






| 这个作业属于哪个课程 | https://bbs.csdn.net/forums/gdut-ryuezh |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/608092799 |
| 这个作业的目标 | 1. 学习对工程文件的性能分析和内存分析;2. 学习对工程进行单元测试;3. 学习PSP表格的制作。 |
| github地址 | https://gitcode.net/yudenggamer/cc6 |
目录
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 100 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 240 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 120 | 180 |
| · Code Review | · 代码复审 | 60 | 90 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 30 | 70 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 620 | 1270 |
二、计算模块接口的设计与实现过程。
1.读写 txt 文件的模块readwrite类
类:readwrite
方法1:readTxt:读取txt文件
方法2:writeTxt:写入txt文件
实现:调用 Java.io 包提供的接口,进行简单的文件读取写入
2.计算Hash值的Hash类
我们实现论文查重的方法是SimHash算法。
算法原理:1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重。
2、Hash,通过hash算法把每个词变成hash值。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。
5、降维。
详细算法:
import java.math.BigInteger;
import java.security.MessageDigest;
import java.util.List;
import com.hankcs.hanlp.HanLP; //注意!这个需要添加一个hanlp分词包。
public class Hash {
public static String getHash(String str){ //这个类是为了获得hash值
try{
MessageDigest messageDigest = MessageDigest.getInstance("MD5"); // 使用了MD5
return new BigInteger(1, messageDigest.digest(str.getBytes("UTF-8"))).toString(2);
}
catch(Exception e){
System.out.println("出错了。");
return str;
}
} //他就会“得到”这个分词的hash值
//注意此时!
public static String quanHash(String str){ //这个才会返回加权hash值
String simHash = "";
List<String> keywordList = HanLP.extractKeyword(str, str.length());//jar包派上用场,取出所有关键词
int size = keywordList.size();
int i = 0;
int[]b=new int[128];
for(String keyword : keywordList){
String keywordHash = getHash(keyword); //我们拿到了hash值
if (keywordHash.length() < 128) {
int a=128-keywordHash.length();
for (int j=0;j<a;j++) {
keywordHash +="0";
}
} //这个是为了防止不够128,补上0,本身没啥大不了的
//加权!
for (int j = 0; j < b.length; j++) {
if (keywordHash.charAt(j) == '0') // 他是一个字符串,我们0就是负
{
b[j] -= (10 - (i / (size / 10)));
}
else //1就是正,不是0就是1
{
b[j] += (10 - (i / (size / 10)));
}
}
i++;
}
//降维
for (int j = 0; j < b.length; j++) {
if (b[j] <= 0)
{
simHash += "0";
} else {
simHash += "1";
}
}
return simHash;
}
}
3.计算海明距离hamming类
方法一:getHammingDistance
用来计算海明距离
方法二:getSimilarity
用来计算相似程度,输出最后结果
都比较简单
public class hamming
{
public static int getHammingDistance(String simHash1, String simHash2) { //该算法用于计算海明距离,原理很简单,就是一个一个比较
int Ham=0;
int n=simHash1.length();
for (int i = 0; i < n; i++)
{
if (simHash1.charAt(i)== simHash2.charAt(i)) //charAt() 方法用于返回指定索引处的字符。索引范围为从 0 到 length() - 1。
{
Ham+=1;
}
}
return Ham;
}
public static double getSimilarity(String simHash1, String simHash2)
{
int distance = getHammingDistance(simHash1, simHash2);
return 0.01 * (100 - distance * 100 / 128); //相似度计算
}
}
4、main 主模块,cc主类
CC主类很简单,就是运用上面的模块
先输入两个txt文件的地址,他们是对比的两个文件
再输入你希望结果出现的txt文件
等待输出:程序运行完成,请检查结果吧!
就可以去查看结果了。
三、计算模块接口部分的性能改进
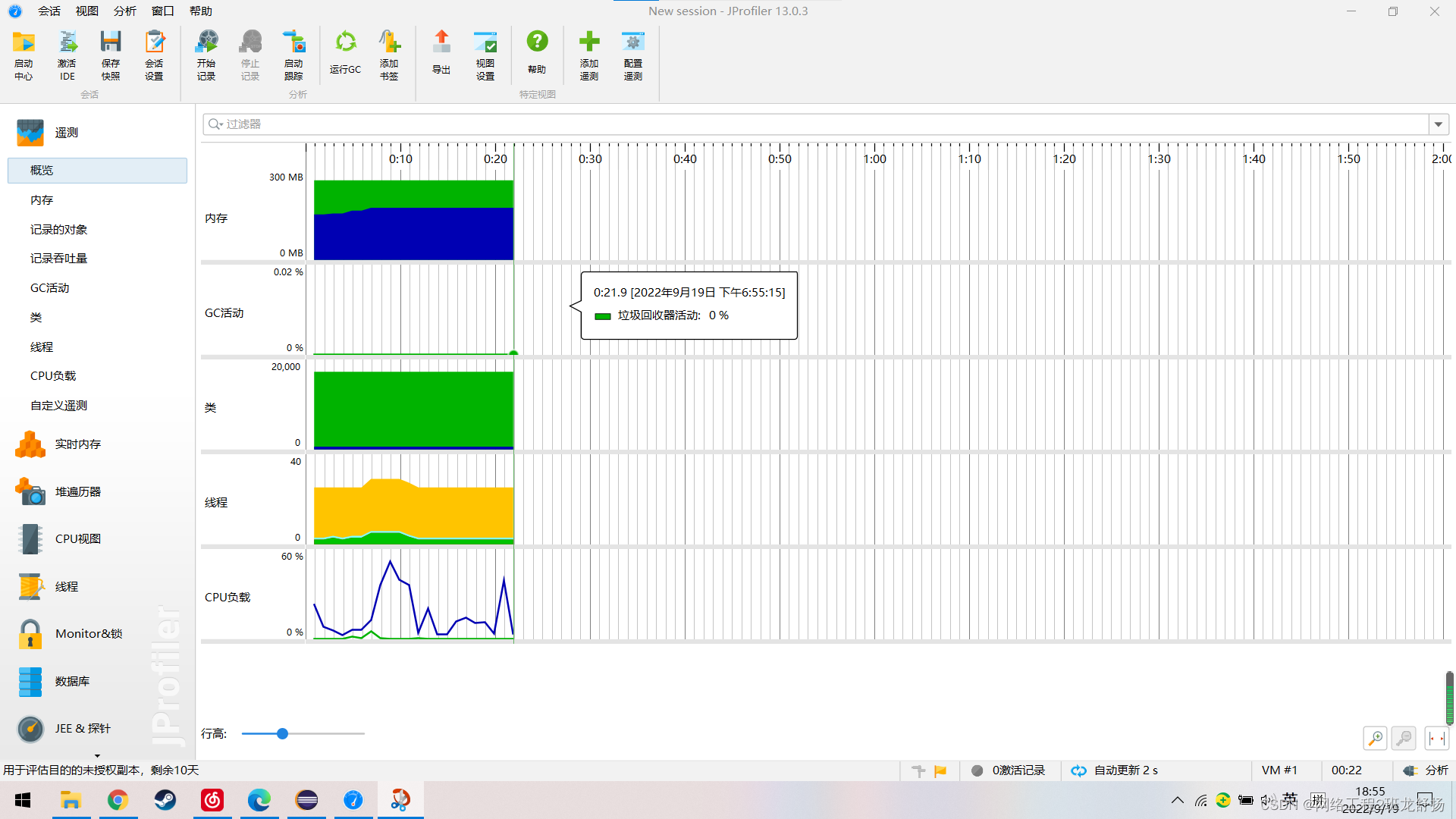

