






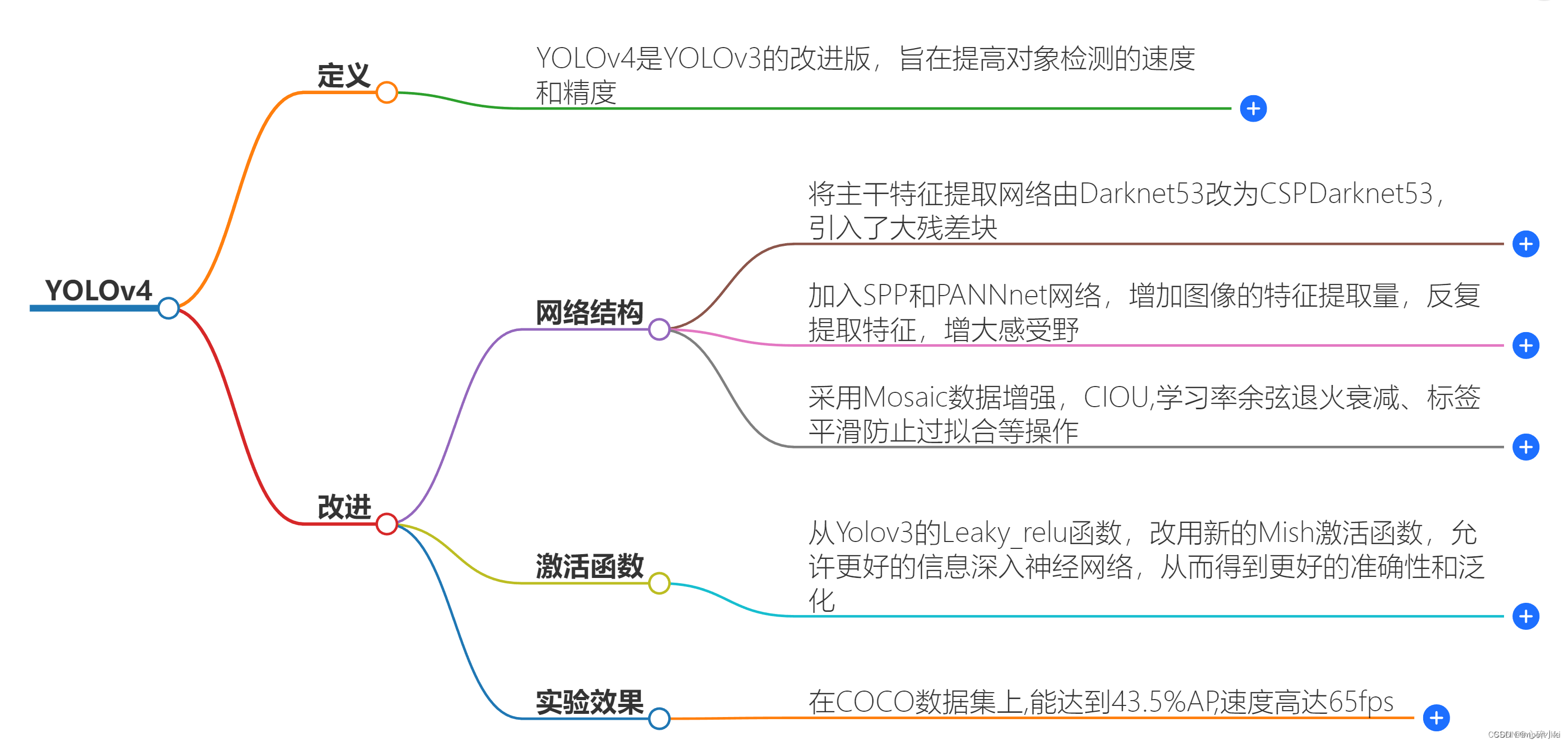
一、什么是Yolov4?
因个人对Yolov4的理解不够清晰和深刻,如果片面的来说明会导致读者产生误解,所以理论部分建议大家看一些更权威的论文或者博客,知乎文章等,比如:
睿智的目标检测30——Pytorch搭建YoloV4目标检测平台-CSDN博客
https://blog.csdn.net/weixin_44791964/article/details/106214657
本实验基于代码Github开源代码:
bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。 (github.com)
https://github.com/bubbliiiing/yolov4-pytorch
二、数据准备
实践是检验真理的唯一标准,话不多说,上手实操,首先我们选用的是飞桨AI Studio星河社区的水果分类目标检测VOC数据集(说白了就是手机摄像头坏了人也懒)
水果分类目标检测VOC数据集_数据集-飞桨AI Studio星河社区 (baidu.com)
https://aistudio.baidu.com/datasetdetail/92360
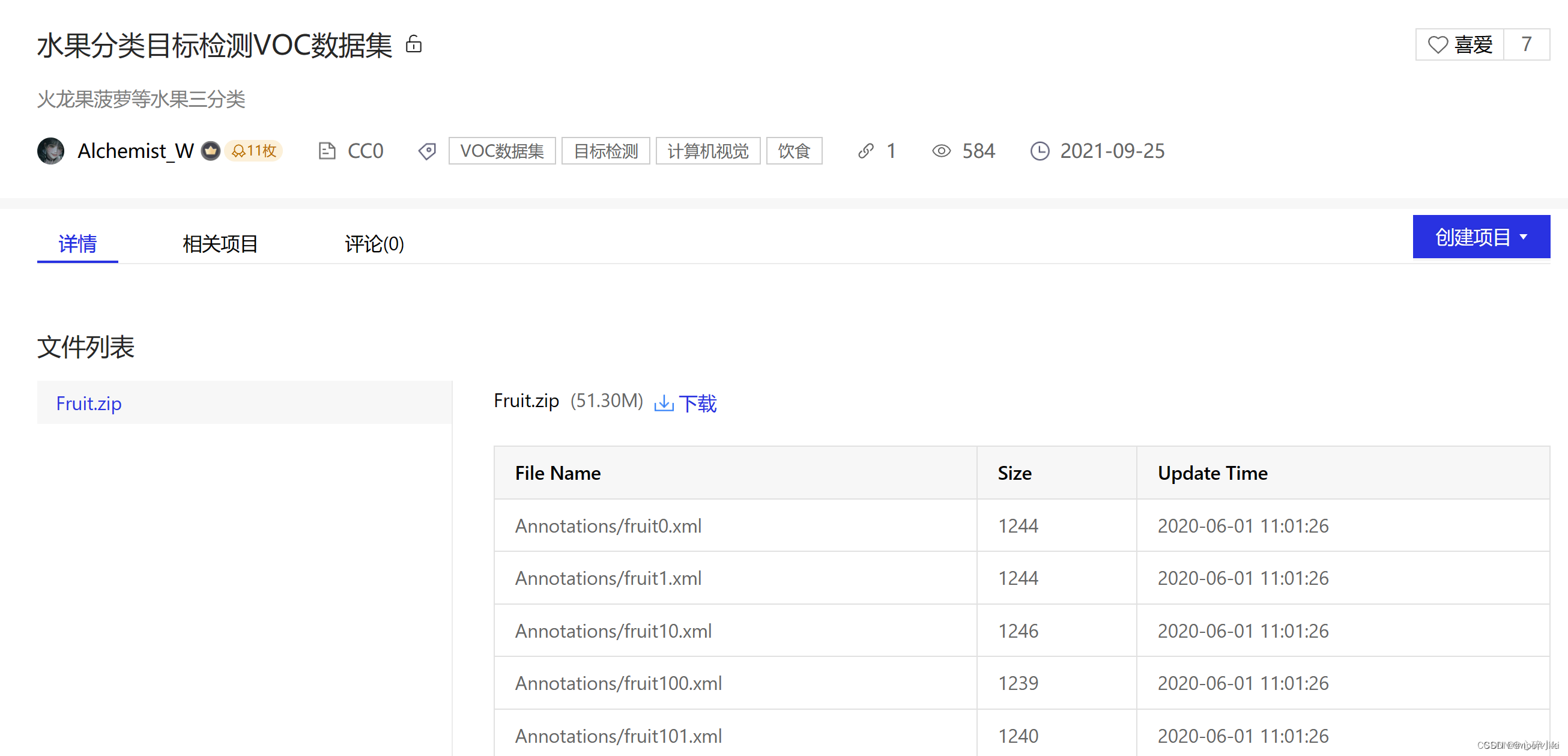
这个数据集主要有dragon fruit,snake fruit,pineapple(火龙果、蛇果、菠萝)三种水果的图片共计200张,数据集图片和标签是分开的,比较方便(懒就是懒,你还方便上了)
1.划分数据集
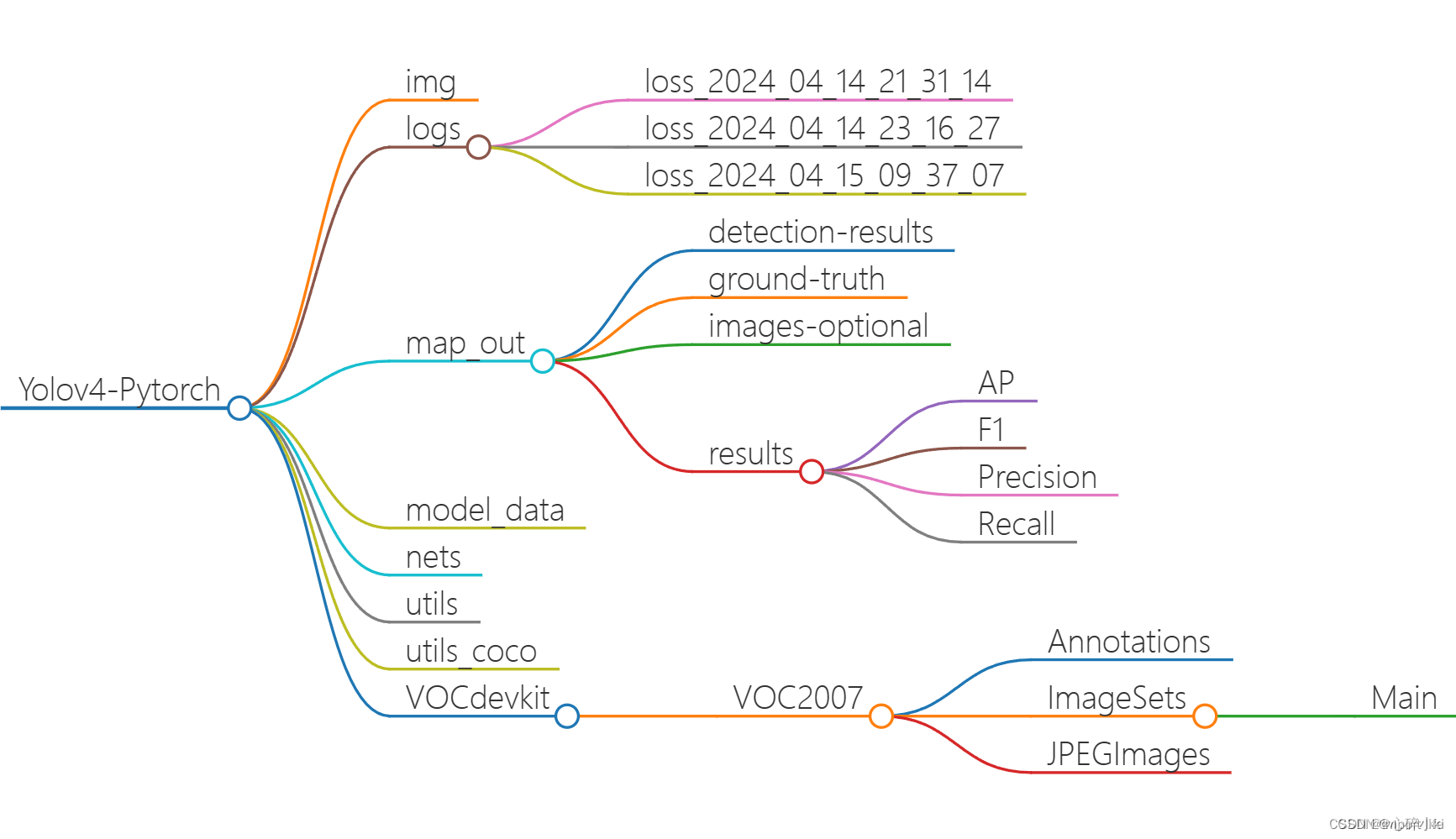
项目的主干结构如上图,数据集的命名其实已经很清楚了,就是Annotations文件夹放标签,ImageSets文件夹放图片,如果是自己找的标注的图片,标注完成后最好一个Annotations文件夹放标签,一个ImageSets文件夹放图片(便于后期对应),然后统一格式命名(用Python实现即可),示例如下(只是结构示例,并非真实可靠数据集,娱乐所作): 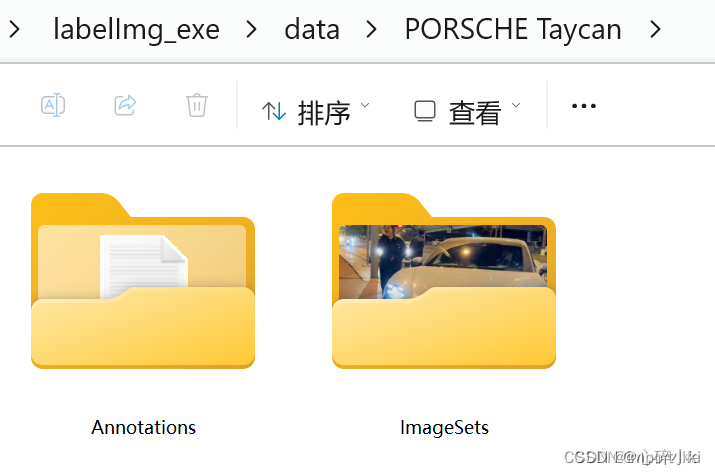
# 设置源文件夹和目标文件夹
source_folder = '这里是需要转换的文件夹路径'
target_folder = '这里是转换输出的文件夹路径'
# 检查目标文件夹是否存在,如果不存在则创建
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 遍历源文件夹中的所有文件
for file_name in os.listdir(source_folder):
if file_name.endswith('.png'):
# 读取PNG图片
img_path = os.path.join(source_folder, file_name)
img = Image.open(img_path)
# 转换为JPEG
rgb_im = img.convert('RGB')
# 保存JPEG图片
target_file_name = file_name[:-4] + '.jpg'
target_img_path = os.path.join(target_folder, target_file_name)
rgb_im.save(target_img_path, 'JPEG')
