深度学习论文笔记和实践
 关注
关注
 分享
分享
文章平均质量分 80
汇总自己在阅读深度学习论文笔记、研究神经网络模型和实践方面的文章
yuanlulu
做过嵌入式Linux开发、深度学习平台开发。擅长c++和python。
展开
-
transformer大语言模型(LLM)部署方案整理
大模型的基本特征就是大,单机单卡部署会很慢,甚至显存不够用。毕竟不是谁都有H100/A100, 能有个3090就不错了。目前已经有不少框架支持了大模型的分布式部署,可以并行的提高推理速度。不光可以单机多卡,还可以多机多卡。原创 2023-09-13 11:25:55 · 4639 阅读 · 0 评论 -
活体识别6:小视科技开源的静默活体检测
按照官方的说明,该方案是一个集成了俩小模型的方案,就是不知道俩小模型的侧重点。总的来说,开源这么一个可用的RGB单帧模型,很值得欣赏。原创 2023-02-02 18:08:14 · 2684 阅读 · 1 评论 -
活体识别5:论文笔记之FeatherNets
我觉得作者做了两件事,一件是通过“集成+级联”的方式拿到了比赛的好成绩,一个是设计了一个轻量级的人脸任务分类网络。这两件事不一定有特别大的关系。要是作者能把只用两个FeatherNet级联的结果写出来就更好了,这样才是一个更有针对性的论文。作为一个开发者,我打算用作者开源的FeatherNetBForIR试试效果。毕竟我只有NIR相机,没有深度相机。原创 2023-02-01 17:15:41 · 618 阅读 · 5 评论 -
活体识别4:论文笔记之《Face Spoofing Detection Using Colour Texture Analysis》
在和打印假脸、视频假脸的对比中,灰度图无法有效区分假脸,因为它们与真脸图片的相似度都比较高(距离小),而在YCbCr空间中,Cb通道和Cr通道中真脸图片和假脸图片相似度较低(距离大),有较明显的区分度。本文的出发点仍然没变,由于缺乏高频信息,假的人脸经过两个不同型号的相机成像和一次打印或显示,将会导致图像质量下降,而且复制的图像也会引入额外的噪声。这个论文是芬兰奥卢大学(Oulu)课题组的一篇很有代表性的论文,写于2016年,使用的是“手工特征+SVM分类器”这种比较传统的方案,方案不复杂,效果还不错。原创 2023-02-01 11:19:24 · 622 阅读 · 0 评论 -
活体识别3:论文笔记之《FACE ANTI-SPOOFING BASED ON COLOR TEXTURE ANALYSIS》
主要思路就是使用一篇参考文献里描述的LBP特征来提取人脸的color-texture信息,该文献中最终的LBP直方图是由各个色彩通道的LBP直方图组合起来形成的。作者在论文里说,HSV和YCbCr两个色彩空间的特征合并后得到的直方图尺寸是59x3x2,所以可以推测,作何使用的直方图灰阶的数量是59,而不是256。这个论文是芬兰奥卢大学(Oulu)课题组的一篇很有代表性的论文,写于2015年,使用的是“LBP特征+SVM分类器”这种比较传统的方案,方案不复杂,效果还不错。本文的活体检测方法如图 2 所示。原创 2023-02-01 10:42:36 · 586 阅读 · 1 评论 -
活体识别2: 综述类资源收集
19年的文章,把传统机器学习的方案和深度学习的方案都介绍了,简单易懂。原创 2023-01-31 10:28:13 · 568 阅读 · 0 评论 -
活体识别1:近红外(NIR)图像特性
第一行从左到右分别为近红外光下的真实人脸、打印黑白人脸以及打印彩色人脸,第二行为相同情况下的可见光成像图。通过图4可以看出,在近红外光下真实人脸能够保留较为完善的边缘轮廓信息,而打印照片的边缘信息丢失较为严重,同时可以看出在近红外下真实人脸的对比度比打印人脸高。来自:[1]隋孟君,茅耀斌,孙金生.基于近红外图像特征的活体人脸检测[J].自动化与仪器仪表,2021(09):25-29.最近在接触活体识别,在网上找到一个介绍近红外光(NIR)特性的论文,我简单做个笔记。原文的全文在文末参考资料里。原创 2023-01-31 09:43:29 · 3473 阅读 · 0 评论 -
