







前言
我的需求是在做动画的时候由音频文件生成嘴型动画,免去做口型的K帧的工作量。在考察了一些技术后,我发现,如果能让算法从音频文件生成音素序列或者blendshaps权重系数序列是比较符合我需求的。离线在线都行,我不需要实时。
声音驱动人脸的比较出名的应该是英伟达的Audio2Face,这个方案生成的是Audio2Mesh,不是blendshaps。输出表情分量(blendshapes)权重比较易用的开源方案应该是谷歌基于MediaPipe做的方案了,可惜是基于视频驱动的,也就是要有人把台词演一遍,使用录像来生成blendshapes。
而我的需求比较明确,就是使用语音来驱动嘴型。考虑到我在这方面没什么技术积累,我选在从语音分析音素,使用音素来找对应嘴型。查找资料后发现共振峰分析是寻找元音音素的一种简单方法,在要求不高的动画场景下是可以用满足需求的。
元音与共振峰
元音就是发音时声带震动并且气流不受明显阻碍的发音。这种发音的能量较高,而且持续过程频率相对稳定。临近的辅音会向元音的频率和口型靠拢。所以元音的口型完全可以作为动画的关键帧。
元音的可以用共振峰来区分。根据网上资料,动画领域主要用5-7个基本的元音来制作口型。它们的共振峰分布如下:
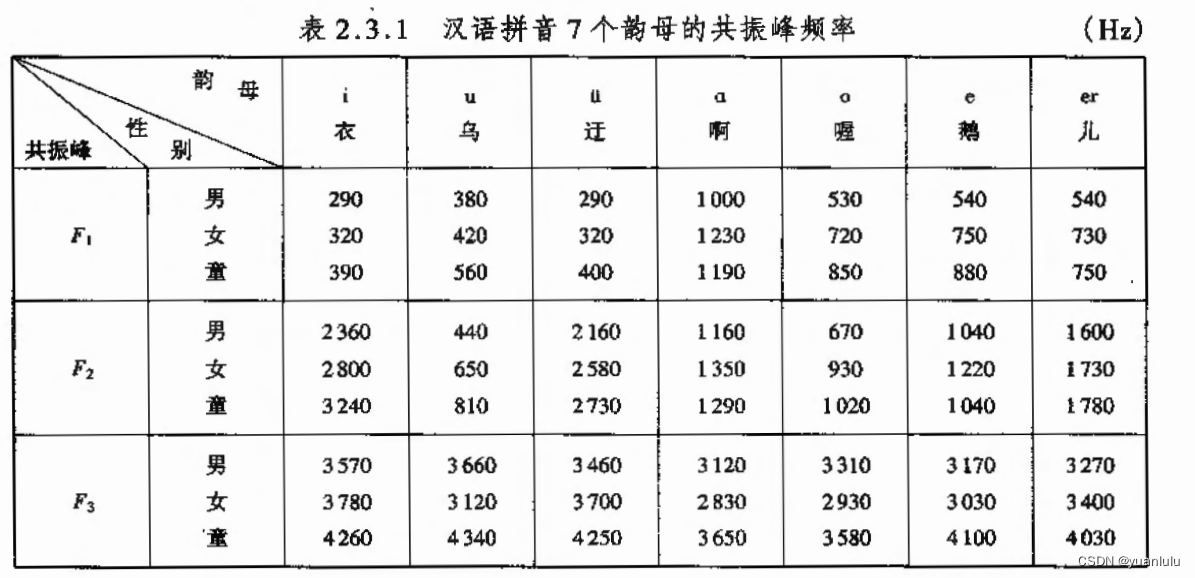
有些地方使用“a\o\e\i\u”这五个元音的口型就够了,有些还会更多些,我按照简单的情况来处理,即只识别前2个共振峰,来区分“a\o\e\i\u”这5个元音。
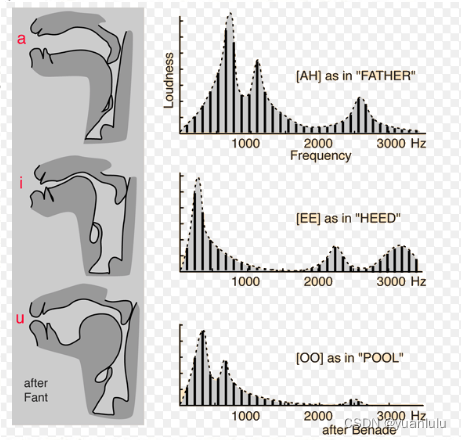
python分析共振峰提取音素的工具
如果数学好,完全可以通过numpy和scipy来计算共振峰。而我自己对声学几乎不懂,信号分析的技能也早忘了,看了几天不得不承认自己写不出来。
好在有librosa这样的python库专门处理语音信号,但是语音的前后处理我也不熟悉,只能找人家开源的代码哪来测试。搜索比较后,我发现一份实现质量比较高的代码:https://github.com/zlzhang1124/AcousticFeatureExtraction
看介绍作者是中科大的一位博士,非常感谢这位同学。这个项目是他使用Librosa音频处理库和openSMILE工具包写的声学特征提取库。其中就包含了用librosa对共振峰的提取。另外说一声,开源声学工具Praat也可以提取共振峰。
代码
我将AcousticFeatureExtraction项目中的acoustic_feature.py做了简化,只保留了提起共振峰的代码。代码如下:
import librosa
import numpy as np
from scipy.signal import lfilter, get_window
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
def func_format(x, pos):
return "%d" % (1000 * x)
class RhythmFeatures:
"""韵律学特征"""
def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming"):
"""
初始化
:param input_file: 输入音频文件
:param sr: 所输入音频文件的采样率,默认为None
:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同
:param n_fft: FFT窗口的长度,默认与窗长相同
:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz)
:param window: 窗类型,默认汉明窗
"""
self.input_file = input_file
self.frame_len = frame_len # 帧长,单位采样点数
self.wave_data, self.sr = librosa.load(self.input_file, sr=sr)
self.window_len = frame_len # 窗长512
if n_fft is None:
self.fft_num = self.window_len # 设置NFFT点数与窗长相等
else:
self.fft_num = n_fft
self.win_step = win_step
self.hop_length = round(self.window_len * win_step) # 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3
self.window = window
def energy(self):