# 删除原始PNG图片
os.remove(img_path)
print("转换并删除原始PNG图片完成!")
2.处理数据集
如果是自己找的图片,并使用labelImg标注的话,这里有一些小tips,绿框框住的部分选择PascalVOC,这样标签文件会是xml格式,如果选择yolo标签文件是txt格式,不方便后续项目的进行。
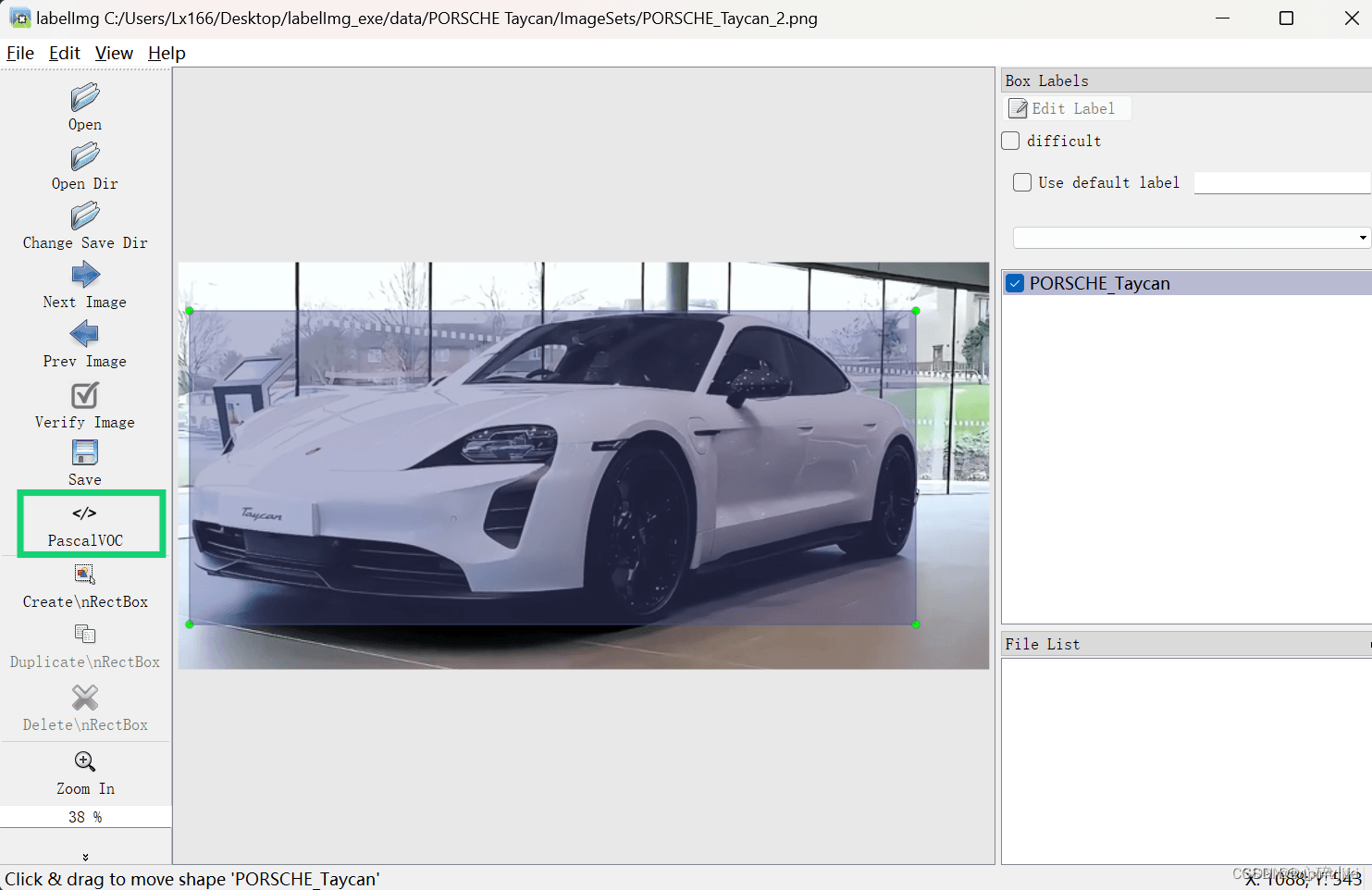
这一步简单来说就是把训练自己的数据集时xml标签文件放入VOCdevkit文件夹下的VOC2007文件夹下的Annotation文件夹中,jpg图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages文件夹中即可,如图所示:
voc_annotation.py里面有一些参数需要设置,分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path。
classes_path = 'model_data/cls_classes.txt'
classes_path用于指向检测类别所对应的txt,训练自己的数据集时,可以自己建立一个cls_classes.txt(或者你想要的名字都可),里面写自己所需要区分的类别。以我的数据集为例,我用的cls_classes.txt为:
就是想要检测的类别是什么就写什么,但要和数据集的类别一致,比如数据集的类别是苹果和椰子,cls_classes.txt里写类别是榴莲和菠萝,这样肯定是不合理的。
三、环境准备
1.环境内容
电脑硬件配置:
设备名称 BBBQL
处理器 11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz 2.50 GHz
机带 RAM 16.0 GB (15.9 GB 可用)
显卡 NVIDIA GeForce RTX 2060 6G(如果用Cuda跑得用N卡,也就是大家说的英伟达的显卡)
电脑软件配置:
PyCharm 2024.1 (Professional Edition)(喜欢vscode用vscode,喜欢命令行用命令行,看个人喜好,此处仅提供具体环境作为参照)
Anaconda3-2024.02-1-Windows-x86_64 (有Conda不用挨个找不同Python安装了)
2.环境配置
python 3.9
Package Version
----------------------- ------------
absl-py 2.1.0
bigtree 0.17.0
chardet 5.2.0
colorama 0.4.6
contourpy 1.2.1
cycler 0.12.1
filelock 3.13.4
fonttools 4.51.0
fsspec 2024.3.1
graphviz 0.20.3
grpcio 1.62.1
h5py 3.11.0
importlib_metadata 7.1.0
importlib_resources 6.4.0
install 1.3.5
Jinja2 3.1.3
kiwisolver 1.4.5
Markdown 3.6
MarkupSafe 2.1.5
matplotlib 3.8.4
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.4
opencv-python 4.9.0.80