onnx模型输入输出维度修改
费了半天劲搭环境,解决onnx转换过程的各种问题,最后发现rknn-toolkit2-v1.3不支持onnx的hardswish算子,白干了。最后,在rknn-toolkit-v1.7环境下将ckpt固化为pb文件,拷贝到rknn-toolkit2-v1.3下,再转换为rknn成功。可以看到右侧inputs和outputs的信息,第一个维度都是无效的,所以我需要把他们固定为1,因为我本来也不需要批量推理。代码运行输出(unk__207和unk__208应该是引起上述保存的原因,改了它们就好了)原创 2022-10-27 20:01:41 · 4805 阅读 · 2 评论 -
人脸矫正方案收集
自己最近在嵌入式上用到了人脸检测和人脸对齐和矫正。这里收集下最近接触的一些方案原创 2022-07-25 23:27:46 · 1760 阅读 · 0 评论 -
这就是神经网络 19:深度学习-人脸检测-S3FD
概述本文介绍1篇人脸检测方面的工作,这是2017年的工作。S3FD是SSD类的检测器,为人脸检测做了相应优化和修改。即使放在今年(2019),这个工作的结果也都是SOTA级的存在。前段时间写了文章总结FaceBoxes,那篇文章和本文的主角S3FD是同一个实验室出品的,都来自中国,并且在榜单中都取得了当时最好的成绩。动机论文一般都要先写出当前存在的问题,然后才好展开具体的方法。本文的动机就...原创 2019-06-24 18:21:10 · 2147 阅读 · 0 评论 -
深度学习-文档检测方案整理
概述这里梳理一下之前收集的几篇关于文档检测的文章,由于一些特殊的原因,最近可能都没机会去实践这些知识了,只能略读归纳一下。在识别纸质文档的第一步,一般首先要识别文档区域,也就是定位出文档4个角的坐标,然后拉伸文档区域,还原宽高比,接着后续的OCR流程。本文主要记录一些文档区域检测方面的文章。网易的方案网易的有道笔记用到了文档检测技术,主要信息披露自以下两篇博客:有道云笔记是如何使用T...原创 2019-06-20 16:40:25 · 3921 阅读 · 1 评论 -
视频安防“上帝视角“的畅想
畅想目前的视频安防手段主要还是记录不同角度的二维画面,实时(比如闯红灯抓拍)或事后分析处理。由于安防摄像头数量众多,安装角度和安装地点分散,很难对存量的巨大数量的视频录像做有效分析。目前很多安防视频平台正在利用深度学习的能力不断增强对视频解读的能力,但是效果基本就是类似去数据库里查某些字段,对普通一线的使用人员来说,这些视频分析手段存在一定的门槛,很难有一个简单的手段把大量的视频画面整合成一个整...原创 2019-06-17 22:40:25 · 1017 阅读 · 1 评论 -
这就是神经网络 18:深度学习-文字识别OCR-CRNN
概述在之前项目中用过CRNN做OCR,我在这里记录一下我对这个算法的理解,我没有对比代码去看,主要结合别人的博客略读论文。声明一下,主要参考了文末的《一文读懂CRNN+CTC文字识别》这篇文章,基本讲的非常易懂。另外,本算法的难点在于CTC的理解, 基本上参考文末的《Sequence ModelingWith CTC》这篇文章能够比较好的有个理解,参考资料里的另一篇博客《CTC算法详解》基本...原创 2019-05-15 21:34:42 · 12626 阅读 · 4 评论 -
项目实践中对语义分割网络DeepLabV3+的改进
概述最近用deepv3+做了一些语义分割的工作,从github上下载了别人实现的tensorflow实现。发现速度不能满足需求,所以本人对deepv3+做了一些改进。原始的网络结构下图左侧是DeepLabV3的结构,中间是U-Net风格的编解码结构,最右侧就是DeepLabV3+的结构。和V3相比,V3+融合了一次底层特征图(主干网络也换了,但是这里体现不出来)。改进方向替换backb...原创 2019-05-15 21:20:32 · 11276 阅读 · 15 评论 -
