






转自https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
作者是Presto主要作者之一Dain Sundstrom
A few months ago, a few of us started looking at the performance of Hive file formats in Presto. As you might be aware, Presto is a SQL engine optimized for low-latency interactive analysis against data sources of all sizes, ranging from gigabytes to petabytes. Presto allows you to query data where it lives, whether it’s in Hive, Cassandra, Kafka, relational databases, or even a proprietary data store.
We are always pushing the envelope in terms of scale and performance. We have a large number of internal users at Facebook who use Presto on a continuous basis for data analysis. Improving query performance directly improves their productivity, so we thought through ways to make Presto even faster. We ended up focusing on a few elements that could help deliver optimal performance in the Presto query engine.
Columnar Reads
Presto is a columnar query engine, so for optimal performance the reader should provide columns directly to Presto. The Hive-based ORC reader provides data in row form, and Presto must reorganize the data into columns. This reorganization is unnecessary, because ORC stores data natively as columns, and the RecordReader interface we are using provides only rows. In Hive 13, a new VectorizedOrcRecordReader was introduced that provides columns instead of rows.
Predicate pushdown
The next important feature is predicate pushdown. In ORC, the minimum and maximum values of each column are recorded per file, per stripe (~1M rows), and every 10,000 rows. Using this information, the reader should skip any segment that could not possibly match the query predicate. The Hive 13 ORC reader has SearchArgument, which filters segments.
Lazy reads
The last critical feature is lazy reads. Predicate pushdown is amazing when it works, but for a lot of data sets, it doesn’t work at all. If the data has a large number of distinct values and is well-shuffled, the minimum and maximum stats will cover almost the entire range of values, rendering predicate pushdown ineffective. This is common with identifier columns like UUID, MESSAGE_ID, PAGE_ID, and IP_ADDRESS, which are the columns most likely to be queried for an exact match (e.g., “count requests for my page”). With lazy reads, the query engine always inspects the columns needed to evaluate the query filter, and only then reads other columns for segments that match the filter (if any are found). For most workloads, this feature saves more CPU than predicate pushdown.
A new ORC reader
The decision to write a new ORC reader for Presto was not an easy one. We spent a lot of time working with the Hive 13 vectorized reader and saw very good performance, but the code was not very mature. The vectorized reader did not support structs, maps, or lists, and neither the row-oriented nor the column-oriented readers supported lazy reads. Additionally, at Facebook we use a fork of ORC named “DWRF”. The DWRF reader didn’t support columnar reads or predicate pushdown, but it did support lazy reads. To get the speed we were looking for, we needed all three features. By writing a new reader, we were able to create interfaces that worked seamlessly with Presto.
We spent a few months working on the new reader implementation, which supports both ORC and DWRF, exposes a columnar interface, and supports predicate pushdown and lazy reads. Before we rolled it out to production, we had to make sure it was as fast as we’d hoped.
Raw decoding performance
The first test we performed was to create a small file containing about 6 million rows using the TPC-H lineitem generator (TPC-H scale factor 1), read various sets of columns, and compare the performance gains between the old Hive-based ORC reader and the new Presto ORC reader. (In all our graphs, the x-axis shows different performance tests with three compression schemes; the y-axis shows gains in efficiency or performance. Please note that the values are not absolutes but rather show the overall speedup of the new code over the old.)