四、单元测试
注意,我是用eclipse测试的,因此这里又要加一个Jar包,Junit.jar。
1.Main类,cc类的测试Mainer类
public class Mainer {
public static void main(String[] args) {
String[] str = new String[7];
str[0] = readwrite.read("D:/test/orig.txt");
str[1] = readwrite.read("D:/test/orig_0.8_add.txt");
str[2] = readwrite.read("D:/test/orig_0.8_del.txt");
str[3] = readwrite.read("D:/test/orig_0.8_dis_1.txt");
str[4] = readwrite.read("D:/test/orig_0.8_dis_10.txt");
str[5] = readwrite.read("D:/test/orig_0.8_dis_15.txt");
str[6] = "D:/test/ak47.txt";
// 以上为从命令行输入的路径名读取对应的文件
String str0 = Hash.quanHash(str[0]);
String str1 = Hash.quanHash(str[1]);
String str2 = Hash.quanHash(str[2]);
String str3 = Hash.quanHash(str[3]);
String str4 = Hash.quanHash(str[4]);
String str5 = Hash.quanHash(str[5]);
// 由字符串得出对应的 simHash值
// 由 simHash值求出相似度
double similarity = hamming.getSimilarity(str0, str1);
readwrite.write(similarity, str[6]);
double similarity1 = hamming.getSimilarity(str0, str2);
readwrite.write(similarity1, str[6]);
double similarity2 = hamming.getSimilarity(str0, str3);
readwrite.write(similarity2, str[6]);
double similarity3 = hamming.getSimilarity(str0, str4);
readwrite.write(similarity3, str[6]);
double similarity4 = hamming.getSimilarity(str0, str5);
readwrite.write(similarity4, str[6]);
// 把相似度写入最后的结果文件中
System.out.println("程序运行完成,请检查结果吧!");
}
}
代码覆盖率