基于语义分割的身份证部件解析和文字检测
概述这个工作主要是利用人脸解析项目的算法,探索一下语义分割的功能。安排实习生利用合成的身份证照片进行了语义分割的标注。我的目的有两个:1.检测身份证上的信息是否齐全;2.确定身份证各文字信息的位置,把文字抠出来给OCR程序。基于opencv的算法之前写过一篇文章《python_opencv–身份证文字区域检测》,利用opencv的接口进行二值化,然后找出所有的阴影对应的外接矩形。这个方法...原创 2019-05-10 18:09:42 · 4990 阅读 · 9 评论 -
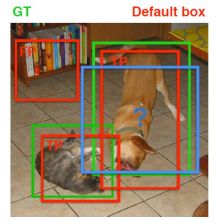
这就是神经网络 17:深度学习-评价指标_ROC_mAP
概述本文主要讲述目标检测指标mAP。主要也是自己做这块有段时间,但是这个指标一直没弄的特别清楚。而且网上很多博客写的并不准确,会给人不少舞蹈,希望自己的文章能帮到别人。基础知识true positive, false positive, true negative, false negative本段参考《目标检测的评价指标》,链接见最下方。首先解释一下上面四个词:分类正确的两类:t...原创 2019-05-08 20:45:46 · 9404 阅读 · 2 评论 -
自制人脸分割/解析数据集:helen_small4seg(附网盘下载地址)
概述我用原始的helen数据,挑选了部分标注比较好的图片,生成了一个规模较小的人脸解析/分割数据集,放在网盘上供大家下载。原始helen数据集介绍关于helen数据集的介绍,请参考我之前的博客:《人脸解析(Face Parsing)和人体解析Human Parsing:方法、数据集和论文》。helen数据集有2330张图片,每个图片有11个分类: Label 00: backgroun...原创 2019-05-03 17:58:16 · 7947 阅读 · 17 评论 -
目标检测中的检测框合并策略:NMS和Soft-NMS
概述目标检测中的Region Proposal动辄上千,会形成大量有重合的检测框,需要使用某些算法对检测框去重。常用的两种算法是NMS和Soft-NMS。NMS全称‘非极大值抑制(non maximum suppression)’.算法思想很简单,按照分类概率排序,概率最高的框作为候选框,其它所有与它的IOU高于一个阈值(这是人工指定的超参)的框其概率被置为0。然后在剩余的框里寻找概率第...原创 2019-05-02 17:00:40 · 6585 阅读 · 0 评论 -
这就是神经网络 16:深度学习-人脸检测-FaceBoxes
概述FaceBoxes是SSD类的检测器,为人脸检测做了相应优化和修改。即使放在今年(2019)也是SOTA级的存在。(本来打算把SSH、S3FD也一起总结了,但是最近时间比较紧张,先放FaceBoxes,另外两个后续再补)借用《人脸检测背景介绍和发展现状》里的一张图:FaceBoxesFaceBoxes是一个快速的人脸检测器。论文里贴的速度是VGA分辨率(640×480)在CPU上2...原创 2019-05-01 18:58:06 · 2161 阅读 · 0 评论 -
这就是神经网络 15:深度学习-人脸检测-MTCNN
概述MTCNN是一个基于级联卷积神经网络的人脸检测和人脸对齐算法。其英文题目《Joint Face Detection and Alignment usingMulti-task Cascaded Convolutional Networks》。本文原始的创意来自《A Convolutional Neural Network Cascade for Face Detection》,有人称它为...原创 2019-04-21 18:47:32 · 3997 阅读 · 1 评论 -
这就是神经网络 14:深度学习-目标检测-YOLOv1、YOLOv2、YOLOv3