packaging 24.0
Pillow 9.5.0
pip 23.3.1
protobuf 5.26.1
pydot 2.0.0
pyparsing 3.1.2
python-dateutil 2.9.0.post0
scipy 1.13.0
setuptools 68.2.2
six 1.16.0
sympy 1.12
tensorboard 2.16.2
tensorboard-data-server 0.7.2
torch 2.2.1+cu121
torchaudio 2.2.1+cu121
torchvision 0.17.1+cu121
tqdm 4.66.2
typing_extensions 4.11.0
Werkzeug 3.0.2
wheel 0.41.2
zipp 3.18.1
同样,此处仅提供具体环境作为参照,便于训练自己数据集时复现。
下面以Pycharm专业版(社区版也一样)为例,手把手复现环境搭建(个人习惯,习惯性环境隔离,每个项目一个解释器):
第一步,打开设置,点击“项目”下的“Python解释器”选项(英文差用了中文插件,见谅);
第二步,点击“添加解释器”然后选择“添加本地解释器”;
第三步,点击“Conda环境”,“创造新环境”,环境名称喜欢什么用什么(用中文会伤心的OK),Python版本我选择的3.9,因为很多教程都是3.6版本的感觉麻烦还是用稍微新一点的版本了。
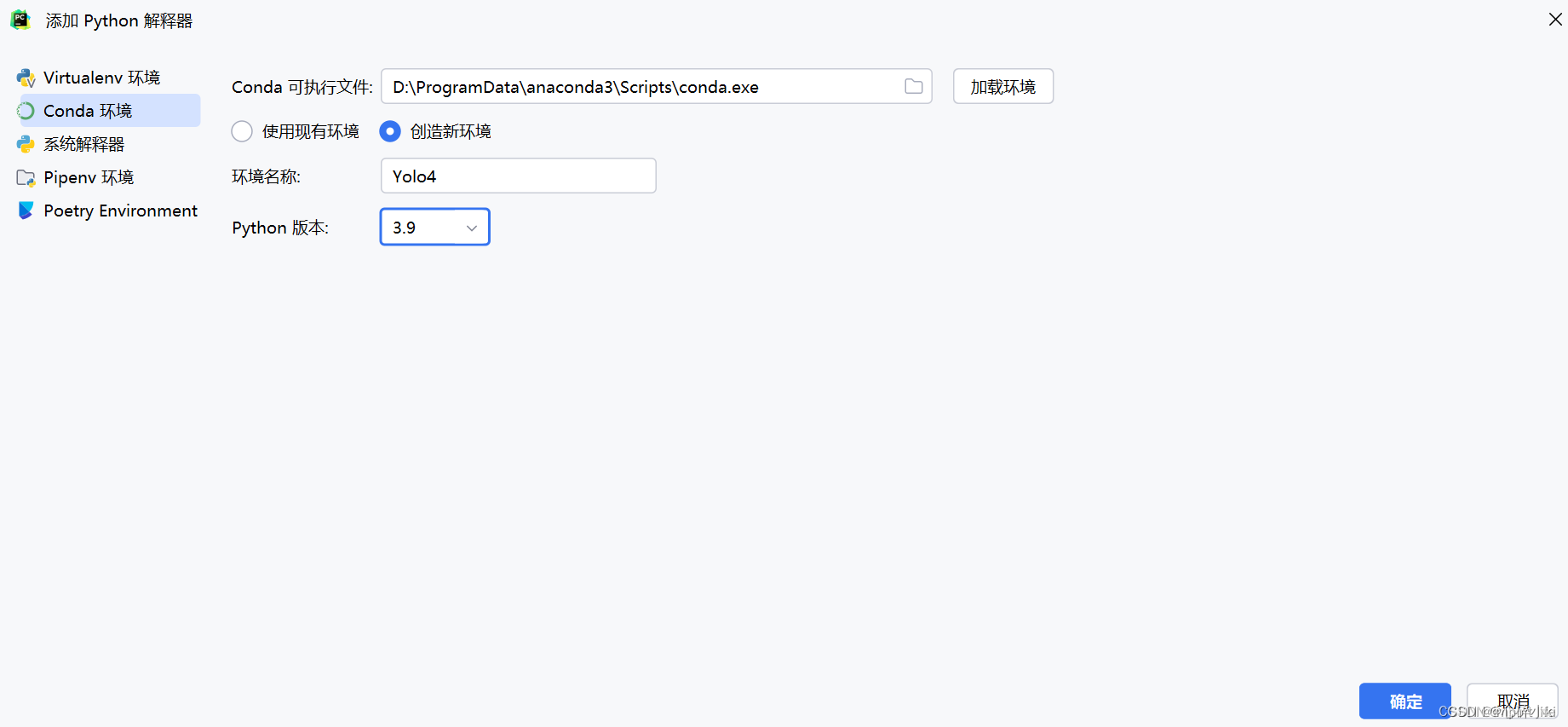
中场休息,如果上一步,没有安装Anaconda的同学就不一定能到Conda环境这一步了,如果说没有安装的可以参考下面的Anaconda安装教程,conda国内镜像源可加可不加,因为不少conda国内镜像源不能正常工作了,安装的时候记得勾选“Add Anaconda3 to the system PATH environment variable",这样就直接添加到系统环境变量了,不用手动配置环境变量
第四步,成功创建完新的虚拟环境之后,设置里就会直接显示并使用新的环境了,这时候点击“应用”,然后点“确定”,正常会自动切换虚拟环境。
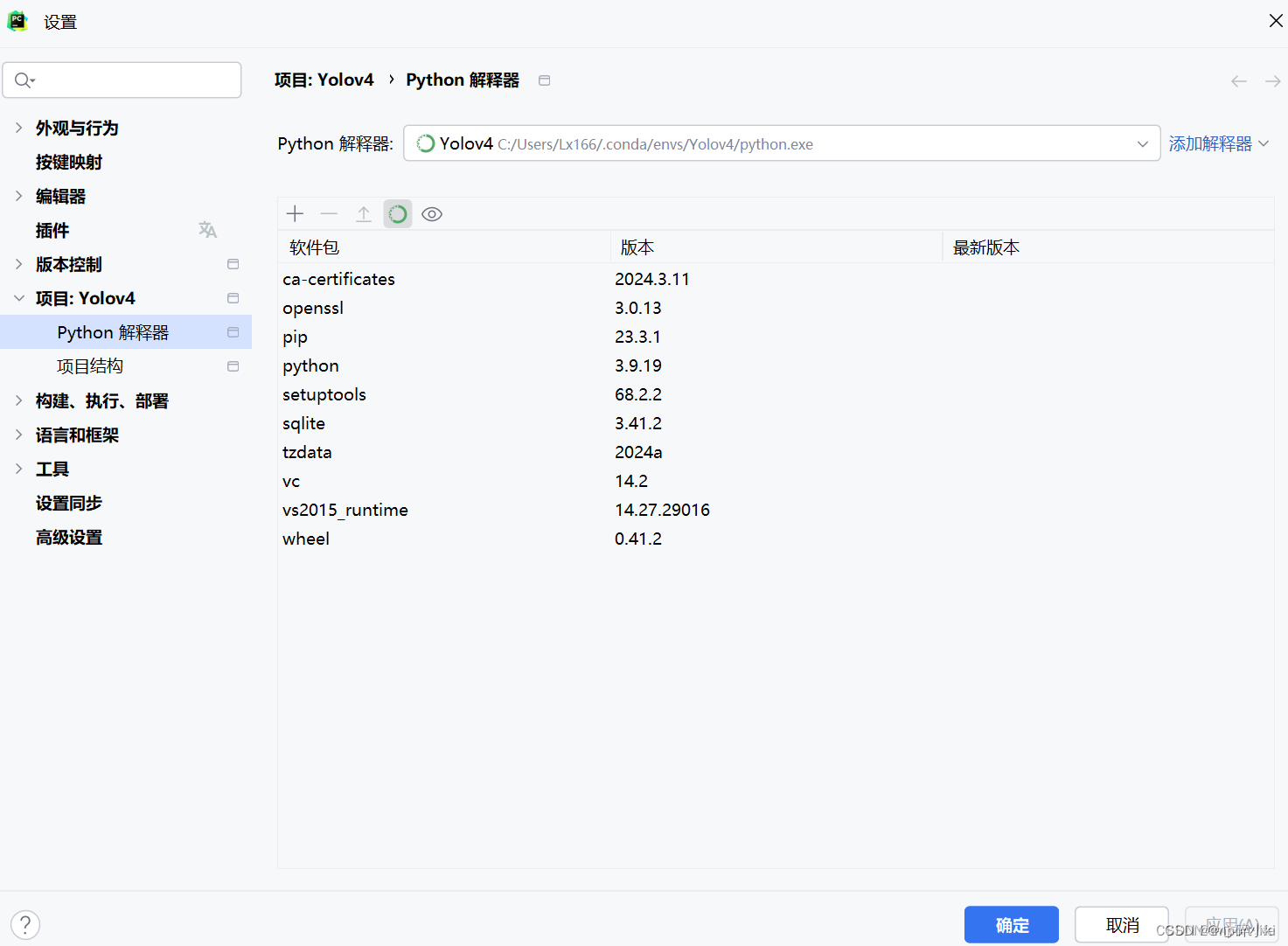
第五步,点击左下角“终端”图标,打开就是新环境,如果创建环境之前是之前的虚拟环境的话需要手动激活,或者重启终端,也可以在终端手动创建conda环境并激活,来去自如,激活命令示例:
3.安装依赖
养成好习惯,有requirements.txt先看requirements.txt,这里是把所需要的包都罗列出来了,如果只想用CPU训练数据集和预测,可以直接安装,如果是想要GPU和Cuda训练和预测数据集,记得删除torch和torchvision那两行,不然后面会搞事情,具体是什么事情的后面会提到。
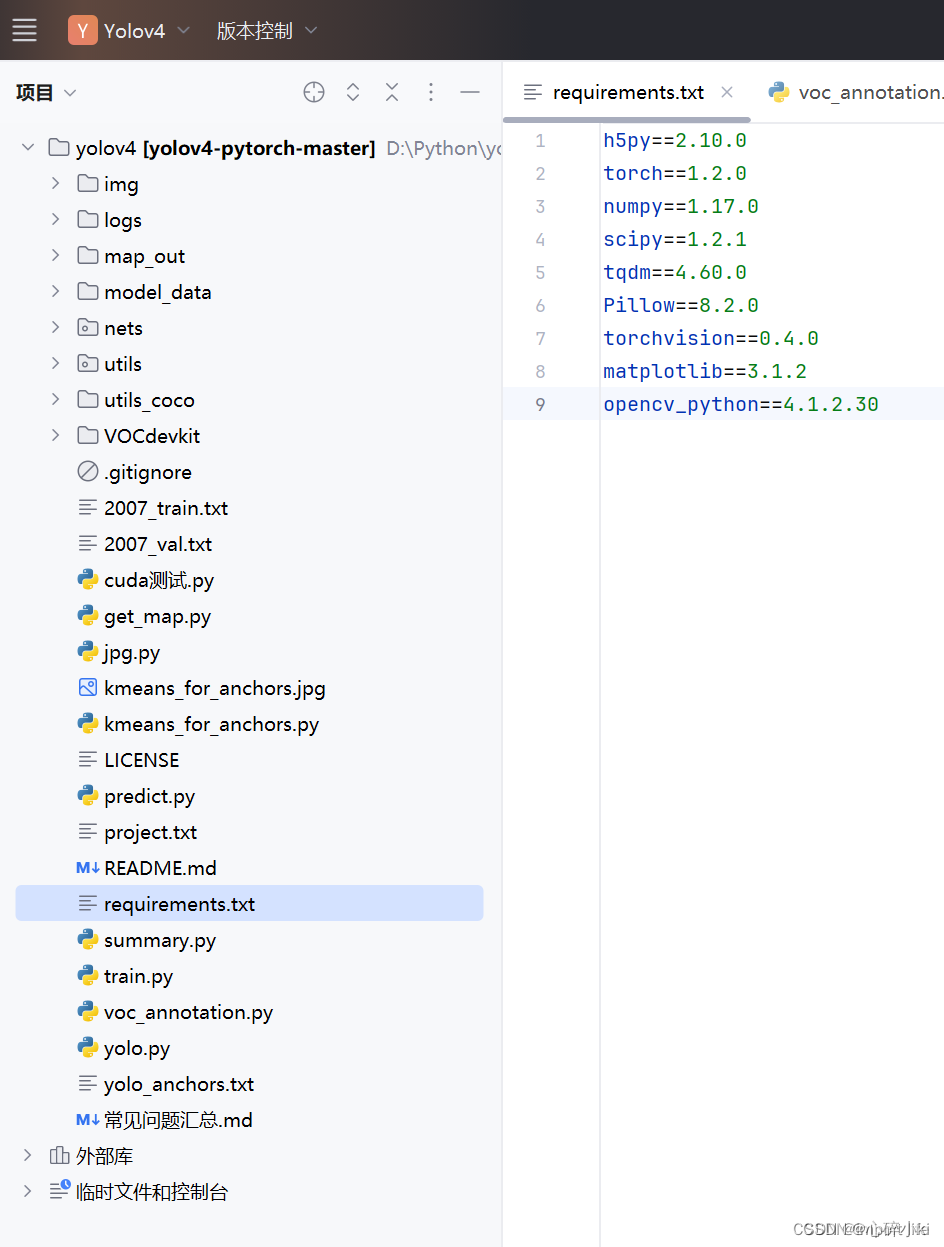
第一步,既然有了requirements.txt,在终端直接无脑输入,
pip install -r requirements.txt
这里如果真无脑输入了,会不会发现少点什么,当然是我们老生常谈的Pip换源
常用Pip国内镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/simple/
上海交通大学:https://mirror.sjtu.edu.cn/pypi/web/simple/
