







Authors
Yi-Fan Yan , Sheng-Jun Huang
Motivation
多标签学习(multi-label learning,MLL)是一种实用而有效的学习框架,适用于语义复杂的对象,每个实例可以同时与多个类标签相关联。但当输出空间远远大于单标签学到的信息时,通常需要一个大的标签数据集来训练一个有效的MLL模型。此外,当有大量候选标签时,多标签对象的注释成本可能非常高。主动洗就是一个很好的突破口,但是很多method没有关注label之间的correlation,特别是对于fine-grain的任务,从coarse到fine的知识学习。作者认为这种label的hierarchy中包含了非常多的信息,举例:label 一只dog比较容易,但是label一只 poodle就比较困难。
Contributions
- 提出了一种新的batch处理模式主动学习方法,利用标签层次结构进行cost-efficient的多标签分类。
- 提出了一种新的对实例标签包含信息性多少的估计准则,该准则不仅考虑了当前查询的有用性,而且考虑了查询后ancestor和descendant标签的潜在贡献。此外,允许层次树的不同级别的标签具有不同的注释成本。在每次迭代中,通过自动最大化instance的信息量,同时最小化整个注释成本来选择一批实例标签对。通过一个双向目标优化问题实现了成本效益的选择。
Method

首先定义,做一些formulation。作者先评估了instant-label里面包含的信息,然后提出了如果做selection的方法
Informativeness for Hierarchical Labels
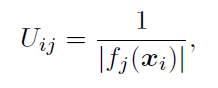 ,
,![]() 是样本,
是样本,![]() 是标签,
是标签,![]() 表明的是
表明的是![]() 样本经过model
样本经过model ![]() 之后评估出来是
之后评估出来是![]() 的相关性。因此,
的相关性。因此,![]() 和
和![]() 相关的时候,那么他们的ancestor也是呈相关的。如果
相关的时候,那么他们的ancestor也是呈相关的。如果![]() 和
和![]() 不相关,相应的,他们的descentant也是不相关的。 当然而作者认为单纯用这个方案并不能完全的evaluate到相关性,因此这对ancestor和descentant也应该贡献到当前
不相关,相应的,他们的descentant也是不相关的。 当然而作者认为单纯用这个方案并不能完全的evaluate到相关性,因此这对ancestor和descentant也应该贡献到当前![]() 和
和![]() 的相似度上去。因此每一对
的相似度上去。因此每一对![]() 和
和![]() 有两种情况需要讨论:
有两种情况需要讨论:
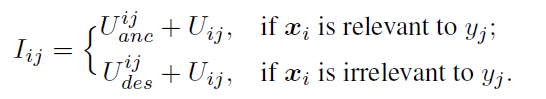 ,但是在query操作之前,我们是不知道的。作者因此,作者先使用K邻近算法对
,但是在query操作之前,我们是不知道的。作者因此,作者先使用K邻近算法对![]() 计算,然后用majority voting得到这一pair的相关性
计算,然后用majority voting得到这一pair的相关性![]() 。有:
。有:
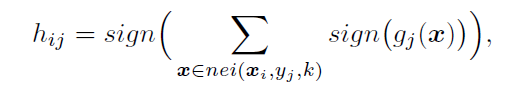 ,
,![]() 是k邻近。如果x是个打了标签的,那么
是k邻近。如果x是个打了标签的,那么![]() 就是标签y,如果x没打标签那么就是
就是标签y,如果x没打标签那么就是![]() 。计算当前结点的ancestor和descentant的uncertainty为,(细节就不写了,文章有)
。计算当前结点的ancestor和descentant的uncertainty为,(细节就不写了,文章有)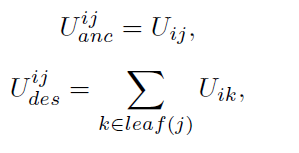
Cost-effective Selection
核心的计算为

















 2757
2757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









