







梯度下降法是一种基于搜索的最优化方法,主要用于最小化损失函数,不太懂的,可以参考我的逻辑回归里面有使用梯度下降法。
所以,梯度下降法的目的是:找到损失函数的最小值
假设损失函数的图像如下
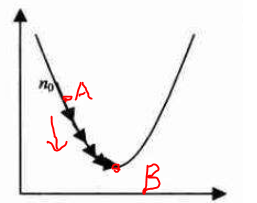
- 我们随机初始化一个点,比如A点,而我们的最低点在B点
- 我们想办法将A移动到B,然后得到B,但是大部分时候,我们不能通过求最小值获得
- 所以我们还可以借助于导数的概念,因为B正好在A点导数的方向,所以公式如下:
公式
A 1 A_1 A1 = A 0 A_0 A0 - η d J d A \frac{dJ}{dA} dAdJ
- A 0 A_0 A0 :表示当前这个点
- A 1 A_1 A1 :表示移动到下一个点
- d J d A \frac{dJ}{dA} dAdJ:表示 A 0 A_0 A0 点的导数(也就是梯度)
- η:称为学习率,他可以调节每次移动的大小
问题
局部最优解

- 可能出在C点,当A点移动到C点,就不再变化了
解决方案:
此时我们需要多尝试几个初始点,避免进入局部最优解
学习率太大


- 上面2种情况就是,学习率太大,导致不收敛
解决方案
- 根据实际情况,调整减小学习率
- 同样也有可能学习率过小,导致下降过慢,可以适当加大学习率
数据不在一个维度
特征中的数据,有的可能非常大,有的比较小,小的数据很快就收敛到最小值,但是大的数据却需要很长的时间才能收敛到最小值
解决方案
此时我们需要数据归一化,我们可以将数据映射到(0,1)之间或者均值归一化等方法
样本太多,计算耗时
上面的方法称为批量梯度下降法,在实际应用中,常常样本量比较大,比如:1000条或者以上。每次移动都会将所有样本带入计算,计算非常耗时,且不切实际。所有我们需要替代方法
解决方案
我们可以使用随机梯度下降法、Adam等方案替代,思路大致一致,有兴趣的可以查看我的博客优化器算法
代码
说了那么多,上个代码吧,使用了sklearn库!
随机梯度下降法
from sklearn.linear_model import SGDRegressor
sgd = SGDRegressor() # 初始化梯度下降法
time sgd.fit(X_train, y_train) #传入训练数据
sgd_reg.score(X_test, y_test) #测试数据评分
归一化方法
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
X_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