"""
每帧内所有采样点的幅值平方和作为能量值
:return: 每帧能量值,np.ndarray[shape=(1,n_frames), dtype=float64]
"""
mag_spec = np.abs(librosa.stft(self.wave_data, n_fft=self.fft_num, hop_length=self.hop_length,
win_length=self.frame_len, window=self.window))
pow_spec = np.square(mag_spec)
energy = np.sum(pow_spec, axis=0)
energy = np.where(energy == 0, np.finfo(np.float64).eps, energy) # 避免能量值为0,防止后续取log出错(eps是取非负的最小值)
return energy
class Spectrogram:
"""声谱图(语谱图)特征"""
def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming", preemph=0.97):
"""
初始化
:param input_file: 输入音频文件
:param sr: 所输入音频文件的采样率,默认为None
:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同
:param n_fft: FFT窗口的长度,默认与窗长相同
:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz)
:param window: 窗类型,默认汉明窗
:param preemph: 预加重系数,默认0.97
"""
self.input_file = input_file
self.wave_data, self.sr = librosa.load(self.input_file, sr=sr) # 音频全部采样点的归一化数组形式数据
self.wave_data = librosa.effects.preemphasis(self.wave_data, coef=preemph) # 预加重,系数0.97
self.window_len = frame_len # 窗长512
if n_fft is None:
self.fft_num = self.window_len # 设置NFFT点数与窗长相等
else:
self.fft_num = n_fft
self.hop_length = round(self.window_len * win_step) # 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3
self.window = window
def get_magnitude_spectrogram(self):
"""
获取幅值谱:fft后取绝对值
:return: np.ndarray[shape=(1 + n_fft/2, n_frames), dtype=float32],(257,全部采样点数/(512*2/3)+1)
"""
# 频谱矩阵:行数=1 + n_fft/2=257,列数=帧数n_frames=全部采样点数/(512*2/3)+1(向上取整)
# 快速傅里叶变化+汉明窗
mag_spec = np.abs(librosa.stft(self.wave_data, n_fft=self.fft_num, hop_length=self.hop_length,
win_length=self.window_len, window=self.window))
return mag_spec
class QualityFeatures:
"""声音质量特征(音质)"""
def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming"):
"""
初始化
:param input_file: 输入音频文件
:param sr: 所输入音频文件的采样率,默认为None
:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同
:param n_fft: FFT窗口的长度,默认与窗长相同
:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz)
:param window: 窗类型,默认汉明窗
"""
self.input_file = input_file
self.frame_len = frame_len # 帧长,单位采样点数