豆瓣:http://pypi.douban.com/simple/
国内开源镜像网站集合汇总(最全,可用) - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/609597886
注: 新版ubuntu系统要求使用https源。
一般来说,镜像源没有最快,只有更快(相对而言)用法示例如下:
pip install <安装包> -i <镜像源>
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/
然后其余的库缺啥补啥,方法跟上面一样,比如我下了tqdm,h5py等库,用了镜像都很快,如果要用CUDA,这一步先不要下载下面这三个库。
torch
torchaudio
torchvision
如果真的相信自己的CPU足够强大可以直接用cpu版本的PyTorch(自行配置镜像源)
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cpu
其他CPU版本的Pytorch下载命令:
Previous PyTorch Versions | PyTorch
https://pytorch.org/get-started/previous-versions/
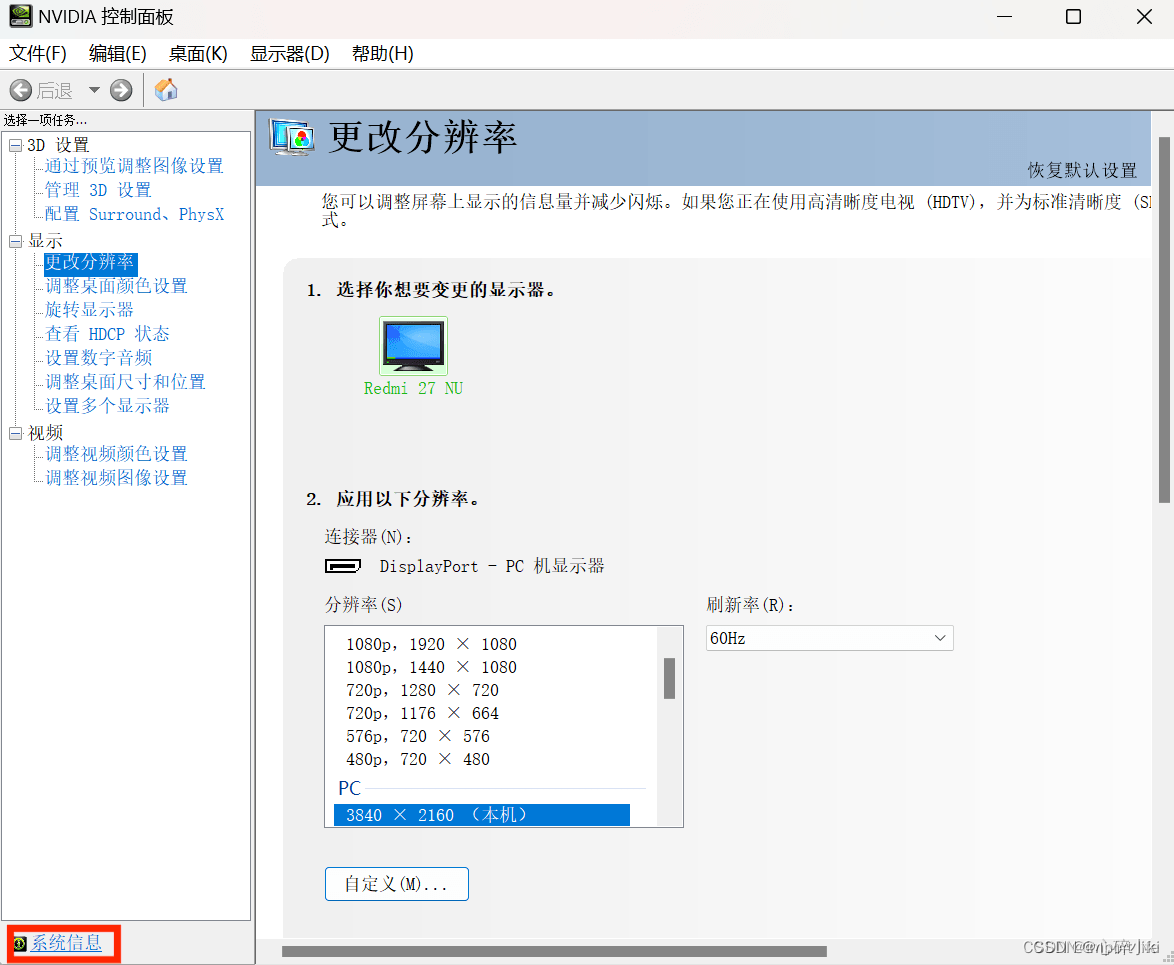
第二步,既然都用上PyTorch了,那么CUDA肯定是要用的咯,那么安装CUDA是必不可少的一步
先看自己的电脑支持什么最高版本的CUDA,右键打开“NVIDIA设置”(红框部分)->选择“NVIDIA控制面板”->选择左下角的系统信息->组件
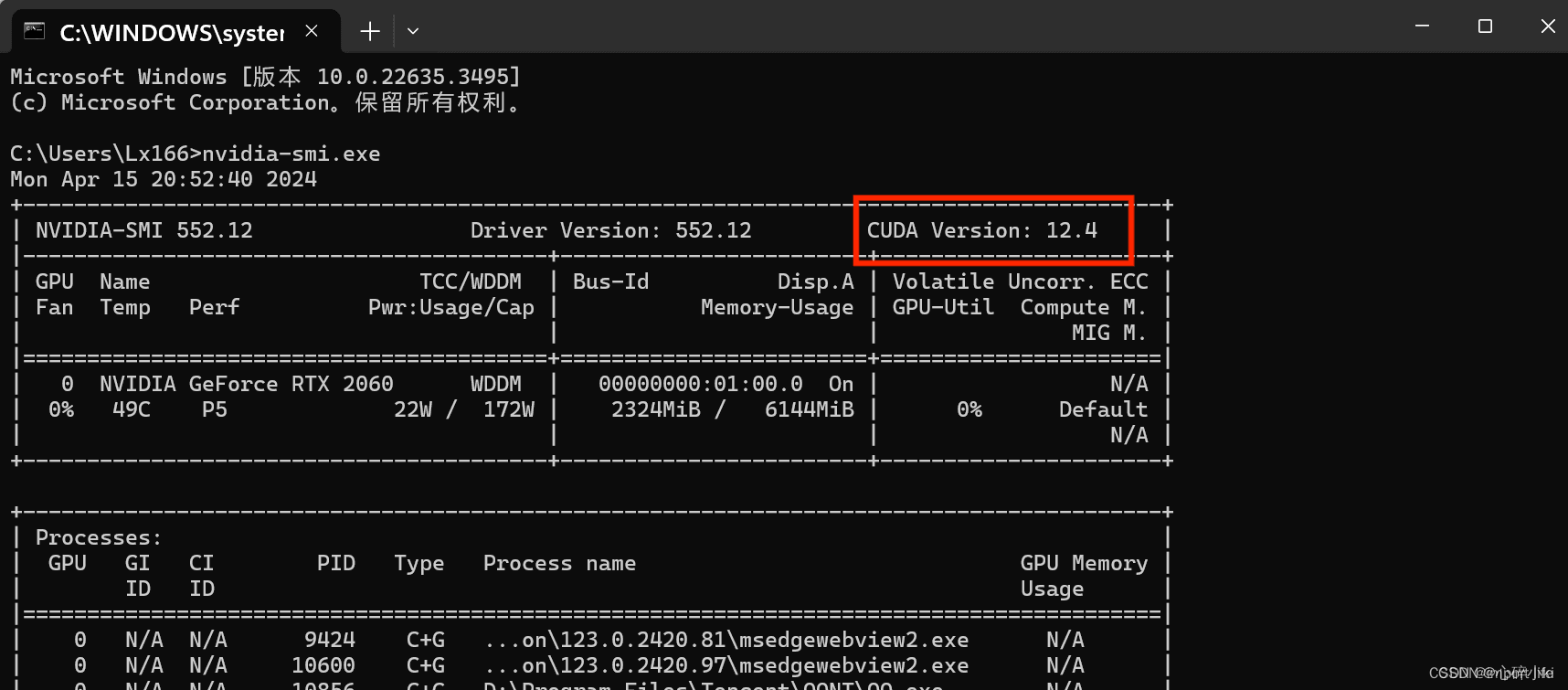
比如我的电脑最高是可以支持12.4版本的CUDA的,知道最高支持版本之后,我们就可以在小于等于该版本的CUDA中选择了。
如果觉得上述步骤麻烦不好操作,在显卡驱动正确安装的前提下可以直接用命令行(Win+R召唤运行,然后输入CMD),然后在命令行输入:
nvidia-smi.exe
这里会直接显示显卡支持的最高的CUDA版本,同样知道最高支持版本之后,我们就可以在小于等于该版本的CUDA中选择了。
Windows安装CUDA ,还需要下载一些其他的东西:
(1)CUDA toolkit(toolkit就是指工具包)
官方教程:(可能需要魔法)
Installation Guide Windows :: CUDA Toolkit Documentation
https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
(2)cuDNN
官方教程:(可能需要魔法)
Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installwindows
(3)Visual Studio2022(使用C++的桌面开发,这里我已经安装过了,为了截张图重新走了遍安装流程)
这里由于CUDA安装教程过长,占用太多篇幅可能会比较枯燥乏味(实在是懒得写了哈哈哈哈哈哈哈哈哈),建议直接搜索相关教程,或者参考一些比较详细的博客,例如:
win11下安装Cuda和Cudnn(pytorch+GPU环境安装),保姆级教程!!!_cudnn-windows-x86_64-8.7.0.84_cuda11-archive-CSDN博客
