







资料来源:台大 李宏毅 2020机器学习深度学习课程
目录
Recurrent Neural Network
Recurrent Neural Network == 循环神经网络
重点:有记忆!!!
Simple RNNLSTMGRU...
一、引入
我们知道智慧订票系统中有 Slot Filling 这种任务
例如,在“arrive Taipei at November 2nd”这个句子中找到destination和time of arrival这两个slot对应的词
destination:Taipei
time of arrival:November 2nd
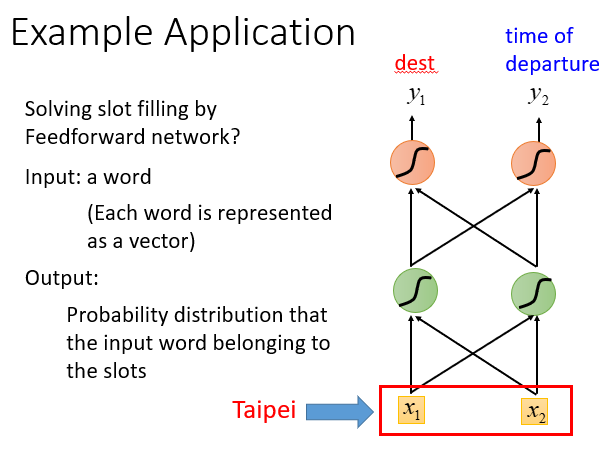
可以用前馈神经网络解决这个问题。
输入一个词对应的向量,输出这个词属于每个slot的概率分布
如输入Taipei,输出Taipei属于dest的概率、Taipei属于time of departure的概率
但是这样还不够!!!
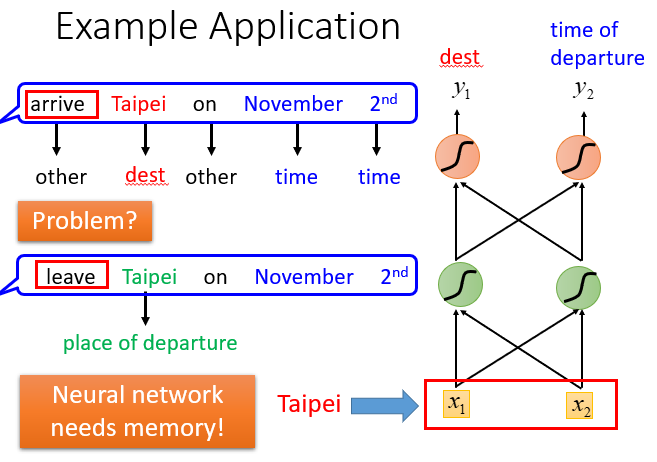
