







香农科技 ACL 2020的论文笔记
代码和paper可见:https://github.com/ShannonAI/mrc-for-flat-nested-ner
文章提出了将ner看做MRC(machine reading comprehen- sion )任务,而不是当做序列标注看待。

文章认为。在序列标注的过程中,如ORG是被当做onehot向量使用的,由于这样不是明确的知道要抽取什么,会导致较差的性能。但是MRC方法会将query编码成重要的实体类别的先验信息。此外,通过对标签类别(如ORG)的综合描述(如“公司、机构和机构”)进行编码,该模型有可能消除类似标签类的歧义。
之前一到两年,有将NLP任务转为MRC的问答模式的方法。如:
- 关系抽取,Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-shot relation extrac- tion via reading comprehension. For example, the relation EDUCATED-AT can be mapped to “Where did x study?”. Given a question q(x), if a non-null answer y can be extracted from a sentence, it means the relation label for the current sentence is R.
任务定义
给定输入序列X = {x1, x2,…, xn},其中n表示序列的长度,我们需要找到X中的每个实体,然后给它分配一个标签y∈y,其中y是一个预定义的所有可能的标签类型的列表(如PER, LOC等)。
数据构建
首先,我们需要将NER标记风格的数据集转换成一组 (问题、答案、上下文) 三元组。有每个标签类型y∈Y,它与自然语言问题qy相关联,qy = {q1, q2, ..., qm} ,其中m表示生成的查询的长度。注释实体xstart,end = {xstart, xstart+1,···,xend-1, xend}是满足start≤end的X的子字符串。每个实体都有一个真实标签y∈y。通过基于标签y生成一个自然语言问题qy,我们可以获得三元组(qy, xstart,end, X),这正是我们需要的三元组(问题,答案,上下文)。注意,我们使用下标“start,end”来表示从' start '到' end '的连续标记。
查询生成
query的生产是非常重要的,因为query编码了关于label的先验知识,这对最终结果有非常重要的影响。
已经有一些生成query的方法,如Entity-relation extraction as multi-turn question an- swering. 中利用基于模板的程序构造查询,提取实体之间的语义关系。
在本文中,我们以注释指南注释作为参考来构造查询。注释指南指出指南提供的注释器数据集的数据集构建器。它们是对标签类别的描述,被描述得尽可能通用和精确,以便注释者可以注释任何文本中的概念或提及,而不会产生歧义。示例如表1所示。

Table 1 Examples for transforming different entity cat- egories to question queries.
模型细节
1、模型骨干
使用了BERT ,为了与BERT一致,查询qy和文章X被连接起来,形成组合字符串{[CLS], q1, q2,…, qm,[9月],x1, x2,…xn},[CLS]和[SEP]是特殊的tokens。然后BERT接收合并后的字符串并输出一个上下文表示矩阵E∈Rn×d,其中d是BERT最后一层的向量维数,我们只需删除查询表示即可。
2、Span选择
两种MRC 的span选择方法:
- Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. 2016. Bidirectional attention flow for machine comprehension.
- Zhiguo Wang, Haitao Mi, Wael Hamza, and Radu Florian. 2016. Multi-perspective context match- ing for machine comprehension.
分别对应的策略是,本文选择了第二个:
- 用两个n类分类器分别预测开始索引和结束索引,其中n表示上下文的长度。由于softmax函数覆盖了上下文中的所有token,因此该策略的缺点是只能输出给定查询的单个span;
- 另一种策略是使用两个二进制分类器,一个用于预测每个token是否为开始索引,另一个用于预测每个token是否为结束索引。这种策略允许为给定的上下文和特定的查询输出多个开始索引和多个结束索引,因此有可能根据qy提取所有相关的实体。我们采用第二种策略,具体描述如下。
Start Index Prediction
基于BERT输出的矩阵E,模型首先预测每个token作为start的概率:
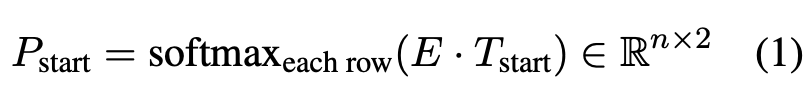
Tstart ∈ Rd×2 是要学习的权重。Pstart 的每一行表示每个索引作为给定查询的实体的起始位置的概率分布。
End Index Prediction
同上,使用Tend 获得分布Pend ∈ Rd×2
Start-End Matching
因为entity之间的覆盖,一个start匹配最近的end index是没有作用的。
本文使用argmax得到可能是起始位置或结束位置的预测索引
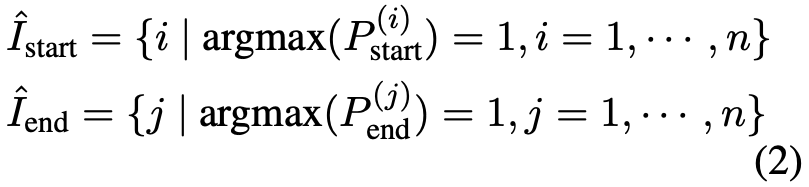
上标(i) 表示矩阵的第i行,所以上面得到两个start和end矩阵,然后用一个二分类模型(match model)来匹配start和end:
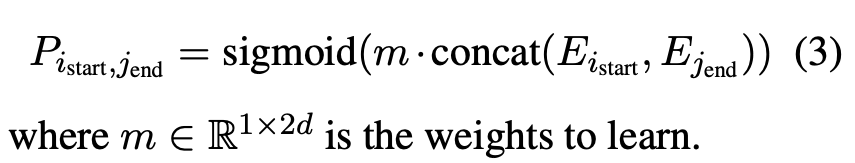
训练和测试
在训练阶段,X都配有Ystart、Yend,其长度为n,是所有真实实体是否是起始还是结束的标志。
索引预测使用如下的loss函数:
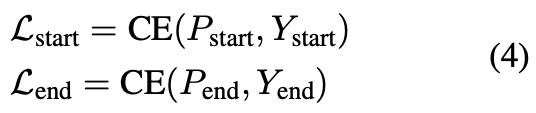
匹配的loss:
![]()
全局优化的loss:
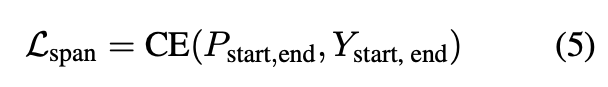
α, β, γ ∈ [0, 1]
在测试阶段,首先预测start和end,然后用匹配模型将他们对齐,最后得到提取出来的答案。
结论
实验很详细
OntoNotes性能有更大提升的原因是OntoNotes包含的实体类型比CoNLL03 (18 vs 4)更多,而且一些实体类别面临数据少和数据稀疏性问题。由于查询对要提取的实体类型编码了重要的先验知识,因此MRC公式更接近于标签稀疏性问题,从而在实体上有了更多的改进。