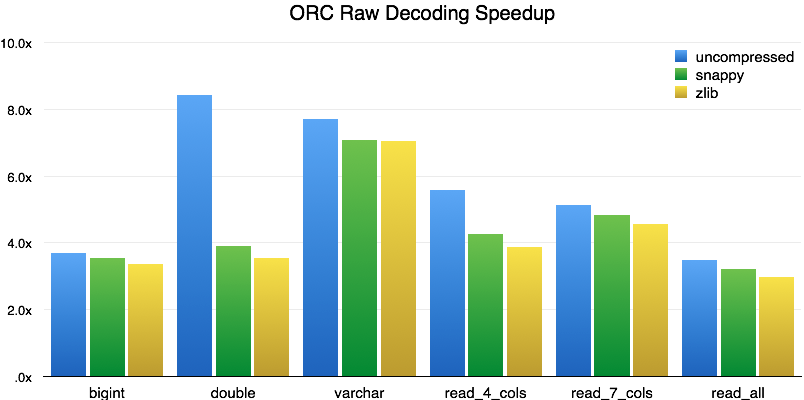
For a single column of BIGINT or DOUBLE, the speedup is 3.5x, and for VARCHAR the speedup is 7x. As we added more columns in the read_4_cols (columns from TPC-H query 6), read_7_cols (columns from TPC-H query 1), and read_all (all 16 columns) tests, the speedup settles around 3x. The massive gain for uncompressed double can be explained by the fact that double-precision values are stored unencoded in ORC. Reading them is just a matter of mapping them into memory, which is virtually free. Queries that can take advantage of lazy reads and predicate pushdown show speedups of 18x and 80x, respectively. We don’t consider that a fair comparison, however, due to lack of support for those features in the built-in Hive reader, so we’ve excluded those results from the chart above.
Query performance
Raw decoding performance is much better than we expected, but it is a single-threaded test that is processing an in-memory data set. How does the new reader perform when integrated into the Presto distributed query engine? To measure this, we ran the same queries as above against a 600-million-row data set (TPC-H scale factor 100) in a Presto cluster running on 14 machines, each with 16 cores and 64 GB of memory (see appendix for full details).
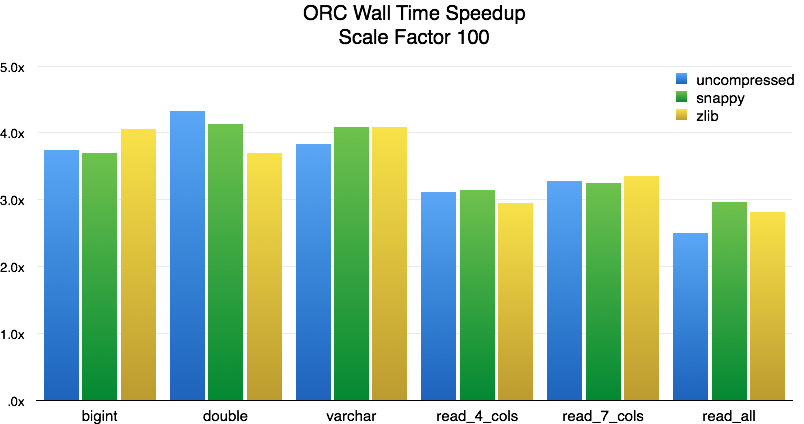
For single-column reads, the speedup in end-to-end query latency (wall time) is 3.5x to 4x. As we add more columns, the performance settles around 3x. We also measured the CPU time required by Presto to process each query:
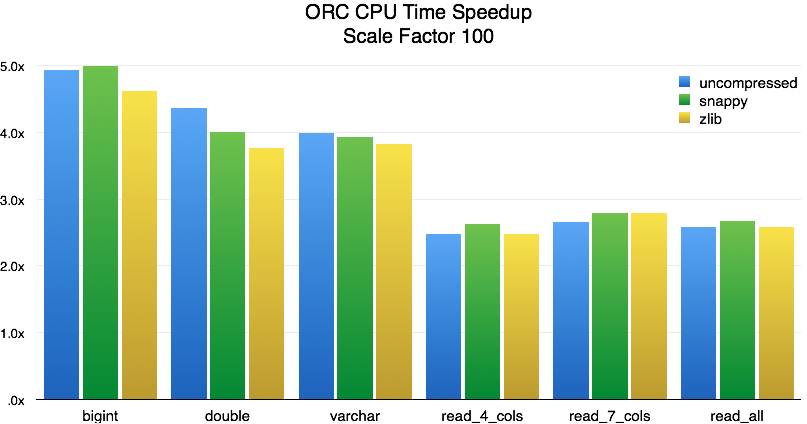
For single column reads, the speedup in CPU time is around 4x. As we add more columns, performance settles around 2.6x. Like in the previous test, we also saw large improvements in performance for queries that could benefit from lazy reads and predicate pushdown.