如果有蓝色框中的两个句子,第一个中的Taipei是destination,第二个中的Taipei是place of departure,但是对于前馈神经网络来说,输入同样的东西就会输出同样的东西。当我们输入Taipei时,要么都是destination的概率最高,要么都是place of departure的概率最高,也就是说区分不出它们的不同(没办法有时使出发地的概率大,有时使得目的地的概率大)。
所以神经网络需要 memory
二、RNN
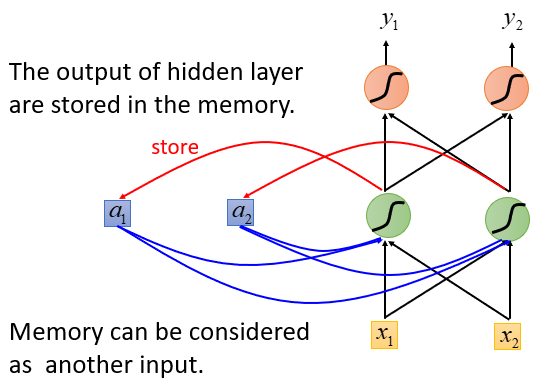
这种有记忆力的神经网络就是RNN
做法:
- 将隐藏层的输出存到memory中
- memory中的值会被作为另一个输入
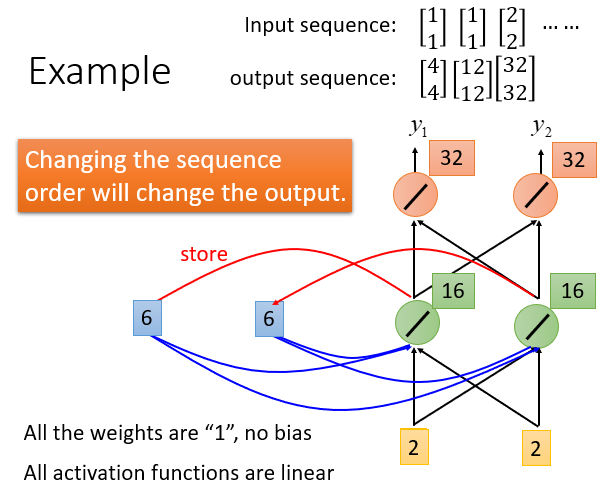
RNN Example
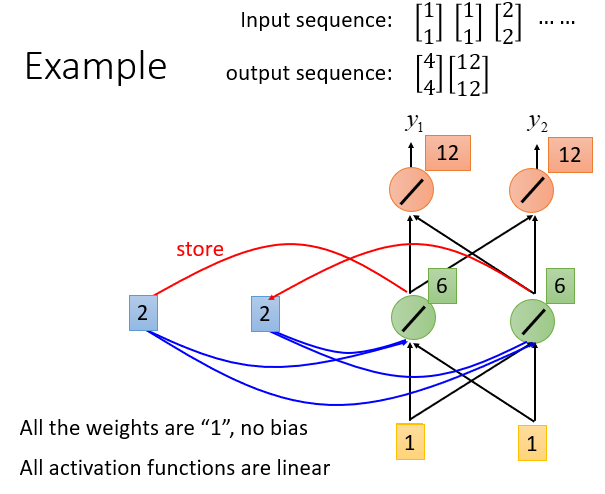
假设weight都为1,无bias,激活函数是线性的。
1.(左边图)设置memory的初始值是0.
首先输入[1 1],得到输出[4 4]
2.(中间图)将hidden layer的output存到memory中,此时memory是2.
接下来输入[1 1],此时输出[12 12].
