










数据读取概述
TensorFlow程序读取数据一共有3种方法:
- 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
- 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
目前我用过的主要是第一种,就是提供feed_dict来向计算图喂数据。第三种比较少用。
本篇博客主要讲第二种。
从文件读取的流水线
下图来自文末的参考资料《tensorflow数据读取》。
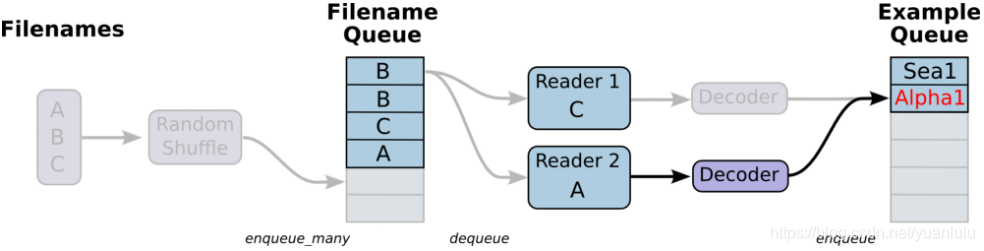
注意这个流水线有两个队列。一个是文件队列,由文件名生成。生成的时候可以指定乱序,长度可以长于文件个数(这时队列内就会有重复)。
第二个队列是读出的样本队列。
两个队列之间的部分由多个读取线程组成,每个线程包括reader、decoder、与处理组成。
注意:样本队列最终以计算图节点的形式接入计算图,计算图根据依赖自动去获取数据,不用手动喂了。
代码文件说明
tensorflow的开源例程里带了一个cifar10的分类的例子演示了上述数据读取的思想,代码在https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
包含以下几个文件:
| 文件名 | 说明 |
|---|---|
| cifar10.py | 构建计算图,包括inference、train、loss,同时返回了流水线读取数据的label和image节点。 |
| cifar10_input.py | 构建从文件读取数据的流水线 |
| cifar10_input_test.py | 测试cifar10_input.py中的reader |
| cifar10_train.py | 训练代码 |
| cifar10_multi_gpu_train.py | 多GPU训练代码 |
| cifar10_eval.py | 评估训练代码 |
cifar10_input.py: inputs分解
cifar10_input.py对外提供了两个接口:inputs和distorted_inputs。区别就是后者回对图像做一些随机翻转、裁剪、亮度调整等处理,相当于数据增广,前者原样返回。
def inputs(eval_data, data_dir, batch_size):
if not eval_data:
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
else:
filenames = [os.path.join(data_dir, 'test_batch.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
with tf.name_scope('input'):
# 1. 创建文件名队列
filename_queue = tf.train.string_input_producer(filenames)
# 2. 创建reader和decoder,增加图片预处理
read_input = read_cifar10(filename_queue)
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
height = IMAGE_SIZE
width = IMAGE_SIZE
# 将原本32*32的图片,转换为24*24
resized_image = tf.image.resize_image_with_crop_or_pad(reshaped_image,
height, width)
# Subtract off the mean and divide by the variance of the pixels.
float_image = tf.image.per_image_standardization(resized_image)
# Set the shapes of tensors.
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# Ensure that the random shuffling has good mixing properties.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(num_examples_per_epoch *
min_fraction_of_examples_in_queue)
# 3. 创建队列,按batch获取image和label
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=False)
这个函数可以分为三部分:
- 创建文件名队列,对上本文开头图片左边的部分
- 创建reader和decoder,增加图片预处理,对应开头图片两个队列之间的部分.这里有调用tf.image.per_image_standardization对图片归一化。
- 创建队列,按batch获取image和label, 对应开头图片最右侧的队列
最终要的是两处函数调用,即调用read_cifar10()和_generate_image_and_label_batch()
先看read_cifar10(),这个函数用于创建reader和decoder。
def read_cifar10(filename_queue):
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# 定义图片格式.
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
image_bytes = result.height * result.width * result.depth
# Every record consists of a label followed by the image, with a
# fixed number of bytes for each.
record_bytes = label_bytes + image_bytes
# Read a record, getting filenames from the filename_queue. No
# header or footer in the CIFAR-10 format, so we leave header_bytes
# and footer_bytes at their default of 0.
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(filename_queue)
# Convert from a string to a vector of uint8 that is record_bytes long.
record_bytes = tf.decode_raw(value, tf.uint8)
# The first bytes represent the label, which we convert from uint8->int32.
result.label = tf.cast(
tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
# The remaining bytes after the label represent the image, which we reshape
# from [depth * height * width] to [depth, height, width].
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[result.depth, result.height, result.width])
# Convert from [depth, height, width] to [height, width, depth].
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
注意这里用的reader是tf.FixedLengthRecordReader,用的decoder是tf.decode_raw。如果是别的格式的文件(如cvs),需要选择别的reader和decoder。这里返回的result各成员都是tensor,不是普通文件,需要运行计算图才能获得实际内容。每次读取一个样本,有意cifar10的文件是多个图片在一个bin文件里,下次会从上次读取的位置接着读。
另外一个重要的函数是_generate_image_and_label_batch(),它的任务主要是创建按batch获取图片的队列,需要上面创建好的result作为输入。
def _generate_image_and_label_batch(image, label, min_queue_examples,
batch_size, shuffle):
"""Construct a queued batch of images and labels.
Args:
image: 3-D Tensor of [height, width, 3] of type.float32.
label: 1-D Tensor of type.int32
min_queue_examples: int32, minimum number of samples to retain
in the queue that provides of batches of examples.
batch_size: Number of images per batch.
shuffle: boolean indicating whether to use a shuffling queue.
Returns:
images: Images. 4D tensor of [batch_size, height, width, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
# Create a queue that shuffles the examples, and then
# read 'batch_size' images + labels from the example queue.
num_preprocess_threads = 16
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)
# Display the training images in the visualizer.
tf.summary.image('images', images)
return images, tf.reshape(label_batch, [batch_size])
根据是否打乱顺序,这个函数会选择调用 tf.train.shuffle_batch()还是tf.train.batch() 返回两个tensor,一个是images和labels,数量就是传入的batch_size控制的。
cifar10_input.py:distorted_inputs分解
def distorted_inputs(data_dir, batch_size):
"""Construct distorted input for CIFAR training using the Reader ops.
Args:
data_dir: Path to the CIFAR-10 data directory.
batch_size: Number of images per batch.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# 1. 创建文件名队列.
filename_queue = tf.train.string_input_producer(filenames)
with tf.name_scope('data_augmentation'):
# 2. 创建reader和decoder,增加图片预处理
read_input = read_cifar10(filename_queue)
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
height = IMAGE_SIZE
width = IMAGE_SIZE
# Image processing for training the network. Note the many random
# distortions applied to the image.
# 随机裁剪
distorted_image = tf.random_crop(reshaped_image, [height, width, 3])
# 随机左右翻转
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 随机调整亮度和对比度
distorted_image = tf.image.random_brightness(distorted_image,
max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.2, upper=1.8)
# 标准化(减去均值像素除以标准差).
float_image = tf.image.per_image_standardization(distorted_image)
# Set the shapes of tensors.
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# Ensure that the random shuffling has good mixing properties.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN *
min_fraction_of_examples_in_queue)
print ('Filling queue with %d CIFAR images before starting to train. '
'This will take a few minutes.' % min_queue_examples)
# 3. 创建队列,按batch获取image和label
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=True)
可以看到,这个函数的整体流程和input基本一致,只是多了在decoder之后的预处理,对图像做了很多转换,起到数据增广的目的。















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









