计算图也会保留
(本文作者注:这种情况新tensor和data不共享内存)
当data是ndarray ,数据类型和目标一致,且目标为cpu类型,一样是共享内存的。
#参数
data (array_like) 为tensor初始化数据 list, tuple, NumPy ndarray, scalar, and other types都行
dtype (torch.dtype, optional) 生成的 tensor的数据类型. 如果是 None,就从data中推测数据类型
device (torch.device, optional) 设备,如果没设置, 用默认 tensor 类型所在的设备,例如'cuda:0'
torch.as_strided()
torch.as_strided(input, size, stride, storage_offset=0) → Tensor
Create a view of an existing torch.Tensor input with specified size, stride and storage_offset.
注:用这个生成的tensor中可能存在多个元素对应input的tensor中的同一个元素的内存地址,如果使用in-place操作就会产生问题,要先克隆一下。
参数:
input (Tensor) – 输入tensor.
size (tuple or ints) – 输出tensor的shape
stride (tuple or ints) – 输出tensor的stride
作者注:虽有些文章及科研人员认为它不是步长,但本作者认为其为步长,可以理解为采样间隔,下面有示例具体说明
storage_offset (int, optional) – 输出张量在内存中的偏移量
示例:
>>> x = torch.randn(3, 3)
>>> x
tensor([[ 0.9039, 0.6291, 1.0795],
[ 0.1586, 2.1939, -0.4900],
[-0.1909, -0.7503, 1.9355]])
>>> t = torch.as_strided(x, (2, 2), (1, 2))
>>> t
tensor([[0.9039, 1.0795],
[0.6291, 0.1586]])
>>> t = torch.as_strided(x, (2, 2), (1, 2), 1)
tensor([[0.6291, 0.1586],
[1.0795, 2.1939]])
torch.from_numpy()
torch.from_numpy(ndarray) → Tensor
从numpy.ndarray生成tensor
返回的tensor和输入的ndarray共享内存,对张量的修改将反映在上ndarray,反之亦然。返回的张量不可调整大小。
目前,可以输入numpy.float64, numpy.float32, numpy.float16,
numpy.int64, numpy.int32, numpy.int16, numpy.int8, numpy.uint8, and numpy.bool的ndarray
torch.zeros()
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回全零矩阵
参数:
size (int...) – 一个整数序列定义了输出tensor的维度. list or tuple都可以
out (Tensor, optional) – 输出 tensor.
dtype (torch.dtype, optional)-返回的tensor的数据类型. 默认是None,这种情况下数据类型就是全局的默认类型.
layout (torch.layout, optional) – 返回tensor的期望布局. Default: torch.strided.
device (torch.device, optional) – 返回的tensor的所在的设备. Default: None, 这种情况下利用当前默认tensor类型中的设备 (see torch.set_default_tensor_type()).
requires_grad (bool, optional) – 是否记录梯度,自动求导需要记录tensor之前的操作,Default: False.
torch.zeros_like()
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tensor
生成像input那样的全零矩阵
torch.zeros_like(input) 就相当于torch.zeros(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)
参数:
input (Tensor) – input的size会决定输出tensor的size.
dtype (torch.dtype, optional) –返回的tensor的数据类型. Default: None, 默认 input的数据类型.
layout (torch.layout, optional) – 返回tensor的期望布局. Default: None, 默认input的布局.
device (torch.device, optional) – 返回tensor的期望设备. Default: None, 默认 input的设备.
requires_grad (bool, optional) – 是否记录梯度, Default: False.
memory_format (torch.memory_format, optional) – 返回Tensor的内存类型. Default: torch.preserve_format.
torch.ones()
torch.ones(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回全1tensor
参数和torch.zeros()一致
torch.ones_like()
torch.ones_like(input, dtype=None, layout=None, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tensor
返回像input的全1tensor
参数和torch.zeros_like()一致
torch.arange()
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回一个一维tensor,大小是(end-start)/step向上取整。从start到end区间等间隔采样的结果,步长为step。
非整数的步长会导致舍入误差,这时可以在end上加上一个小的 epsilon
参数:
start (Number) – 起始值 Default: 0.