(此时也可以看出给了相同的input[1 1],可能会得到不同的输出结果[4 4] 和 [12 12])
3.(右边图)将hidden layer的output存到memory中,此时memory是2.
接下来输入[1 1],此时输出[12 12].
最终得到输出序列[4 4] [12 12] [32 32]
改变输入值的顺序,输出也会改变

RNN获得的效果
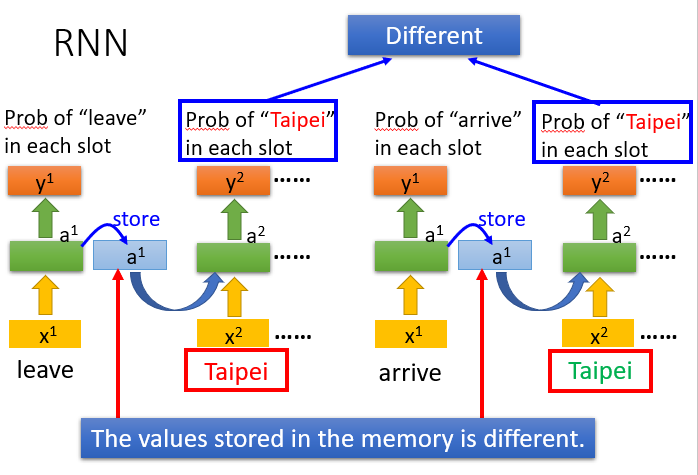
通过RNN后,arrive Taipei 和 leave Taipei 中的Taipei在每个slot中的概率不同
注意:下图中左边部分(或右边部分)是同一个network在不同的时间点被使用,而不是2个network
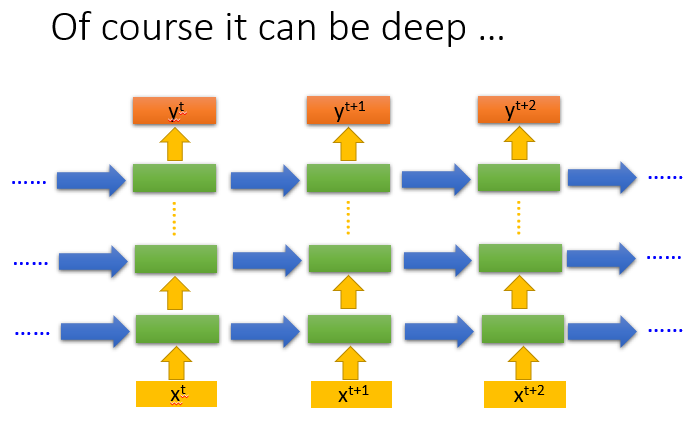
RNN也可以是deep的
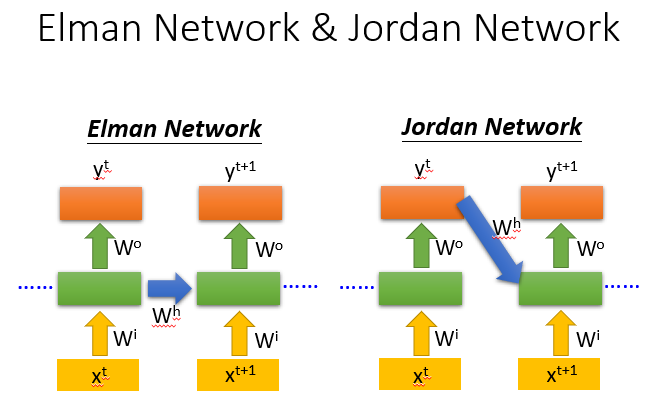
两种不同的RNN变形
上述讲的是Elman Network(将hidden layer的值存起来,在下一个时间点再读进来)
另外一种是Jordan Network(将output的值存起来,下一个时间点再读进来)