self.wave_data, self.sr = librosa.load(self.input_file, sr=sr)
self.n_fft = n_fft
self.window_len = frame_len # 窗长512
self.win_step = win_step
# 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3
self.hop_length = round(self.window_len * win_step)
self.window = window
def formant(self, ts_e=0.01, ts_f_d=200, ts_b_u=2000):
"""
LPC求根法估计每帧前三个共振峰的中心频率及其带宽
:param ts_e: 能量阈值:默认当能量超过0.01时认为可能会出现共振峰
:param ts_f_d: 共振峰中心频率下阈值:默认当中心频率超过200,小于采样频率一半时认为可能会出现共振峰
:param ts_b_u: 共振峰带宽上阈值:默认低于2000时认为可能会出现共振峰
:return: F1/F2/F3、B1/B2/B3,每一列为一帧 F1/F2/F3或 B1/B2/B3,np.ndarray[shape=(3, n_frames), dtype=float64]
"""
_data = lfilter([1., 0.83], [1], self.wave_data) # 预加重0.83:高通滤波器
inc_frame = self.hop_length # 窗移
n_frame = int(np.ceil(len(_data) / inc_frame)) # 分帧数
n_pad = n_frame * self.window_len - len(_data) # 末端补零数
_data = np.append(_data, np.zeros(n_pad)) # 无法整除则末端补零
win = get_window(self.window, self.window_len, fftbins=False) # 获取窗函数
formant_frq = [] # 所有帧组成的第1/2/3共振峰中心频率
formant_bw = [] # 所有帧组成的第1/2/3共振峰带宽
rym = RhythmFeatures(self.input_file, self.sr,
self.frame_len, self.n_fft, self.win_step, self.window)
e = rym.energy() # 获取每帧能量值
e = e / np.max(e) # 归一化
for i in range(n_frame):
f_i = _data[i * inc_frame:i * inc_frame + self.window_len] # 分帧
if np.all(f_i == 0): # 避免上面的末端补零导致值全为0,防止后续求LPC线性预测误差系数出错(eps是取非负的最小值)
f_i[0] = np.finfo(np.float64).eps
f_i_win = f_i * win # 加窗
# 获取LPC线性预测误差系数,即滤波器分母多项式,阶数为 预期共振峰数3 *2+2,即想要得到F1-3
a = librosa.lpc(f_i_win, order=8)
rts = np.roots(a) # 求LPC返回的预测多项式的根,为共轭复数对
# 只保留共轭复数对一半,即虚数部分为+或-的根
rts = np.array([r for r in rts if np.imag(r) >= 0])
rts = np.where(rts == 0, np.finfo(np.float64).eps,
rts) # 避免值为0,防止后续取log出错(eps是取非负的最小值)
ang = np.arctan2(np.imag(rts), np.real(rts)) # 确定根对应的角(相位)
# F(i) = ang(i)/(2*pi*T) = ang(i)*f/(2*pi)
# 将以角度表示的rad/sample中的角频率转换为赫兹sample/s
frq = ang * (self.sr / (2 * np.pi))
indices = np.argsort(frq) # 获取frq从小到大排序索引
frequencies = frq[indices] # frq从小到大排序
# 共振峰的带宽由预测多项式零点到单位圆的距离表示: B(i) = -ln(r(i))/(pi*T) = -ln(abs(rts[i]))*f/pi
bandwidths = -(self.sr / np.pi) * np.log(np.abs(rts[indices]))
