









HDFS HA
背景:
在hadoop2.0之前,HDFS集群中的NameNode存在单点故障(SPOF)对于只有一个NameNode的集群,若NameNode机器出现故障,则整个集群将无法使用,直到NameNode重新启动
- NameNode主要在一下两方面影响集群:
- NM机器发生意外
- NM机器需要升级
HDFS HA通过配置Active/Standby两个NM实现在集群中对NM的热备份来解决上述问题。
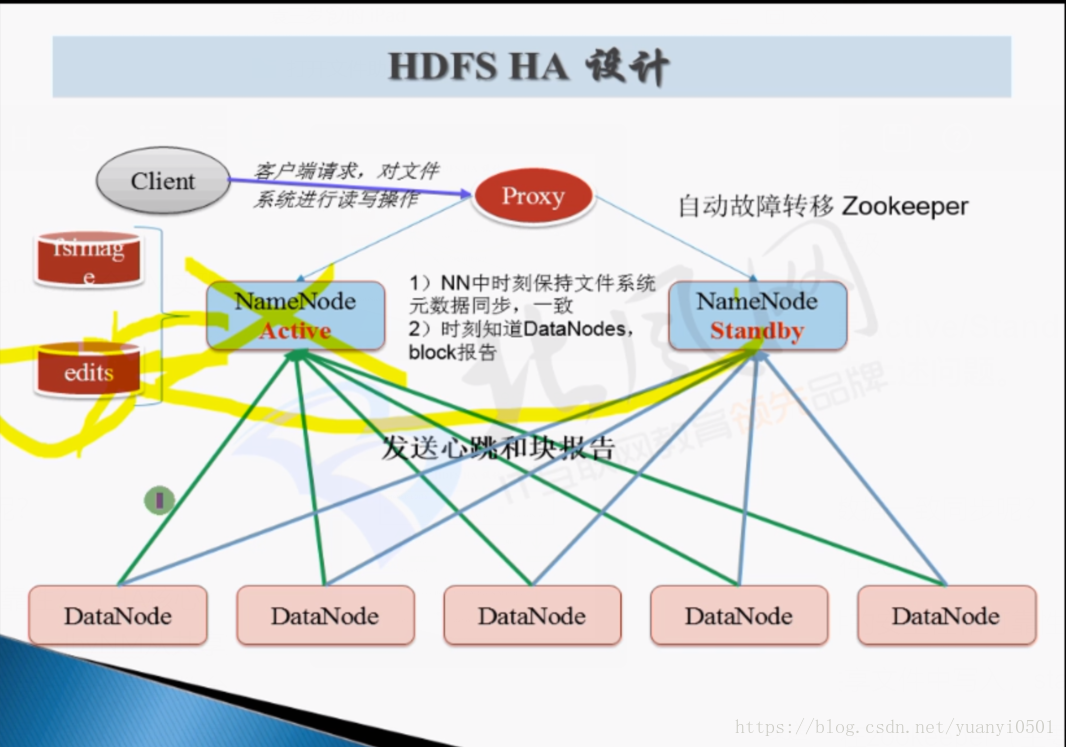
HDFS HA设计
配置HA要点:
- share edits
- journalNode
- NameNode(active、standby)
- client proxy
- proxy代理管理NM地址,客户端请求时,通过proxy去寻找active的NameNode
- fence 隔离
- 同一时刻仅仅有一个NM对外提供服务
- 使用sshfence
- 必须保证两个NM之间能够ssh无密码登陆
- 必须保证两个NM之间能够ssh无密码登陆
- 如何保证两个NM数据一致同步呢?
- 关键在编辑文件edits
- 如何保证edits文件的安全性和可靠性?(
- HA核心)
- activeNM往共享文件中写入,standbyNM从共享文件中读取
- 编辑日志存储在zookeeper(主要因为zk是基数台机器)的journalNode进程。如果有n个机器写入成功,则代表standbyNM可以去共享文件中读取。
- 如何保证两个NM不抢占工作?