https://blog.csdn.net/qq_36623004/article/details/127228147
Pytorch、CUDA和cuDNN的安装图文详解win11(解决版本匹配问题) - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/641832733
CUDA安装及环境配置——最新详细版-CSDN博客
https://blog.csdn.net/chen565884393/article/details/127905428
第三步,检查CUDA是否安装成功,老办法(Win+R召唤运行,然后输入CMD),然后在命令行输入:
nvcc -V
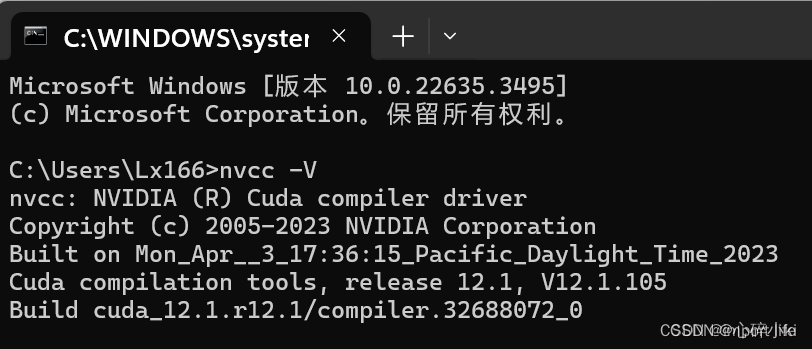
出现了你的CUDA版本信息,说明安装成功了。要是还想测试一下能不能用,CUDA也有测试工具测着玩,我的安装路径是:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\extras\demo_suite
具体路径看用的人安装的路径,在demo_suite文件夹执行CMD,或者也可以在命令行跳到这个文件夹都可,查询一下本机的gpu设备,输入:
deviceQuery
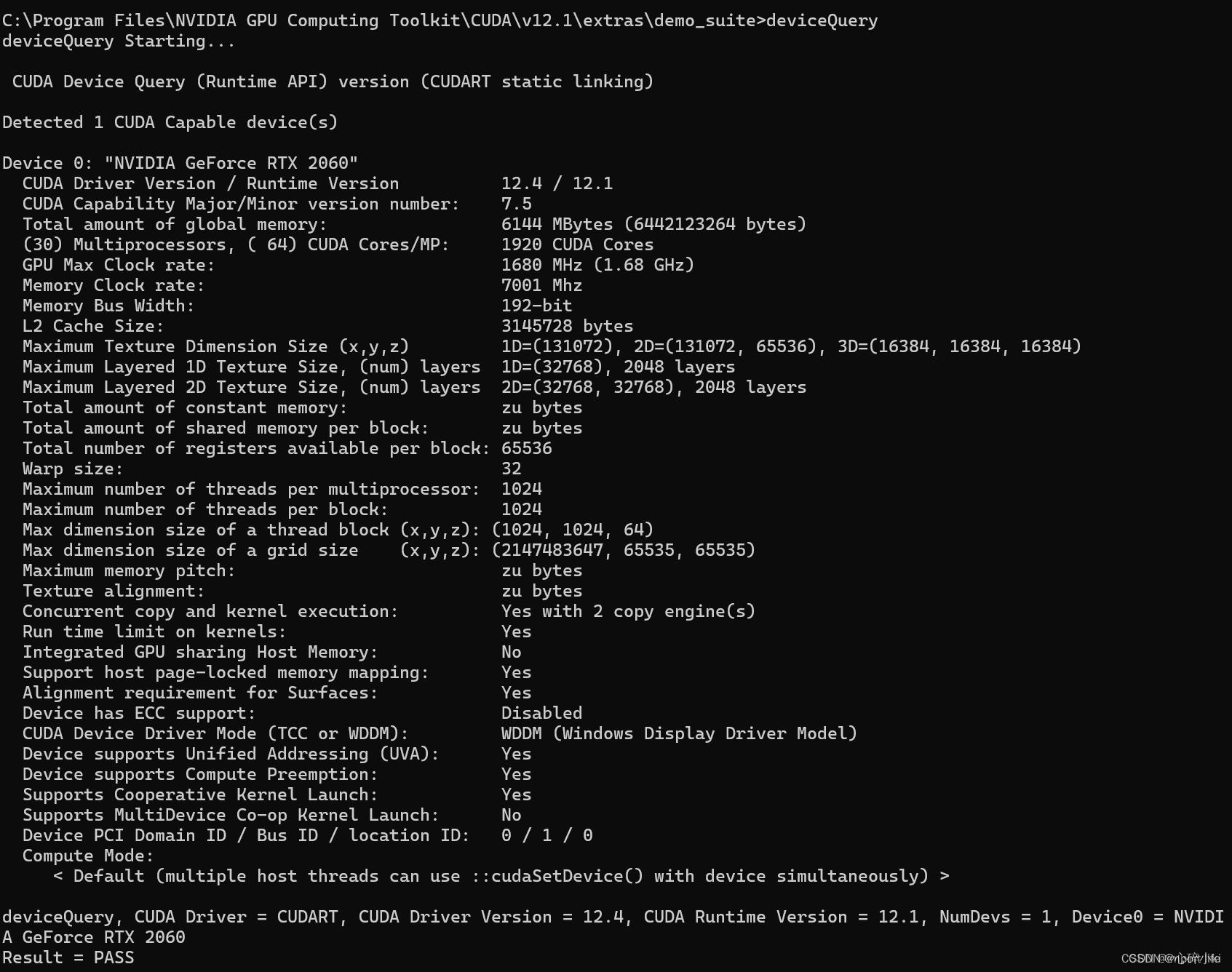
再来测试一下带宽,输入
bandwidthTest
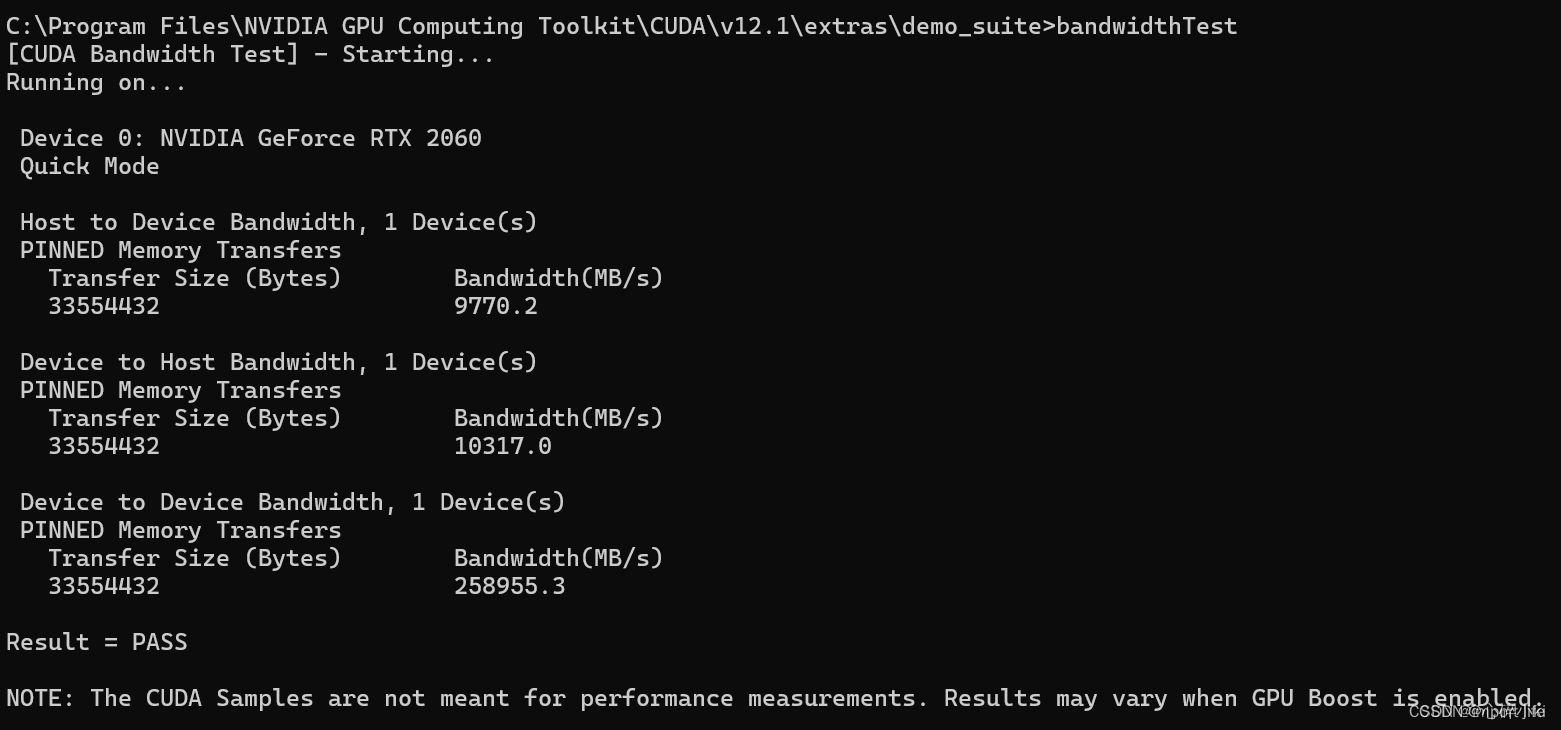
能看出结果都是PASS,说明一切运行正常
第四步,安装CUDA版本的torch,torchaudio,torchvision三个库
命令如下(如果网速尚可不要用镜像,因为镜像源总是下成CPU版本的Pytorch):
这里以Windows,CUDA 12.1,PyTorch 2.2.1版为例:
# CUDA 12.1
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
找到适合自己CUDA版本的PyTorch版本下载即可,可选版本很多:
再贴一遍PyTorch下载命令链接:
Previous PyTorch Versions | PyTorch
https://pytorch.org/get-started/previous-versions/
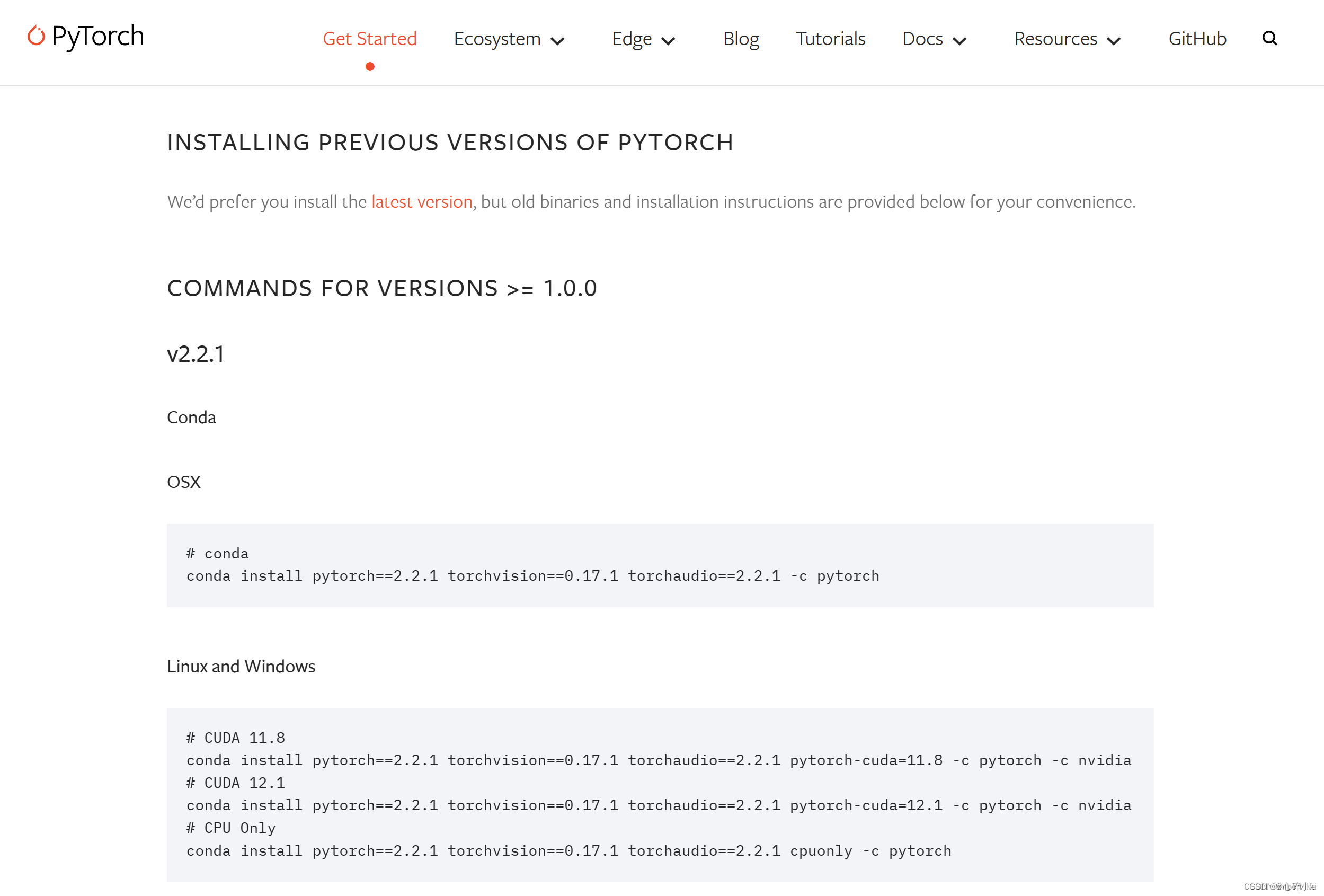
第五步,在Python里测试下载好的CUDA版本的PyTorch是否可用
一个简单的测试代码,瞎写的:
import torch
import torchaudio
import torchvision
print(torch.__version__) #输出torch版本
print(torchaudio.__version__) #输出torchaudio版本
print(torchvision.__version__) #输出torchvision版本
print(torch.cuda.is_available()) # 如果这个命令返回True,那么PyTorch可以使用CUDA
正确的CUDA版本PyTorch输出结果:

错误的CPU版本PyTorch输出结果:(仅为打印出来的示例,具体是否输出内容是这些我也忘了)

也有PyTorch不完全是CUDA版本的情况:(torchvision明显是cpu版本,总之是坑,谨记避雷!)