formant_f = [] # F1/F2/F3
formant_b = [] # B1/B2/B3
if e[i] > ts_e: # 当能量超过ts_e时认为可能会出现共振峰
# 采用共振峰频率大于ts_f_d小于self.sr/2赫兹,带宽小于ts_b_u赫兹的标准来确定共振峰
for j in range(len(frequencies)):
if (ts_f_d < frequencies[j] < self.sr/2) and (bandwidths[j] < ts_b_u):
formant_f.append(frequencies[j])
formant_b.append(bandwidths[j])
# 只取前三个共振峰
if len(formant_f) < 3: # 小于3个,则补nan
formant_f += ([np.nan] * (3 - len(formant_f)))
else: # 否则只取前三个
formant_f = formant_f[0:3]
formant_frq.append(np.array(formant_f)) # 加入帧列表
if len(formant_b) < 3:
formant_b += ([np.nan] * (3 - len(formant_b)))
else:
formant_b = formant_b[0:3]
formant_bw.append(np.array(formant_b))
else: # 能量过小,认为不会出现共振峰,此时赋值为nan
formant_frq.append(np.array([np.nan, np.nan, np.nan]))
formant_bw.append(np.array([np.nan, np.nan, np.nan]))
formant_frq = np.array(formant_frq).T
formant_bw = np.array(formant_bw).T
# print(formant_frq.shape, np.nanmean(formant_frq, axis=1))
# print(formant_bw.shape, np.nanmean(formant_bw, axis=1))
return formant_frq, formant_bw
def plot(self, show=True):
"""
绘制语音波形曲线和log功率谱、共振峰叠加图
:param show: 默认最后调用plt.show(),显示图形
:return: None
"""
plt.figure(figsize=(8, 6))
# 以下绘制波形图
plt.subplot(2, 1, 1)
plt.title("Wave Form")
plt.ylabel("Normalized Amplitude")
plt.xticks([])
audio_total_time = int(len(self.wave_data) / self.sr * 1000) # 音频总时间ms
plt.xlim(0, audio_total_time)
plt.ylim(-1, 1)
x = np.linspace(0, audio_total_time, len(self.wave_data))
plt.plot(x, self.wave_data, c="b", lw=1) # 语音波形曲线
plt.axhline(y=0, c="pink", ls=":", lw=1) # Y轴0线
# 以下绘制灰度对数功率谱图
plt.subplot(2, 1, 2)
spec = Spectrogram(self.input_file, self.sr, self.frame_len,
self.n_fft, self.win_step, self.window, 0.83)
log_power_spec = librosa.amplitude_to_db(
spec.get_magnitude_spectrogram(), ref=np.max)
librosa.display.specshow(log_power_spec[:, 1:], sr=self.sr, hop_length=self.hop_length,
x_axis="s", y_axis="linear", cmap="gray_r")
plt.title("Formants on Log-Power Spectrogram")
plt.xlabel("Time/ms")
plt.ylabel("Frequency/Hz")
plt.gca().xaxis.set_major_formatter(mtick.FuncFormatter(func_format))