end (Number) – 终值
step (Number) – 步长 Default: 1.
out (Tensor, optional) – 输出的 tensor.
dtype (torch.dtype, optional) – 返回的 tensor的数据类型. Default: 如果是None, 使用全局默认数据类型 (see torch.set_default_tensor_type()).如果没给, 就从其他输入参数推断输出的数据类型. 如果start或者end中有浮点类型的数据, dtype就会推断为默认类型, see get_default_dtype(). 否则就是 torch.int64.
layout (torch.layout, optional) – 返回 Tensor的类型. Default: torch.strided.
device (torch.device, optional) – 返回tensor期望的设备. Default: if None, 用默认设备 (see torch.set_default_tensor_type()).
requires_grad (bool, optional) – 是否记录梯度. Default: False.
示例:
>>> torch.arange(5)
tensor([ 0, 1, 2, 3, 4])
>>> torch.arange(1, 4)
tensor([ 1, 2, 3])
>>> torch.arange(1, 2.5, 0.5)
tensor([ 1.0000, 1.5000, 2.0000])
torch.range()
torch.range(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
这个与torch.arange()的区别是,这个生成的tensor的size是(end-start)/step向下取整加1.
参数均一致
torch.linspace()
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
生成从start到end的steps个等距点
参数只有steps与torch.arange()不同,其余均相同
示例:
>>> torch.linspace(3, 10, steps=5)
tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])
>>> torch.linspace(-10, 10, steps=5)
tensor([-10., -5., 0., 5., 10.])
>>> torch.linspace(start=-10, end=10, steps=5)
tensor([-10., -5., 0., 5., 10.])
>>> torch.linspace(start=-10, end=10, steps=1)
tensor([-10.])
torch.logspace()
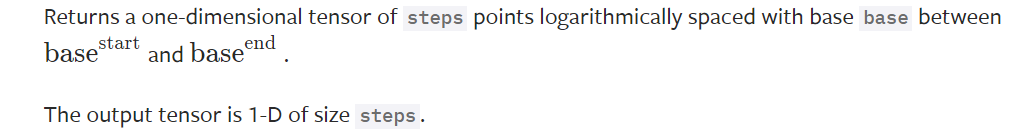
torch.logspace(start, end, steps=100, base=10.0, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数:
base (float) –是log的底 Default: 10.0.
其余参数均与torch.linspace()相同
示例:
>>> torch.logspace(start=-10, end=10, steps=5)
tensor([ 1.0000e-10, 1.0000e-05, 1.0000e+00, 1.0000e+05, 1.0000e+10])
>>> torch.logspace(start=0.1, end=1.0, steps=5)
tensor([ 1.2589, 2.1135, 3.5481, 5.9566, 10.0000])
>>> torch.logspace(start=0.1, end=1.0, steps=1)
tensor([1.2589])
>>> torch.logspace(start=2, end=2, steps=1, base=2)
tensor([4.0])
torch.eye()
torch.eye(n, m=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
生成对角阵,对角线上全1,其余全0
参数:
n (int) - 行数
m (int, optional) – 列数,默认等于 n
out (Tensor, optional) – 输出tensor.
dtype (torch.dtype, optional) – 数据类型. Default: if None, uses a global default (see torch.set_default_tensor_type()).
layout (torch.layout, optional) – 布局. Default: torch.strided.
device (torch.device, optional) – 设备
requires_grad (bool, optional) – 是否记录梯度 Default: False.
torch.empty()
torch.empty(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False) → Tensor
生成一个充满未初始化数据的tensor
pin_memory (bool, optional) – 如果设置, 返回的tensor会放在锁页内存中. 只适用于 CPU tensors. Default: False.