- 配置NameNode隔离性

配置
规划集群
| . | hdp-node-01 | hdp-node-02 | hdp-node-03 |
|---|---|---|---|
| HDFS | NameNode | NameNode | |
| . | DataNode | DataNode | DataNode |
| . | JournalNode | JournalNode | JournalNode |
| YARN | ResourceManager | ||
| . | NodeManager | NodeManager | NodeManager |
| MapReduce | JobHistoryServer |
步骤:
- 准备环境(在之前分布式文件基础上修改)
- 先将之前分布式文件备份(每台机器)
- cp -r hadoop-2.5.0/ dist-hadoop-2.5.0
- mv hadoop-2.5.0/data/tmp/ dist-tmp
- mkdir hadoop-2.5.0/data/tmp
- hdfs-site.xml
- 先将之前分布式文件备份(每台机器)
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode RPC ADDRESS -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hdp-node-01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hdp-node-02:8020</value>
</property>
<!-- NameNode HTTP WEB ADDRESS -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hdp-node-01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hdp-node-02:50070</value>
</property>
<!-- NameNode SHARED EDITS ADDRESS -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp-node-01:8485;hdp-node-02:8485;hdp-node-03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/data/dfs/jn</value>
</property>
<!-- HDFS PROXY CLIENT -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- HDFS SSH FENCE -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0/data/tmp</value>
</property>
</configuration>
启动
- 将修改的配置文件同步到其他机器:
- scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml root@hdp-node-02:/opt/app/hadoop-2.5.0/etc/hadoop/
- scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml root@hdp-node-03:/opt/app/hadoop-2.5.0/etc/hadoop/
- step 1:启动三台机器的journalnode
- sbin/hadoop-daemon.sh start journalnode
