






by: Eva Tse, Zhenxiao Luo, Nezih Yigitbasi @ Big Data Platform team
原文网址http://techblog.netflix.com/2014/10/using-presto-in-our-big-data-platform.html
At Netflix, the Big Data Platform team is responsible for building a reliable data analytics platform shared across the whole company. In general, Netflix product decisions are very data driven. So we play a big role in helping different teams to gain product and consumer insights from a multi-petabyte scale data warehouse (DW). Their use cases range from analyzing A/B tests results to analyzing user streaming experience to training data models for our recommendation algorithms.
We shared our overall architecture in a previous blog post. The underpinning of our big data platform is that we leverage AWS S3 for our DW. This architecture allows us to separate compute and storage layers. It allows multiple clusters to share the same data on S3 and clusters can be long-running and yet transient (for flexibility). Our users typically write Pig or Hive jobs for ETL and data analytics.
A small subset of the ETL output and some aggregated data is transferred to Teradata for interactive querying and reporting. On the other hand, we also have the need to do low latency interactive data exploration on our broader data set on S3. These are the use cases that Presto serves exceptionally well. Seven months ago, we first deployed Presto into production and it is now an integral part of our data ecosystem. In this blog post, we would like to share our experience with Presto and how we made it work for us!
Why Presto?
We had been in search of an interactive querying engine that could work well for us. Ideally, we wanted an open source project that could handle our scale of data & processing needs, had great momentum, was well integrated with the Hive metastore, and was easy for us to integrate with our DW on S3. We were delighted when Facebook open sourced Presto.
In terms of scale, we have a 10 petabyte data warehouse on S3. Our users from different organizations query diverse data sets across expansive date ranges. For this use case, caching a specific dataset in memory would not work because cache hit rate would be extremely low unless we have an unreasonably large cache. The streaming DAG execution architecture of Presto is well-suited for this sporadic data exploration usage pattern.
In terms of integrating with our big data platform, Presto has a connector architecture that is Hadoop friendly. It allows us to easily plug in an S3 file system. We were up and running in test mode after only a month of work on the S3 file system connector in collaboration with Facebook.
In terms of usability, Presto supports ANSI SQL, which has made it very easy for our analysts and developers to get rolling with it. As far as limitations / drawbacks, user-defined functions in Presto are more involved to develop, build, and deploy as compared to Hive and Pig. Also, for users who want to productionize their queries, they need to rewrite them in HiveQL or Pig Latin, as we don’t currently use Presto in our critical production pipelines. While there are some minor inconveniences, the benefits of being able to interactively analyze large amounts of data is a huge win for us.
Finally, Presto was already running in production at Facebook. We did some performance benchmarking and stress testing and we were impressed. We also looked under the hood and saw well designed and documented Java code. We were convinced!
Our production environment and use cases
Currently, we are running with ~250 m2.4xlarge EC2 worker instances and our coordinator is on r3.4xlarge. Our users run ~2500 queries/workday. Our Presto cluster is completely isolated from our Hadoop clusters, though they all access the same data on our S3 DW.
Almost all of our jobs are CPU bound. We set our task memory to a rather high value (i.e., 7GB, with a slight chance in oversubscribing memory) to run some of our memory intensive queries, like big joins or aggregation queries.
We do not use disk (as we don’t use HDFS) in the cluster. Hence, we will be looking to upgrade to the current generation AWS instance type (e.g. r3), which has more memory, and has better isolation and performance than the previous generation of EC2 instances.
We are running the latest Presto 0.76 release with some outstanding pull requests that are not committed yet. Ideally, we would like to contribute everything back to open source and not carry custom patches in our deployment. We are actively working with Facebook and looking forward to committing all of our pull requests.
Presto addresses our ad hoc interactive use cases. Our users always go to Presto first for quick answers and for data exploration. If Presto does not support what they need (like big join / aggregation queries that exceed our memory limit or some specific user-defined functions that are not available), then they would go back to Hive or Pig.
We are working on a Presto user interface for our internal big data portal. Our algorithm team also built an interactive data clustering application by integrating R with Presto via an open source Python Presto client.
Performance benchmark
At a high level, we compare Presto and Hive query execution time using our own datasets and users’ queries instead of running standard benchmarks like TPC-H or TPC-DS. This way, we can translate the results back to what we can expect for our use cases. The graph below shows the results of three queries: a group-by query, a join plus a group-by query, and a needle-in-a-haystack (table scan) query. We compared the performance of Presto vs. Hive 0.11 on Hadoop 2 using Parquet input files on S3, all of which we currently use in production. Each query processed the same data set with varying data sizes between ~140GB to ~210GB depending on the file format.
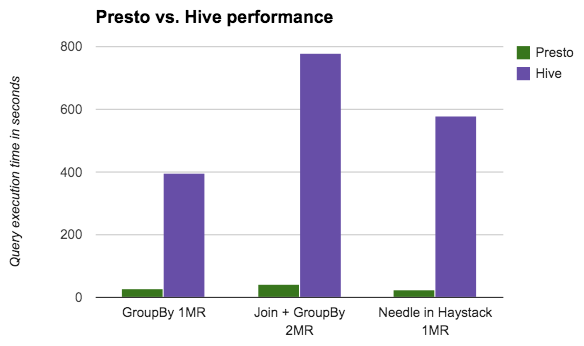
Cluster setup: 40 nodes m2.4xlarge
Settings we tuned: task.shard.max-threads=32 task.max-memory=7GB sink.max-buffer-size=1GB hive.s3.max-client-retries=50 hive.s3.max-error-retries=50 hive.s3.max-connections=500 hive.s3.connect-timeout=5m hive.s3.socket-timeout=5m
`
We understand performance test environments and numbers are hard to reproduce. What is worth noting is the relative performance of these tests. The key takeaway is that queries that take one or two map-reduce (MR) phases in Hadoop run 10 to 100 times faster in Presto. The speedup in Presto is linear to the number of MR jobs involved. For jobs that only do a table scan (i.e., I/O bound instead of CPU bound), it is highly dependent on the read performance of the file format used. We did some work on Presto / Parquet integration, which we will cover in the next section.