传说Jordan Network可以得到更好的performance
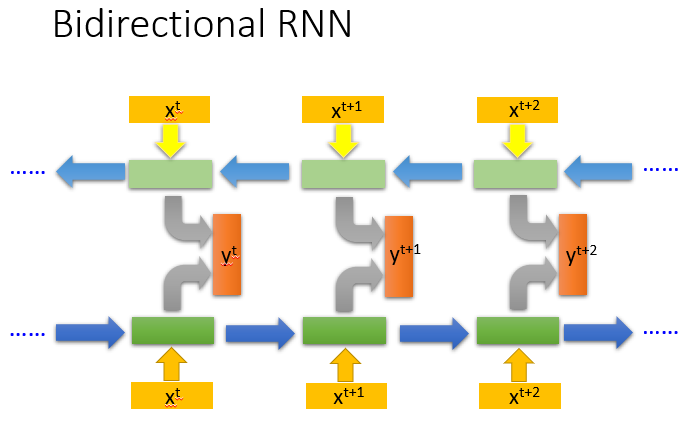
双向RNN
train一个正向的RNN同时train一个逆向的RNN,将两个方向的hidden layer拿出来,都接给一个output layer。
产生output时看得范围比较广,得到的效果好
类比:从 句首 读和从 句尾 读
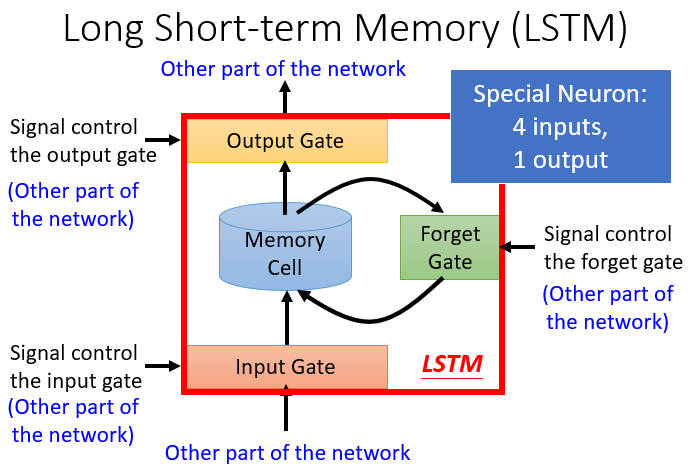
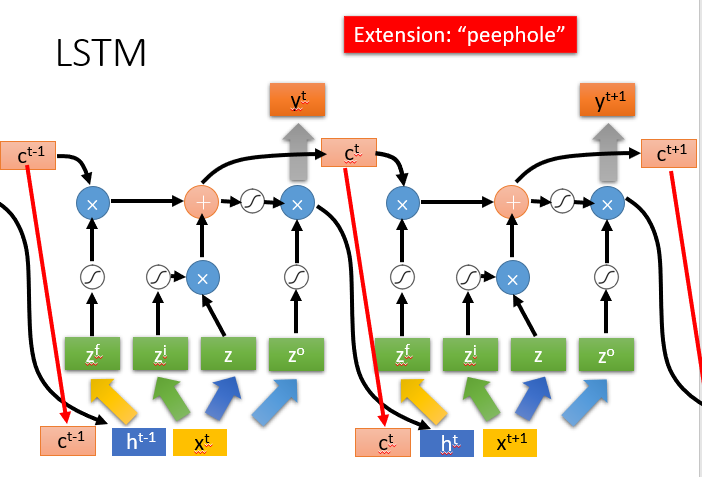
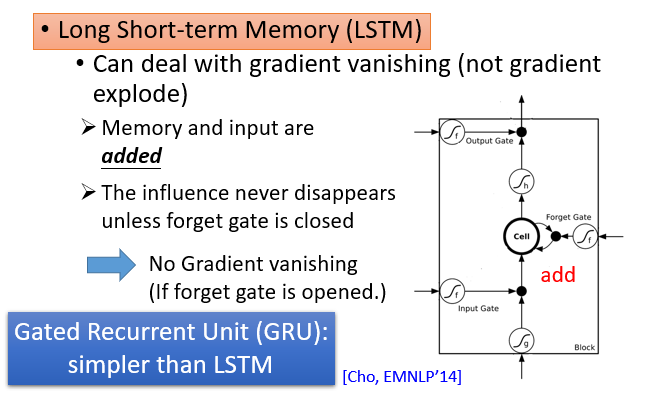
三、RNN变体——Long Short-Term Memory(LSTM)
长短期记忆网络LSTM
3个gate(Input Gate 、Forget Gate、Output Gate)- 当neural network 的输入想要写到memory中时,必须先要通过一个闸门Input Gate
- (当Input Gate打开时,才能将输入值写入memory cell中;当其关闭时,其他neuron无法写入值)
