






1.Google三驾马车
GFS MapReduce Bigtable
2.Hadoop2.x相比于1增加了哪些组件?
Yarn
3.GFS存储的文件都被分割成固定大小的块,每个块都会复制到多个块服务器上(可靠性),请问默认会存储几份?
3
4.下面哪个目录保存了Hadoop集群的命令(比如启动Hadoop)?
sbin
5.HDFS首先把大数据文件切分成若干个小的数据块,再把这些数据分别写入不同的结点。这些负责保存文件数据的结点被称为?
DataNode
6.名称节点是HDFS的管理者,它的职责有3个方面。
负责管理和维护HDFS命名空间,负责管理DataNode上的数据块,接受客户端的请求
7.YARN Web界面默认占用哪个端口?
8088
8.MapReduce的特点?
易于编程,良好的扩容性,高容错性
9.什么场景适合采用列式存储?
单列,获取频率较高,对于大数据环境,利用数据压缩和线性扩展,事务使用率不高,数据量非常大。
10.Reducce的个数由什么决定?
Partition分区个数
11.

core-site.xml
12.

/mydemo下的目录数量、文件数量、文件总结大小
13.


14.

15.

16.

17.

18.
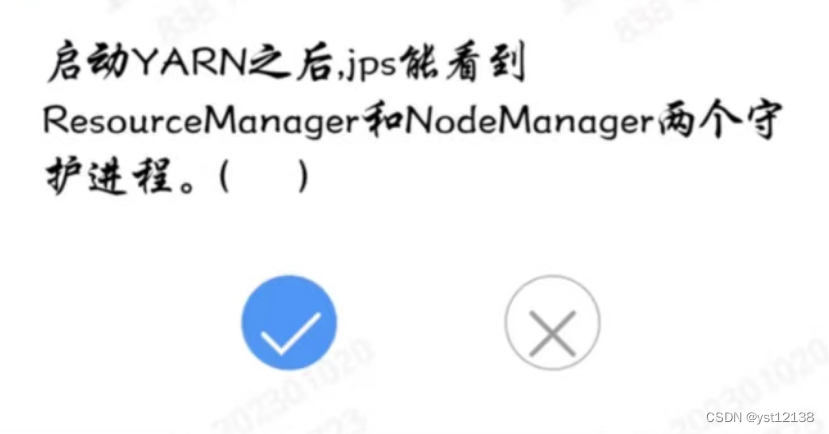
19.
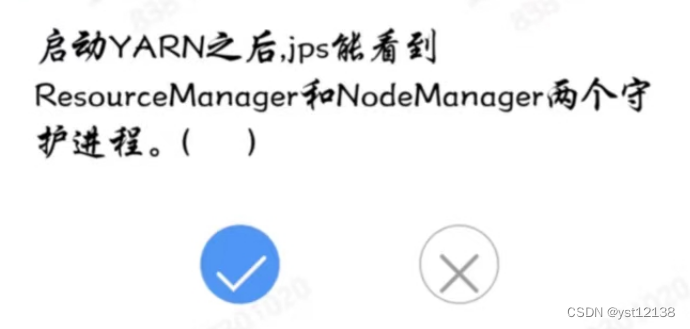
20.
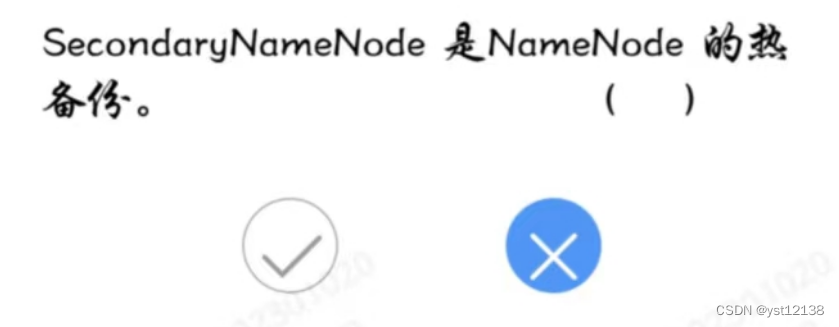
21.

22.

23.

24.

25.

26.![]()
MapReduce模型的要点包括以下几个方面:
1. MapReduce由两个阶段组成:Map阶段和Reduce阶段。
2. Map阶段将大任务分解为若干个小任务,每个小任务可以并行计算,彼此间几乎没有依赖关系。
3. Reduce阶段对Map阶段的结果进行全局汇总。
4. MapReduce适用于大规模数据处理场景,可以实现分布式计算。
5. MapReduce的核心思想是“分而治之”,即将复杂的任务分解为若干个简单的任务来并行处理。
6. MapReduce的实现可以使用Hadoop等分布式计算框架。
27.
HDFS文件读取过程如下:
1.客户端向NameNode请求文件的位置信息。
2.NameNode返回包含文件块所在DataNode的位置信息的块映射表。
3.客户端根据块映射表直接连接到DataNode上,向其请求文件块。
4.DataNode返回所请求的文件块。
5.客户端将接收到的文件块组合成完整的文件。
28.

Flume主要由三个部分组成:Source、Channel和Sink。它们各自的作用如下:
1. Source:负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
2. Channel:是Source和Sink之间的缓冲区,用于存储Flume接收到的数据。Channel可以是内存或磁盘,可以配置容量和事务等属性。
3. Sink:负责将数据从Channel中取出并写入到目标存储系统中,如HDFS、HBase、Elasticsearch等。Sink组件可以对数据进行转换、过滤和格式化等操作。
29.

pig -x local















 6534
6534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