Large scale
The size of the data we used for the benchmarks in the previous section was 40 GB uncompressed, 21 GB when compressed with Snappy, and 15 GB with ZLIB. Our cluster has 896 GB of total available memory, so it can easily fit all that data in RAM. How does the reader perform with IO-bound workloads? To evaluate this, we ran the queries over a data set 100 times larger (TPC-H scale factor 10,000). Our initial tests uncovered a few performance issues due to unnecessary seeks and excessive GC pressure. These are the benchmark results after we addressed those problems:
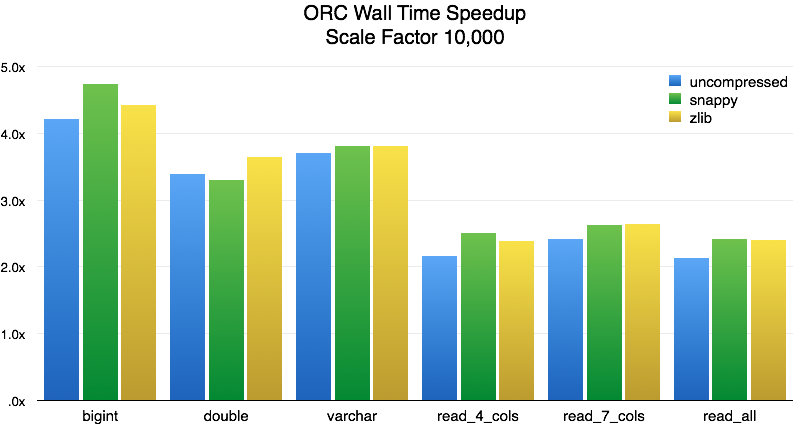
For single column reads, the speedup in end-to-end query latency (wall time) is 3.5x to 4.5x. As we add more columns, the performance settles around 2.5x. As before, we also measured the CPU time required by Presto to process each query:
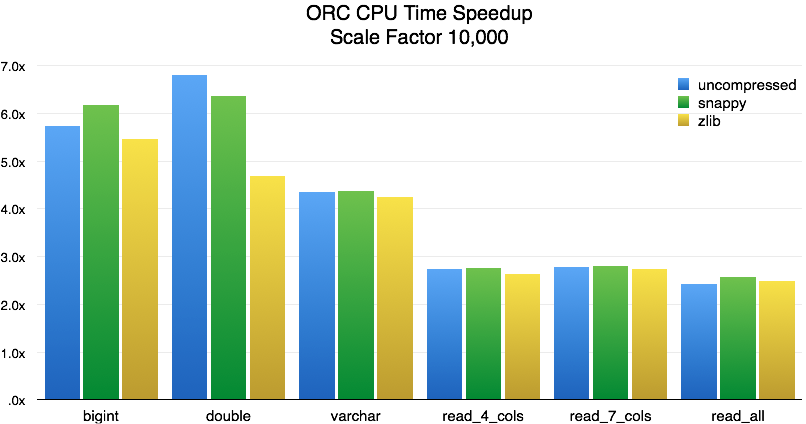
For single column reads, the speedup in CPU time is 4.5x to 6.5x. As we add more columns, performance settles around 2.6x. The performance is in line with the smaller scale factor except for wall time for multiple columns.