- 当Ouput Gate决定是否将memory cell中的值输出
- 当Forget Gate决定是否将memory cell中过去记忆的东西忘记
至于Input Gate处于打开还是关闭,是待神经网络学习的参数
普通的neuron: 1 input, 1 output
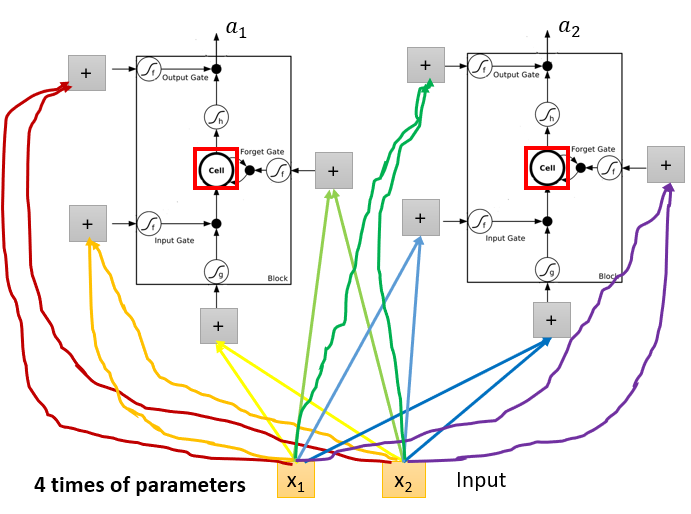
LSTM: 4 inputs, 1 output
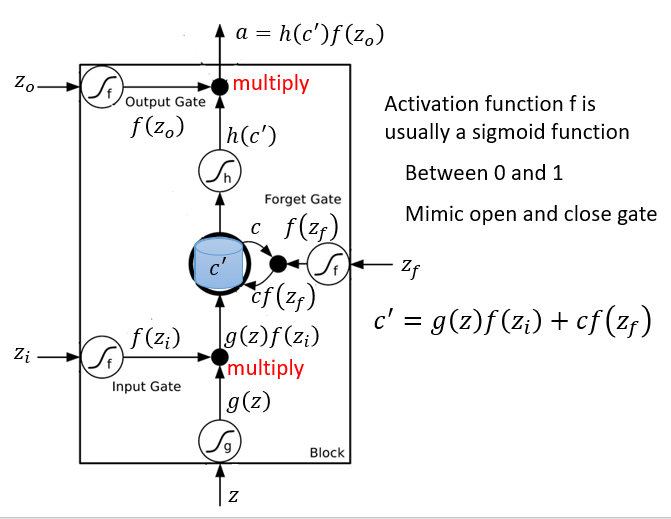
( Z i Z_i Zi、 Z f Z_f Zf、 Z o Z_o Zo都是标量,分别用来操控3个gate)
- f ( Z i ) = 1 f(Z_i) = 1 f(Zi)=1时Input Gate打开,允许输入值保存到memory
- f ( Z o ) = 1 f(Z_o) = 1 f(Zo)=1时Ouput Gate打开,允许memory中的值输出
- f ( Z f ) = 1 f(Z_f) = 1 f(Zf)=1时Forget Gate打开, 会保留memory中的内容; f ( Z f ) = 0 f(Z_f) = 0 f(Zf)=0 会清除memory中的值