# 以下在灰度对数功率谱图上叠加绘制共振峰点图
formant_frq, __ = self.formant() # 获取每帧共振峰中心频率
color_p = {0: ".r", 1: ".y", 2: ".g"} # 用不同颜色绘制F1-3点,对应红/黄/绿
# X轴为对应的时间轴ms 从第0帧中间对应的时间开始,到总时长结束,间距为一帧时长
x = np.linspace(0.5 * self.hop_length / self.sr,
audio_total_time / 1000, formant_frq.shape[1])
for i in range(formant_frq.shape[0]): # 依次绘制F1/F2/F3
plt.plot(x, formant_frq[i, :], color_p[i], label="F" + str(i + 1))
plt.legend(prop={'family': 'Times New Roman', 'size': 10}, loc="upper right",
framealpha=0.5, ncol=3, handletextpad=0.2, columnspacing=0.7)
plt.tight_layout()
if show:
plt.show()
# 调用声音质量特征,获取共振峰
quality_features = QualityFeatures("audios/audio_raw.wav")
fmt_frq, fmt_bw = quality_features.formant() # 3个共振峰中心频率及其带宽
# 绘制波形图、功率谱,并叠加共振峰
quality_features.plot(True)
print(f"fmt_frq.shape:{fmt_frq.shape}")
print(f"fmt_frq:{fmt_frq}")
代码最后获得的两个变量:fmt_frq, fmt_bw 。其中前一个变量表示共振峰的中心频率,后一个是共振峰的宽度。共振峰变量的形状是(3, 187),第一个维度表示3个共振峰,第二个维度是语音分帧的个数。该代码默认每帧含512次采样,在16K采样频率的音频中对应32ms的时间,时间帧步长是窗口的2/3,也就是512*2/3=341个采样点(21ms,16kHz)。两个相邻帧有 11ms左右的重合。
代码运行效果
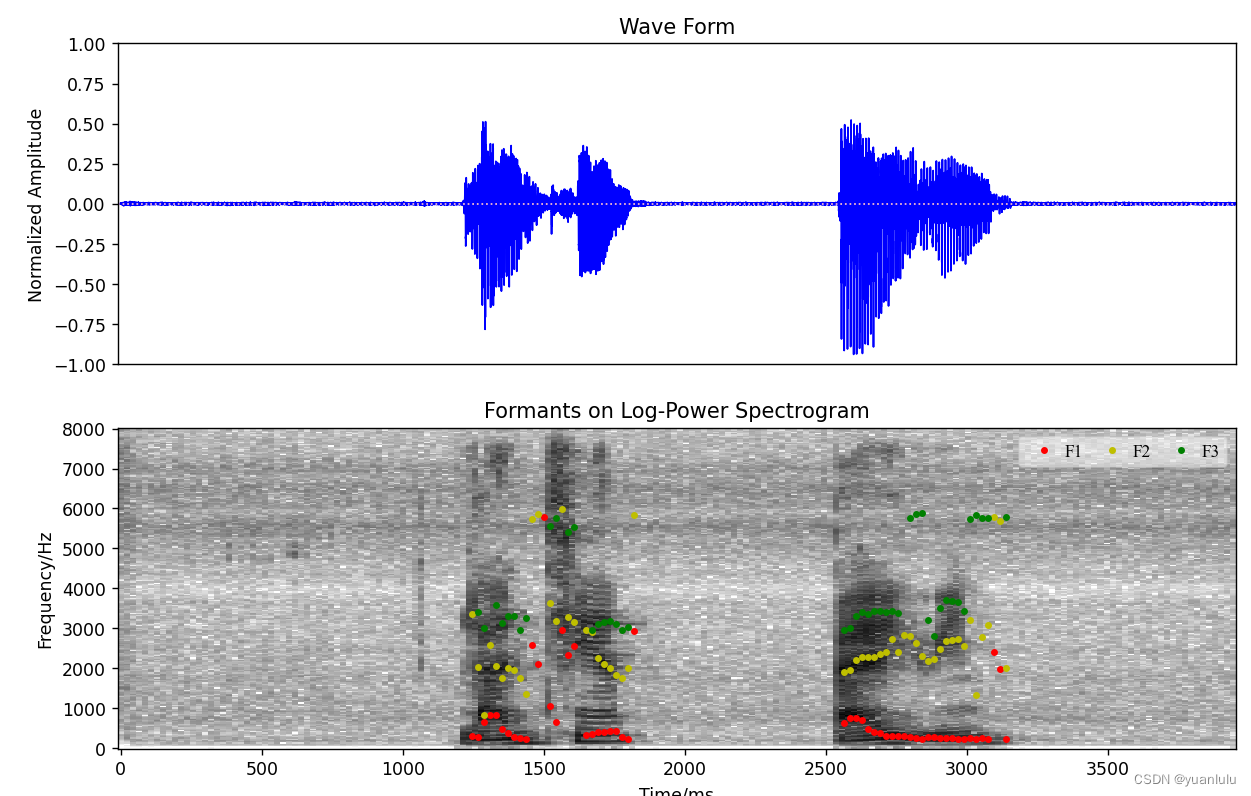
从matplotlib画出的语谱图和共振峰的叠加可以明显看出,声音在10~20ms内是比较平稳的。测试用的语音文件audios/audio_raw.wav是一个3.9秒多长的音频文件,里面的内容是汉语说的“蓝天、白云”这俩词,
下方图中的F1\F2\F3就是每个时刻的前3个共振峰。
终端输出为:
\testAudio> python.exe .\test.py
fmt_frq.shape:(3, 187)
fmt_frq:[[ nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan 295.4372654 281.46398512
643.08725603 828.75316361 835.10236184 469.64272051 361.60362711
261.06746809 253.78150682 224.23440054 2584.83912138 2110.27116893
5782.85560724 1045.922613 637.28375908 2960.14609412 2335.76678412
2544.88542653 nan 330.84780381 338.59204428 393.40544965
409.26523556 435.53623471 415.58251618 266.78135187 224.4345106
2927.82369207 nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
625.4384216 744.20278136 755.45704222 690.11319987 469.14109997
393.73415352 370.41417256 294.9946868 292.35913908 307.02051166
296.87615942 265.0965944 244.79459479 232.74200457 264.05691401
277.25767944 254.15531455 252.64240597 243.76628395 228.56500771
225.64808771 243.50021758 234.9380833 248.15770012 232.41377478