其余参数与torch.zeros()一致
torch.empty_like()
torch.empty_like(input, dtype=None, layout=None, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tensor
与torch.zeros_like()一致
torch.empty_strided()

torch.empty_strided(size, stride, dtype=None, layout=None, device=None, requires_grad=False, pin_memory=False) → Tensor
参数:
size (tuple of python:ints) – the shape of the output tensor
stride (tuple of python:ints) – the strides of the output tensor
dtype (torch.dtype, optional) – the desired data type of returned tensor. Default: if None, uses a global default (see torch.set_default_tensor_type()).
layout (torch.layout, optional) – the desired layout of returned Tensor. Default: torch.strided.
device (torch.device, optional) – the desired device of returned tensor. Default: if None, uses the current device for the default tensor type (see torch.set_default_tensor_type()). device will be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types.
requires_grad (bool, optional) – If autograd should record operations on the returned tensor. Default: False.
pin_memory (bool, optional) – If set, returned tensor would be allocated in the pinned memory. Works only for CPU tensors. Default: False.
示例:
>>> a = torch.empty_strided((2, 3), (1, 2))
>>> a
tensor([[8.9683e-44, 4.4842e-44, 5.1239e+07],
[0.0000e+00, 0.0000e+00, 3.0705e-41]])
>>> a.stride()
(1, 2)
>>> a.size()
torch.Size([2, 3])
torch.full()
torch.full(size, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
生成size大小的矩阵,矩阵的每个元素都是fill_value
参数:
size (int...) – a list, tuple, or torch.Size of integers 输出tensor的size
fill_value – the number to fill the output tensor with.
out (Tensor, optional) – 输出 tensor.
dtype (torch.dtype, optional) – 数据类型 Default: if None, uses a global default (see torch.set_default_tensor_type()).
layout (torch.layout, optional) – Tensor的布局. Default: torch.strided.
device (torch.device, optional) – 设备
requires_grad (bool, optional) – 是否计算梯度 Default: False.
示例
>>> torch.full((2, 3), 3.141592)
tensor([[ 3.1416, 3.1416, 3.1416],
[ 3.1416, 3.1416, 3.1416]])

torch.full_like()
full_like(input, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, memory_format=torch.preserve_format) -> Tensor
参数
input (Tensor) –input的tensor的size会决定输出tensor的size.
fill_value – 填充值
dtype (torch.dtype, optional) – 数据类型 Default: if None, defaults to the dtype of input.
layout (torch.layout, optional) – 布局Default: if None, defaults to the layout of input.
device (torch.device, optional) – 设备Default: if None, defaults to the device of input.
requires_grad (bool, optional) – 是否计算梯度Default: False.
memory_format (torch.memory_format, optional) – 返回tensor的内存类型 Default: torch.preserve_format.
torch.quantize_per_tensor()
torch.quantize_per_tensor(input, scale, zero_point, dtype) → Tensor
Converts a float tensor to quantized tensor with given scale and zero point.
参数
input (Tensor) – float tensor to quantize
scale (float) – scale to apply in quantization formula
zero_point (int) – offset in integer value that maps to float zero
dtype (torch.dtype) – the desired data type of returned tensor. Has to be one of the quantized dtypes: torch.quint8, torch.qint8, torch.qint32
示例:
>>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8)
tensor([-1., 0., 1., 2.], size=(4,), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=0.1, zero_point=10)
>>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8).int_repr()
tensor([ 0, 10, 20, 30], dtype=torch.uint8)
torch.quantize_per_channel()
torch.quantize_per_channel(input, scales, zero_points, axis, dtype) → Tensor
Converts a float tensor to per-channel quantized tensor with given scales and zero points.
参数:
input (Tensor) – float tensor to quantize
scales (Tensor) – float 1D tensor of scales to use, size should match input.size(axis)
zero_points (int) – integer 1D tensor of offset to use, size should match input.size(axis)
axis (int) – dimension on which apply per-channel quantization
dtype (torch.dtype) – the desired data type of returned tensor. Has to be one of the quantized dtypes: torch.quint8, torch.qint8, torch.qint32
示例:
>>> x = torch.tensor([[-1.0, 0.0], [1.0, 2.0]])
>>> torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8)
tensor([[-1., 0.],
[ 1., 2.]], size=(2, 2), dtype=torch.quint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([0.1000, 0.0100], dtype=torch.float64),
zero_point=tensor([10, 0]), axis=0)
>>> torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8).int_repr()
tensor([[ 0, 10],
[100, 200]], dtype=torch.uint8)















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









