








Abstract
将NER的序列标注任务看作一项MRC任务,此方法可以引入query先验知识,对于不同类别的重叠实体回答不同的独立问题,可以解决重叠实体问题。
NER as MRC
Task Formalization
给定输入序列 X = { x 1 , . . . , x n } X=\{x_1, ...,x_n\} X={x1,...,xn},n是序列长度,本文要在X中找到每一个实体,并分配一个 y ∈ Y y\in Y y∈Y
Dataset Construction
将tagging-style标注的数据集转化为一个三元组集合(quesiton, answer,context)
对于每一个tag类型
y
∈
Y
y\in Y
y∈Y,对应一个自然语言问题
q
y
=
(
q
1
,
.
.
.
.
,
q
m
)
q_y=(q_1,....,q_m)
qy=(q1,....,qm),m是query的长度。
Query Generation
参考数据指南,引入实体类型的属性信息
Model
[ C L S ] q 1 , . . . , q m [ S E P ] x 1 , . . . , x n [ S E P ] [CLS]q_1,...,q_m[SEP]x_1,...,x_n[SEP] [CLS]q1,...,qm[SEP]x1,...,xn[SEP]输入到BERT中,得到山下文表达矩阵 E ∈ R n × d E\in R^{n \times d} E∈Rn×d
span selection
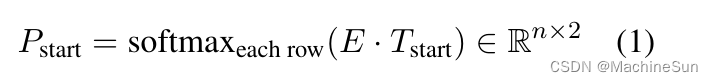
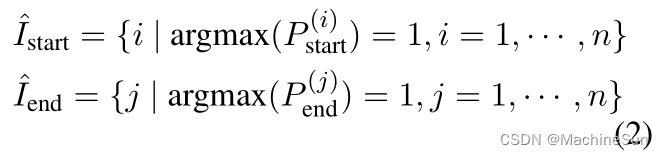
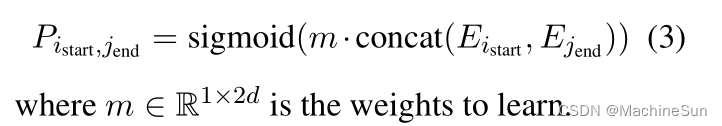
利用指针网络分别求出头和尾,然后用match矩阵求头和尾匹配的概率,这个点很强
Result
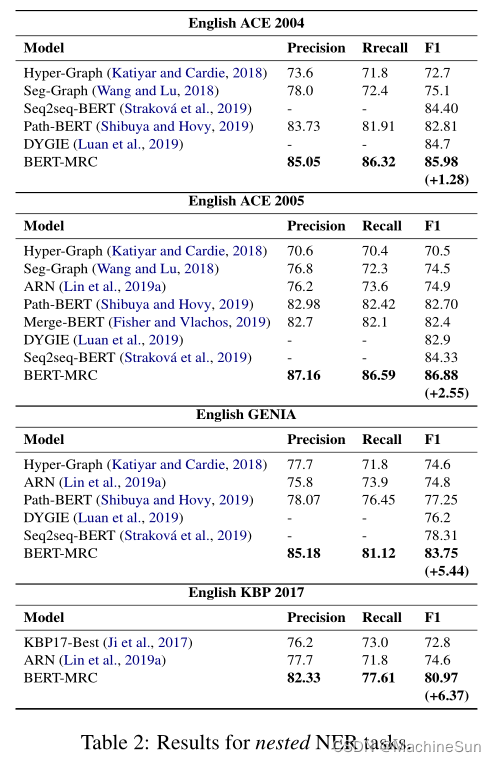
启示
- 牛皮
- 这个代码,改了有两个月,就是达不到他的分数,有点难。最重要的是时间复杂度太高了,ACE05训练完要十个小时,还是四张3090一块跑的情况下。建议原地放弃

















 3761
3761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