输出文件

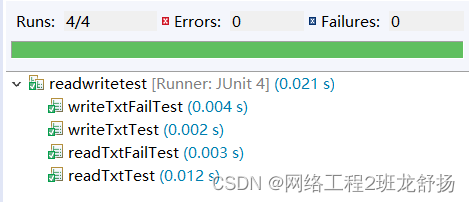
2.readwrite模块测试
import org.junit.Test;
public class readwritetest {
@Test
public void readTxtTest() {
// 路径存在,正常读取
String str = readwrite.read("D:/test/orig.txt");
String[] strings = str.split(" ");
for (String string : strings) {
System.out.println(string);
}
}
@Test
public void writeTxtTest() {
// 路径存在,正常写入
double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55};
for (int i = 0; i < elem.length; i++) {
readwrite.write(elem[i], "D:/test/ans.txt");
}
}
@Test
public void readTxtFailTest() {
// 路径不存在,读取失败
String str = readwrite.read("D:/test/none.txt");
}
@Test
public void writeTxtFailTest() {
// 路径错误,写入失败
double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55};
for (int i = 0; i < elem.length; i++) {
readwrite.write(elem[i], "User:/test/ans.txt");
}
}
}
代码覆盖率

3.Hash模块
import org.junit.Test;
public class HashTest {
@Test
public void getSimHashTest(){
String str0 = readwrite.read("D:/test/orig.txt");
String str1 = readwrite.read("D:/test/orig_0.8_add.txt");
System.out.println(Hash.quanHash(str0));
System.out.println(Hash.quanHash(str1));
}
}
代码覆盖率


4.Hamming模块
import org.junit.Test;
public class HammingTest {
@Test
public void getHammingDistanceTest() {
String str0 = readwrite.read("D:/test/orig.txt");
String str1 = readwrite.read("D:/test/orig_0.8_add.txt");
String str2=Hash.getHash(str0);
String str3=Hash.getHash(str1);
double i=hamming.getSimilarity(str2,str3);
}
}
代码覆盖率

五、计算模块部分异常处理说明
读取异常,我们直接抛出并且添加一个输出以提醒,程序读取出错了。
Hash模块也有同样的操作。
输出同理。
try{
file1 = new FileInputStream(file);
InputStreamReader read1 = new InputStreamReader(file1, "UTF-8");
BufferedReader read2 = new BufferedReader(read1); //将其转化为字符
while(true)
{
if((strLine = read2.readLine()) != null) {
str += strLine; //如果下一行不空,我们就读下去
}
else break;
}
read1.close();
read2.close();
file1.close(); //关闭资源
}
catch(IOException e)
{
System.out.println("文件读取出错,请检查你的输入");
}
六、总结
这次作业让我很清晰地认识到自己的不足,对项目开发缺乏经验,导致需要大量地查询很多没有学习过的资料,对这些资料的学习也耗费了大量的时间,而自己的Java程序开发的经验也仍有很大不足,编程速度比较慢,让我对自己目前的经验有了很深刻的理解。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









