







论文地址: https://arxiv.org/pdf/1910.11476.pdf
总结:将ner任务看成mrc(machine reading comprehension)任务 解决实体嵌套问题
如 北京大学不仅是一个组织 同时北京是一个地点 而看成mrc任务的好处在于引入了query这个先验知识 比如对于LOC类别 我们构造这样的query 找出国家 城市等抽象或具体的地点 模型通过attention机制 对于query中的国家 城市词汇学习到了地点的关注信息然后反馈到passage中的实体信息捕捉中 提取具有不同类别重叠的两个实体需要回答两个独立的问题 和最近打的比赛思路类似 ner和qa有时候就是可以解决同一类型问题的
论文细节写的很详细 大概从三个点来讲的
- 构造query ner向qa转化的关键就在这 假设目前我们要预测的实体类别个数为m 则我们需要构造m个不同的query 每个样本相当于扩充了m倍 得到m个新的样本 关于如何构造query 这个就需要人工来设计了 对于通用的location person organization类别 可以使用一些简单的query 就像ORG就可以设计为 找出公司 商业机构 社会组织等组织机构
- 构造训练数据 用BERT来做阅读理解任务首先需要构造相应格式的训练数据 目前假设我们对每个原始样本 构造了m个query 接下来就是将每个query和样本passage进行拼接 得到m个不同的bert输入数据 如下所示:
[[cls] 找出某某地点[sep]passage中包含地点的一句话[sep]]
经过构造后的一条数据样本是预测一个类别的实体的位置信息
另外 在构造数据的时候有很多细节需要注意:
序列长度问题 由于bert最长只能接收512长度的序列 因此很多情况下都需要截断
对序列进行mask 由于我们搜索实体的范围仅局限与上下文passage 不包括query 但是bert处理的是query+passage整体序列 在最后计算loss的时候 我们需要将query部分(以及cls,sep、pad等特殊字符)mask掉 使其在计算loss时被忽略
- 损失函数
分别预测实体的开始位置、结束位置以及从开始到结束位置是实体的概率 损失函数分为三个部分 L-start L-end L-span
- start:每一个token的二分类CE之和(答案开始)
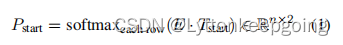
L-end:每一个token的二分类CE之和(答案结束)一样
L-span:答案开始和答案结束组合的二分类CE之和 span loss通过一个二维矩阵来记录真实实体在句子中的(Start,End)位置 比如某个实体在文本中的位置是1~3 那么它在二维矩阵的坐标(1,3)则标注为1 然后分别用三个超参控制三个不同loss的比例
然后解释了如何解决实体嵌套的问题
主要就是构造问题的时候用的annotation guideline notes来作为参考进行构造答案 guideline为tag定义类别可以归纳类别和准确为人类标注提供注释防止歧义 然后又说了一下为什么选guideline当然最后是guideline最好
模型:就是bert作为baseline
















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