Comparisons
The performance of the new ORC reader is significantly better than that of the old Hive-based ORC reader, but that doesn’t tell us how it compares with readers for other data formats. We converted the data from the large-scale test to RCFile-binary format, which has the fastest reader implementation in Presto, and ran the benchmark. These are the results:
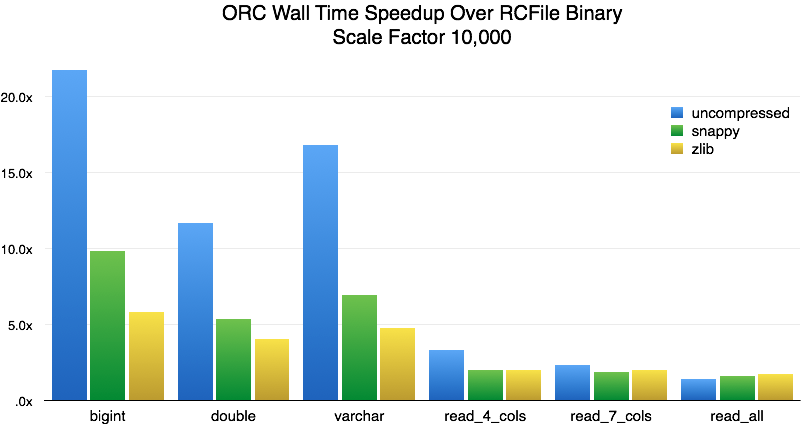
The biggest speedup is for single-column queries over uncompressed data (10-20x). This is largely explained by the fact that the RCFile-binary data size is twice as large as ORC’s, and query performance is limited by available disk bandwidth. For ZLIB, we can see a more moderate speedup of 4-5x. For tests involving multiple columns, the speedups are generally in the 2-3x range. For CPU time, we see this:
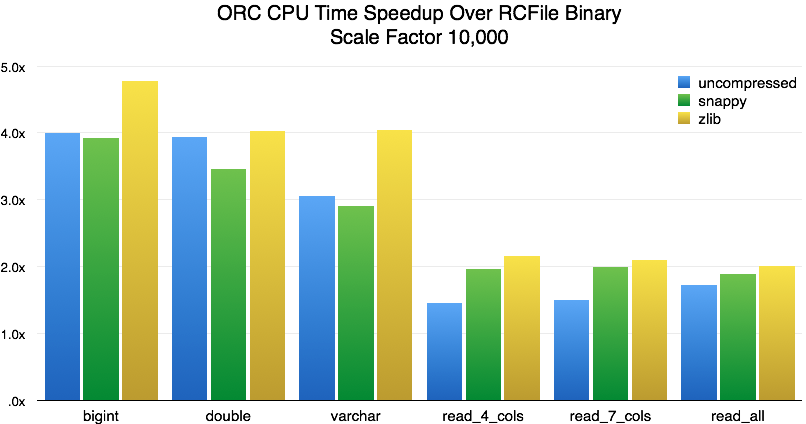
The average speedup is 3.8x for single-column reads and 1.9x for multiple-column reads, but the largest speedups are with ZLIB, which is the most common compression scheme for RCFile. In the predicate pushdown benchmarks, we see a 20x wall time and 50x CPU time speedup. We don’t consider that a fair comparison, however, because RCFile does not track column statistics, and therefore cannot do predicate pushdown. Even though the RCFile reader implements lazy reads, we still see a speedup of 2x in wall time and 4x in CPU time in these tests.
