







Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach
1、背景
1、作者(第一作者和通讯作者)
Wei Huang, Enhong Chen
2、单位
中国科学技术大学
3、年份
2019
4、来源
CIKM
2、四个问题
1、要解决什么问题?
以往的HMTC任务的研究大多采用分类器来同时处理所有类别,或者将原始问题分解为一组扁平的多标签分类子问题,忽略了文本与层次结构之间的关联以及层次结构不同层次之间的依赖关系。本文主要解决以上问题。
2、用了什么方法解决?
本文提出了一种新的基于层次注意力的递归神经网络(HARNN)框架
3、效果如何?
在两个真实数据集上的大量实验结果证明了HARNN的有效性和解释能力。
4、还存在什么问题?
论文笔记
1、INTRODUCTION
首先作者给出了HMTC受到了产业界和学术界的广泛关注
层次多标签文本分类(HMTC): 如下图,跟节点被认为0级,父节点比子节点更具一般性。它以一种优雅的方式展示了数据的特征,并以多维的视角通过层次结构来解决分类问题。

接着作者表示一些研究只关注范畴层次结构的局部区域或整体结构,而忽略了层次结构不同层次之间的依赖关系。
接着作者表明了层次多标签分类的问题:针对上图红色字更侧重于物理,蓝色字更多集中在C1类中的化学,而红色划线的字则更进一步描述C2中的核物理。图中文件D集中在C2核物理上,因为它的父类是C1中的物理,而C3中的核反应堆是核物理的一个子类。因此,如何预测每个层次的类别,同时准确地对整个层次结构中的所有类别进行分类是一个不平凡的问题。
最后,作者提出了自己所做的模型能够很好的解决上述问题。
2、RELATED WORK
2.1、Studies on HMTC
从最初的基于平面的方法,如:决策树和朴素贝叶斯;到分层支持向量机,到基于树的方法,再到神经网络的方法。作者指出这些工作主要集中在局部区域或范畴层次的整体结构上。此外,它们忽略了层次结构不同级别之间的依赖关系,这导致了错误传播和众所周知的类成员不一致。
2.2、Attention Mechanism
在文本分类中,注意力机制是通过赋予不同的权重来突出文本语义表示的不同部分的一种有效方法。在作者的框架中,最重要的步骤之一是自上而下、逐级揭示文本与层次结构中每个类别之间的关联,这与注意机制相关。
在前述工作中,注意力权重通常是通过文本与特定层次中每个类别之间的对应关系来计算的,这独立地对待层次结构的不同层次,从而忽略了不同层次之间的依赖关系。在这项工作中,我们提出了一种新颖的分层注意循环结构,从上到下逐步捕捉文本与每个类别之间的关联,整合了不同层次之间的依赖关系。具体地说,在层次化注意机制中,文本和每个类别的关注权重不仅受前一级别的影响,还会影响下一级别。
3、PRELIMINARIES
3.1、Problem Definition
定义1:Hierarchical Structure γ
C = (C1,C2,…,CH),其中C为为categories label集合,H为label的层级数量,Ci为第i层label的集合。
定义2:HMTC Problem
给定文档集合D,及相关的层级标签结构γ,HMTC问题可以转成学习一个分类模型Ω进行标签预测,即为:Ω ( D , γ , Θ ) → L
其中Θ为要学习的参数,Di={w1,w2,. . .,wN}为第i个文本,有N个序列词组成;对应Li= { l1,l2,. . . ,lH }为第i层标签集合。其实,文中解决HTMC任务场景是有一定限制的:对应输入的文本x来说,它在H层标签体系中,每层都是有标签的,而且每层标签的数量是1个或多个。
4、MODEL ARCHITECTURE
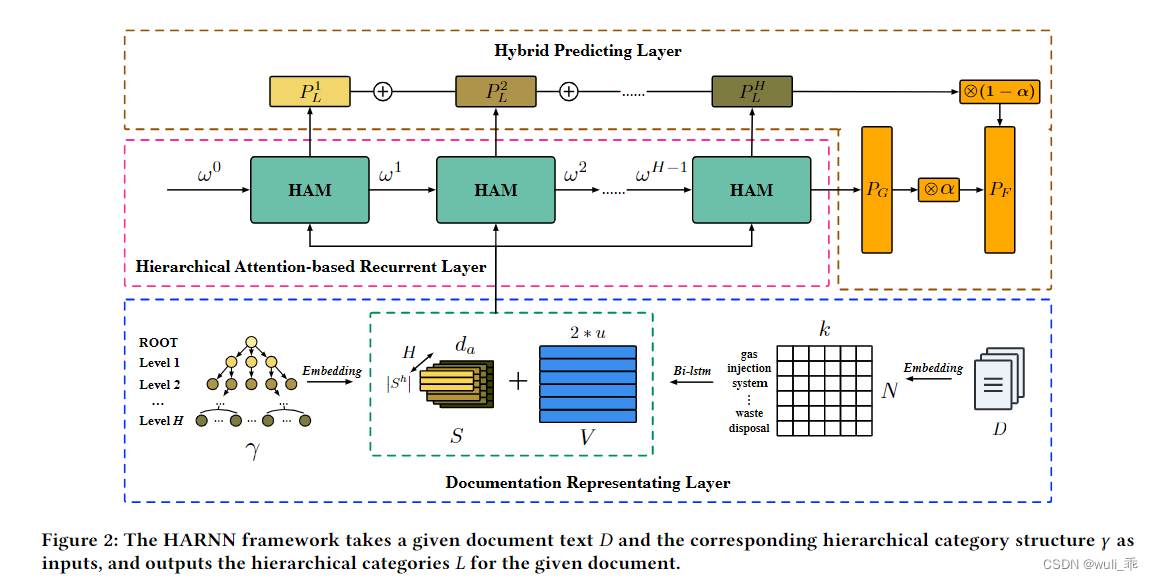