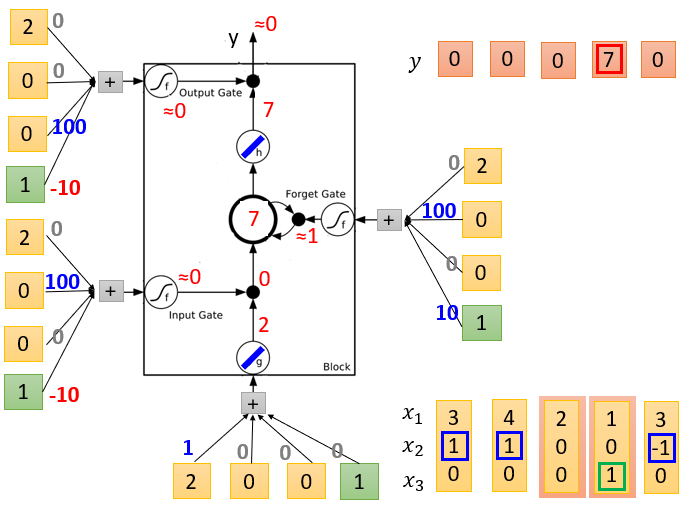
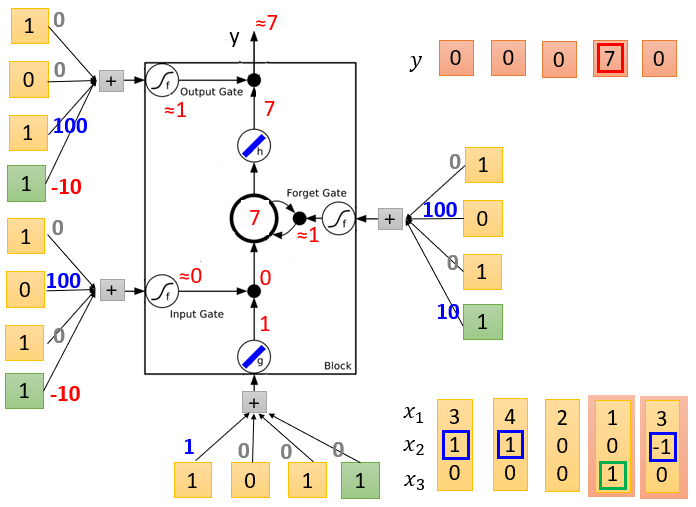
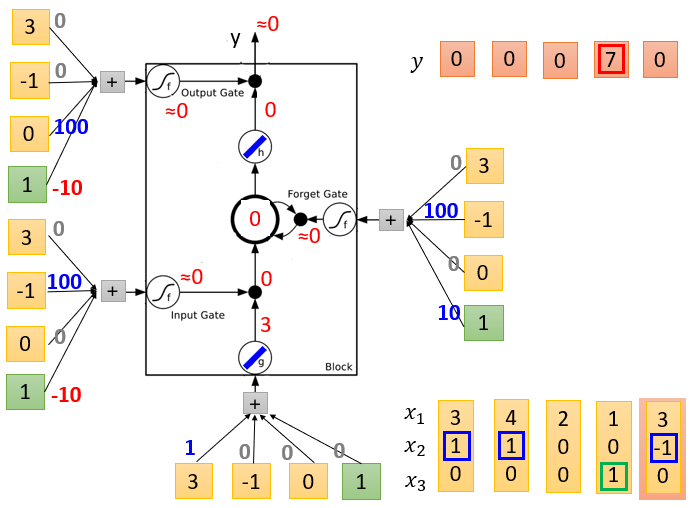
LSTM Example
图1是初始化,memory是0, 4个输入,假设对应的weight( 3 ∗ 4 3*4 3∗4个)和bias( 1 ∗ 4 1*4 1∗4个,绿色框对应的是bias)已经学习好了(标在图中)
图2表示输入[3 1 0 1]
图3表示输入[4 1 0 1]
(从左到右依次为图1、2、3)
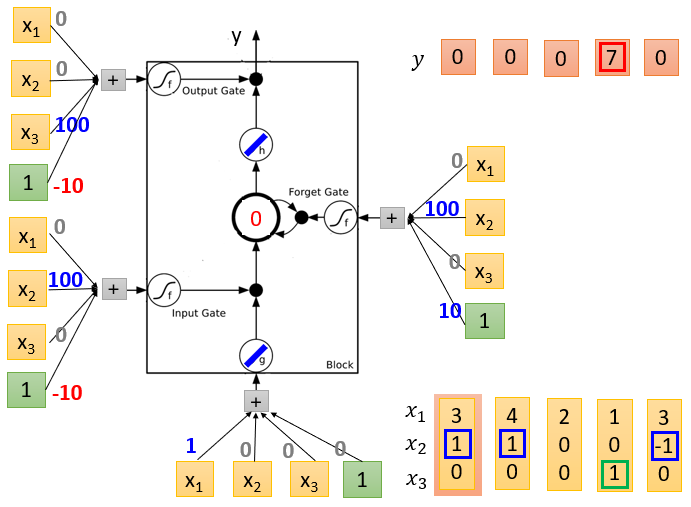

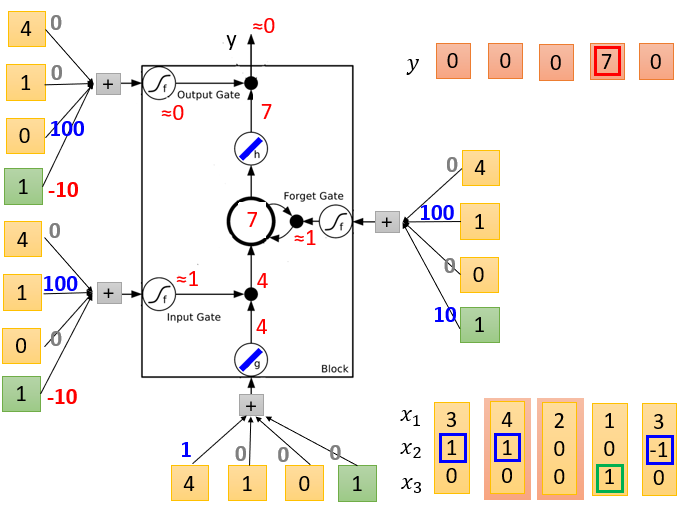
图4表示输入[2 0 0 1]
图5表示输入[1 0 1 1]
图6表示输入[3 -1 0 1]
(从左到右依次为图4、5、6)
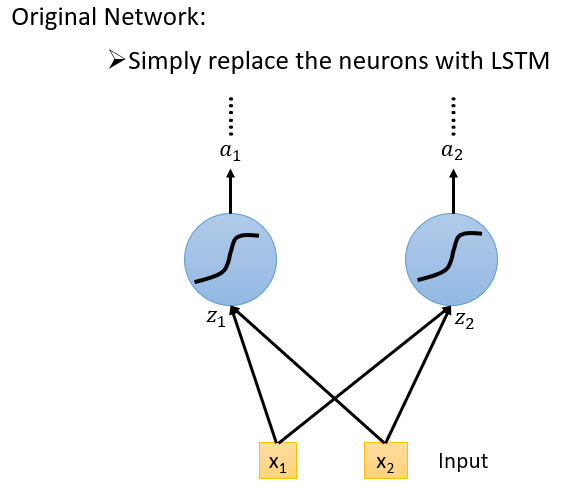
一般的神经网络和LSTM的区别