- step 2:将nn1格式化,并启动
- bin/hdfs namenode -format
- sbin/hadoop-daemon.sh start namenode
- step 3:在nn2上,同步nn1的元数据信息
- bin/hdfs namenode -bootstrapStandby
- step 4:启动nn2
- sbin/hadoop-daemon.sh start namenode
- step 5:将nn1切换为active
- bin/hdfs haadmin -transitionToActive nn1
- step 6:在nn1上启动所有的datanode
- sbin/hadoop-daemon.sh start datanode
bin/hdfs haadmin命令:
- sbin/hadoop-daemon.sh start datanode
- -transitionToActive 使状态变成active
- -transitionToStandby 使状态变成standby
- -failover [–forcefence] [–forceactive]
- -getServiceState 查看状态
- -checkHealth
- -help
HA 自动故障转移
| . | hdp-node-01 | hdp-node-02 | hdp-node-03 |
|---|---|---|---|
| HDFS | NameNode | NameNode | |
| . | ZKFC | ZKFC | |
| . | DataNode | DataNode | DataNode |
| . | JournalNode | JournalNode | JournalNode |
| YARN | ResourceManager | ||
| . | NodeManager | NodeManager | NodeManager |
| MapReduce | JobHistoryServer |
- 启动以后都是standby
- 选举一个为active
- 监控
- ZKFC (zookeeper failoverController)
- ZKFC (zookeeper failoverController)
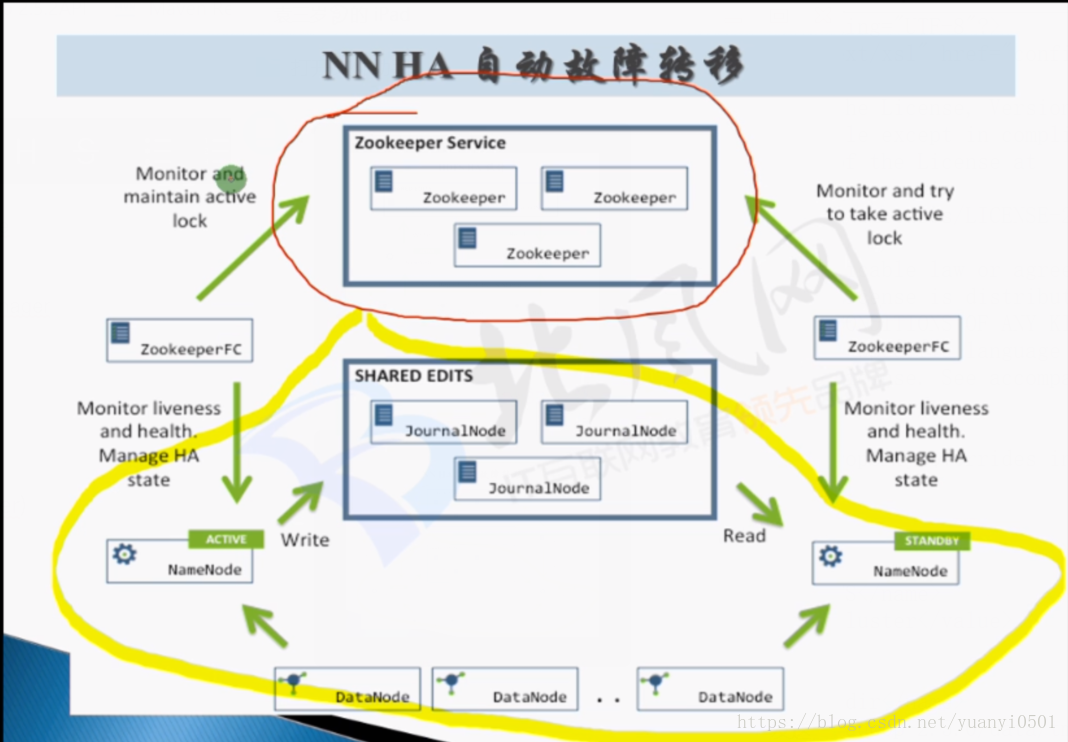
- 如果zkservice挂了会影响系统工作么?
-不会。zkfc相当于zk的客户端,是配置在HDFS上的
配置文件
- hdfs-site.xml
<!-- automatic failover -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
- core-site.sml
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp-node-01:2181,hdp-node-02:2181,hdp-node-03:2181</value>
</property>
启动
- 关闭所有的HDFS服务 sbin/stop-dfs.sh
- 同步配置文件
- 启动zk集群:bin/zkServer.sh start
- 初始化HA在zk中状态:bin/hdfs zkfc -formatZK
- 在zk中创建了 /hadoop-ha/mycluster文件
- 启动HDFS服务:sbin/start-dfs.sh

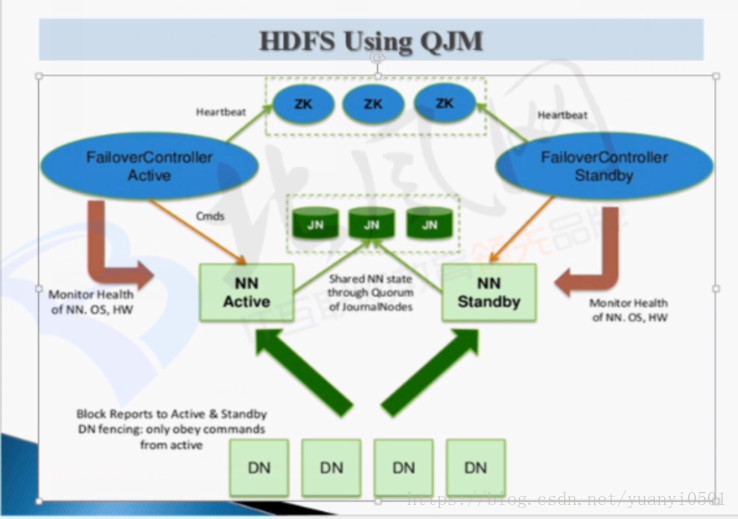
掌握下面的这张图:















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









