







RFM模型的设计
》关于 RFM 模型,之前有介绍过。它是:主要用于衡量当前用户价值和客户潜在价值的重要工具和手段。
》【从消费行为的角度,对用户进行分层,并采取差异化营销策略】


》根据一组数据,设计RFM模型。
-
但是发现到分组的数据不合理,出现极端的数据,内部差异程度较大。所以需要用到 聚类算法(K-Means)


-
最终用python的
KMeans方法,计算出合理的分组数据,如下代码:
import pandas as pd
from sklearn.cluster import KMeans # 调用Sklearn机器学习库
# 获取数据
data = pd.read_csv("sales_kmeans.csv")
# 利用Kmeans获取聚类中心(分界点)
kmodels = KMeans(n_clusters=4) # 分为4个分界点,构造聚类器
for col in data.columns: # 获取每一列的数据
kmodels.fit(data[[col]]) # 聚类
print(col)
centers = kmodels.cluster_centers_ # 获取聚类中心
for c in centers:
print(c[0])
'''
运行结果为:
R
790.58
713.90
895.97
637.94
F
1.06
58.09
13.61
3.73
M
369.51
68696.84
4535.10
16324.23
'''
》附上数据表,最终生成的结果如图:
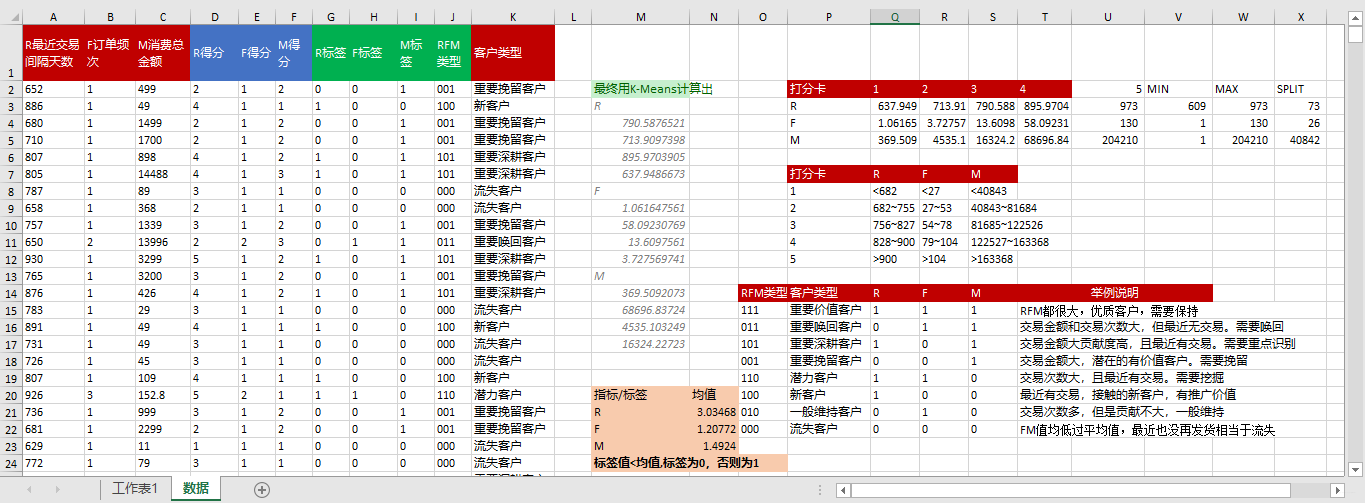
》实现数据可视化:
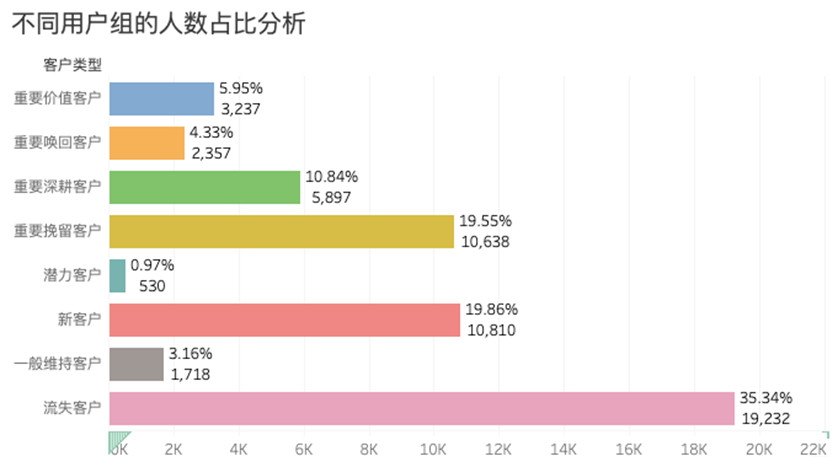
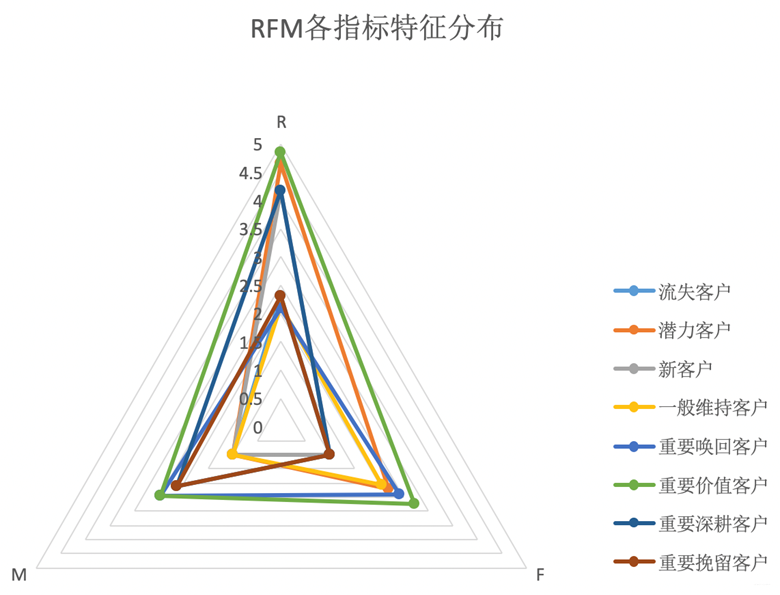
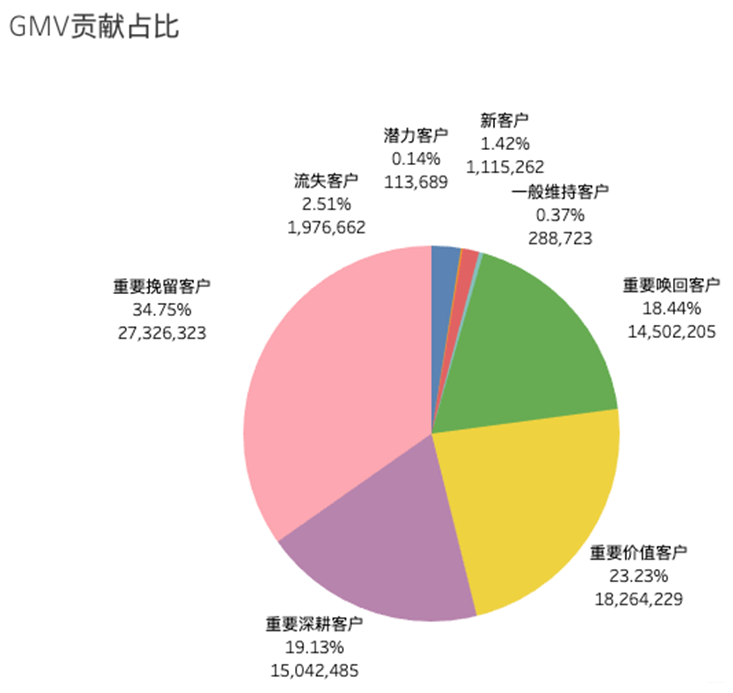
》整理出来的ppt【基于RFM的用户精细化管理】,链接如下:
https://wwa.lanzous.com/i5aw7hdlddc














 2685
2685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