YOLOYOLO是与SSD齐名的one_stage目标检测算法代表。SSD系列有比较多的变体,大部分都不是SSD作者做的工作。而YOLO目前已经进化到V3,据我所知都是yolo作者自己做的工作。网络结构由于yolo属于one_stage的目标检测算法,所以网络结构比较简单。固定输入448x448大小的图片,最后输出7x7x30大小的特征图。作者的主干网络受GoogLeNet的启发,共有...原创 2019-04-15 20:21:28 · 8367 阅读 · 1 评论 -
这就是神经网络 13:语义分割loss函数和评价指标
序最近刚刚完成自己规划的语义分割部分论文阅读,算是一个小结吧。语义分割的LOSS函数语义分割对像素的分类,可以用交叉熵作为loss函数。但是语义分割也有自己的特殊性,整个环面中前景物体有时会有较小的占比(比如医学图像中的病灶),这时需要加大前景(或缝隙)的权重,使训练过程更容易学到有用的特征。比如WBE Loss是U-Net引入的,对边界像素对应的loss加大权重,使之对边界更敏感。fo...原创 2019-04-02 21:04:27 · 4320 阅读 · 0 评论 -
这就是神经网络 12:深度学习-语义分割-DeepLabV1、V2、V3和V3+
概述说到语义分割,谷歌的DeepLab系列都是一个无法绕过的话题。目前这个系列共出了4个版本:V1、V2、V3和V3+。DeepLab是全景分割,也有DeeperLab原班人马在里面参与。本文主要关注DeepLabV3+和DeepLab。V1、V2作为前作,有一定的参考价值,但是我精力有限,这两篇主要从其它总结材料里学习而不是原论文,V3和V3+才是我的重点。一个系列看下来,感觉好漫长,半辈...原创 2019-03-31 16:31:20 · 4254 阅读 · 0 评论 -
这就是神经网络 11:深度学习-语义分割-DFN、BiSeNet、ExFuse
前言本篇介绍三篇旷视在2018年的CVPR及ECCV上的文章。旷视做宣传做的很好,出的论文解读文章很赞,省去了我从头开始理解的痛苦,结合论文基本能很快了解全貌。语义分割任务同时需要 Spatial Context 和 Spatial Detail ,也就是分类的语义信息和形状的空间信息。不同的网络从不同的角度解决这两个问题,做不同的妥协。DFN这是在CVPR2018上被接收的文章。DFN...原创 2019-03-24 20:24:29 · 7696 阅读 · 1 评论 -
这就是神经网络 10:深度学习-语义分割-RefineNet、PSPNet 、GCN
前言看论文写总结不易。喜欢就点个赞或者关注下。RefineNet这是16年底的论文,看完PSPNet和DeepLabV3+再回来看此论文,感觉乏善可陈。RefineNet给我的感觉就是一个resnet思想改造的U-Net,参数和计算量都大了很多。作者的一些trick没有很充分的对比实验来说明非此不可,我只能说本网络效果不错,但是谈不上多大的创新,也没耳目一新的见解,论文写的还不是很充分。说...原创 2019-03-15 21:21:43 · 4619 阅读 · 4 评论 -
人脸解析(Face Parsing)和人体解析Human Parsing:方法、数据集和论文
人脸解析人脸解析(Face Parsing)即把人脸的各个部分分割出来。下图左侧是原图,中间是标注,右侧是我输出的结果:这方面网上资料不多,论文也不火,很少看到商用的。目前看到华为有提供这个功能。华为人脸解析地址:https://developer.huawei.com/consumer/cn/hiai/engine/face-parsing人脸解析可预见的应用场景就是虚拟试妆,或者电...原创 2019-03-15 18:21:20 · 25392 阅读 · 5 评论 -
这就是神经网络 9:深度学习-语义分割-FCN、U-Net、SegNet
FCN简介FCN全称是‘Fully Convolutional Networks’,也就是全卷积网络。这个网络去掉了全连接层,网络结构里只有卷积(池化和反卷积)操作。本文的FCN特指这个语义分割网络,而非广义的全卷积网络。作者在论文里说,这是第一个可以端到端训练、输出像素级预测(pixels-to-pixels)语义分割网络,它可以处理任意大小的图片输入。本网络使用上采样层进行预测,使用降采...原创 2019-03-02 21:36:00 · 10455 阅读 · 0 评论 -