2415.6740718 1978.58991489 223.76912043 nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan]
[ nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan 3363.68235737 2021.6145788
831.44366031 2575.28046028 2064.21166609 1758.5357594 1995.84270031
1955.44390292 1755.93200822 1342.26492091 5723.72990562 5873.27687827
nan 3637.85724415 3169.38203909 5982.93665063 3283.31851878
3147.82956474 nan 2945.26859554 2892.40821315 2256.95576039
2114.84716553 1990.92601848 1819.63562926 1752.70830969 2009.41999548
5843.2076653 nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
1896.63386843 1956.50447695 2204.7404156 2282.51596933 2285.07575014
2279.51187706 2348.03325521 2390.82931201 2729.35034936 2395.17716454
2825.64012327 2816.54937968 2635.48981783 2297.76460039 2170.07770698
2219.48740582 2476.6785624 2677.65584371 2698.72924298 2723.86118608
2549.6561192 3209.49030793 1328.85985423 2777.06134543 3083.53097808
5790.8243976 5691.62823107 2014.59820987 nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan]
[ nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan 3415.02666762
3015.25865868 nan 3574.21619403 3119.62135428 3312.35189139
3313.13623142 2944.88536117 3251.29068546 nan nan
nan 5567.92371711 5750.25574261 nan 5406.873526
5531.17327367 nan nan 2957.28569092 3113.80571194
3143.1268893 3169.64744391 3095.28044073 2964.38836861 3038.83796034
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
2964.34820864 3002.727209 3308.51955426 3399.66106747 3346.62320663
3430.27527635 3428.80316423 3410.65949794 3436.0085123 3383.50158874
nan 5759.22372186 5858.85520446 5893.1610462 3196.25479081
2815.03764609 3511.05523645 3701.27881046 3675.98510793 3661.41315779
3420.77152166 5734.83426542 5844.07894149 5771.596685 5759.73389375
nan nan 5777.07014464 nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan nan nan nan
nan nan]]
测试用的语音文件audios/audio_raw.wav是一个3.9秒多长的音频文件,共63488个采样点,按照步长341个采样点(21ms,16kHz)来计算,约186帧。
代码中打印共振峰的形状是fmt_frq.shape:(3, 187),可能是补齐了一帧。














 5867
5867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