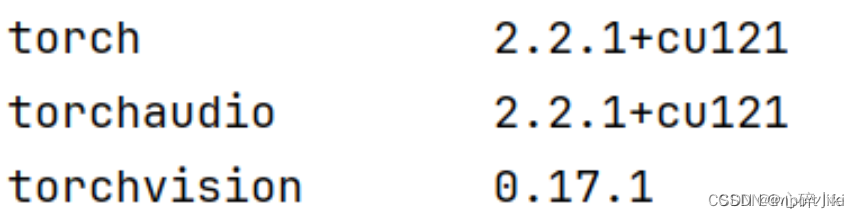
到此为止,我们前期的环境准备流程基本结束。
四、训练数据
1.运行voc_annotation.py
处理数据集修改了classes_path并对应自己的类别文件就可以直接运行,输出结果示例如下:
这个代码的主要作用如下:
设置处理模式 (annotation_mode):
根据设定的模式,可以只生成数据集的划分文件(例如训练集、验证集),或者同时生成这些划分并且创建包含具体标注信息的文本文件。
设定类别信息 (classes_path):
指定一个文件,该文件包含了数据集中所有目标的类别名称,用于区分不同的物体。
数据集划分比例 (trainval_percent 和 train_percent):
设定训练集和验证集的数量比例,以及它们两者与测试集的数量比例。
处理VOC数据集:
从标注文件(XML文件)中提取出目标的类别和对应的边界框(bounding box)坐标。
根据提供的类别信息和标注,包括目标的难易程度(difficult),生成特定于训练的文本文件,这些文件包含了用于训练目标检测模型的必要信息。
输出的文件格式通常是一个图片文件的路径,后面跟着该图片中所有标注对象的类别索引和边界框坐标。
自动化标注文件创建与数据集划分:
自动生成用于训练、验证和测试的数据划分文件(如train.txt, val.txt, test.txt)。
这样可以简化后续模型训练时的数据准备工作,因为模型可以直接读取这些划分文件来获取必要的训练和验证数据。
统计信息输出:
在处理完毕后,代码还会输出一些统计信息,比如每个类别的目标数量,以及提醒信息,例如如果训练集的数量较小或者某些类别没有目标。
总而言之,这段代码的主要作用是从标注的XML文件中提取出目标检测任务所需的信息,并自动创建相应的训练、验证和测试划分文件,方便进行后续的模型训练和评估工作。
2.运行train.py
这个train.py代码可以改的参数很多,第一次训练咱们化繁为简,成功了再谈改进,如果CUDA成功安装了并安装了CUDA版本的PyTorch就把Cuda参数设置为True,用cpu可以不管,然后classes_path参数修改为自己定义好类别的txt文件;
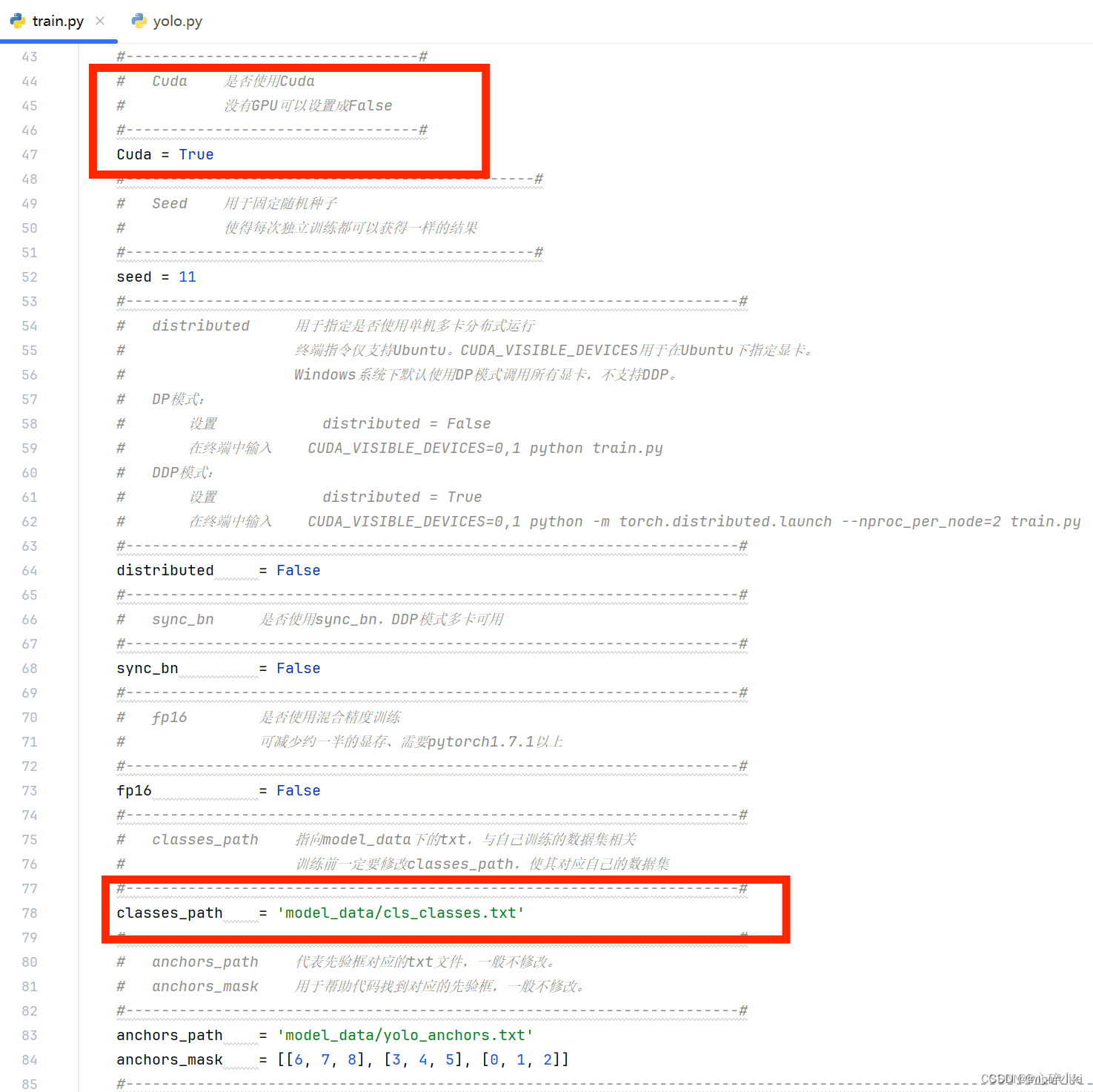
yolo.py也需要修改相关函数:
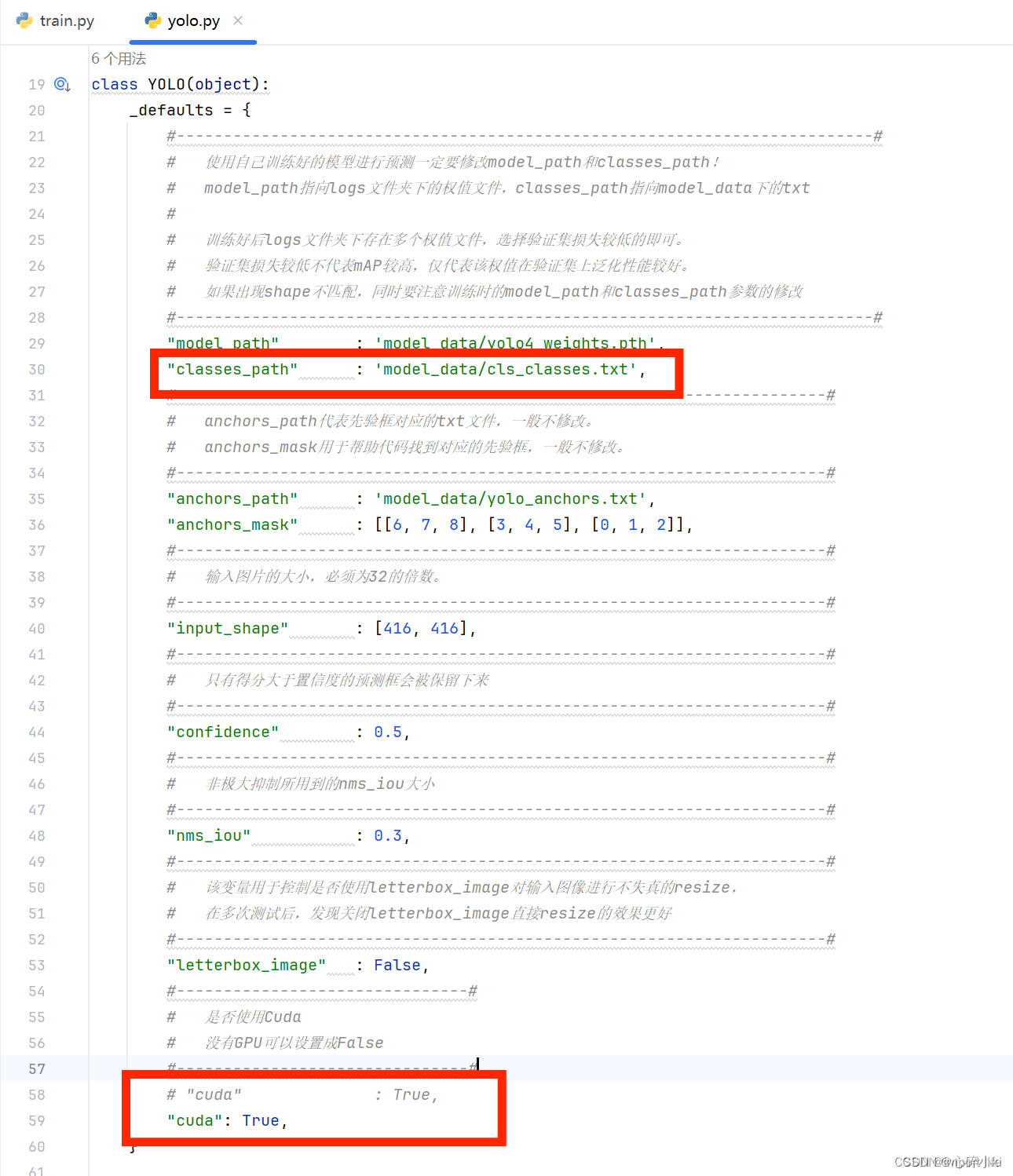
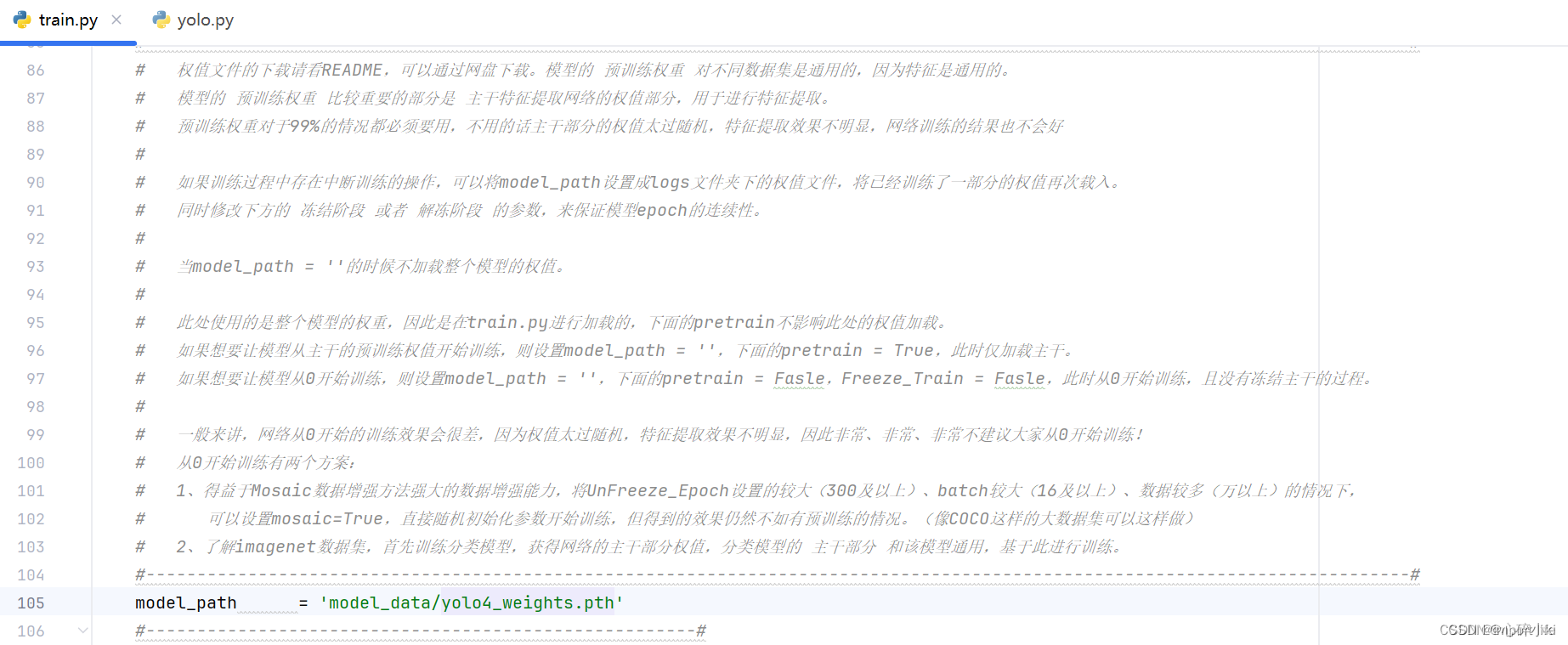
注意,train.py文件中有个重要参数,mode_path主干权值文件,一般是使用现成的训练好的权值文件yolo4_weights.pth和yolo4_voc_weights.pth;
我第一次训练(批次(epoch)=100)的时候使用的主干权值文件是yolo4_weights.pth,

第二次训练进(批次(epoch)=100),用了我自己训练的权值文件(fruit_weights)作为主干权值,

第三次训练(批次(epoch)=300),用了我自己训练的权值文件(fruitv2_weights)作为主干权值,可以看到,性能提升非常大。

总之其实可以老老实实用yolo4_weights.pth等现成的权值文件多训练几百个批次(epoch),主干权值文件能不动尽量不动。(注:不改变原代码函数的情况下200张图片100个批次2060显卡跑满的话一个小时左右就跑完了)
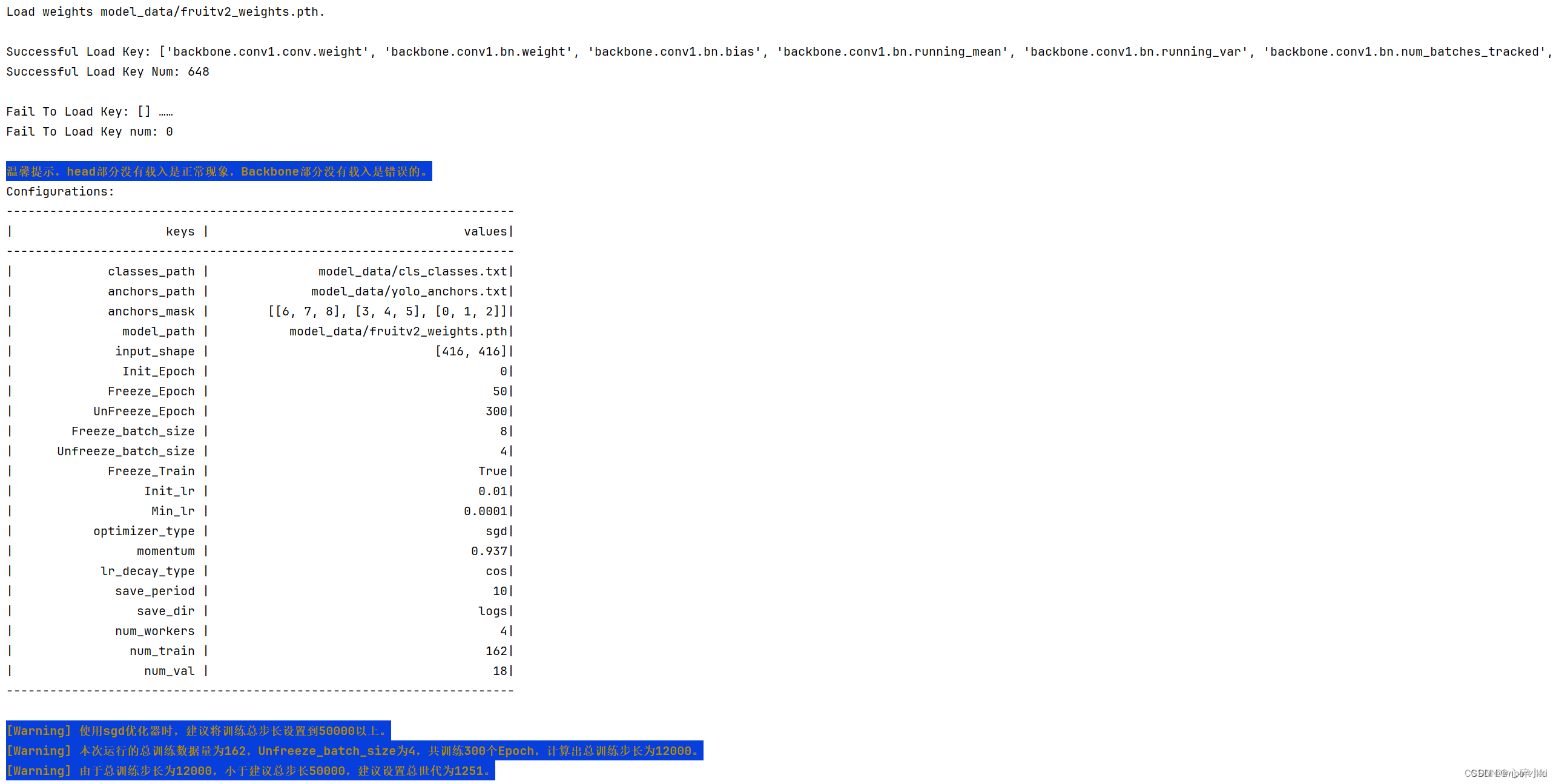
UnFreeze_Epoch模型总共训练的批次(epoch)数参数的话,如果对数据集没什么信心可以设置个20-30批次左右看输出内容,如果输出各项指标一直是0就可以直接结束,改进数据集了。
训练期间会输出模型性能的统计数据,包括不同类别(dragon fruit 和 snake fruit)的平均精度(AP)和平均精度均值(mAP),以及它们对应的分数阈值、F1-分数、召回率和精确率。
这个代码主要作用如下:
准备阶段:
设置是否使用GPU。
初始化随机种子以确保结果可复现。
设置是否使用分布式训练。
定义模型需要检测的类别。
加载预定义的YOLO模型的锚点(anchors),用于指导模型预测目标大小。
加载图像数据和标签数据的路径。
模型配置:
加载模型架构,可以选择加载预训练权重以此来初始化模型,或者从头开始训练。
设置输入图像的尺寸。