这就是神经网络 8:深度学习-目标检测-SSD和DSSD
前言最近有一篇综述目标检测的论文《Deep Learning for Generic Object Detection: A Survey》,来自首尔国立大学的 Lee hoseong 在近期开源了「deep learning object detection」GitHub 项目,正是参考该论文开发的。该项目集合了从 2013 年 11 月提出的 R-CNN 至在近期发表的 M2Det 等几十篇...原创 2019-02-24 17:55:20 · 2926 阅读 · 1 评论 -
卷积、反卷积和空洞卷积的图片示意
github上有一个项目用于演示各种卷积的动态过程:https://github.com/vdumoulin/conv_arithmetic下图是卷积操作:下图是转置卷积(反卷积):空洞卷积(扩张卷积):空洞卷积也有自己的缺点,需要设计一些精巧的组合来保证视野域能覆盖的比较紧密。具体参考下面的讨论:知乎讨论《如何理解空洞卷积(dilated convolution)?》:https...原创 2019-02-22 12:49:27 · 6265 阅读 · 0 评论 -
这就是神经网络 7:深度学习-目标检测-超详细图解Faster R-CNN
本文动机说实话,介绍Faster R-CNN的文章我看了很多,论文的英文原文和翻译都看过,我知道two-statge和anchor的主要思想,可是我脑子里始终没法建立一个完整的Faster R-CNN的框架,有太多的细节没有搞清楚,每个步骤的tensor是什么维度?这些维度是什么含义?第二阶段的坐标回归和第一阶段一样吗?有太多的细节让我疑惑不已。别人的文章讲的都是别人建立了整体概念以后的细节分解...原创 2019-02-06 21:43:28 · 7018 阅读 · 1 评论 -
这就是神经网络 6:SqueezeNet和Xception
概述之前也写博客介绍过轻量化神经网络架构:《集异璧-神经网络结构 5:轻量化神经网络–MobileNet V1、MobileNet V2、ShuffleNet V1、ShuffleNet V2》。但是那篇文章没有包含SqueezeNet和Xception。这次把这两个网络补上。SqueezeNet (2017)SqueezeNet 由伯克利&斯坦福的研究人员合作发表于 ICLR-2...原创 2019-01-28 22:01:16 · 2475 阅读 · 0 评论 -
超详细:自制yolo3训练数据集总结
概述本文总结yolo作者实现的darknet版本的yolo3训练数据集格式。数据集文件目录最终数据集需要3个文本文件和2个目录: train.txt # 文本文件,保存训练图片目录列表 test.txt # 文本文件,保存测试图片目录列表 class.names # 文本文件,保存分类名称 labels # 目录,保存每个图片的边界框和分类信息 ...原创 2018-12-25 21:54:05 · 9501 阅读 · 6 评论 -
这就是神经网络 5:轻量化神经网络--MobileNet V1、MobileNet V2、ShuffleNet V1、ShuffleNet V2
概述深度神经网络模型被广泛应用在图像分类、物体检测等机器视觉任务中,并取得了巨大成功。然而,由于存储空间和功耗的限制,神经网络模型在嵌入式设备上的存储与计算仍然是一个巨大的挑战。本文介绍几个经典的人工设计的轻量化神经网络模型。(当然也有其它方法对已有的网络模型进行压缩,甚至自动学习设计紧凑的网络模型,本文不涉及这部分)轻量化神经网络牵涉到的基础知识(如分组卷积、1x1点卷积、深度卷积(dep...原创 2018-12-06 23:59:38 · 9644 阅读 · 1 评论 -
这就是神经网络 4:ResNet-V1、ResNet-V2、ReNeXt、SENet