分析
MRC有提升是因为MRC公式通过对查询中的先验边进行编码,简化了实体提取过程;另一方面,良好的表现也可能来自于BERT的大规模预培训。
为了区别出大规模BERT预训练的影响,文章将LSTM-CRF标记模型(Emma Strubell, Patrick Verga, David Belanger, and Andrew McCallum. 2017. Fast and accurate entity recognition with iterated dilated convolutions. )与其他基于MRC的模型如QAnet (Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V. Le. 2018. Qanet: Combining local convolution with global self-attention for reading comprehension. )和BiDAF (Min Joon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. )进行了比较,得出本文方法不依赖于大规模的预训练。可以看出,虽然BERT-Tagger表现不佳,但基于MRC的方法QAnet和BiDAF仍然显著优于基于LSTM+CRF的标记模型。

文章还给出BiDAF model 的注意力矩阵输出的query和sentence的额一个例子

构造query的方法
•标签位置索引:使用标签的索引构造查询,即“一”、“二”、“三”。
•关键字:查询是描述标签的关键字,例如,标签ORG的问题查询是“组织”。
•基于规则的模板填充:使用模板生成问题。对tag ORG的查询是“文本中提到了哪个组织”。
•维基百科:查询是使用其维基百科定义构造的。对tag ORG的查询是“一个组织是由多个人组成的实体,比如一个机构或一个协会。”
同义词:指的是与使用牛津词典提取的原始关键词的意思完全或几乎相同的单词或短语。对tag ORG的查询是“association”。
•关键字+同义词:关键字和它的同义词的连接。
•注释指南注释:是我们在本文中使用的方法。tag ORG的查询是“查找组织,包括公司、机构和机构”。
Zero-shot Evaluation on Unseen Labels
对未知label的泛化性测试

mrc有先验知识可以提供,所以具有zero-shot 学习能力
训练集大小

MRC只用了一般的数据就能达到红线100%的数据效果
个人觉得这篇论文思路非常好,将nests、flat ner任务统一框架,预测start和end然后再加上一个match model,一共三个步骤。这个思路是非常正的,符合正常人类的思维。传统的序列标注直接给出start end type,三个任务都在一起,可能比较难学,并且不容做到两种ner任务的统一。并且加上了先验知识,利用QA机制,每次能查出所有相关查询(label)的实体。后面可以结合加入更多的先验知识如替换单一的bert模型,使用flat lattice那样的模型作为骨干网络,是不是效果会更上一层。















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









