






一,用途
其实逻辑回归是用来二分类的。根据数据的某几个特征来给对应的数据分类。例如人[身高,三围,体重]的三个特征来分类出人是胖还是瘦
二,理论推导
1,一个二分类的问题:
分类后的Y{0,1},特征值X(x1,x2,x3...xn)
如何找到一个模型让给出的X值求得分类的结果0或1?
2,找出某个函数来X->Y
如:Y=wX+b
但是这个函数求出来的Y值类似个一条线,很难达到0和1,所以这时引入一个函数:
3,Sigmoid函数
g(x)=
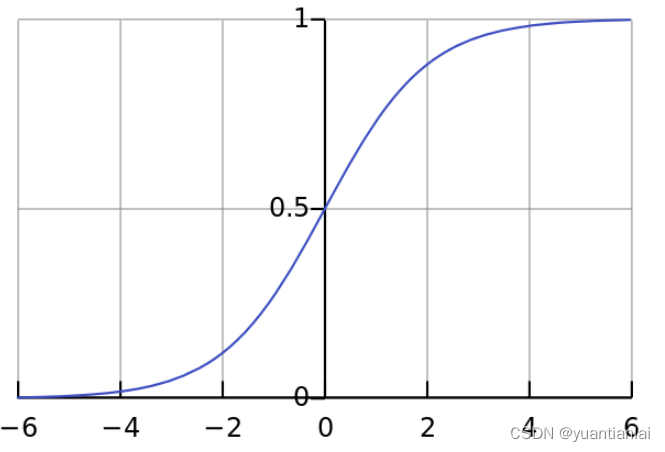
如图,能让我们的y值很好的得到分类(0和1)
4,将上述两个公式合二为一
公式一: 线性模型
公式二: 激活函数 sigmoid
则我们想要的y和x的关系如下:
转换后得
可推出:
5,极大似然估计
有:
其中i从0到k为1的概率,i从k+1到n为0的改了,上式也可改为
对他去对数(除以n防止梯度爆炸)并乘以-1(将求最大值转成最小值)
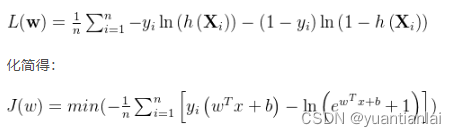
接下来就是求当上述公式为最小的时候的w值
6,正常有两种方式
法一:梯度下降法(一阶收敛)

停止迭代正常有两个方式
(1)设置最大迭代数
(2)设置阈值,如减少的值小于阈值则停止
法二:牛顿法(二阶收敛)
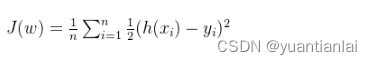

三,上述公式的代码实现
以kaggle里的数据集Dry_Bean_Dataset.csv 干豆数据集作为数据案例,在kaggle中难以下载的可点击 干豆数据集 下载
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv('Dry_Bean_Dataset.csv')
df = pd.DataFrame(data)
# print(df.columns,df.shape)
color=[]
label=[]
for i in df['Class'][0:3349]:
if i=='SEKER':
color.append('red')
label.append(0)
else:
color.append('blue')
label.append(1)
# plt.scatter(df['MajorAxisLength'][0:3349],df['MinorAxisLength'][0:3349],color=color)
# plt.xlabel('MajorAxisLength')
# plt.ylabel('MinorAxisLength')
# plt.show()
x1= df['MajorAxisLength'][0:3349]
x2= df['MinorAxisLength'][0:3349]
train_data = list(zip(x1,x2,label))
# print(train_data)
np.random.shuffle(train_data) #打散数据
# print(train_data)
alpha=0.001 # 学习率
circle=1000 # 学习次数
batchlen= 40 #3349个数据分成多份,每份的数据个数
w=np.random.normal(size=(3,1)) #初始化w
# print(w)
# np.random.shuffle(train_data) #打散数据
data=[train_data[i:i+batchlen] # 将数据分成多个batch
for i in range(0,len(train_data),batchlen)]
# print(data)
def sigmoid(x):
return 1/(1+np.exp(-x))
def train1(w):
for i in range(circle):
print('the {} epoch'.format(i))
for batch in data:
d_w = np.zeros(shape=(3,1)) # 用来承接w数据 最后学的数据
for j in batch:
x0= np.r_[j[0:2],1] #去除指标 并加个1 (个人理解:加的那个1就是对应的y值的位置)
# print(x0)
x=np.mat(x0).T #转会为列向量
# print(x)
y=j[2] #y值 就是标签值
# print(y)
dw=(sigmoid(w.T*x)-y)[0,0]*x # 梯度下降法(一介收敛)
# print(sigmoid(w.T*x)-y)
# print((sigmoid(w.T * x) - y)[0,0])
# print(dw)
d_w+=dw
w-=alpha*d_w/len(batch)
def train2(w):
for i in range(circle):
print('the {} epoch'.format(i))
for batch in data:
d_w = np.zeros(shape=(3, 1)) # 用来承接w数据 最后学的数据
for j in batch:
x0 = np.r_[j[0:2], 1] # 去除指标 并加个1 (个人理解:加的那个1就是对应的y值的位置)
# print(x0)
x = np.mat(x0).T # 转会为列向量
# print(x)
y = j[2] # y值 就是标签值
# print(y)
dw=((self.sigmoid(self.w.T*x)-y)*self.sigmoid(self.w.T*x)*(1-self.sigmoid(self.w.T*x)))[0,0]*x # 牛顿法 二阶收敛
# print(sigmoid(w.T*x)-y)
# print((sigmoid(w.T * x) - y)[0,0])
# print(dw)
d_w += dw
w -= alpha * d_w / len(batch)
#求得了w的值 就可以预测y值了
def predict(x,w):
s= sigmoid(w.T*x)
if s >= 0.5:
return 1
elif s < 0.5:
return 0
# 训练数据
w=train1(w)
# w=train2(w)
欢迎指正















 1649
1649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









