







 超级会员免费看
超级会员免费看
文章目录
一、“PyMuPDF、Pillow和pytesseract实现PDF文件中文OCR识别”存在的问题及改进方向
上一版的OCR识别博文在这:
https://blog.csdn.net/yuetaope/article/details/139642133
1.1 存在问题
上一版的方法是将页面整体转换为图片,然后整体识别图片,未区分原PDF中的文字元素和图片元素。这样做的结果是,原本不需要OCR识别的文字元素也转换成了图片,造成运行速度和识别率的降低。
1.2 改进方向
浏览pymupdf官网
https://pymupdf.readthedocs.io/en/latest/the-basics.html#supported-file-types
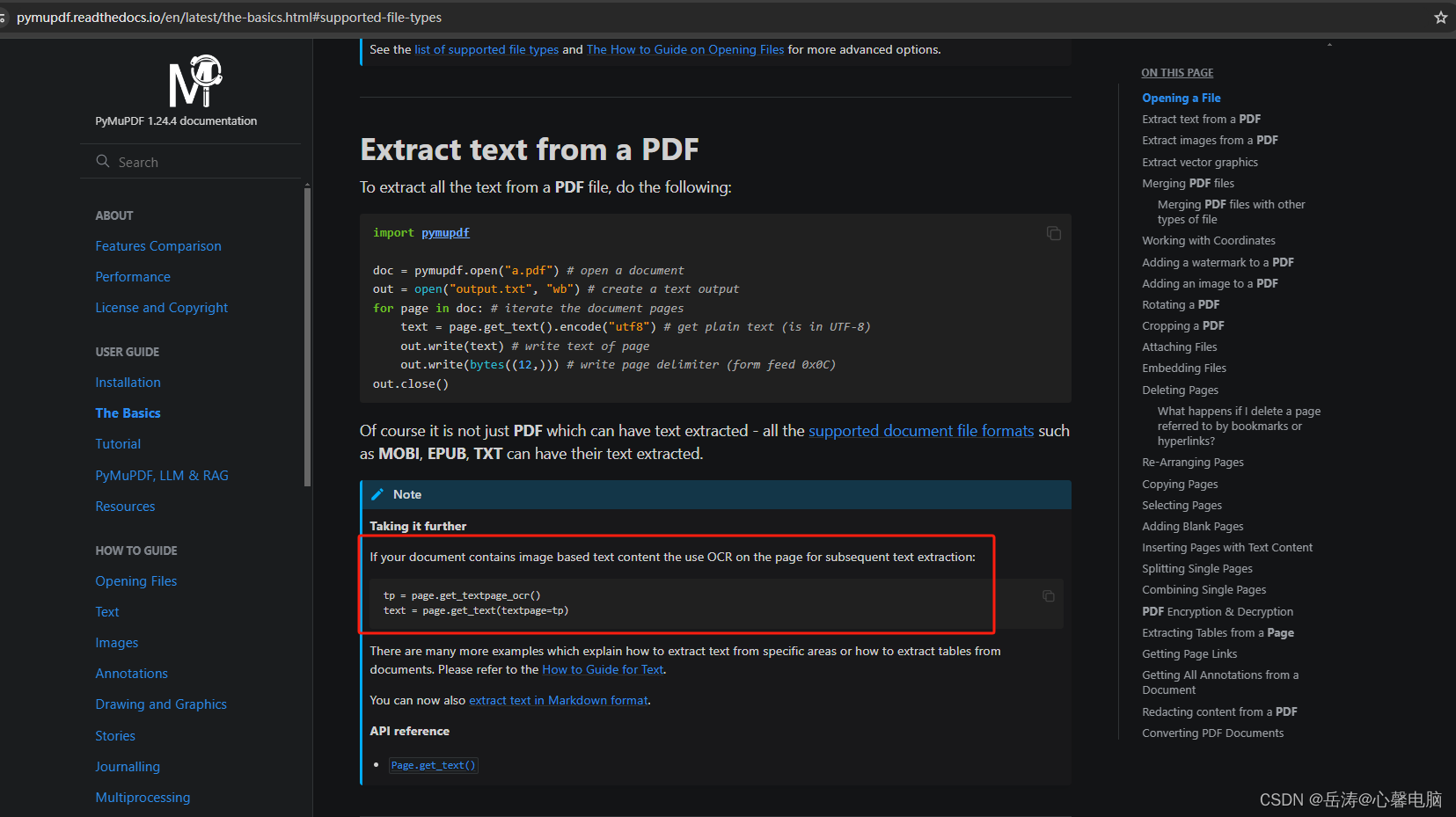
1.2.1 使用PyMuPdf识别文字元素
首先,使用使用PyMuPdf的page.get_textpage_ocr()识别文字元素
tp 
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