Finally, for those of you not yet using Presto, we compared the new Presto ORC reader with the Parquet reader in Impala 2.0.1. For wall time, we see this:
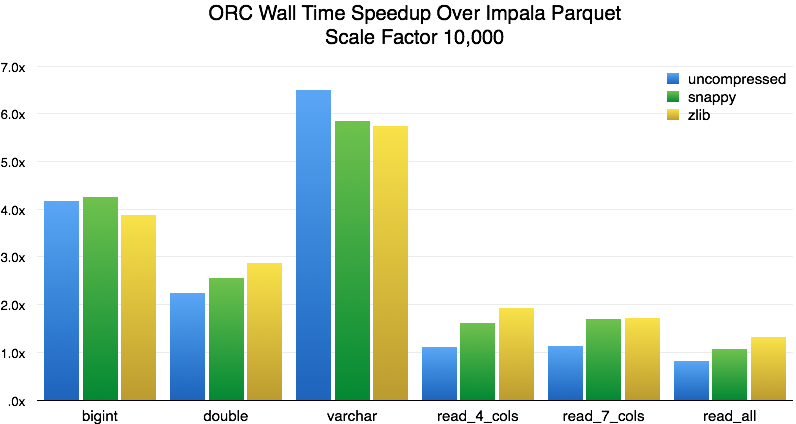
The speedup varies depending on the type of read, which is expected given the different file formats. The speedup for a single BIGINT is about 4x, for DOUBLE about 2.5x, and for VARCHAR about 6x. As we add more columns, the performance for ZLIB falls between 1.3x to 1.9x, for Snappy 1.1x to 1.6x, and for uncompressed data between 0.8x to 1.1x. The poor showing in uncompressed data is unsurprising since massive files generally result in GC pressure. Impala does not fully utilize all the CPUs on the test machines, which hurts the wall time. To account for this lack of parallelism in Impala, we also measured CPU time:
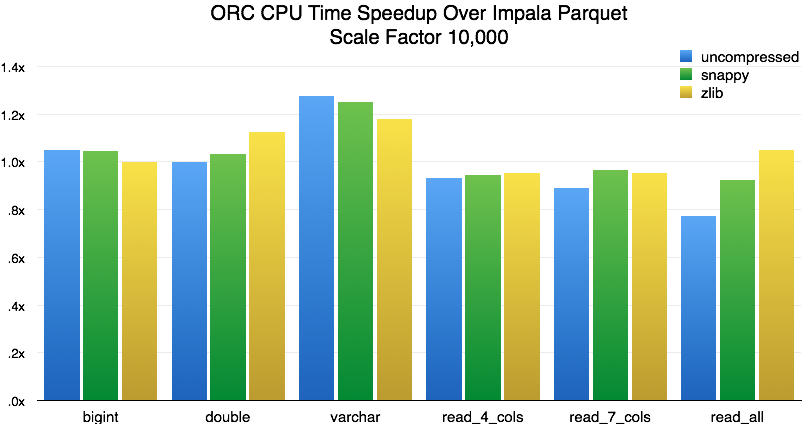
Using CPU time, we see that Impala Parquet and Presto ORC have similar CPU efficiency. For single columns, we see slightly better performance for Presto, and for more columns, we see slightly better performance for Impala. Again, uncompressed data performs much worse, due to GC pressure from the large uncompressed files.
Overall speedup
The new Presto ORC reader is a significant improvement over the old Hive-based ORC reader and the RCFile-binary reader. On top of that, we’ve seen massive speedups with the new lazy reads and predicate pushdown features. With the reader fully integrated into Presto, we saw a number of improvements with terabyte-scale ZLIB compressed tables:
- 2-4x wall time and CPU time speedup over the old Hive-based ORC reader
- 2-4x wall time and CPU time speedup over the RCFile-binary reader
- 1.3-5.8x wall time speedup (and comparable CPU time) over Impala Parquet
- Large speedup (4x+) when lazy reads are utilized
- Substantial speedup (30x+) when predicate pushdown is utilized
Will you see this speedup in your queries? As any good engineer will tell you, it depends. The queries in this test are carefully crafted to stress the reader as much as possible. A query bounded by client bandwidth (for example, SELECT FROM table ) or a computation-bound query (lots of regular expressions or JSON extraction) will see little to no speedup. What the new code does is open up a lot of CPU headroom for the main computation of the query, which generally results in quicker queries or more concurrency in your warehouse.
The Presto ORC reader is available in open source, and it’s being used at Facebook, showing good results. Try it out and tell us what you think.
Appendix: Test cluster configuration
Hardware
We have a 14-machine cluster, each containing:
- CPU: Dual 8-core Intel Xeon CPU (32 Hyper-Threads), E5-2660 @ 2.20GHz
- Memory: 64 GB
- Disk: 15 x 3 TB (JBOD configuration)
- Network: 10 gigabit with full bandwidth between machines
Environment
CDH 5.2.1 (HDFS, Hive, Metastore)
CentOS 6.3 (Operating System)
Test systems
Presto 0.89
Impala 2.0.1















 3232
3232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