根据是否进行冻结训练(只训练模型的部分层,其他层保持不变),设置不同的训练策略,例如学习率和训练轮次(Epoch)。
数据增强:
使用了Mosaic和Mixup等数据增强技术,可以在训练中生成更多样化的训练样本。
编译模型:
根据设置的学习率、优化器类型(如SGD或Adam)、以及是否使用Focal Loss或iou损失等选项,配置模型的优化器。
设置学习率衰减策略。
训练流程:
分两个阶段进行训练:冻结训练(只训练模型顶层,主干网络被冻结)和解冻训练(训练所有层)。
在每个阶段,会根据实际数据集的大小动态调整训练时的批量大小(Batch Size)和学习率。
逐轮次(Epoch)进行训练,每轮次结束后可能保存模型权重,并可以选择性地对验证集进行评估,以监控模型性能。
记录和评估:
将训练过程中的损失值和经过验证集评估得到的性能指标记录下来。
总结来说,这段代码用于训练Yolo目标检测模型,涉及到了数据准备、数据增强、模型配置、训练流程以及性能评估等关键步骤。
训练完的权值文件默认保存在log文件夹下,log文件夹下的best_epoch_weights.pth就是我们训练好的权值文件,示例如下:
3.运行predict.py
训练好我们要用的权值文件以后,先修改yolo.py代码,model_path换成自己训练好的权值文件;
yolo.py还有个不明显但是训练自己数据集后必须要更改的地方,onnx_path同样改成训练好的权值文件,classes_path应该不用多说,改成自己设置好的类别txt文件。
yolo.py总会报两个错误,但我没明白原因,反正不影响预测啥的,直接无视:
然后修改predict.py里的图片输入路径,不改也不甚要紧,然后用找来的图片来测试训练好的数据集权值文件效果。
如果PyTorch版本比较新,在predict.py运行时可能会弹出警告:
D:\Python\yolov4\utils\utils_bbox.py:88: UserWarning: The torch.cuda.*DtypeTensor constructors are no longer recommended. It's best to use methods such as torch.tensor(data, dtype=*, device='cuda') to create tensors. (Triggered internally at C:\actionsrunner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\tensor\python_tensor.cpp:85.) anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0])) Traceback (most recent call last): File "D:\Python\yolov4\predict.py", line 95, in <module> r_image = yolo.detect_image(image, crop = crop, count=count) File "D:\Python\yolov4\yolo.py", line 207, in detect_image label_size = draw.textsize(label, font) AttributeError: 'ImageDraw' object has no attribute 'textsize'
我的解决办法是直接修改了utils_bbox.py这个代码中的几行问题代码,修改如下(注释掉了原代码):
#----------------------------------------------------------#
# 按照网格格式生成先验框的宽高
# batch_size,3,13,13
#----------------------------------------------------------#
# anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0]))
anchor_w = torch.tensor(scaled_anchors, dtype=torch.float, device='cuda').index_select(1, torch.tensor([0],
dtype=torch.long,
device='cuda'))
# anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_h = torch.tensor(scaled_anchors, dtype=torch.float, device='cuda').index_select(1, torch.tensor([1],
dtype=torch.long,
device='cuda'))
anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape)
anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape)
#----------------------------------------------------------#
# 利用预测结果对先验框进行调整
# 首先调整先验框的中心,从先验框中心向右下角偏移
# 再调整先验框的宽高。
#----------------------------------------------------------#
# pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes = torch.zeros(prediction[..., :4].shape, dtype=torch.float, device='cuda')
pred_boxes[..., 0] = x.data + grid_x
pred_boxes[..., 1] = y.data + grid_y
pred_boxes[..., 2] = torch.exp(w.data) * anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * anchor_h
在使用CPU的情况下,如果Pillow库是直接安装的,没有指定版本,也会报类似的错误:
Traceback (most recent call last): File "D:\py\yolov4-pytorch-master\predict.py", line 96, in <module> r_image = yolo.detect_image(image, crop=crop, count=count) File "D:\py\yolov4-pytorch-master\yolo.py", line 212, in detect_image label_size = draw.textsize(label, font) AttributeError: 'ImageDraw' object has no attribute 'textsize'
解决方法也很简单,卸载新版Pillow库 ,
pip uninstall pillow
然后按照要求指定安装老版本的Pillow==8.2.0即可。
pip install Pillow==8.2.0
五、成果展示
最后给你们看一下我训练好的权值文件的成果吧,哈哈,快要0点了,1500流量券马上拿不到了,不写了。
1.图片测试
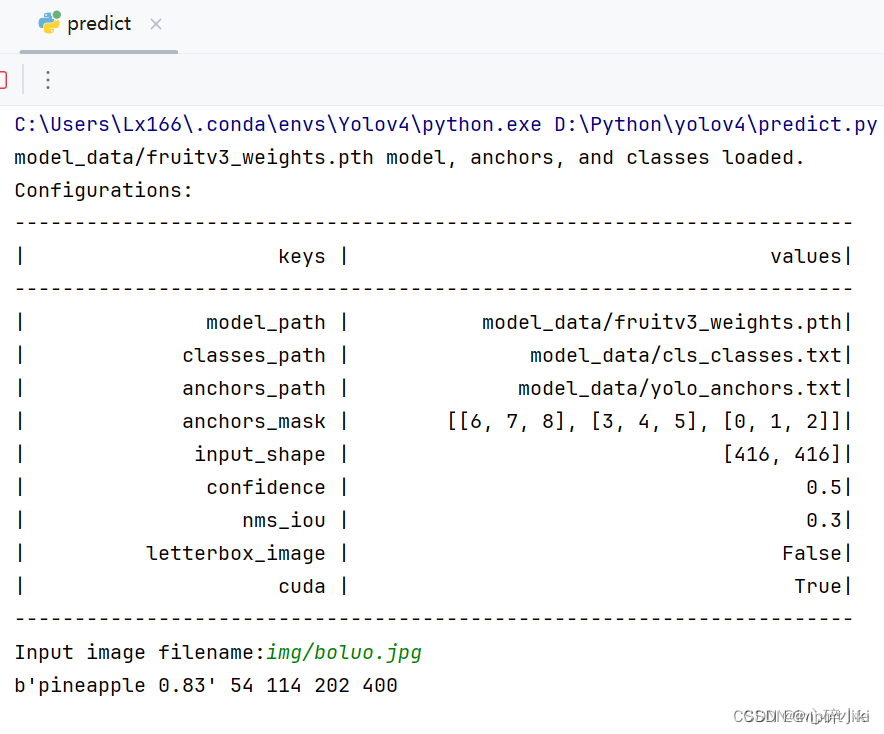
第一张菠萝图片:

第二张菠萝图片:

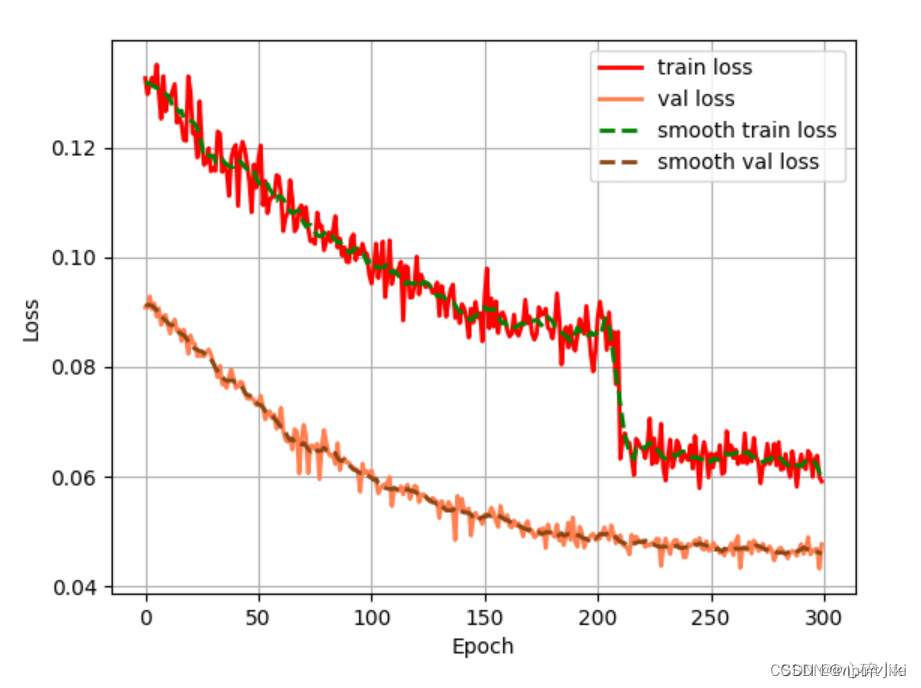
2.epoch_loss 损失曲线图
图中有四条线,分别用不同颜色标识:
红色实线表示训练损失(train loss)。
橙色实线表示验证损失(val loss)。
绿色虚线表示平滑后的训练损失(smooth train loss)。
蓝色虚线表示平滑后的验证损失(smooth val loss)。
横轴标记为“Epoch”,范围从0到300。
纵轴标记为“Loss”,范围从0.04到0.12左右。
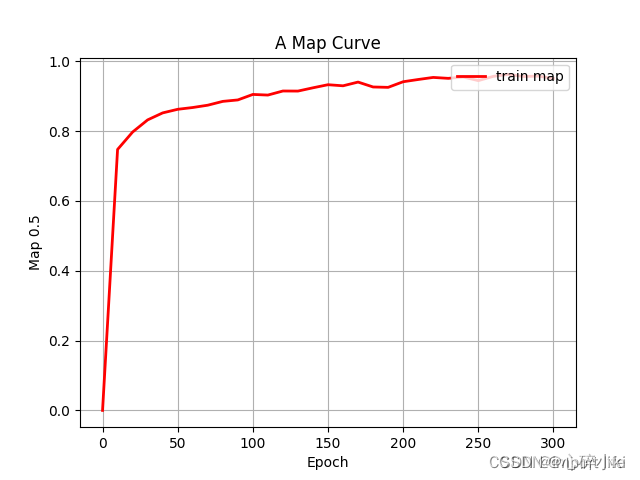
3.epoch_map 平均精度曲线图
红色曲线代表“train_map”随“Epoch”变化的趋势。
横轴标记为“Epoch”,范围从0延伸至300。
纵轴标记为“mAP”,范围从0到1.0。
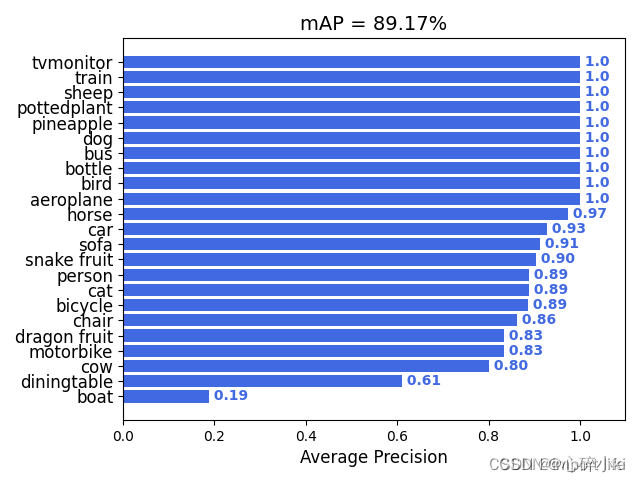
4.不同类别“精确度-召回率曲线”下的平均精度(mAP)图

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