上图为论文的整体模型架构图,分为三层:(1)Documentation Representing Layer (DRL)——进行文本和层级标签的表征学习;(2)Hierarchical Attention-based Recurrent Layer (HARL)——使用注意力机制,让学习的文本向量和标签向量进行循环学习,交互;(3)Hybrid Predicting Layer (HPL)——混合方式进行标签预测。下面重点介绍这三部分内容。
4.1、Documentation Representing Layer
DRL的目标是生成文档文本的统一表示和层次类别结构
Embedding Layer:于对文本和层次类别结构进行编码。DRL接收文档D的文本标记和层次类别结构γ作为输入。
Bi-LSTM Layer:增强文本语义表示的编码。BI-LSTM不仅可以学习输入序列之间的长距离依赖关系,还可以同时学习前后向的上下文信息,这有利于增强文本语义表示的编码。
在文本表征上,先使用worde2vec获取词向量,然后使用Bi-LSTM网络进行表征学习,学习得到序列向量V = {h1,h2,…,hN} ∈ RNx2u。
在后续操作上,作者使用了基于词的平均池化操作(word-wise average pooling operation),将V变成 V ~ \widetilde{V} V = avg(h1,h2,…,hN)∈R2u。
在层级标签表征上,是使用lookup方式生成初始化矩阵标S = (S1,S2,…,SH)。
最后将表征学习到的V和S进行拼接,进入下一个layer进行学习。
4.2、Hierarchical Attention-based Recurrent Layer
这一层是论文核心的体现,其主要思想就是:将第一个layer学习的向量接入一个rnn网络,该网络的内部是HAM结构,而HAM在文中称为Hierarchical Attention-based Memory,意思就是基于attention的层级记忆单元。另外,这个循环网络的节点数应该就是标签的层级数,如数据集的标签有5个层级,那么这一层的rnn节点就为5,可以理解为一层接着一层进行递进式学习,像标签的层级结构一样。
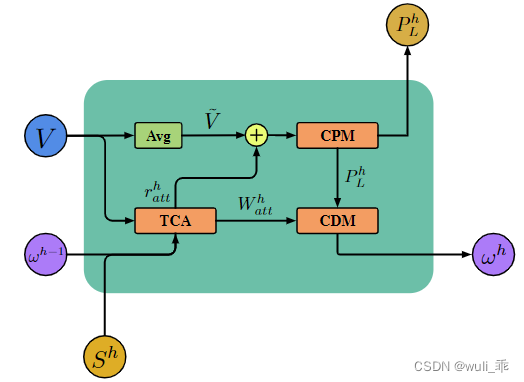
上图为HAM示意图,有点类似LSTM结构,其有三部分组成: Text-Category Attention (TCA),Class Prediction Module (CPM),Class Dependency Module(CDM),其计算公式为:
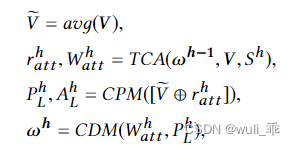
其中 r a t t h r^h_{att} ratth, W a t t h W^h_{att} Watth分别代表h-level层的文本与标签交互信息,与h-level层文本与标签交互的attention权重。
P L h P^h_L PLh, A L h A^h_L ALh别代表h-level层标签预测的概率,与h-leve层模型整体表征的信息。
ω h ω^h ωh为h层学习到的信息,作为记忆信息,进行传递学习用。
⊕表示向量连接运算
Text-Category Attention:目标是捕捉文本和类别之间的关联,并输出相关联的文本类别表示 r a t t h r^h_{att} ratth和在第h类别级别处的文本类别关注矩阵 W a t t h W^h_{att} Watth。其主要目标是让输入的文本与各层级的标签进行交互学习,使用的方法类似注意力机制

给定上一个类级别 ω h − 1 ω^{h-1} ωh−1∈ R N × 2 u R^{N×2u} RN×2u,我们将其与全文语义表示 V V V∈ R N × 2 u R^{N×2u} RN×2u相结合来生成 V h V_h Vh = ω h − 1 ⊗ V ω^{h-1} ⊗ V ωh−1⊗V。 V h V_h Vh是利用上一层的信息进行更新,可以理解接受上一层与label相关用的信息; ⊗ ⊗ ⊗表示入口式乘积操作。
O h , W a t t p O_h,W^p_{att}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