普通的神经网络中的神经元换成LSTM的memory cell
LSTM与RNN的联系
每个memory cell中的值接起来,就代表
c
t
−
1
c^{t-1}
ct−1这个向量
在时间点
t
t
t,输入一个向量
x
t
x^t
xt,它会经过transform变成
z
z
z(也是一个vector,代表每一个LSTM的输入,维度和LSTM的数目相同)
同理
z
i
z^i
zi是操控Input Gate的vector,第1维操控第一个LSTM的Input Gate,第2维操控第2个LSTM的Input Gate…
z
z
z、
z
i
z^i
zi、
z
f
z^f
zf、
z
o
z^o
zo这4个vector的维度都和LSTM的数目一致
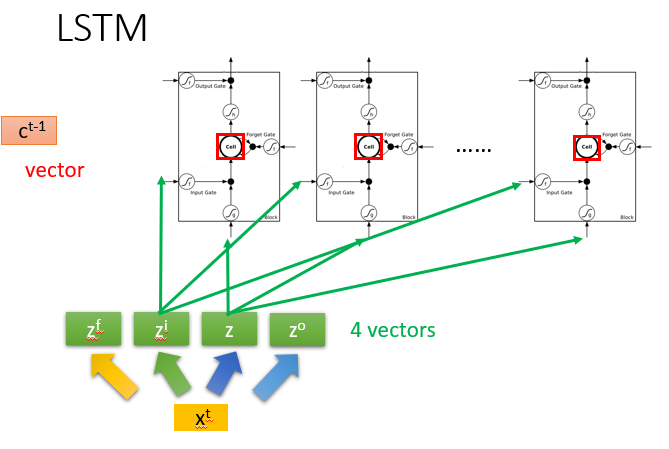
一个LSTM的输入只是vector的1维 但多个LSTM的输入可以同时运算
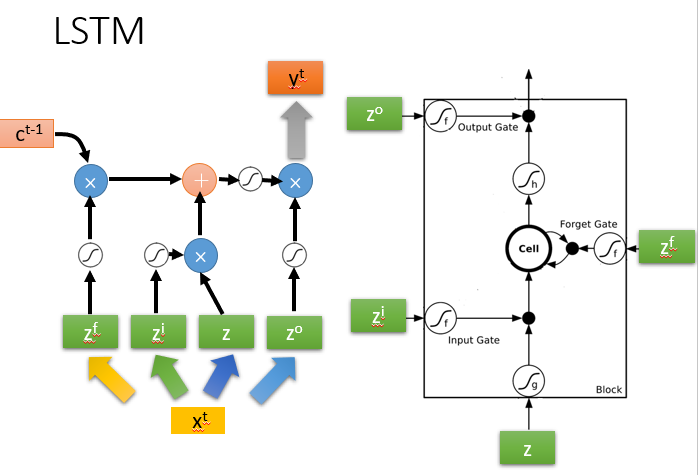
输入的是memory cell的值的向量、hidden layer的值的向量、输入值向量并在一起的向量
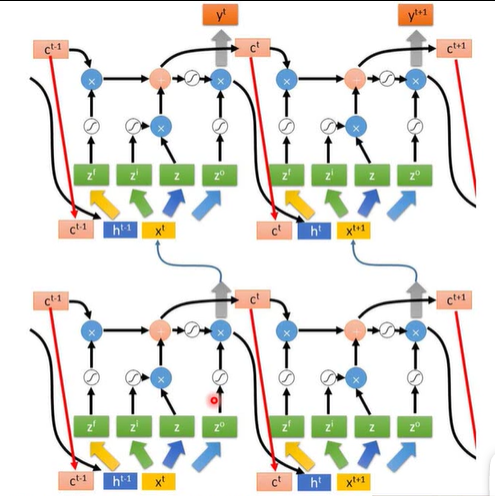