ResNet-V1(2015)ResNet在ILSVRC 2015分类任务上赢得了第一名。ResNet在主要是为了解决深度网络的退化问题。退化问题是指,随着网络深度的增加,准确率达到饱和(这可能并不奇怪)然后迅速下降。这并不是由过拟合引起的,因为训练准确率也下降了。考虑在一个浅层网络上增加恒等映射成为一个更深版本的网络,更深的模型不应当产生比它的浅层版本更高的训练错误率。作者的思路就是产生...原创 2018-12-05 21:05:25 · 8070 阅读 · 0 评论 -
这就是神经网络 3:NIN,Inception-V1,Inception-V2,Inception-V3, Inception-V4
NIN (2014)NIN全称是‘Network In Network’。这篇论文主要有两个改进思路:MLPconv和全局平均池化。MLPconv全称是multilayer perceptron convolution layer(直译为:多层感知机卷积层),也就是普通卷积层+1x1卷积+ReLU激活函数。NIN中的MLPconv是对conv+relu的改进,conv+relu构建的是一个一...原创 2018-12-03 21:18:22 · 4718 阅读 · 0 评论 -
这就是神经网络 2:VGG论文翻译(大部分)
概述非常喜欢VGG这篇论文,内容写的层层递进,逻辑严密。对多尺度及深度的探讨很经典。奈何别人的翻译十分拗口,总是感觉理解不透。只好自己反复阅读,把最精彩的多尺度及实验部分翻译一下。翻译过程尽量使用国人能懂的方式,宁愿以中国人的思维重写也不使用机器翻译的结果,过程中反复推敲,修改了部分啰嗦的定语和不易懂的表达方式。不喜欢‘我亲爱的老伙计‘、’你这该死的’这种假翻译。翻译就应该让人感觉不出这是翻...原创 2018-11-23 19:53:02 · 3260 阅读 · 1 评论 -
这就是神经网络 1:早期分类网络之LeNet-5、AlexNet、ZFNet、OverFeat、VGG
概述本系列文章计划介绍总结经典的神经网络结构,先介绍分类网络,后续会包括通用物体检测、语义分割,然后扩展到一些相对较细的领域如人脸检测、行人检测、行人重识别、姿态估计、文本检测等。一些经典网络的年代、性能及参数趋势如下表所示:LeNet-5 (1998)LeNet-5来自Yann LeCun在1998年的论文,这个网络用于识别手写数字。作者有个很出名的数据集MNIST,也是本论文用到的...原创 2018-11-21 18:13:52 · 4380 阅读 · 1 评论 -
深度学习中的组归一化(GroupNorm)
批归一化(BN)的缺点BN 需要用到足够大的批大小(例如,每个工作站采用 32 的批量大小)。一个小批量会导致估算批统计不准确,减小 BN 的批大小会极大地增加模型错误率。加大批大小又会导致内存不够用。归一化的分类BN,LN,IN,GN从学术化上解释差异:BatchNorm:batch方向做归一化,算N*H*W的均值LayerNorm:channel方向做归一化,算C*H*W的均值...原创 2018-11-17 17:45:48 · 16204 阅读 · 1 评论 -
深度学习中的Batch Normalization
动机我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要...原创 2018-11-17 16:09:28 · 420 阅读 · 0 评论 -
行人(客流)计数的一些底层技术
概述自己之前写过一篇文章介绍自己做的行人(客流)计数的工作:基于检测和多目标跟踪的客流统计功能小结这篇文章利用行人检测及多目标跟踪技术,对过边线的人数进行计数。检测和多目标跟踪我就不多说了,这里说一下如何进行过线检测。基本思想多目标跟踪会对每一帧的每个检测框赋予一个持续不变的ID,作为同一个目标的标识。同时,为了进行位置判断,我会把每个检测框抽象为一个点,比如将检测框上边缘的中心作为人的位...原创 2019-09-08 12:22:58 · 5596 阅读 · 8 评论