Our Presto contributions
The primary and initial piece of work that made Presto work for us was S3 FileSystem integration. In addition, we also worked on optimizing S3 multipart upload. We also made a few enhancements and bug fixes based on our use cases along the way: disabling recursive directory listing, json tuple generation, foreground metastore refresh, mbean for S3 filesystem monitoring, and handling S3 client socket timeout.
In general, we are committed to make Presto work better for our users and to cover more of their needs. Here are a few big enhancements that we are currently working on:
Parquet file format support
We recently upgraded our DW to use the Parquet file format (FF) for its performance on S3 and for its flexibility to integrate with different data processing engines. Hence, we are committed to make Presto work better with Parquet FF. (For details on why we chose Parquet and what we contributed to make it work in our environment, stay tuned for an upcoming blog post).
Developing based on Facebook’s initial Parquet integration, we added support for predicate pushdown, column position based access (instead of name based access) to Parquet columns, and data type coercion. For context, we use the Hive metastore as our source of truth for metadata, and we do schema evolution on the Hive metastore. Hence, we need column position based access to work with our Hive metastore instead of using the schema information stored in Parquet files.
Here is a comparison of Presto job execution times among different FFs. We compare read performance of sequence file (a FF we have historically used), ORCFile (we benchmarked the latest integration with predicate pushdown, vectorization and lazy materialization on read) and Parquet. We also compare the performance on S3 vs. HDFS. In this test, we use the same data sets and environment as the above benchmark test. The query is a needle-in-a-haystack query that does a select and filter on a condition that returns zero rows.
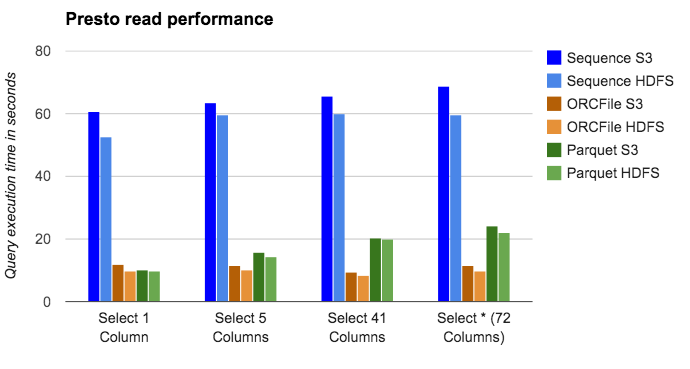
As next step, we will look into improving Parquet performance further by doing predicate pushdown to eliminate whole row groups, vectorization and lazy materialization on read. We believe this will make Parquet performance on par with ORC files.
ODBC / JDBC support
This is one of the biggest asks from our users. Users like to connect to our Hive DW directly to do exploratory / ad hoc reporting because it has the full dataset. Given Presto is interactive and integrated with Hive metastore, it is a natural fit.
Presto has a native ODBC driver that was recently open sourced. We made a few bug fixes and we are working on more enhancements. Overall, it is working well now for our Tableau users in extract (non-live exploration) mode. For our users who prefer to use Microstrategy, we plan to explore different options to integrate with it next.
Map data type support
All the event data generated from our Netflix services and Netflix-enabled devices comes through our Suro pipeline before landing in our DW. For flexibility, this event data is structured as key/value pairs, which get automatically stored in map columns in our DW. Users may pull out keys as a top level columns in the Hive metastore by adjusting some configurations in our data pipeline. Still, a large number of key/value pairs remain in the map because there are a large number of keys and the key space is very sparse.
It is very common for users to lookup a specific key from the map. With our current Parquet integration, looking up a key from the map column means converting the column to JSON string first then parsing it. Facebook recently added native support for array and map data types. We plan to further enhance it to support array element or map key specific column pruning and predicate pushdown for Parquet FF to improve performance.
Our wishlist
There are still a couple of items that are high on our wishlist and we would love to contribute on these when we have the bandwidth.
Big table join. It is very common for our queries to join tables as we have a lot of normalized data in our DW. We are excited to see that distributed hash join is now supported and plan to check it out. Sort-merge join would likely be useful to solve some of the even bigger join use cases that we have.
Graceful shrink. Given Presto is used for our ad hoc use cases, and given we run it in the cloud, it would be most efficient if we could scale up the cluster during peak hours (mostly work hours) and scale down during trough hours (night time or weekends). If Presto nodes can be blacklisted and gracefully drained before shutdown, we could combine that with available JMX metrics to do heuristic-based auto expand/shrink of the cluster.
Key takeaway
Presto makes the lives of our users a lot easier. It tremendously improves their productivity.
We have learned from our experience that getting involved and contributing back to open source technologies is the best way to make sure it works for our use cases in a fast paced and evolving environment. We have been working closely with the Facebook team to discuss our use cases and align priorities. They have been open about their roadmap, quick in adding new features, and helpful in providing feedback to our contributions. We look forward to continuing to work with them and the community to make Presto even better and more comprehensive. Let us know if you are interested in sharing your experiences using Presto.
Last but not least, the Big Data Platform team at Netflix has been heads-down innovating on our platform to meet our growing business needs. We will share more of our experiences with our Parquet FF migration and Genie 2 upgrade in upcoming blog posts.
If you are interested in solving big data problems like ours, we would like to hear from you!















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