多层LSTM
Don’t worry if you cannot understand this. Keras can handle it.Keras supports “LSTM”, “GRU”, “SimpleRNN” layers
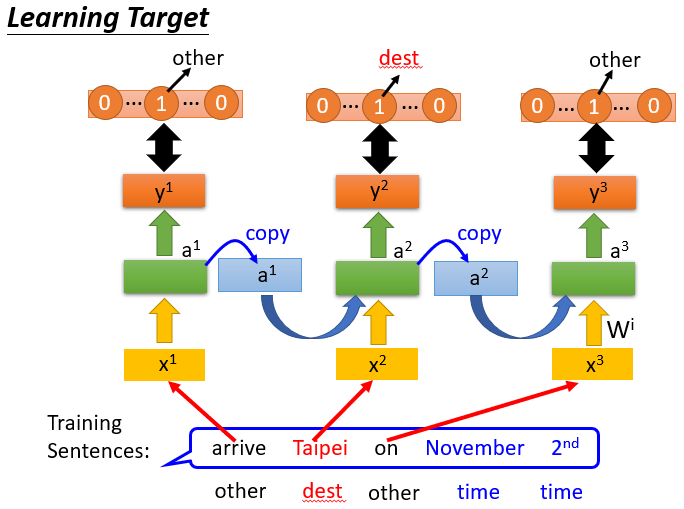
四、RNN的训练
RNN的训练目标
RNN的损失函数一般用交叉熵
注意:丢进去"Taipei"之前要将"arrive"丢进去,注意序列
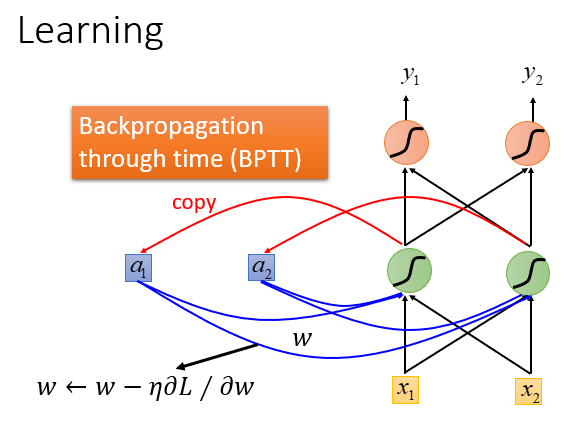
RNN采用BPTT算法进行训练
实际上也是采用梯度下降的方法
在前馈神经网络中用梯度下降原理,比较有效的算法是BP算法
RNN中也用的是梯度下降的原理,为了计算方便,用BPTT算法
RNN训练出现的问题及解决
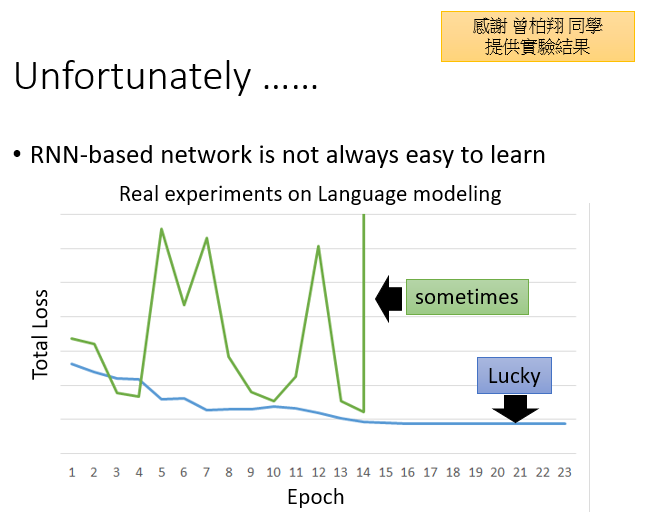
LSTM可以解决梯度消失问题















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









